

前言
作为一名前端开发者,刀耕火种的年代随着 NodeJS 等工具的出现,已经一去不复返了。如果你还停留在写着冗长的HTML代码,不断重复着复制粘贴,那么你应该继续学习了。
之所以写这篇文章,是源于前段时间我的一个Github个人主页项目。因为是要放在Github上的,所以只能是静态站点,那么所有静态页面如果一个一个手写的话,是很痛苦的。没有了后台程序,如何去定义模板文件?总不至于每个页面中都写上相同的 header 和 footer 吧。可以使用 Sass 去写 CSS 吗?可以使用 CoffeeScript 去写 JavaScript 吗?可以使用 Markdown 去写HTML内容吗?可以使用 Jade 去写HTML结构吗?
带着这些疑问,我将一步一步实现一个自动化的前端静态站点项目。
环境准备
Mac 或 Linux,不推荐Windows下开发,因为你会遇到很多蛋疼的问题,从本质上来说,你应该开始在Linux下做开发了。
如果你像我一样还在使用 Windows,可以安装一个Ubuntu虚拟机,然后通过 Samba 共享文件,用 SSH 和 Windows做连接,最终就能实现在你熟悉的 Windows下做开发(编辑文件),而运行环境却是 Linux。
1、创建项目
不管做什么开发,我们都应该遵循一定的规范,创建项目同样要注意文件夹的名字和结构。首先创建一个如下的基础项目结构,暂且就将项目命名为 auto-web:
简单解释一下:
/src源文件所在地。开发过程中的各种CSS和JS源文件都往这里面放。/dist目标文件所在地。上线前通过工具生成的CSS和JS目标文件都输出到这里。/images图片文件。/vendor第三方的 CSS、JS 和字体文件都存放到这里。/viewsHTML 视图文件。
当然目前我们是手动创建的,可以设想一下,利用NodeJS,我们是完全可以做到一条命令创建出这样的文件夹结构。
2、从 index.html 开始
首先我们习惯性地创建一个 index.html 页面
Hello world
这是我的个人主页
3、我想用 Jade
什么是 Jade ? - Jade 是 Node 的一个模板引擎,一句话就是让我们能够更快更简便地写HTML,大家可以去 Jade 的 官网,由于其主要是靠缩进来定义结构,所以一般都能够很快地学会这种写法。
类似的模板引擎在 Rails 里面也有一个叫 Slim 。当然有很多开发者是不喜欢用类似的方式去开发,不过我们这里仅作为一个示例,具体用还是不用取决于你自己。
OK,咱们来将 index.html 换成 Jade。
首先,咱们在 /views 文件夹下创建一个 index.jade 文件,然后输入下面的内容:
doctype html
html
head
meta(charset="utf-8")
title Hello world
body
h2 这是我的个人主页
这和上面的 index.html 是完全一样的。那么我们可以对比一起两种写法:
在 HTML 代码量越大的情况下,Jade 的写法就越有优势了。当然还是那句话,用与不用都取决于你自己的爱好。
OK,到此为止,我们已经写好了一个 HTML的模板引擎。
直接点击 index.jade 能运行吗?肯定是不行的。在这里我得强调一下,我们所要做的额外的工作,不是为了运行项目,而是为了开发项目。就好比我们都要去北京,只不过你是走路去的,而我是坐飞机去的,目的一致,优化了开发流程而已。
明白了这一点,我们就知道,应该将 index.jade 转换成 index.html 了。
该如何转换呢?这必然得用上工具了,咱们需要一门后台语言的命令行工具,Ruby?Python? 对,他们都能完成这份工作。但我们是前端,自然最佳选择就是 NodeJS 了。
4、该 NodeJS 出场了
相信大家也都对 NodeJS 有过一定的了解,咱们先不要求精通,只要知道怎么使用即可。
首先咱们去 NPM 中查找要用到的 jade 包,找到 mmand Line 命令行,首先按照文档说的安装(必要时前面加上 sudo):
$ npm install jade -g
这里的 npm 是 Node 的一个包管理器,也就是通过类似上面的命令去安装程序中需要用到的包。
然后通过 jade --help 可以看到如何将一个 Jade 文件转换成 HTML:
jade views/index.jade -o ./
这样就能在我们的项目根目录下生成一个 index.html 了,而且它的内容是压缩过的。
好像还不错,咱们可以书写 *.jade 文件,然后通过命令生成 *.html 。
5、母版页
网站不可能只有一个页面,但是我们肯定会有公共的头部和底部,不可能每个页面都去写一遍。
有两种方式达到这种目的,一种是母版页,通过占位符和填坑的方式实现,也就是接下来我们要讲的。还有一种是在每个页面中去引入公共部分。当然得根据自己的需要来决定了。
首先我们在 views/ 下创建一个 layouts/layout.jade 母版页:
doctype html
html
head
meta(charset="utf-8")
title Hello world
body
header
| 这是头部
block con
footer
| 这是底部
注意这里的 block con 是关键,意思是创建一个标识为 con 的坑,等着其它具体页面来填内容。
那么该怎么填内容呢?我们来改写views/index.jade 文件
extends ./layouts/layout.jade
block con
div 这是主页
首先是通过 extends 引入模板文件,然后再在 block con 下面去填充首页的具体内容。
这样,以后添加任何新页面都可以通过上面的格式来了,不用去管公共部分。
6、该写 CSS 了
页面没有样式是不行的,那么我们接下来就来写样式文件。不过我们这里希望用 Sass 来写。
Sass 是一个 CSS 预处理器,简单点说就是用另外一种方式去书写 CSS(增加了包括变量、嵌套等等新写法),最终同样通过工具转换成原始的 CSS文件。不了解的同学可以大致看一下 官网,也都是很容易学会的。
好了,咱们在 /src/sass 中创建一个 main.scss 文件:
body{
background-color: #EEE;
h2{color: Red}
}
作为演示,咱们这只用到了其中的嵌套规则。
上面说到,*.scss 也是不能直接引用的,需要先转换成 *.css。怎么转换呢?首先还是安装 Sass:
npm install sass -g
然后执行下面的命令将 /src/main.scss 输出到 /dist/css/main.css 中
sass src/sass/main.scss dist/css/main.css
大家可以看到,在 /dist/css/ 中实际上生成了 main.css 和 main.css.map 两个文件,当然咱们可以不用管 main.css.map 这个文件,因为我也没去看到底这个文件有什么作用。
OK,大功告成。接下来我们就在 views/layouts/layout.jade 中将 main.css 引入。
修改 views/layouts/layout.jade:
doctype html
html
head
meta(charset="utf-8")
title Hello world
link(href="dist/css/main.css" rel="stylesheet")
body
header
| 这是头部
block con
footer
| 这是底部
然后重新执行
jade views/index.jade -o ./
打开新生成的 index.html 文件,是不是应用上了我们的样式了?
