喜闻微软ChakraCore 引擎开源,翻译了一下官方架构文档,原文链接:Architecture Overview · Microsoft/ChakraCore Wiki · GitHub
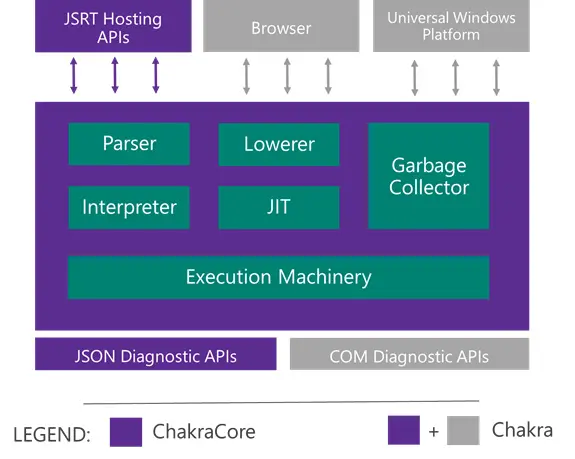
ChakraCore 组成部件
ChakraCore 是一个完整的JavaScript 虚拟机,它拥有着和Chakra 几乎相同的功能与特性。但在它们之间有两个重要的不同点:
- ChakraCore 没有公开Chakra 与浏览器和UWP之间的私有绑定部分。
- 当前Chakra 使用着一套基于COM 的诊断接口,而ChakraCore 将使用一套全新的基于JSON 的诊断接口。这套接口不仅是平台无关的,而且可能成为标准或在长期维护(the long run)中被用来做不同实现之间的互操作。我们还计划将这套接口移植到Chakra 中。
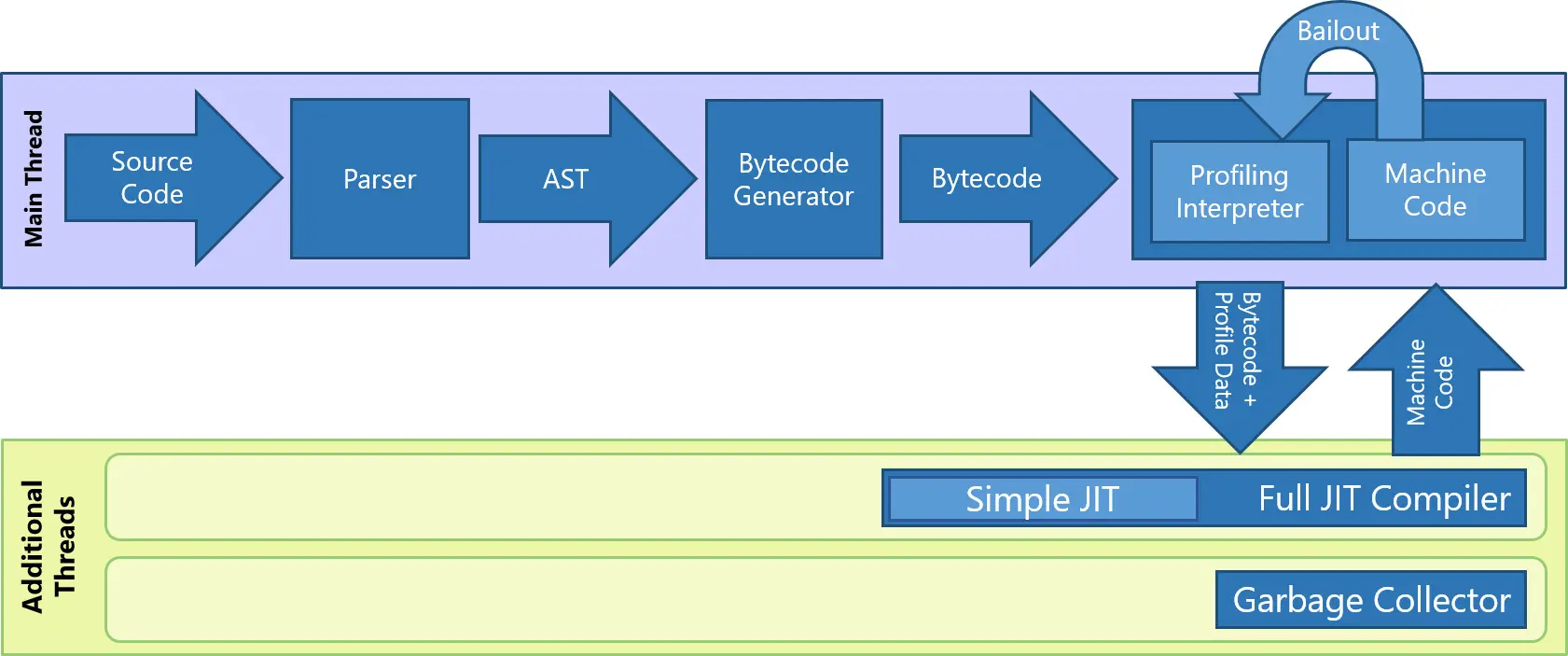
执行管线
ChakraCore 支持一种多级架构,(1)解释器用来快速启动;(2)并行的JIT 编译器用来产生高度优化的代码;(3)以及一个并行的后台GC 来降低停顿,提高app 和网页的UI 响应速度。一旦一个app 或网页的JavaScript 源码进入JavaScript 子系统(即开始运行),ChakraCore 首先进行一次快速的语法解析来报告语法错误。接下来ChakraCore 的所有工作将对每个函数按需执行(as-needed-per-function)。只要有可能,ChakraCore 就会延迟那些暂时不需要的函数的语法解析和抽象语法树(AST)的生成,并且将JIT 编译和垃圾回收等工作推出主线程。这样做的目的仍是为了有效利用硬件资源去保证app 和网页的响应。
