

今天被谷歌AlphaGo刷屏了。各媒体内容角度不同,笔者所在人工智能高级微信群中专家纷纷评论:
-
谷歌基于深度学习的围棋程序赢了欧洲冠军,值得庆祝。但不必过分解读,必经计算机的强项在于计算能力和记忆能力。
- 关键是以前一直神话围棋的不可战胜,现在战胜了欧洲冠军,后续看3月9段之战。
- 如果让程序与一组冠军下,会是什么结果?(蒙特卡洛树的方法容易扩展,不过计算量大增)
- 如果围棋突然变成29*29,机器会reboot?
- Chess Program,需要大量学习对局棋谱。所以有专家做扫描棋谱识别OCR出了名。
后续讨论更为发散。但对技术圈和更多行业的触动还在继续。下为综合多家媒体报道的内容,以及新智元公众号的深度翻译。新
人工智能挑战围棋有多难?
计算机和人类竞赛在棋类比赛中已不罕见,在三子棋、跳棋和国际象棋等棋类上,计算机都先后完成了对人类的挑战。但对拥有2500多年历史的围棋而言,计算机在此之前从未战胜过人类。围棋看起来棋盘简单、规则不难,纵横各19九条等距离、垂直交叉的平行线,共构成19×19(361)个交叉点。比赛双方交替落子,目的是在棋盘上占据尽可能大的空间。
在极简主义的游戏表象之下,围棋具有令人难以置信的深度和微妙之处。当棋盘为空时,先手拥有361个可选方案。在游戏进行当中,它拥有远比国际象棋更多的选择空间,这也是为什么人工智能、机器学习的研发者们始终希望在此取得突破的原因。
就机器学习的角度而言,围棋的计算最大有3361种局面,大致的体量是10170,而已经观测到的宇宙中,原子的数量才1080。国际象棋最大只有2155种局面,称为香农数,大致是1047。
“机器学习”预测人类行为
传统的人工智能方法是将所有可能的走法构建成一棵搜索树 ,但这种方法对围棋并不适用。此次谷歌推出的AlphaGo,将高级搜索树与深度神经网络结合在一起。这些神经网络通过12个处理层传递对棋盘的描述,处理层则包含数百万个类似于神经的连接点。
其中一个神经网络“决策网络”(policy network)负责选择下一步走法,另一个神经网络“值网络”(“value network)则预测比赛胜利方。谷歌方面用人类围棋高手的三千万步围棋走法训练神经网络,与此同时,AlphaGo也自行研究新战略,在它的神经网络之间运行了数千局围棋,利用反复试验调整连接点,这个流程也称为巩固学习(reinforcement learning)。通过广泛使用Google云平台,完成了大量研究工作。
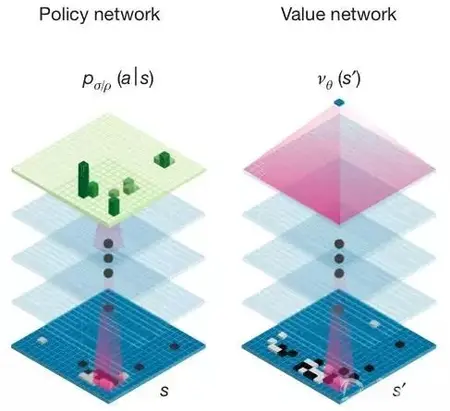
AlphaGo所使用的神经网络结构示意图
征服围棋对于谷歌来说有重要意义。AlphaGo不仅是遵循人工规则的“专家”系统,它还通过“机器学习”自行掌握如何赢得围棋比赛。谷歌方面希望运用这些技术解决现实社会最严峻、最紧迫的问题——从气候建模到复杂的灾难分析。
在具体的机器训练上,决策网络的方式是输入人类围棋专家的比赛,到系统可以预测57%人类行动为止,此前最好成绩是44%。此后AlphaGo通过在神经网络内部进行比赛的方式(可以简单理解成和自己下棋),开始学习自主探索新的围棋策略。目前AlphaGo的决策网络可以击败大多数具有庞大搜寻树的最先进的围棋程序。
值网络也是通过自己和自己下棋的方式来训练。目前值网络可以评估每一步棋能够有多大胜算。这在此前被认为是不可能的。
AlphaGo战绩惊人
实际上,目前AlphaGo已经成为最优秀的人工智能围棋程序。在与其他程序的对弈中,AlphaGo用一台机器就取得了500场的胜利,甚至有过让对手4手后获胜的纪录。去年10月5日-10月9日,谷歌安排AlphaGo与欧洲围棋冠军Fan Hui(樊麾:法国国家围棋队总教练)闭门比赛,谷歌以5-0取胜。

AlphaGo与欧洲围棋冠军樊麾的5局较量
公开的比赛将在今年三月举行,AlphaGo将在韩国首尔与韩国围棋选手李世石九段一决高下,李世石是近10年来获得世界第一头衔最多的棋手,谷歌为此提供了100万美元作为奖金。李世石表示很期待此次对决,并且有信心获得胜利。
值得一提的是,上一次著名的人机对弈要追溯到1997年。当时IBM公司研发的超级计算机“深蓝”战胜了国际象棋冠军卡斯巴罗夫。不过国际象棋的算法要比围棋简单得多。国际象棋中取胜只需“杀死”国王,而围棋中则用数子或比目的方法计算胜负,并不是简单地杀死对方棋子。此前,“深蓝”计算机的设计人2007年发表文章指出,他相信十年内能有超级电脑在围棋上战胜人类。