7、该写 JavaScript 了
同样滴,JavaScript 也有自己的预处理,那就是 CoffeeScript 了。这样你就可以写 JavaScript 写得很爽了。不了解的同学可以看看 教程 很简单。
类似上面的 CSS,首先在 src/coffee 下创建一个 main.coffee 文件,然后写上测试代码:
hello = ()->
console.log("your coffee is work")
hello()
然后
npm install -g coffee-script
接着编译 src/*.coffee 到 dist/js/*.js:
coffee -c -o src/coffee/main.coffee dist/js/
这里在测试中好像是不能输出来的,不过文档是这样写的,先不用管这个,暂时可以直接将其编译到当前目录下,然后手动复制到 dist/js/*.js 下面:
coffee -c src/coffee/
接下来我们就在 views/layouts/layout.jade 中将 main.js 引入。
修改 views/layouts/layout.jade:
doctype html
html
head
meta(charset="utf-8")
title Hello world
link(href="dist/css/main.css" rel="stylesheet")
script(src="dist/js/main.js")
body
header
| 这是头部
block con
footer
| 这是底部
然后重新执行
jade views/index.jade -o ./
打开新生成的 index.html 文件,F12看看是不是输出了 your coffee is work。
8、该创作了
估计很多同学都想利用 Github 个人主页(下面会讲到)来写博客,如果是有后台程序,那么一般是将博客内容存到数据库中,然后在一个指定的页面中读取显示出来。
那么全静态站点该如何做呢?我们没有数据库。的确,但是我们仍然可以把博客内容剥离出来,放到一个单独的文件中,然后通过命令去生成单个的博客页面。
这里我们使用 Markdown 格式来写内容,我们新建一个文件夹 views/blog/ 文件夹用于存放所有博客文件。首先我们新建一个 views/blog/index.jade 的页面用于显示文章:
extends ../layouts/layout.jade
block con
article
include:marked hello.md
注意这里是通过 include:marked 指令来将 Markdown 文件引进来并解析成 HTML,这是 Jade 为我们提供的功能。
然后创建一个 hello.md 的文章:
### 这是标题
这是内容
[链接文字](链接地址)
最后就会生成一个 blog/index.html。
这里我们是把 include:marked hello.md 写死了,事实上我们是要实现在 views/blog/ 下添加很多的 Markdown 格式的博客内容文件,然后执行 gulp 即可在 blog/下面生成对应的 HTML 文件。
大家可以思考一下这个问题,我这里就不做了,也许会在后面的文章中来进行补充。
到此为止,整个项目已经初具成效了。
那么我们每次修改内容的时候,都得去执行相应的命令,是不是有点繁琐呢?程序员一定要懒,能程序做的就别自己手动去做。那么有这种工具可以帮我们完成这一系列动作吗?
9、自动化构建
所谓的自动化构建就是将多个开发中的操作整理到一起,简化我们的整个开发过程。简单点说就是配置一系列的命令语句,然后一行命令就搞定所有的CSS、JavaScript等处理工作。
当然构建工具的选择还是蛮多的(查看 完整列表)。这里我们选择的是 gulp,因为使用和配置都比较简单。
首先是安装 gulp
npm install --global gulp
然后在你的项目根目录下创建一个 gulpfile.js 文件,内容如下:
var gulp = require('gulp');
gulp.task('default', function() {
// place code for your default task here
});
然后执行
gulp
可以看到默认的任务执行了,只是没有做任何工作:
[14:18:31] Starting 'default'...
[14:18:31] Finished 'default' after 79 μs
下面我们就来配置 gulp 来完成我们的自动化任务,这里咱们先以编译 Sass 文件作为示例。
首先得引入 Sass 的处理包,注意这里不再是 sass ,而是 gulp 的 Sass 插件,可以在 npm 上面找到(点击这里)然后我们可以看看它的大致用法。
首先是引入:
var sass = require('gulp-sass');
然后是创建一个任务:
gulp.task('styles',function(){
gulp.src('./src/sass/*.scss')
.pipe(sass())
.pipe(gulp.dest('./dist/css'))
})
这里我们通过 src 指定 *.scss 源文件的位置,然后传入 pipe(自动化流程中的处理管道)最后通过 dest 指定输出路径。整个过程其实是很好理解的。
完了你的 gulpfile.js 文件就会是这个样子:
var gulp = require('gulp'),
sass = require('gulp-sass');
gulp.task('styles',function(){
gulp.src('./src/sass/*.scss')
.pipe(sass())
.pipe(gulp.dest('./dist/css'))
})
接下来同样需要安装 gulp-sass
npm install -g gulp-sass
最后,我们执行
gulp
可以看到,Sass 文件已经编译成功了。
对于 coffee 和 jade 文件,我们同样创建各自的任务和处理管道,这里就不重复说了,可以直接看代码。
这里还有一个 clean 任务,用于每次新编译的时候把老文件清空掉
gulp.task('clean',function(cb){
del(['./dist'],cb)
})
因为执行 gulp 命令默认是取的 default 任务,所以我们需要创建该任务,并把其它任务都给加进去
gulp.task('default',['clean'],function(){
gulp.start('styles','scripts','templates');
})
可以看到这里是保证在 clean 任执行完成后再去执行我们的 'styles','scripts','templates' 任务。
在实际的开发过程中,不管我们修改什么文件,只需要 gulp 一下即可,方便了很多。但是仍然每次修改都得执行一下。可不可以让 gulp 来监听我们的文件变化,然后自动重新执行编译任务呢?
答案是可以的。只需要将这些任务加入监控 watch 就行了:
gulp.task('watch',function(){
gulp.watch('./src/sass/*.scss',['styles']);
gulp.watch('./src/coffee/*.coffee',['scripts']);
gulp.watch('./views/*.jade',['templates']);
})
然后执行
gulp watch
这样,gulp 就开始监听文件了,不管我们做了什么修改,都不用再次执行 gulp 了。
源码 中我用到了更多的包(压缩、合并、重命名等等)大家可以了解一下,不懂的可以去 npm 上查一下用法文档。
10、开发环境
如果要是在别人的环境中运行该项目,那么我们之前安装的包都得重新安装一遍,是不是很麻烦。别怕,我们有 package.json,用来管理我们这些包的依赖,换了环境只需要执行一下 npm install 即可将我们之前的包都给安装上了,相当省事。
需要手动创建 package.json 吗?NO,只需执行
npm init
接下来我们就可以按照提示创建自己的 package.json 了。 里面包含了该项目的一些信息,咱们找到 dependencies 这一行,这便是该项目要用到的包。正常情况下应该是这种格式:
"dependencies": {
"gulp": "^3.9.0",
"gulp-sass": "~2.0.4",
....
}
但是很遗憾,里面什么都没有,这意味着我们必须一个个手动往里面添加我们上面用到的包了。
心好累...
