

本文系第 12 届 D2 前端大会议题《把前端监控做到极致》的总结文章,你也可以直接查看现场视频 或 PPT。
说到监控,大家第一时间想到的肯定是 Zabbix、Nagios 等各种强大的后端监控服务。诚然,这些强大的平台通过采集服务器以及链路上各种中间件的数据,为我们的应用稳定起到了不可或缺的保驾护航作用。
然而在互联网的另一端,运行在用户终端上的代码却缺少这样强大的监控能力。
对于资深工程师来说,想到或者做出一个前端监控方案并不是什么难事 —— 通过监听全局的 window.onerror 事件捕获到运行时错误,然后上报到采集端,再做一个页面展示数据 —— 看起来确实只需要写一个简单的 CRUD 应用就能搞定。
本文将从 采集、数据处理、分析、报警 4 个维度进一步阐述如何把前端监控做到极致。
小福利
如果你还没有使用前端监控服务,那么可以先看看这个小福利。只用两行代码就能打造一个前端异常实时监控平台,还带报错数统计功能。
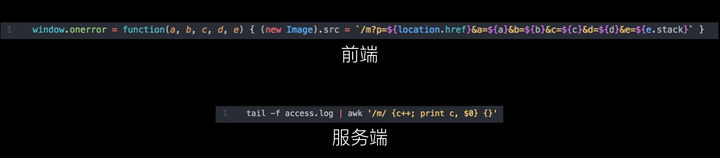
其实现思路正如开题所言,通过 window.onerror 采集到所有的未捕获异常,并通过 new Image 的方式构造一个 404 的 HTTP 请求,最后在服务端实时过滤 access.log 中匹配的请求并计数即可。
实际运行效果如下:

当然,这个监控系统并不能直接应用在生产环境。要让监控真正发挥价值,还需要从采集、处理、分析、报警等多个方面进行优化增强。
采集
Script Error
当我们采集前端报错的时候,第一个遇到的问题就是 Script Error。Script Error 不是一种具体的错误,而是浏览器对跨域错误出于安全机制考虑的一种处理方式。
一个前端错误为什么涉及到了「安全」问题呢?2006 年一位安全研究人员发现第三方脚本可以通过页面中报错信息的不同判断当前用户是否登录了指定的网站,并向 Webkit 项目提出了相关的 issue。7 年之后,各大浏览器厂商基本都支持了这一安全设定。
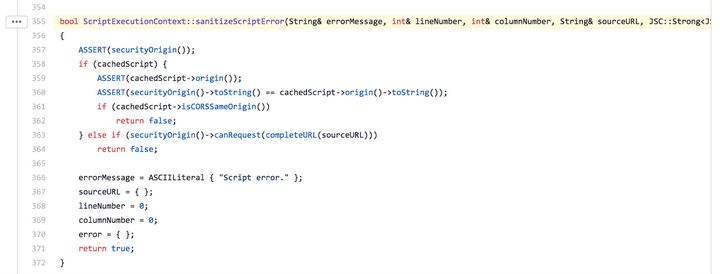
简单的说,如果你的页面和页面中引用的 JavaScript 文件不同源(协议、域名、端口不一致),那么这些脚本抛出的错误都属于跨域错误。那么我们在做前端监控捕获这些错误的时候,应该怎么避免采集到 Script Error 呢?
答案是 crossorigin 属性。这是一个应用在 <script> 标签上的属性,添加之后即可保证即使是跨域错误也能捕获到完整的错误信息。然而事情真的只有这么简单吗?
crossorigin 生效需要服务器端和浏览器端同时支持。服务器端支持比较简单,即返回跨域脚本的服务器(一般为 CDN 服务器)正确的带上 CORS 响应头 —— Access-Control-Allow-Origin: * —— 即可,目前常见的 CDN 服务均支持这一特性。而浏览器端的支持情况就没有这么乐观了。
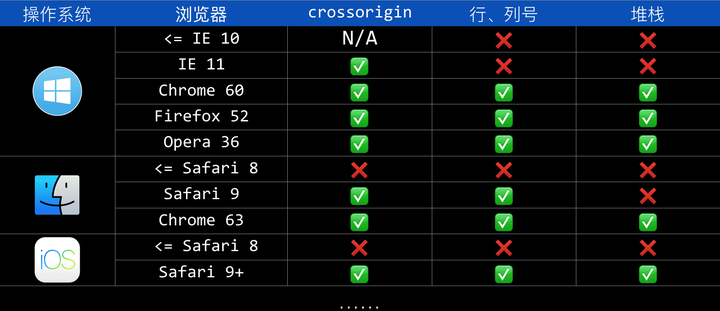
可以看到,crossorigin 前端支持问题的重灾区发生在 IE 和 Safari 上。IE 这个拖油瓶出现问题是情理之中,Safari 在 9.0 之前的版本也不支持 crossorigin 就说不过去了。这也直接导致了许多运行在 iOS Webview 中的业务无法正确捕获到错误。
突破跨域报错限制
那么怎样能突破 crossorigin 的这些限制,尽可能的捕获到更详细的错误呢?
