

Lucene是apache软件基金会4 jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎(英文与德文两种西方语言)。Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎
全文检索概述
比如,我们一个文件夹中,或者一个磁盘中有很多的文件,记事本、world、Excel、pdf,我们想根据其中的关键词搜索包含的文件。例如,我们输入Lucene,所有内容含有Lucene的文件就会被检查出来。这就是所谓的全文检索。
因此,很容易的我们想到,应该建立一个关键字与文件的相关映射,盗用ppt中的一张图,很明白的解释了这种映射如何实现。
倒排索引

有了这种映射关系,我们就来看看Lucene的架构设计。下面是Lucene的资料必出现的一张图,但也是其精髓的概括。
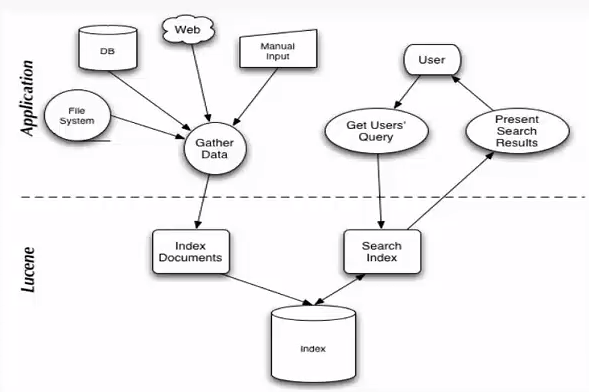
我们可以看到,Lucene的使用主要体现在两个步骤:
1 创建索引,通过IndexWriter对不同的文件进行索引的创建,并将其保存在索引相关文件存储的位置中。
2 通过索引查寻关键字相关文档。
在Lucene中,就是使用这种“倒排索引”的技术,来实现相关映射。
Lucene数学模型
文档、域、词元
文档是Lucene搜索和索引的原子单位,文档为包含一个或者多个域的容器,而域则是依次包含“真正的”被搜索的内容,域值通过分词技术处理,得到多个词元。
For Example,一篇小说(斗破苍穹)信息可以称为一个文档,小说信息又包含多个域,例如:标题(斗破苍穹)、作者、简介、最后更新时间等等,对标题这个域采用分词技术又可以得到一个或者多个词元(斗、破、苍、穹)。
Lucene文件结构
层次结构
index
一个索引存放在一个目录中
segment
一个索引中可以有多个段,段与段之间是独立的,添加新的文档可能产生新段,不同的段可以合并成一个新段
document
文档是创建索引的基本单位,不同的文档保存在不同的段中,一个段可以包含多个文档
field
域,一个文档包含不同类型的信息,可以拆分开索引
term
词,索引的最小单位,是经过词法分析和语言处理后的数据。
正向信息
按照层次依次保存了从索引到词的包含关系:index-->segment-->document-->field-->term。
反向信息
反向信息保存了词典的倒排表映射:term-->document
IndexWriter
lucene中最重要的的类之一,它主要是用来将文档加入索引,同时控制索引过程中的一些参数使用。
Analyzer
分析器,主要用于分析搜索引擎遇到的各种文本。常用的有StandardAnalyzer分析器,StopAnalyzer分析器,WhitespaceAnalyzer分析器等。
Directory
索引存放的位置;lucene提供了两种索引存放的位置,一种是磁盘,一种是内存。一般情况将索引放在磁盘上;相应地lucene提供了FSDirectory和RAMDirectory两个类。
Document
文档;Document相当于一个要进行索引的单元,任何可以想要被索引的文件都必须转化为Document对象才能进行索引。
Field
字段。
IndexSearcher
是lucene中最基本的检索工具,所有的检索都会用到IndexSearcher工具;
Query
查询,lucene中支持模糊查询,语义查询,短语查询,组合查询等等,如有TermQuery,BooleanQuery,RangeQuery,WildcardQuery等一些类。
QueryParser
是一个解析用户输入的工具,可以通过扫描用户输入的字符串,生成Query对象。
Hits
在搜索完成之后,需要把搜索结果返回并显示给用户,只有这样才算是完成搜索的目的。在lucene中,搜索的结果的集合是用Hits类的实例来表示的。
测试用例
Github 代码
代码我已放到 Github ,导入spring-boot-lucene-demo 项目
github spring-boot-lucene-demo
添加依赖
<!--对分词索引查询解析-->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-queryparser</artifactId>
<version>7.1.0</version>
</dependency>
<!--高亮 -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-highlighter</artifactId>
<version>7.1.0</version>
</dependency>
<!--smartcn 中文分词器 SmartChineseAnalyzer smartcn分词器 需要lucene依赖 且和lucene版本同步-->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-smartcn</artifactId>
<version>7.1.0</version>
</dependency>
<!--ik-analyzer 中文分词器-->
<dependency>
<groupId>cn.bestwu</groupId>
<artifactId>ik-analyzers</artifactId>
<version>5.1.0</version>
</dependency>
<!--MMSeg4j 分词器-->
<dependency>
<groupId>com.chenlb.mmseg4j</groupId>
<artifactId>mmseg4j-solr</artifactId>
<version>2.4.0</version>
<exclusions>
<exclusion>
<groupId>org.apache.solr</groupId>
<artifactId>solr-core</artifactId>
</exclusion>
</exclusions>
</dependency>配置 lucene
private Directory directory;
private IndexReader indexReader;
private IndexSearcher indexSearcher;
@Before
public void setUp() throws IOException {
//索引存放的位置,设置在当前目录中
directory = FSDirectory.open(Paths.get("indexDir/"));
//创建索引的读取器
indexReader = DirectoryReader.open(directory);
//创建一个索引的查找器,来检索索引库
indexSearcher = new IndexSearcher(indexReader);
}
@After
public void tearDown() throws Exception {
indexReader.close();
}
**
* 执行查询,并打印查询到的记录数
*
* @param query
* @throws IOException
*/
public void executeQuery(Query query) throws IOException {
TopDocs topDocs = indexSearcher.search(query, 100);
//打印查询到的记录数
System.out.println("总共查询到" + topDocs.totalHits + "个文档");