难道就不能自动给我们加上去吗?不能,不过我们如果在开始安装每个包的时候在命令结尾加上 -save 参数,那么后面这些依赖便可以自动加到 dependencies 下了,如:
npm install coffee-script -save
所以下次开发的时候,别忘了在安装包的时候加上这个参数。
11、版本控制
现在项目已经完成了,我们应该将它纳入版本控制了。什么叫版本控制呢?通俗点说就是充分管理你的代码日志,你对代码做的任何增删改,只要你提交过,就会记录下来,而且可以随时回退到之前的任何状态,从而保证整个开发过程不会断层。
目前我们基本上都会使用Git来完成版本控制,Git只是一种协议,而具体则有Github、Bitbucket、Gitlab之类的实现。而 Github 则是开源项目的不二选择。
1、首先我们在项目根目录下执行
git init
这里是初始化,会创建一个 .git 文件夹,里面包含了所有跟版本控制相关的数据。所以,如果你想把该项目和Git断开,直接删除该文件夹即可。
2、添加一个 README.md (可选)用于描述项目
touch README.md
注意这里是 Markdown 格式的。
3、忽略某些文件
在提交代码之前,我们需要将某些文件排除在外,比如由 npm 产生的 node_modules 文件夹,这是开发环境下用到的,可以通过 npm install 在新环境下安装依赖。所以理应不纳入版本管理,还有缓存之类的都应该排除掉。
那么我们就创建一个名为 .gitignore 的文件,内容就如下:
.DS_Store
node_modules
.sass-cache
上面只是一个大致的内容,实际开发的时候你得根据自己的需求去忽略某些文件。
4、提交代码到本地
git add .
git commit -m "init project"
注意,这里仅仅是将代码提交到了本地。
5、提交到 Github
首先我们在Github上创建一个项目 auto-web
Create repository 到下一个页面上,复制那句
git remote add origin git@github.com:awesomes-cn/auto-web.git
(这里是我的,你得复制你自己的) 然后回到项目根目录执行该命令。
最后执行提交
git push -u origin master
去你的 Github 上,可以看到该项目的所有文件已经传上去了,而那些忽略掉的文件则没有上去。
感兴趣的同学可以 cat .git/config 一下:
[core]
repositoryformatversion = 0
filemode = true
bare = false
logallrefupdates = true
[remote "origin"]
url = git@github.com:awesomes-cn/auto-web.git
fetch = +refs/heads/*:refs/remotes/origin/*
[branch "master"]
remote = origin
merge = refs/heads/master
这就是本地与远程连接的一个配置,由 remote 和 branch 组成,即通过【远端源+分支】来精确定位到最终提交的地址。如果我们直接修改这个文件,也会和用命令一样达到相同的配置效果。
起初是没有这些内容的,当我们执行 git remote add origin ... 时则添加了
[remote "origin"]
url = git@github.com:awesomes-cn/auto-web.git
fetch = +refs/heads/*:refs/remotes/origin/*
而 git push -u origin master 则指定了
[branch "master"]
remote = origin
merge = refs/heads/master
所以如果只有 master 分支,后面的提交就直接可以 git push 了。
如果这是你在公司做的,回到家了想继续开发,只需
git clone git@github.com:awesomes-cn/auto-web.git
cd auto-web
npm install
gulp watch
开发环境就绪,继续吧....
免费个人主页
如果你想把该项目作为一个个人主页项目,也就是直接浏览静态页面。Github 给每个用户提供了一个特殊的库,那就是 .github.io ,因为这个项目是可以直接在浏览器中浏览的。一般的前端库都会将文档页面或者演示页面放到该主页上,这样就没必要自己搭服务器来做了。
那么很简单,只需要把该项目的名字改成 .github.io 比如我的是 awesomes-cn.github.io。
然后就可以在浏览器中通过 http://.github.io 访问了。
如此,一个个人主页就诞生了,可以用来做个人简历和博客,完全不用服务器和数据库参与,而且不需要花一分钱的费用。
如果网站中有大量的资源图片,要是放在 Github 上势必会影响访问速度。所以可以将图片放到云存储上面,比如七牛云存储,个人最多有15G的免费流量,完全够用了。
总结
上面的每个部分,我讲得都不是很深入,如果按照我所说的,整个流程都走通了,那么你现在可以对自己感兴趣的部分去做深入了解和学习了。
当前的前端发展是很快的,但某些思想却是不变的,我们必须学会以不变应万变。打好基础,将来不管什么新的框架或者工具都可以快速上手。
附 Github 源码: github.com/awesomes-cn…
最近在开发消息通知的时候,遇到了一个CSS的小问题,默认在用户界面会有下面的显示:
因为用的是 bootstrap,那么理所当然,我们的CSS会像下面这样:
@我的
评论 2
赞 1
粉丝
我们可以在 bootstrap 的样式 文件 中看到:
.badge {
display: inline-block;
min-width: 10px;
padding: 3px 7px;
font-size: 12px;
font-weight: bold;
line-height: 1;
color: #fff;
text-align: center;
white-space: nowrap;
vertical-align: baseline;
background-color: #777;
border-radius: 10px;
}
那么我们可以想象,默认情况下肯定是下面这种显示:
因为 .badge 本身是有 background-color 和 padding 的。所以即使没有内容也会有一个红色背景的小方块。
那么如何让这个没有内容的方块不显示呢?
当然我们可以利用 JavaScript 来实现(这里使用 jQuery):
$(".badge:empty").hide()
不过对于界面显示的控制,能用CSS就不要用 JavaScript,那么能用 CSS 实现吗?
答案是可以的,我们可以在上面 bootstrap 样式代码的下一行看到这样一句:
.badge:empty {
display: none;
}
经查询文档
:empty 的作用就是匹配没有子元素(包括文本节点)的选择器。除了 IE8 及更早的版本,所有主流浏览器均支持 :empty 选择器。当然我们这里就直接利用 display: none; 让其隐藏了。
还是那句,能用CSS就不要用 JavaScript。
前段时间有微博用户发博称 Github 推出了 个人简历,于是就试了一把,只需输入自己的用户名即可生成自己的简历。
后来经提醒,这并非是Github官方推出的,这才引起我的注意,于是详细看了一下。
该 项目 其实只是一个 Github 上的名为 resume 的组织开发的,而且根据地址 http://resume.github.io/ 得知,这仅仅是 Github 提供的个人主页,而这里面能运行的只有静态页面。该项目的最后更新时间是在两年前,可见这并非是一个新项目,不过不影响我们对它的分析。
那么问题来了,既然是静态站点,为什么能获取每个用户的动态信息呢?只有一种可能,就是利用 JavaScript 去调用 Github 开放的 API。咱们来看看它的 源码。
要想做到每个用户得到自己的信息,那就得拿到用户的唯一标识( Github 用户名)。我的简历地址是 http://resume.github.io/?awesomes-cn,所以路径规则也就是 http://resume.github.io/?Github用户名,怎么拿这个用户名呢?我们来看看 代码:
(function () {
var e,
a = /\+/g, // Regex for replacing addition symbol with a space
r = /([^&=]+)=?([^&]*)/g,
d = function (s) { return decodeURIComponent(s.replace(a, " ")); },
q = window.location.search.substring(1);
while (e = r.exec(q)) {
urlParams[0] = d(e[1]);
}
})();
这里最主要的一句是 window.location.search.substring(1) 该语句可以获取到 url 后面的参数,如访问 http://resume.github.io/?awesomes-cn 时执行
window.location.search //-?awesomes-cn
window.location.search.substring(1) //- awesomes-cn
拿到用户名后,接下来就会执行 run() 方法,该方法里面就是调用Github的API去获取信息了,比如其中有一个 github_user 方法:
var github_user = function(username, callback) {
$.getJSON('https://api.github.com/users/' + username + '?callback=?', callback);
}
实际上就是利用 JSONP 从 Github 上去获取用户的基本信息。然后在回调中对数据进行处理
var res = github_user(username, function(data) {
data = data.data;
...