此外,AlphaGo的发布,也是Deep MInd在2014年1月被谷歌收购以来首次发声。在被收购之前,这家位于伦敦的人工智能领域的公司还获得了特斯拉和SpaceX创始人马斯克的投资。
详解部分技术内容所有完全信息(perfect information)博弈都有一个最优值函数(optimal value function),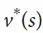 ,它决定了在所有参与博弈的玩家都做出了完美表现的情况下,博弈的结果是什么:无论你在棋盘的哪个位置落子(或者说是状态s)。这些博弈游戏是可能通过在含有大约
,它决定了在所有参与博弈的玩家都做出了完美表现的情况下,博弈的结果是什么:无论你在棋盘的哪个位置落子(或者说是状态s)。这些博弈游戏是可能通过在含有大约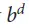 个可能行动序列(其中b是博弈的宽度,也就是在每个位置能够移动的步数,而d是博弈的深度)的搜索树(search tree)上反复计算最优值函数来解决的。在象棋(
个可能行动序列(其中b是博弈的宽度,也就是在每个位置能够移动的步数,而d是博弈的深度)的搜索树(search tree)上反复计算最优值函数来解决的。在象棋(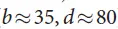 )和围棋之类(
)和围棋之类(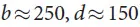 )的大型博弈游戏中,穷尽地搜索是不合适的,但是有效搜索空间是可以通过2种普遍规则得到降低的。首先,搜索的深度可能通过位置估计(position evaluation)来降低:在状态s时截取搜索树,将随后的子树部分(subtree)替换为根据状态s来预测结果的近似的值函数
)的大型博弈游戏中,穷尽地搜索是不合适的,但是有效搜索空间是可以通过2种普遍规则得到降低的。首先,搜索的深度可能通过位置估计(position evaluation)来降低:在状态s时截取搜索树,将随后的子树部分(subtree)替换为根据状态s来预测结果的近似的值函数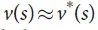 。这种方法使程序在象棋、跳棋、翻转棋(Othello)的游戏中表现超越了人类,但人们认为它无法应用于围棋,因为围棋极其复杂。其次,搜索的宽度可能通过从策略概率
。这种方法使程序在象棋、跳棋、翻转棋(Othello)的游戏中表现超越了人类,但人们认为它无法应用于围棋,因为围棋极其复杂。其次,搜索的宽度可能通过从策略概率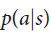 ——一种在位置s时表示出所有可能的行动的概率分布——中抽样行动来降低。比如,蒙特卡洛法通过从策略概率p中为博弈游戏双方抽样长序列的行动来让搜索达到深度的极限、没有任何分支树。将这些模拟结果进行平均,能够提供有效的位置估计,让程序在西洋双陆棋(backgammon)和拼字棋(Scrabble)的游戏中展现出超越人类的表现,在围棋方面也能达到低级业余爱好者水平。
——一种在位置s时表示出所有可能的行动的概率分布——中抽样行动来降低。比如,蒙特卡洛法通过从策略概率p中为博弈游戏双方抽样长序列的行动来让搜索达到深度的极限、没有任何分支树。将这些模拟结果进行平均,能够提供有效的位置估计,让程序在西洋双陆棋(backgammon)和拼字棋(Scrabble)的游戏中展现出超越人类的表现,在围棋方面也能达到低级业余爱好者水平。
详解:AlphaGo 如何在对弈中选择步法
黑色棋子代表AlphaGo正处于下棋状态,对于下面的每一个统计,橙色圆圈代表的是最大值所处的位置。
a.用价值网络(value network)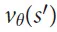 估测根节点s处的所有子节点s’,展示了几个最大的获胜概率估计值。
估测根节点s处的所有子节点s’,展示了几个最大的获胜概率估计值。
b.计算树中从根节点s处伸出来的边(其中每条边用(s,a)来表示)的动作值Q(s,a),仅当(λ=0)时,取价值网络估值的平均值。
c.计算了根位置处伸出的边的动作值Q(s,a),仅当(λ=1)时,取模拟估计值的平均值。