当一个函数第一次执行时,ChakraCore 的语法解析器(parser)产生一个抽象语法树(AST)来代表这个函数的源码,随后AST 会被翻译为字节码(bytecode),这些字节码将由ChakraCore 解释器直接执行。在解释执行期间解释器会收集一些程序信息,如类型信息、调用次数,这些信息会被用来帮助JIT 编译器生成高度优化的机器码。当ChakraCore 在解释器中发现一个函数或者循环体(loop-body)背多次执行时,会将其送入后台JIT 编译队列为这个函数生成优化的代码。一旦这些优化代码准备就绪,ChakraCore 就会替换函数和循环的入口到这些新代码,之后的执行将远快于之前的解释执行。
ChakraCore 的后台JIT 编译器借助解释器生成的profile 数据来推断可能出现的模式,从而生成高度优化的本地代码。当得到JavaScript 代码的某些动态特性后,如果代码行为打破了基于profile 的预测,编译出的代码将会被“释出”(bails out)到解释器,进行字节码解释执行以获取更多的profile 数据。为了平衡JIT 编译时间与内存占用,ChakraCore 并不在一个函数每次释出时编译它,而是利用缓存下来的编译结果直到释出次数达到一定的门槛,之后才会迫使代码重新被JIT 编译并且抛弃旧的编译结果。
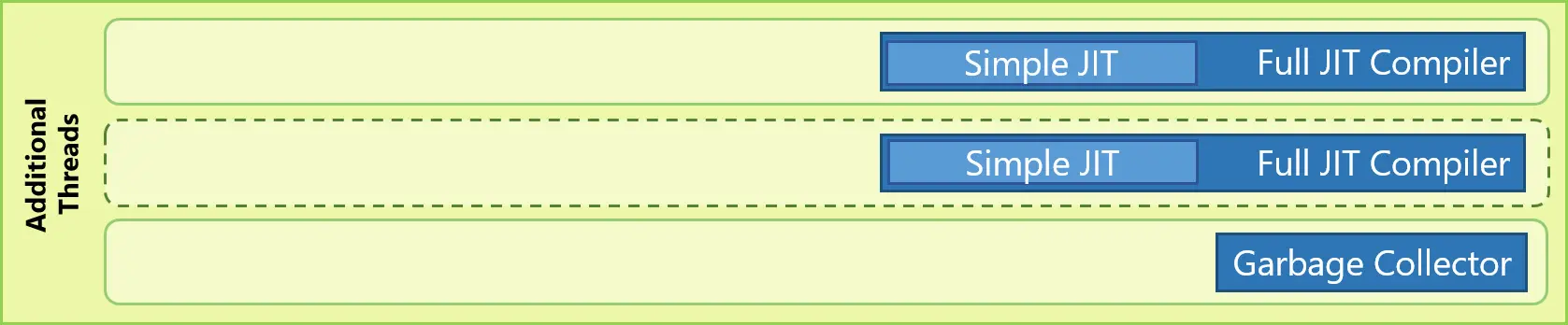
 JIT 编译器
JIT 编译器