}
大家可能会注意到,类似这样的调用还有很多(如 github_user_repos、github_user_orgs等)他们分别对应一个获取 Github API 数据的方法,而每个回调的最后都会有类似下面的代码:
$.ajax({
url: resume,
dataType: 'html',
success: function(data) {
var template = data,
html = Mustache.to_html(template, view);
$('#resume').html(html);
document.title = name + "'s Résumé";
$("#actions #print").click(function(){
window.print();
return false;
});
}
});
那么上面的代码有何作用呢?实际上是用到了 mustache.js 这个模板引擎,将处理好的数据最终渲染到页面上展示出来。
基本上整个流程就出来了,该项目目前已获得 19796 个 star。What ?一个并非多么牛逼的项目为什么能获得这么多 star 呢?想必大家也注意到了,如果没有 star 该项目,是展示不出自己的简历的。
难道它还能拦截未 star 的用户?答案是可以的,下面我们就来找找这段神奇的代码。
可以肯定的是,这段代码一定是在 githubresume.js 中,不过代码太多,不好找。那么咱们换一种方式,首先访问一下未 star 时的页面,上面显示着很大的一句
THIS USER HASN'T OPTED IN。
OK 将这段文字复制到 Github,在当前库中去搜索,最终可以找到 views/opt_out.html 这个文件,可以推测出这是一个模板文件,会在 githubresume.js 中去调用。
接下来我们再去 githubresume.js 中搜索 opt_out.html,然后终于揪出了这段代码:
if (! github_user_starred_resume(username)) {
$.ajax({
url: 'views/opt_out.html',
dataType: 'html',
success: function(data) {
var template = data;
$('#resume').html(data);
}
});
return;
}
顺势找到
var github_user_starred_resume = function(username, page) {
...
if (repos.length > 0) {
star = github_user_starred_resume(username, page + 1);
}
return star;
}
意思是通过 github_user_starred_resume 去 Github 查看当前用户是否 star 了该项目,如果没有则渲染'views/opt_out.html' 这个模板。
真相大白,其实我们应该学会这种思考的方式,享受这种寻找原因的过程。
如何判断一个变量是否是数组,有同学会说,直接像下面这样不就行了:
typeof([]) === 'array'
很可惜,上面的代码会返回 false,typeof([]) 事实上是一个 object。
JavaScript 有 5 种简单的数据类型(undefined、null、string、number、boolean)和 1 种复杂数据类型(object),实际上调用 typeof 得到的结果如下:
typeof(1) //-number
typeof("1") //-string
typeof(1) //-number
typeof(true) //- boolean
typeof(undefined) //- undefined
typeof(function(){}) //-function
typeof([]) //-object
typeof(new Date()) //-object
typeof(null) //- object
所以是不能直接通过 typeof 判断出数组的。
那么咱们来看看 Underscore 是怎么实现的
var nativeIsArray = Array.isArray
.....
_.isArray = nativeIsArray || function(obj) {
return toString.call(obj) === '[object Array]';
};
首先会判断浏览器是否支持 Array.isArray() 这个方法,支持的话就直接用这个,比较省事。经测试IE下只能是IE9+才支持。所以为了兼容性的考虑,不能完全依靠这个方法。
接下来咱们看看 toString(),JavaScript 中的每个对象都有一个 toString() 方法,默认是从 Object 继承过来的,如果没有重写的话,会返回 "[object type]" 其中的 type 就表示该对象的类型了。
那么这就好办了,咱们来执行:
[1,2,3].toString()
结果并没有返回我们期望的 "[object Array]",而是返回了 "1,2,3",这是因为数组重写了 toString() 方法,从而导致上面的代码直接将数组元素转换成了字符串的形式。
OK,那得从上级里面找,然后通过 call() 去将上下文改成当前数组。
window.toString() //- "[object Window]"
满足我们的要求,省略掉 window,就能得出
toString.call([]) //- "[object Array]"
由上面的分析,我们可以得出,typeof() 能拿到其中 4 种基本数据类型和 object 和 function ,而 toString() 则能拿到更具体的类型。
在Underscore 1.1.7 中新增了一个 _.isObject 方法,用来判断是否为对象,代码如下:
_.isObject = function(obj) {
return obj === Object(obj);
};
上面的代码是将传入的 obj 和 Object(obj) 进行全等的比较,Object(obj) 会将 obj 转换成一个对象,=== 则是对值和类型的两方面比较。
(function(obj) {
return obj === Object(obj); //- 输出 true
})({})
只有当传入的是 对象、数组、函数 的时候才会返回 true。如果传入的是值类型(数值、布尔值、null、undefined)则会返回 false。
然而在 1.7.0 版本后,该方法又被改成了下面的 代码:
_.isObject = function(obj) {
var type = typeof obj;
return type === 'function' || type === 'object' && !!obj;
};
我们来理解一下,先通过 typeof obj 获取到变量的类型,然后再判断该类型是否为 'function' 或 'object'。
看上去好像已经足够了,那为什么还有后面的 && !!obj 呢?这里面有什么玄机吗?
我们先来看看,如果去掉 && !!obj 是否能满足需求。
typeof 方法有一个比较特殊的地方:
typeof(null) //- 返回 object
为什么会这样呢?这是由于当初 JavaScript 设计的问题,咱们无需深究,只要知道 typeof(null) 会返回 object 而不是 null 即可。
type === 'function' || type === 'object'
自然对 null 也就束手无策了,所以有了 && !!obj。
那到第二个问题了,!!obj 能把 null 排除掉吗?答案是肯定的。
在 JavaScript 中,空字符串、数字0 和 NaN、null 或者 undefined 作为布尔值时都为 false,那么
!null //- true
!!null //- false
因此便把 null 给排除掉了。
JavaScript 中有很多类似的处理方式,通过两次“负负得正”的转换,利用其中的一些转换规则,来达到我们的目的,比如我们另一篇 文章 中讲到的 ~~。
不过我还没有搞清楚为什么会将 isObject 在两个版本中做这样的修改。有知道的同学可以说说。
更新:
经过 咨询 得知,对于 obj === Object(obj) V8 引擎有一个小bug,不过这并不是做此改变的原因,实际上只是一个 优化的选择。
如何将一个浮点数转换成整数呢?很多同学会说
parseInt(1.5) //- 输出 1
还有其它方法吗?
在阅读了 smartcrop.js 的源码后,我发现整个代码中很多地方出现了类似这样的代码
options.cropWidth = ~~(options.width * scale);
options.cropHeight = ~~(options.height * scale);
那么这个 ~~ 有何妙用呢?
大家知道 ~ 表示按位取反
~1 //- 输出 -2
大致是先将十进制的 1 转换成二进制,然后将其中的 0 和 1 对换,再转换成十进制,就得到了 -2
那么对 1.5 取反呢?
~1.5 //- 输出 -2
仍然输出了 2,因为 ~ 只对整数有用,遇到浮点数则会先将其转换成整数。
那么我们完全可以利用这个特性来完成我们的转换目的了。
因为 ~ 是两个数直接的一个可逆的变换,就相当于正负号,所以负负得正
~1.5 //- 输出 -2
~-2 //- 输出 1
最终也就实现了将浮点数转换成整数了
~~1.5 //- 输出 1
那么既然已经有了 parseInt() 为什么还要用 ~~ 呢?