首先最简单也是最直白的方式,就是把页面中所有的跨域资源放在跟页面同样的域下,这样脚本抛出的错误不再是跨域错误,也就不存在 crossorigin 的使用场景了。当然同域化之后也会遇到很多问题,比如无法利用 CDN 的性能、页面单域资源并发加载限制等等。
另一种解决方案是通过 Patch 原生方法来尽可能的捕获到错误,这也是很多监控脚本默认提供的能力。比如说我们可以通过如下代码来 Patch 原生的 setTimeout 方法:
const prevSetTimeout = window.setTimeout;
window.setTimeout = function(callback, timeout) {
const self = this;
return prevSetTimeout(function() {
try {
callback.call(this);
} catch (e) {
// 捕获到详细的错误,在这里处理日志上报等了逻辑
// ...
throw e;
}
}, timeout);
}
同理,我们还可以 Patch 更多的原生方法,比如 Array.prototype.forEach、setInterval、requestAnimationFrame等等。
诚然这种方法能帮我们尽可能捕获到更多异常,但是因为 Patch 了 JavaScript 原生的方法,总是感觉会存在很多的不确定性。
在这里还要提一下去年 QCon 上百姓网前端同学刘小杰提出的一种基于 Babel 的自动添加 try...catch... 的方法,感兴趣的同学可以去深入看看,会有不少启发。
框架层解决方案
在不少现代前端框架中,都提供了框架层的异常处理方案,比如 AngularJS 的 ErrorHandler 和 Vue 的 Vue.config.errorHandler。在这里我们以 React 16 的 componentDidCatch 为例,说明如何使用框架的能力采集错误。
以下是 React 官网中的示例:
class ErrorBoundary extends React.Component {
constructor(props) {
super(props);
this.state = { hasError: false };
}
componentDidCatch(error, info) {
this.setState({ hasError: true });
// 在这里可以做异常的上报
logErrorToMyService(error, info);
}
render() {
if (this.state.hasError) {
return <h1>Something went wrong.</h1>;
}
return this.props.children;
}
}
在使用时,用 ErrorBoundary 包裹你的业务组件即可:
<ErrorBoundary>
<MyWidget />
</ErrorBoundary>
数据处理
传统的监控服务一般都会使用 MySQL 等数据库进行数据持久化,但当数据量指数级增长时,MySQL 这种 OLTP 数据库已经不再适合用来提供监控数据分析服务。
在大数据时代,搭建一套标准化的、针对监控业务的大数据解决方案已经不是什么难事,下图即为一个简单的数据架构示意图:
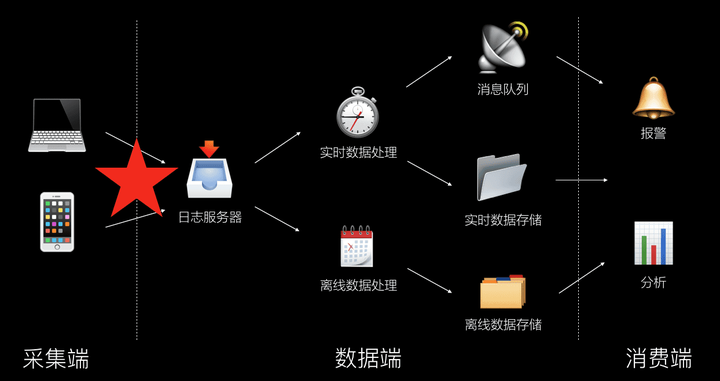
在数据处理过程中,值得一提的是数据采样率的功能设计。
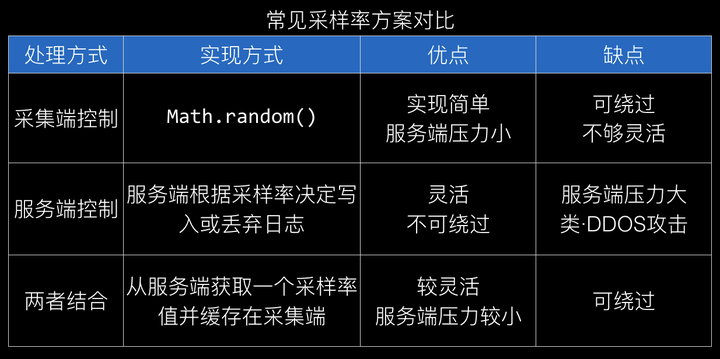
不难看出目前的采样率设计方案都或多或少存在缺陷和妥协,那么有没有一种更优的解决方案呢?