for (ScoreDoc scoreDoc : topDocs.scoreDocs) {
//取得对应的文档对象
Document document = indexSearcher.doc(scoreDoc.doc);
System.out.println("id:" + document.get("id"));
System.out.println("title:" + document.get("title"));
System.out.println("content:" + document.get("content"));
}
}
/**
* 分词打印
*
* @param analyzer
* @param text
* @throws IOException
*/
public void printAnalyzerDoc(Analyzer analyzer, String text) throws IOException {
TokenStream tokenStream = analyzer.tokenStream("content", new StringReader(text));
CharTermAttribute charTermAttribute = tokenStream.addAttribute(CharTermAttribute.class);
try {
tokenStream.reset();
while (tokenStream.incrementToken()) {
System.out.println(charTermAttribute.toString());
}
tokenStream.end();
} finally {
tokenStream.close();
analyzer.close();
}
}
创建索引
@Test
public void indexWriterTest() throws IOException {
long start = System.currentTimeMillis();
//索引存放的位置,设置在当前目录中
Directory directory = FSDirectory.open(Paths.get("indexDir/"));
//在 6.6 以上版本中 version 不再是必要的,并且,存在无参构造方法,可以直接使用默认的 StandardAnalyzer 分词器。
Version version = Version.LUCENE_7_1_0;
//Analyzer analyzer = new StandardAnalyzer(); // 标准分词器,适用于英文
//Analyzer analyzer = new SmartChineseAnalyzer();//中文分词
//Analyzer analyzer = new ComplexAnalyzer();//中文分词
//Analyzer analyzer = new IKAnalyzer();//中文分词
Analyzer analyzer = new IKAnalyzer();//中文分词
//创建索引写入配置
IndexWriterConfig indexWriterConfig = new IndexWriterConfig(analyzer);
//创建索引写入对象
IndexWriter indexWriter = new IndexWriter(directory, indexWriterConfig);
//创建Document对象,存储索引
Document doc = new Document();
int id = 1;
//将字段加入到doc中
doc.add(new IntPoint("id", id));
doc.add(new StringField("title", "Spark", Field.Store.YES));
doc.add(new TextField("content", "Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎", Field.Store.YES));
doc.add(new StoredField("id", id));
//将doc对象保存到索引库中
indexWriter.addDocument(doc);
indexWriter.commit();
//关闭流
indexWriter.close();
long end = System.currentTimeMillis();
System.out.println("索引花费了" + (end - start) + " 毫秒");
}响应
17:58:14.655 [main] DEBUG org.wltea.analyzer.dic.Dictionary - 加载扩展词典:ext.dic
17:58:14.660 [main] DEBUG org.wltea.analyzer.dic.Dictionary - 加载扩展停止词典:stopword.dic
索引花费了879 毫秒删除文档
@Test
public void deleteDocumentsTest() throws IOException {
//Analyzer analyzer = new StandardAnalyzer(); // 标准分词器,适用于英文
//Analyzer analyzer = new SmartChineseAnalyzer();//中文分词
//Analyzer analyzer = new ComplexAnalyzer();//中文分词
//Analyzer analyzer = new IKAnalyzer();//中文分词
Analyzer analyzer = new IKAnalyzer();//中文分词
//创建索引写入配置
IndexWriterConfig indexWriterConfig = new IndexWriterConfig(analyzer);
//创建索引写入对象
IndexWriter indexWriter = new IndexWriter(directory, indexWriterConfig);
// 删除title中含有关键词“Spark”的文档
long count = indexWriter.deleteDocuments(new Term("title", "Spark"));
// 除此之外IndexWriter还提供了以下方法:
// DeleteDocuments(Query query):根据Query条件来删除单个或多个Document
// DeleteDocuments(Query[] queries):根据Query条件来删除单个或多个Document
// DeleteDocuments(Term term):根据Term来删除单个或多个Document
// DeleteDocuments(Term[] terms):根据Term来删除单个或多个Document
// DeleteAll():删除所有的Document
//使用IndexWriter进行Document删除操作时,文档并不会立即被删除,而是把这个删除动作缓存起来,当IndexWriter.Commit()或IndexWriter.Close()时,删除操作才会被真正执行。
indexWriter.commit();
indexWriter.close();
System.out.println("删除完成:" + count);
}
响应