初步设想是性能上会有差别。
然后我就在浏览器中分别跑了下面的代码:
a=new Date()
var b;
for(i=0;i<10000000;i++){
b = parseInt(1.5)
}
alert(new Date() - a)
平均耗时为 210
a=new Date()
var b;
for(i=0;i<10000000;i++){
b = ~~1.5
}
alert(new Date() - a)
平均耗时为 40
可见在性能上 ~~ 是优于 parseInt() 的。
通常我们在对一个数据进行遍历的时候会这样写:
var arr = [...]
for(var i=0; i
大家可以想象一下这种写法的问题,每次循环的时候都会去判断
i
那么每次判断都会去计算一下数据的长度:arr.length,这样下来是比较耗性能的,有没有更好的写法呢?
我们看看 smartcrop.js 中的一段 代码
for(var i = 0, i_len = result.crops.length; i < i_len; i++) {
...
}
这里我们将 result.crops 这个数组的长度存放在了一个临时的变量 i_len 中,这样就避免了每次循环计算数组长度了。
块化已经成为了我们开发过程中不可或缺的组织方式,目前比较流行的就是AMD和CMD,下面咱们来讲讲 AMD。
AMD的全称是 Asynchronous Module Definition,即异步模块定义。这是因为在浏览器端造成的加载延迟,只能以异步加回调的方式来完成模块的正确加载和引用。
如何写一个自己的AMD模块呢?
很简单,我们只需要定义一个 define() 方法即可。这是为什么呢?因为 AMD规范 就是这么定义的。
从该规范中我们可以看到 define 方法的定义规则
define(id?, dependencies?, factory);
这是AMD规范要求的定义,那么最终运行的时候我们得找一个该规范的实现,那就是RequireJs,我们可以在其中找到关于 define 的 定义
define = function (name, deps, callback) {
...
}
那么如何将一个库输出成AMD模块呢?
我们看看 smartcrop 的 源码
if (typeof define !== 'undefined' && define.amd) define(function(){return SmartCrop;});
通过一个匿名函数去定义,这允许我们使用的时候去定义自己的名字,这也是RequireJs推荐的方式,我们的库都应该这样去定义。
我们再来看看 jQuery 中是如何输出AMD 模块的:
if ( typeof define === "function" && define.amd ) {
define( "jquery", [], function() {
return jQuery;
});
}
这里并非是通过匿名函数定义的,而是采用了命名模块。因为 jquery 被其它第三方库用得相当广泛,所以如果采用匿名函数方式就很容易造成不同命名的冲突,因此只能采用命名模块
我们知道,JavaScript 的方法参数是允许可选的。
例如有一个包含a,b,c 三个参数的方法
function say(a,b,c){
......
}
如果我们只想给a,b传值,我们可以
say('a','b')
如果我们想只给 c 传值呢?
通常我们会这样做
say(null,null,'c')
还有其它方法吗?(这里有一个前提是我们可以通过一定的规则来区分出a,b,c,比如类型)
了解AMD的同学都知道,实现AMD需要定义一个define方法,一般我们会直接传入一个匿名函数
define(function(){
...
})
或者加上依赖
define(['jquery'],function($){
...
})
而并没有用null去替代前面的未传入的参数。
那么我们来看看 RequireJs 的源码。RequireJs 中有一个define方法定义,里面有3个参数:
define = function (name, deps, callback) {
var node, context;
//Allow for anonymous modules
if (typeof name !== 'string') {
//Adjust args appropriately
callback = deps;
deps = name;
name = null;
}
if (!isArray(deps)) {
callback = deps;
deps = null;
}
....
}
实际上就是通过判断传入的第一个实参 name 的类型来确定其对应的到底是形参的第几个,如果不是 string,则通过下面的代码来交换实参,并将 name 设成 null:
callback = deps;
deps = name;
name = null;
接下来会判断 deps 是不是数组,如果不是数组则表示只传入了一个 callback,那么就再交换顺序,将 deps 置为 null
callback = deps;
deps = null;
实际上就相当于我们定义一个
define(function(){
...
})
最终会映射成
define(null,null,function(){
})
这样的好处就是可以根据传入的实参的类型(或者其它判断条件)来确定到底对应的是哪个形参。而在调用的时候就没必要传入 null 去替代不想传入的参数了。
话说,这是属于前端的时代......
在前面的文章中,我已经讲过了如何利用 Github 搭建一个免费的静态站点(深入 Github 主页)没错,这里是静态站点,说白了就是一个托管静态资源的存储而已,不提供运行后台代码的功能。
那么我们怎么做到静态站点展示动态内容呢?只有一种方式,那就是直接调用 JS 数据接口。例如之前的文章 探索那个所谓的 Github 简历项目 正是这样实现的,他是通过调用 Github 开放的 API 来获取每个会员的数据。
一个完整的网站在数据层面来讲就是对数据的增删改查而已,我们提供的接口需要具备这样的功能。那么我们可以用自己熟悉的后台语言撘一个 API ,然后让静态站点来调用,但是这个 API 是需要服务器来部署的,服务器是需要 money 的,而且如果你不懂后端开发怎么办?这和我今天讲的内容相冲突,记住,我们的目标是不花一分钱。
那我们再想想,既然自己搭建API行不通,那唯一的办法就是调用别人的 API了。大家熟知的一些大公司都会开放一些API,但那是别人给你开放的用于获取他们数据的接口,给你什么数据是他们决定的,而我们需要的是对自己的数据进行操作,我想要什么就得给我什么,很明显这不符合我们的要求。