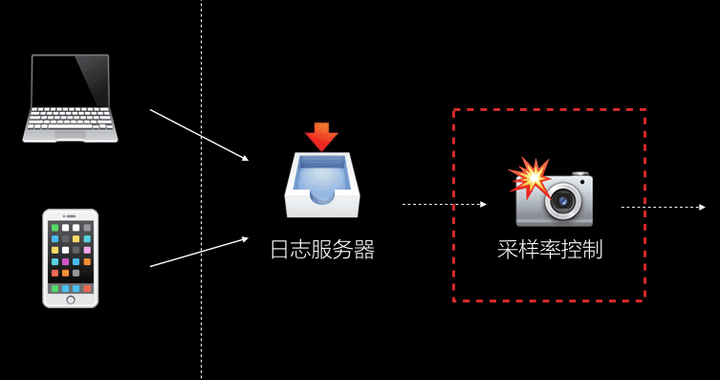
经过大量的实践后,我们认为在日志服务进入数据处理流程之前进行采样率控制是比较理想的方案,理由如下:
- 日志写入成本低
- rotate 机制保证存储不会浪费
- 了解真实打点请求数据量
- 避免采集端绕过采样率限制
分析
当故障发生时
解决了数据采集和处理的问题,我们应该怎么着手进行分析呢?让我们先看一个真实案例:
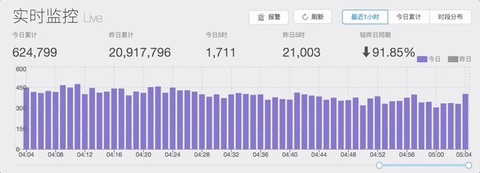
当你吃着火锅唱着歌的时候,突然看到实时监控数据暴涨,这个时候你的第一反应是什么呢?是不是手足无措不知道应该怎么处理?当线上出现紧急状况时,我们的首要思路是找到问题触发的特征,比如是否集在某个页面或者某种浏览器等等。
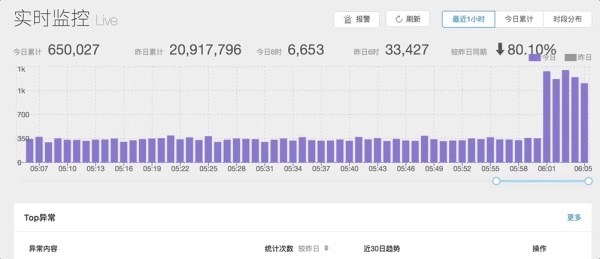
通过监控平台提供的分析功能,初步定为到问题原因后,再进行深入的调查。
报错数高一定是不稳定吗
这里试举两个反例来说明报错数高不一定就是前端不稳定。
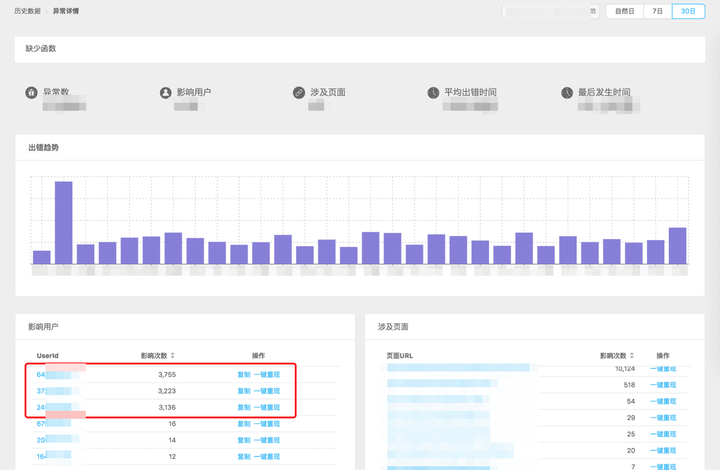
如上图所示,虽然该应用 1 天爆出了上万的 JavaScript 异常,但是我们在分析过程中发现,95% 的报错都集中在 3 个 userId 上。再对这 3 个 userId 进行深入的调查不难发现,这是 3 个爬取数据的爬虫账号,不巧爬数据的脚本写的有 Bug,被前端监控系统忠实的捕捉到了。
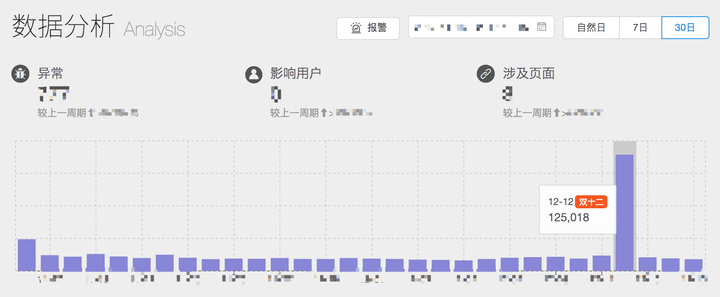
又如上图所示,某天的数据出现暴增,可能是因为页面的访问量出现暴增。
因此我们不难发现,仅仅通过报错数的多少不足以判断系统是否稳定。
异常波动一定有元凶
前端发生故障最常见的原因就是新发布的版本存在 Bug,那么这种问题在监控平台中如何提供分析思路呢?