d.直接从SL策略网络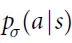 中得出的落子概率,(如果这个概率高于0.1%)则结果以百分比形式表示出来。
中得出的落子概率,(如果这个概率高于0.1%)则结果以百分比形式表示出来。
e.计算了在模拟过程中,从根节点选出的某个动作的频率百分比。
f.表示来自于AlphaGo搜索树的主要变异性(principal variation)(最大访问数路径),移动路径以序号形式呈现出来。
红色圆圈表示AlphaGo选择的步法;白方格表示樊麾作出的回应;樊麾赛后评论说:他特别欣赏AlphaGo预测的(标记为1)的步法。
AlphaGo与樊麾的比赛结果
以编号形式展示了AlphaGo和樊麾进行围棋比赛时各自的落子顺序。棋盘下方成对放置的棋子表示了相同交叉点处的重复落子。每对中的第一个棋子上的数字表示了何时发生重复落子,而落子位置由第二个棋子上的数字决定。(见补充信息 Supplementary Information)
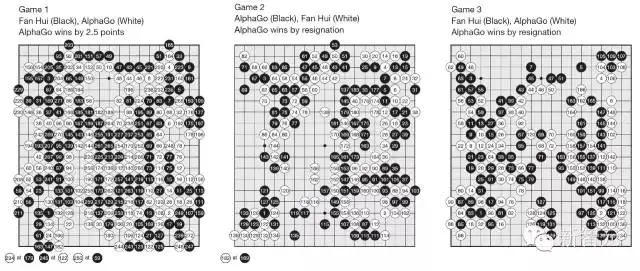
第一盘:AlphaGo 以 2 目半获胜
第二盘:AlphaGo 中盘胜
第三盘:AlphaGo 中盘胜

第四盘:AlphaGo 中盘胜
第五盘:AlphaGo 中盘胜
最终,我们评估了分布式AlphaGo与樊麾的比赛,他是专业2段位选手,2013、14和15年欧洲围棋赛冠军。在2015年10月5日到9日,AlphaGo和樊麾正式比赛了5局。AlphaGo全部获胜。这是第一次一个电脑围棋程序,在没有让子、全尺寸(19X19)的情况下击败人类专业选手,这一成果过去认为至少需要 10 年才能实现。
讨论在我们的工作中,我们开发了围棋程序,它将深度神经网络和树搜索结合起来。这个程序可以达到最强的人类选手的表现,因此完成了一个人工智能“伟大挑战”。我们也为围棋首创了高效步法选择和位置评估函数,这是通过具有创新性地将监督和强化学习两种方法结合起来从而训练深度神经网络。我们也引入了一个新搜索算法,这一算法成功的整合了神经网络评估和蒙特卡洛树模拟算法。我们的程序AlphaGo在高性能树搜索引擎中从一定规模上将这些成分整合在一起。
在和樊麾的比赛中,AlphaGo在评估位置方面要比深蓝与Kasparov4比赛时所评估的位置少几千倍,这是由于我们使用了策略网络更智能地选择那些位置,还使用了价值网络更精确地评估它们,而价值网络更接近人类的下棋方式。另外,深蓝依靠手工设计评估方程,而AlphaGo的神经网络是直接通过纯比赛数据训练,也使用了通用监督和强化学习方法。
围棋代表了很多人工智能所面临的困难:具有挑战性的决策制定任务、难以破解的查找空间问题和优化解决方案如此复杂以至于用一个策略或价值函数几乎无法直接得出。之前在电脑围棋方面的主要突破是引入MCTS,这导致了很多其他领域的相应进步:例如,通用博弈,经典的计划问题,计划只有部分可观测问题、日程安排问题和约束满足问题。通过将策略和价值网络与树搜索结合起来,AlphaGo终于达到了专业围棋水准,让我们看到了希望:在其他看起来无法完成的领域中,AI也可以达到人类级别的表现。
介绍下Google DeepMindGoogle DeepMind 是一家英国人工智能公司,创立于2010年,名为DeepMind Technologies,2014年被谷歌收购,更名为Google DeepMind。
这家公司由Demis Hassabis、Shane Legg和Mustafa Suleyman创立。公司目标是“解决智能”,他们尝试通过合并机器学习最好的方法和系统神经科学来构建强大的通用学习算法。他们试图形式化智能,进而不仅在机器上实现它,还要理解人类大脑。当前公司的焦点在于研究能玩游戏的电脑系统,研究的游戏范围很广,从策略型游戏围棋到电玩游戏。
- Demis Hassabis,人工智能研究人员,神经科学家,电脑游戏设计者,毕业于剑桥大学,并在伦敦大学获得PhD,研究兴趣:机器学习、神经科学。
- Shane Legg,计算学习研究人员,DeepMind创始人,研究兴趣:人工智能、神经网络、人工进化、强化学习和学习理论。
-
Mustafa Suleyman,英国企业家,DeepMind Technologies的共同创始人和产品运营主管,同时也是Reos Partners的共同创始人,被谷歌收购后,他成为Google DeepMind的应用AI部门主管。