我们需要的到时是什么呢?我希望是这样的:它给我们提供的接口,可以让我们自己通过JS去发送请求,附带的参数可以告知接口,我要创建一个表,我要删除一条数据,我要查找数据列表。
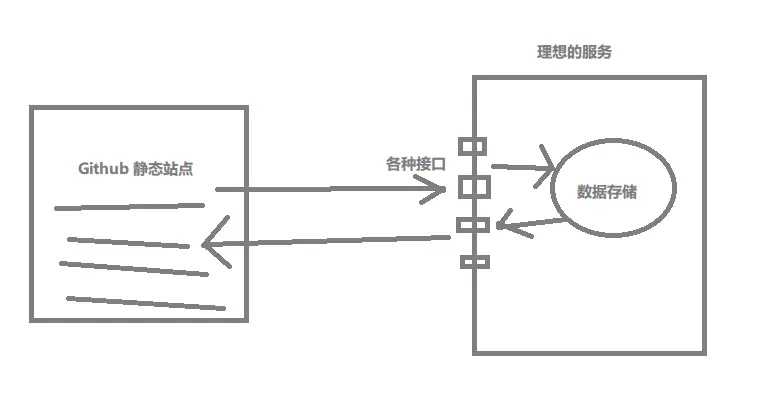
对的,就是它必须同时给我提供数据存储和开放接口
Parse
它是干嘛的呢?Parse 主要是为移动开发提供的一套数据操作的接口(说白了就是整个后端程序都由他来做)开发者不再需要关注后台数据操作了。同时它也提供了JS的SDK,所以我们完全可以用它来开发一个 web 应用。

那它是免费的吗?不是,不过它提供了免费的用量
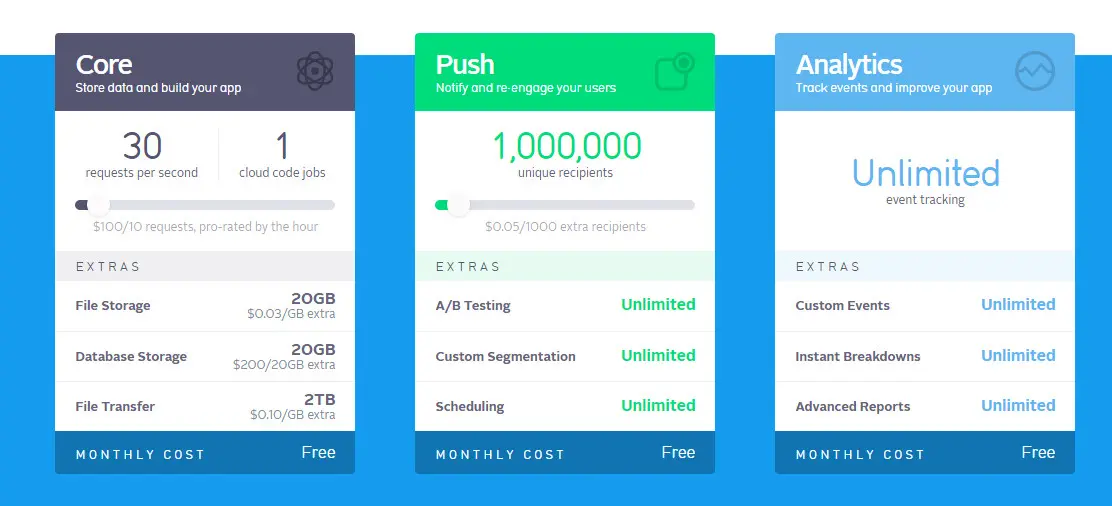
可以看到,Parse 为我们提供了每秒30个请求的免费额度,对于一个小网站完全是够用了。
工作原理
用户可以从多个终端(web、IOS、Andriod)发送请求到 https://api.parse.com/1/classes/Mem,然后携带上下面格式的URL参数:
where={"name":"awesome"}
可以看到这里是要查询 name 为 awesome 的 Mem 记录(下面有更多的查询条件介绍)。
Parse 服务端接受到这个请求后,会去解析里面的每个参数,从而确定要做什么操作。说白了就是在前端去写 sql 语句,以前这些都是由后端开发人员做的,现在完全开放给前端去做了。
我们不再需要为每一个数据对象的操作去写一个专门的接口,而是直接走一个 万能接口 具体做什么操作,根据传入的参数即可分析出来。
功能
Parse 提供了一个应用所需的几乎所有后台功能:
- 数据操作
- 用户、会话、角色
- 文件存储
- 坐标导航
- 错误处理
- 安全
- 消息推送
- 性能分析
所以拿它做一个完整的应用是没什么问题的,下面我们就看看查询的 JS SDK 用法。
JS SDK 概览
这里我主要讲一些大家关心的问题。
对象
Parse 上的数据以JSON键值对储存在 Parse.Object 中。用Parse.Object.extend 创建子类:
初始化创建对象,包含3个内置字段(objectId, createdAt, updatedAt)
var Mem = Parse.Object.extend("Mem");
var mem = new Mem();
设置值:
mem.set("name", "hxh");
获取值
var name = mem.get("name");
保存 / 更新
mem.save({
age: 18
},{
success: function(mem){...},
error: function(mem, error) {...}
})
删除对象
mem.destroy({
success: function(mem){...},
error: function(mem, error) {...}
})
删除字段值
mem.unset("age");
查询对象
var query = new Parse.Query(mem);
query.get(,{
success: function(mem){...},
error: function(mem, error) {...}
})
刷新对象
mem.fetch({
success: function(mem){...},
error: function(mem, error) {...}
})
对象关联
比如一个 myComment(评论实例)归属于一个 myPost(文章实例)
myComment.set("parent", myPost);
获取关联的对象
var post = myComment.get("parent");
post.fetch({
...
});
查询
1、新建查询对象
var Mem = Parse.Object.extend("Mem");
var query = new Parse.Query(mem);
2、查询条件
query.equalTo("name", "hxh");
3、执行查询
query.find({
success: function(results) {...},
error: function(error) {...}
})
或只返回第一个结果
query.first({
success: function(results) {...},
error: function(error) {...}
})
返回数量
query.count({
success: function(count) {...},
error: function(error) {...}
})
更多查询条件
query.notEqualTo("name", "awesomes"); // 不等于
query.greaterThan("age", 18); // 大于
query.lessThan("age", 50); // 小于
query.lessThanOrEqualTo("age", 50); // 大于等于
query.greaterThanOrEqualTo("age", 50); // 小于等于
query.containedIn("name",["hxh","awesome"]) //- 包含
query.notContainedIn("name",["hxh","awesome"]) //- 不包含
query.exists("age"); //- 存在
query.doesNotExist("age"); //- 不存在
// 字段类型为数组
query.containsAll("arrayKey", [2, 3, 4]); //- 包含数组值
// 字段类型为字符串
query.startsWith("name", "awe"); //- 以什么字符串开头
指定返回部分字段值(包括内置字段 objectId, createdAt, updatedAt)
query.select("name", "age");
query.skip(5); //- 忽略前5个结果
query.limit(10); // 最多返回10个结果
query.ascending("age"); //- 升序
query.descending("name"); //- 降序
关联查询(一个用户有一个信息表)
query.include("info");
query.find({
success: function(mems) {
var info = mems[0].get("info");
}
})
子查询(or)
...
var mainQuery = Parse.Query.or(query1, query2);
...