ChakraCore 拥有两级JIT 编译器。在同一个后台线程中,ChakraCore 有一个完全JIT 编译器(Full JIT Compiler) 用来产生高度优化的代码;还有一个简单JIT 编译器(Simple JIT Compiler),这是一个有较少优化版本的完全JIT 编译器。在执行管线中,ChkaraCore 首先将解释执行的函数换入简单JIT 编译器,然后才是完全JIT 编译。在大多数情况下,简单JIT 编译耗时少于完全JIT 编译,所以相比单级JIT,这种架构有助于更快启动app 和网页。多一个简单JIT 的另外一个优势是,当"释出“发生时,函数的执行可以更快地从解释切换到简单JIT 编译,直到完全JIT 编译的代码就绪。简单JIT 编译的代码执行管线依然继续收集profile 信息以供完全JIT 编译器使用。
无论何时,只要有潜在的未被利用的硬件资源,ChakraCore 也可为后台JIT 编译器产生多个并行线程。存在多个后台JIT 编译线程时,ChakraCore 的简单JIT 编译和完全JIT 编译的工作都会被分摊到多个编译线程上进行跨线程编译。这有助于在总体上减少JIT 编译延迟。
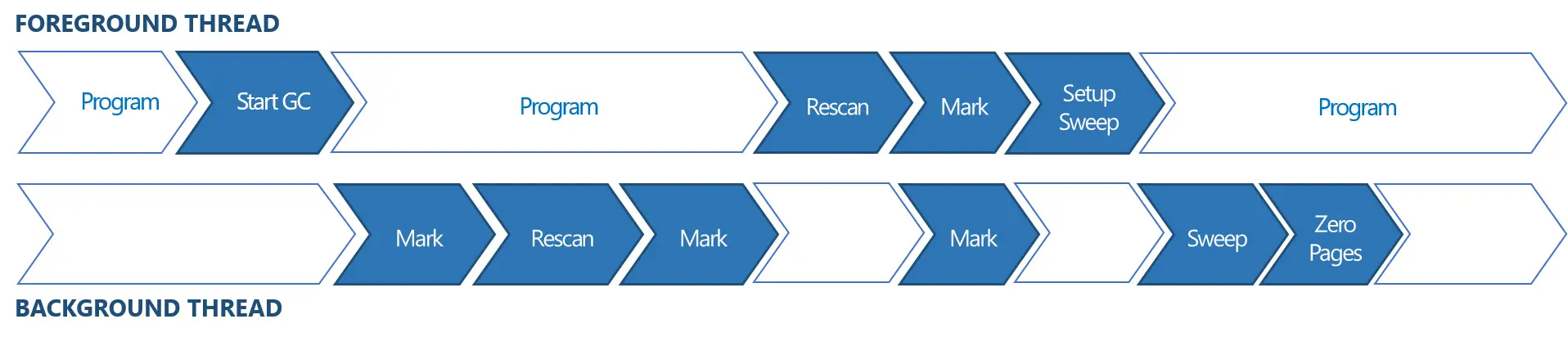
 垃圾回收
垃圾回收
ChakraCore 拥有一个分代式标记清扫垃圾回收器,它支持并行、部分回收。当完全并行GC 被初始化,ChakraCore 的后台GC 会进行一个初始标记阶段,然后重新扫描(rescan)来找出在这个初始标记阶段被主线程修改的对象,随后再运行第二个标记阶段来标记重新扫描时被修改的对象。当第二个标记阶段扫描结束后,主线程暂停执行并启动最终的重新扫描(final rescan),之后最终的标记阶段(final marking pass)会被分解到主线程和已经在执行的GC 线程。最后清扫阶段由后台GC 线程完成,并且将无法到达的(unreachable)的对象重新加入分配池。