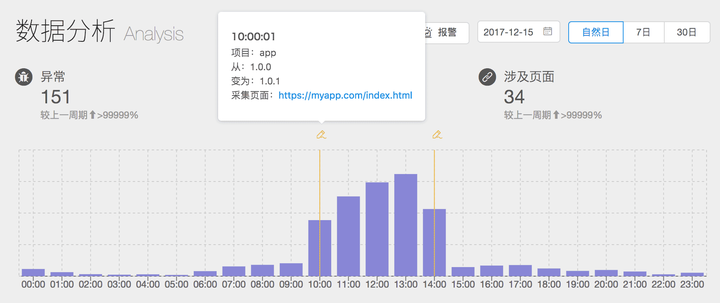
当然,也并不是所有的波动都是前端变更引起。比如说后端接口突然故障,也会导致前端因为无法读取到某个接口结果而报错。
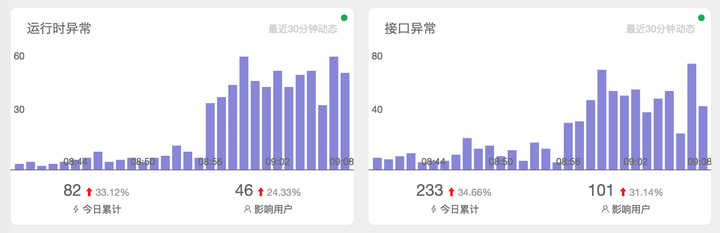
报警
说到报警,绝大多数的监控平台都提供规则报警的能力。然而规则报警最大的问题在于随着业务的不断发展,原本配置的规则将会出现阈值过低或过高的问题。若阈值配置过低,则会产生大量的误报警,继而引起整个监控能力的报警疲劳。
为了解决规则报警的问题,监控平台可以引入一些简单的数学模型来解决时序数据的异常识别工作。以最常见的高斯分布(正态分布)为例,利用 3-sigma 原则可以快速判断某一时刻的报错数是否满足概率分布,继而可以产生报警:
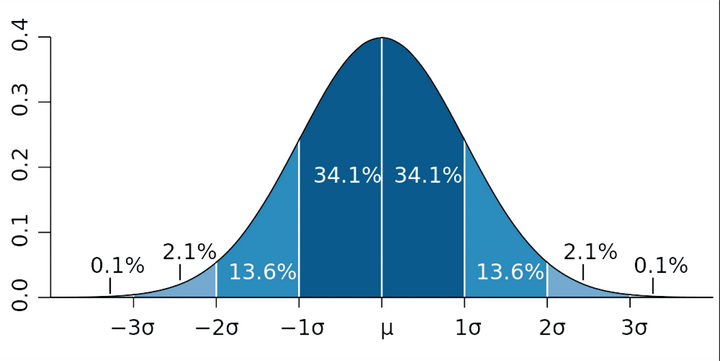
当然,这样的报警模型还存在非常大的优化空间,比如对数据周期性、季节性的处理,又比如过滤掉某些可能影响平均数的极高值等。
结语
前端监控看似简单,但想要监控真正发挥价值,还需要从各个方面进行不断的优化和打磨。当然,最重要的是,要意识到前端监控的必要性,及早开始进行监控,才能更好的避免线上故障的产生。
如果你对我们正在做的事情有兴趣,欢迎加入阿里巴巴和我们一起亲手打造属于自己的数据产品,简历请发 shuangyang.ys@alibaba-inc.com