文件资源
对于网站要用到的资源文件,我前面的文章说过,可以存放在云存储里面。但是上传需要接口,如果该云存储提供了上传的JS接口,那可以使用。
Parse 自身也为我们提供了云存储的功能,而且提供了上传文件的SDK,比较方便。如果你非得要把文件上传到一个未提供JS接口的第三方云存储里面,那可以通过 Cloud Code 后台代码去实现(见下面)
安全
说实话,在了解了 Parse JS SDK 工作方式后,我第一个关心的问题就是如何保证安全性。
大家可以想想,和 IOS 、Andriod 不一样,我们是将 APPLICATION_ID 和 REST_API_KEY 都直接暴露在页面中的,任何人都可以拿到。
因此 Parse 采用下面的方式来提升安全性:
- 所有请求必须走 HTTPS 和 SSL,Parse 会拒绝响应非 HTTPS 的请求。
- 对于每个数据表我们都可以设置其读写和修改权限,然后根据用户的角色和来控制权限。
- 基于Cloud Code 的数据完整性校验,也就是你的数据格式必须满足要求才允许被操作(如在
beforeSave 做一些校验工作)
- 基于Cloud Code 的业务逻辑
咱们这里举个例子,比如这是一个博客程序,下面有每个用户的评论,而每个用户只能删除自己的评论,别人是不能删除的。
那么咱们就可以先将评论表设置成公开可读,以及对特定的角色(或用户)开放修改权限(这个是可以在 Parse 后台做配置的)。然后通过登录记录每个用户的会话,获取到当前用户角色,后台就会做相应的判断来决定你是否有权限删除该评论。
Cloud Code
对于一些简单的应用,使用上面的客户端SDK去调用服务端接口完全是没问题的,但是一些复杂的需求就满足不了了,这个时候我们就需要真正去后台写代码解决。
Cloud Code 就是干这事的,意思就是我们在 Parse 的云端去写代码(Node)来处理复杂逻辑。它可以接收请求并控制返回内容。还可以创建定时任务、日历记录和 Webhook,简单说,就是你基本上可以完成你在普通服务端开发中做的所有事情。
结合 Cloud Code 和 Express 框架可以和普通动态网站完全一样。
一句话,Cloud Code 就是作为 Parse 原有数据操作的一个补充,增强了服务的可定制性。
托管
Parse 同样为我们提供了托管,也就是说,你可以不用 Github,直接全部使用 Parse。
和 Github 不同的是,Parse 提供的托管是可以运行 Node 后端代码的,所以你完全可以写一个 Express 应用托管到 Parse 上。
但是对于一个轻量级的 web 应用我还是偏向于将代码托管在 Github 上进行开源和版本控制。在一个分工明确的社会,得将不同的任务交给最专业的去完成。
Node 给前端开发带来了很大的改变,促进了前端开发的自动化,我们可以简化开发工作,然后利用各种工具包生成生产环境。如运行 sass src/sass/main.scss dist/css/main.css 即可编译 Sass 文件。在实际的开发过程中,我们可能会有自己的特定需求,那么我们得学会如何创建一个Node命令行工具。
命令行接口:Cmmand Line Interface,简称 CLI,是 Node 提供的一个用于命令行交互的工具,本质是基于 Node 引擎运行的。
在前面的文章 前端扫盲-之打造一个自动化的前端项目 中,给大家留了一个问题,就是如何通过执行一条命令就生成我们需要的项目结构。今天我就带着大家一步一步解答这个问题。
我们的初步设想是,在指定目录下执行一个命令(假设为autogo)
autogo demo
就会生成一个目录名为 demo 的项目,里面包含有我们所需的基础文件结构。
开始
1、首先咱们创建一个程序包清单(package.json 文件)包含了该命令包的相关信息:
npm init
然后根据提示输入对应的信息,也可以一路回车,待生成好 package.json 文件后再作修改。
2、创建一个用于运行命令的脚本 bin/autogo.js:
#! /usr/bin/env node
console.log("hello")
然后我们执行
node bin/autogo.js
能够看到输出了 hello,当然这不是我们想要的结果,我们是要直接运行 autogo命令就能输出 hello。
3、告诉 npm 你的命令脚本文件是哪一个,这里我们需要给 package.json 添加一个 bin 字段:
{
...
"bin": {
"autogo": "./bin/autogo.js"
}
...
}
这里我们指定 autogo 命令的执行文件为 ./bin/autogo.js。
4、启用命令行:
npm link
这里我们通过 npm link 在本地安装了这个包用于测试,然后就可以通过
autogo
来运行命令了。
可能遇到的问题
1、有的同学可能在执行 autogo 命令后会报下面的错误:
-bash: /usr/local/bin/autogo: /usr/local/bin/node^M: bad interpreter: No such file or directory
之所以出现这个错误是因为 bin/autogo.js 文件是在 windows 下做的编辑,windows 下默认的换行是 \n\r ,而 linux 下默认的换行是 \n,所以文件后的 \r 在 linux 下是不会别识别的,显示成了 ^M。
要解决这个问题的办法就是改变文件的编码,这里我们需要用到 dos2unix 这个包。
首先安装
sudo apt-get install dos2unix
sudo dos2unix bin/autogo.js
问题就解决了。
2、还有的同学可能会遇到下面这个报错
: No such file or directory
报这个错是因为 #! /usr/bin/env node 没能识别出你的 node 的路径,需要将你的 node 安装路径(如/usr/local/bin/)加入到系统的 PATH 中。
其实你可以在测试环境中将这个标识换成 #!/usr/local/bin/node(这里得 which node 找到你自己的 node 路径),再运行就没问题了。但是我们之所以用 #! /usr/bin/env node 是因为这可以动态检测出不同用户各自的 node 路径,而不是写死的,毕竟不是所有用户的 node 命令都是在 /usr/local/bin/ 下。
得确保在发布之前将其改回成 #! /usr/bin/env node。
到此,一个本地的 npm 命令行工具就已经成功完成了,(可参见 官方文档)接下来我们就来完善具体的功能。
创建项目结构
咱们需要的项目结构大致如下,包含了所需的文件和文件夹(详见)。
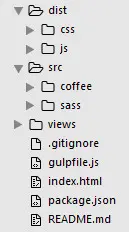
要创建上面的结构,我们可以通过程序来创建么个文件和文件夹,但是对于这么多文件,而且每个文件里或许还有更多内容,所以我们应该用一个更简便的方法。
实际上我们可以先创建一个完整的结构,然后在执行命令时,通过程序把这些文件和文件夹整个复制到目标项目文件夹中去,最后再对某些文件做一些修改即可。
按照这个思路,我们根据上面的结构,将这些文件和文件夹创建到 structure 下,然后咱们创建一个生成结构的方法 lib/generateStructure.js(这里咱们将功能模块放在了 lib/目录下)
var Promise = require("bluebird"),
fs = Promise.promisifyAll(require('fs-extra'));
function generateStructure(project){
return fs.copyAsync('structure', project,{clobber: true})
.then(function(err){
if (err) return console.error(err)
})
}
module.exports = generateStructure;
上面的代码就是通过 fs-extra 这个包(查看文档) 将 structure 目录下的内容复制到了 project 参数的目标文件夹中。 fs-extra 是对 fs 包的一个扩展,方便我们对文件的 操作。
这里咱们用到了 bluebird(查看文档),这是一个实现 Promise 的库,因为这里牵涉到了对文件的操作,所以会有异步方法,而 Promise 就是专门解决这些异步操作嵌套回调的,能将其扁平化。
自然,我们应该安装这两个包:
npm install bluebird --save
npm install fs-extra --save
这里加上 --save 参数是为了在安装后就自动将该依赖加入到 package.json 中。然后咱们改造一下 bin/autogo.js
#!/usr/bin/env node
var gs = require('../lib/generateStructure');
gs("demo");
然后执行
autogo
可以看到当前目录下生成了一个 demo 文件夹,里面包含了和 structure 相同的文件结构。
我们的目标已经初步达成了,接下来我们就来细化该命令。
命令参数
上面的命令中,我们执行 autogo 时,是生成了一个固定的 demo 项目,实际上这个名字是不能写死的,而是应该通过命令中的参数传进去。像下面这样:
autogo demo
因此,我们得在 bin/autogo.js 中去接收参数了。为了方便起见,我们这里直接使用一个专门用于处理命令行工具的包 commander(文档)。
同样,首先安装
$ npm install commander --save
然后改造 bin/autogo.js 为:
#!/usr/bin/env node
var program = require('commander'),
gs = require('../lib/generateStructure');
program
.version(require('../package.json').version)
.usage('[options] [project name]')
.parse(process.argv);
var pname = program.args[0]
gs(pname);
这里的 .version() 意思是返回该命令包的版本号,即运行
autogo --version //- 返回1.0.0
会返回 package.json 中定义的版本号。
.usage() 显示基本使用方法
执行
autogo --help
会输出:
Usage: autogo [options] [project name]
Options:
-h, --help output usage information
-V, --version output the version number
可以看到 Commander 帮我们做好了用法(Usage) 信息,以及两个参数(Options)-h, --help 和 -V, --version。
.parse(process.argv); 是将接收到的参数加入 Commander 的处理管道。
program.args 是获取到命令后的参数,注意这里是一个数组
autogo //- 返回 []
autogo demo //-返回 ['demo']
autogo demo hello //-返回 ['demo','hello']
这里咱们取第一个参数作为项目名,然后调用
var pname = program.args[0]
gs(pname);
现在我们执行:
autogo demo2
就可以看到新的项目demo2生成了,看上去我们已经完成工作了,只要运行 autogo <项目名> 就可以生成一个新的项目结构,里面包含了处理 Sass、coffee、jade 的 gulp 构建工具。
如果我们直接运行 autogo 是会报错的,因为没有传入项目名,实际上我们在运行一个命令而不传入任何参数时,可以直接返回帮助信息:
...
var pname = program.args[0]
if (!pname) program.help();
...
上面我们判断是否存在参数,如果不存在就调用 program.help() 方法,这是 commander 为我们提供的显示帮助信息的方法,可以直接调用。
那有的同学要说了,我不想用 jade ,就喜欢写原生的 HTML,很明显我们做了多余的事,而且整个结构就不那么合理了,我们需要的是一个干净的项目结构。
这个时候我们就需要把与jade 相关的文件都删掉(这里不是删 structure 目录下的文件,而是新项目下的指定文件)。与 jade 有关的文件有:
/structure/views/ 下的 index.jade 和 layouts/layout.jade /structure/gulpfile.js 中的 templates 任务代码
因此,咱们得把上面这些文件和代码干掉。
移除指定模块
首先,咱们创建一个 lib/jadeWithout.js 用来移除 jade:
var Promise = require("bluebird"),
fs = Promise.promisifyAll(require('fs-extra')),
del = require('../lib/delFile');
var files = ['/views/layouts/layout.jade','/views/index.jade'];
function jadeWithout(project){
return Promise.all([del(project,files)])
.then(function(){
return console.log('remove jade success');
})
}
module.exports = jadeWithout;
这里咱们将指定的 files 数组中的文件都删除了,这里我用了一个公共的删除文件模块 /lib/delFile.js:
var Promise = require("bluebird"),
fs = Promise.promisifyAll(require('fs-extra'));
function del(project,files){
return files.map(function(item){
return fs.removeAsync(project + item)
})
}
function delFile(project,files){
return Promise.all([del(project,files)])
}
module.exports = delFile;
因为我们这里不光有 jade,还有sass和coffee可以被移除,所以我们创建一个公共入口 withoutFile.js:
var Promise = require("bluebird");
function deal(project,outs){
return outs.map(function(item){
var action = require('../lib/'+item+'Without');
return action(project)
})
}
function withoutFile(project,outs){
return Promise.all([deal(project,outs)])
}
module.exports = withoutFile;
这里我们需要传入一个要移除的列表(如['sass','jade']),然后对每个模块进行删除。
最后,我们将withoutFile 引入到bin/autogo.js 中:
...
var gs = require('../lib/generateStructure'),
wf = require('../lib/withoutFile');
...
Promise.all([gs(pname)])
.then(function(){
return wf(pname,["jade",'sass'])
})
然后我们再次执行
autogo demo
可看到控制台依次输出了
generate project success
remove jade success
remove sass success
而且目标项目中相关文件已经被删除了。
这里咱们是 wf(pname,["jade",'sass']) 写死了 outs 参数作为测试,实际上是要再传入一个数组,那么这个数组从哪儿来呢?很明显,得从命令行参数中获取。
我们希望的是这样:
autogo --without jade demo
option
commander 为我们提供了一个 option 管道来配置命令参数,修改 bin/autogo.js:
...
program
.version(require('../package.json').version)
.usage('[options] [project name]')
.option('-W, --without ', 'generate project without some models(value can be `sass`、`coffee`、`jade`)')
.parse(process.argv);
...
这里咱们添加了 option,其格式为 .option('-<大写标识>, --<小写全称> <可取参数类型>', '数功能描述')
接着处理 without 参数:
...
var outs = program.without ? [program.without] : []
Promise.all([gs(pname)])
.then(function(){
return wf(pname,outs)
})
...
然后咱们再运行
autogo --without jade demo
可以看到这里只移除了 jade 模块,那如果我想移除多个呢?是不是可以这样:
autogo --without [jade,sass] demo
注意,这样是会报错的,因为获取到的 program.without 是一个字符串 '[jade,sass]'而不是数组,所以咱们可以这样:
autogo --without jade,sass demo
program.without 则为'jade,sass' 然后再
program.without.split(',')
既可以获取到一个数组了,因此咱们的代码就变成了:
...
var outs = program.without ? program.without.split(',') : []
Promise.all([gs(pname)])
.then(function(){
return wf(pname,outs)
})
...
这下我们就可以这样来运行了:
autogo demo --without sass,jade
发布
到目前为止,我们开发的 autogo 还是在本地的,现在就该将其发布到 npm 上了。
1、首先咱们得 注册一个账号。
2、回到项目中,执行
npm login
输入用户名、密码和邮箱便可将本地机器与 npm 连接起来了。
3、执行
npm publish
然后回到你的 npm 个人主页,就可以看到我们发布成功了 www.npmjs.com/package/aut…
从包的路径规则来看,是没有包含用户名的,由此可知,同名的包是不会被允许的,所以大家在跟着做的时候要给项目取一个不同的名字。
然后咱们来测试一下刚刚发布的包
首先删除本地开发做的 autogo 链接
sudo npm unlink
npm install autogo -g
注意这里需要带上 -g 参数,因为命令行是应该安装在全局环境中。安装成功后,我们切换到另外一个目录下,执行:
autogo demo
然而结果并非我们想象的那样:
Unhandled rejection Error: ENOENT, lstat 'structure'
at Error (native)
意思是找不到 structure,这是怎么回事呢?
实际上当我们执行 npm install autogo -g 的时候,实际上是将命令包安装在了 /usr/local/lib/node_modules/autogo 下面,所以在执行命令的目录下是找不到 structure 文件夹的。
那该怎么办呢?我们能想到的就是,得在程序中去获取这个包安装的实际路径。
幸运的是 Node 给我们提供了 __dirname 这个变量用于获取当前执行文件的路径。
我们在 lib/generateStructure.js 下 console.log(__dirname) 会输出 /usr/local/lib/node_modules/autogo/lib ,然后我们把后面的lib 去掉就是根目录了:
var root = __dirname.replace(/autogo\/lib/,'autogo/')
function generateStructure(project,outs){
return fs.copyAsync(root + 'structure', project)
.then(function(err){
return err ? console.error(err) : console.log('generate project success');
})
}
...
修改后,我们按照下面的方式更新,重新安装,然后
autogo demo
cd demo
npm install
gulp watch
OK 一个新的项目诞生了,准备开发吧...
更新
首先修改 package.json 配置文件中的 version 字段,比如这里我从 0.1.0 改成 0.1.1(只能大于当前版本),然后再次
npm publish
即可成功发布新版本。
想将该项目从 npm 中移除吗?执行 :
npm unpublish autogo --force
附:项目源码 github.com/awesomes-cn…