删除完成:1更新文档
/**
* 测试更新
* 实际上就是删除后新增一条
*
* @throws IOException
*/
@Test
public void updateDocumentTest() throws IOException {
//Analyzer analyzer = new StandardAnalyzer(); // 标准分词器,适用于英文
//Analyzer analyzer = new SmartChineseAnalyzer();//中文分词
//Analyzer analyzer = new ComplexAnalyzer();//中文分词
//Analyzer analyzer = new IKAnalyzer();//中文分词
Analyzer analyzer = new IKAnalyzer();//中文分词
//创建索引写入配置
IndexWriterConfig indexWriterConfig = new IndexWriterConfig(analyzer);
//创建索引写入对象
IndexWriter indexWriter = new IndexWriter(directory, indexWriterConfig);
Document doc = new Document();
int id = 1;
doc.add(new IntPoint("id", id));
doc.add(new StringField("title", "Spark", Field.Store.YES));
doc.add(new TextField("content", "Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎", Field.Store.YES));
doc.add(new StoredField("id", id));
long count = indexWriter.updateDocument(new Term("id", "1"), doc);
System.out.println("更新文档:" + count);
indexWriter.close();
}响应
更新文档:1按词条搜索
/**
* 按词条搜索
* <p>
* TermQuery是最简单、也是最常用的Query。TermQuery可以理解成为“词条搜索”,
* 在搜索引擎中最基本的搜索就是在索引中搜索某一词条,而TermQuery就是用来完成这项工作的。
* 在Lucene中词条是最基本的搜索单位,从本质上来讲一个词条其实就是一个名/值对。
* 只不过这个“名”是字段名,而“值”则表示字段中所包含的某个关键字。
*
* @throws IOException
*/
@Test
public void termQueryTest() throws IOException {
String searchField = "title";
//这是一个条件查询的api,用于添加条件
TermQuery query = new TermQuery(new Term(searchField, "Spark"));
//执行查询,并打印查询到的记录数
executeQuery(query);
}响应
总共查询到1个文档
id:1
title:Spark
content:Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎!多条件查询
/**
* 多条件查询
*
* BooleanQuery也是实际开发过程中经常使用的一种Query。
* 它其实是一个组合的Query,在使用时可以把各种Query对象添加进去并标明它们之间的逻辑关系。
* BooleanQuery本身来讲是一个布尔子句的容器,它提供了专门的API方法往其中添加子句,
* 并标明它们之间的关系,以下代码为BooleanQuery提供的用于添加子句的API接口:
*
* @throws IOException
*/
@Test
public void BooleanQueryTest() throws IOException {
String searchField1 = "title";
String searchField2 = "content";
Query query1 = new TermQuery(new Term(searchField1, "Spark"));
Query query2 = new TermQuery(new Term(searchField2, "Apache"));
BooleanQuery.Builder builder = new BooleanQuery.Builder();
// BooleanClause用于表示布尔查询子句关系的类,
// 包 括:
// BooleanClause.Occur.MUST,
// BooleanClause.Occur.MUST_NOT,
// BooleanClause.Occur.SHOULD。
// 必须包含,不能包含,可以包含三种.有以下6种组合:
//
// 1.MUST和MUST:取得连个查询子句的交集。
// 2.MUST和MUST_NOT:表示查询结果中不能包含MUST_NOT所对应得查询子句的检索结果。
// 3.SHOULD与MUST_NOT:连用时,功能同MUST和MUST_NOT。
// 4.SHOULD与MUST连用时,结果为MUST子句的检索结果,但是SHOULD可影响排序。
// 5.SHOULD与SHOULD:表示“或”关系,最终检索结果为所有检索子句的并集。
// 6.MUST_NOT和MUST_NOT:无意义,检索无结果。
builder.add(query1, BooleanClause.Occur.SHOULD);
builder.add(query2, BooleanClause.Occur.SHOULD);
BooleanQuery query = builder.build();
//执行查询,并打印查询到的记录数
executeQuery(query);
}响应
总共查询到1个文档
id:1
title:Spark
content:Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎!匹配前缀
/**
* 匹配前缀
* <p>
* PrefixQuery用于匹配其索引开始以指定的字符串的文档。就是文档中存在xxx%
* <p>
*
* @throws IOException
*/
@Test
public void prefixQueryTest() throws IOException {
String searchField = "title";
Term term = new Term(searchField, "Spar");
Query query = new PrefixQuery(term);
//执行查询,并打印查询到的记录数
executeQuery(query);
}响应
总共查询到1个文档
id:1
title:Spark
content:Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎!短语搜索
/**
* 短语搜索
* <p>
* 所谓PhraseQuery,就是通过短语来检索,比如我想查“big car”这个短语,
* 那么如果待匹配的document的指定项里包含了"big car"这个短语,
* 这个document就算匹配成功。可如果待匹配的句子里包含的是“big black car”,
* 那么就无法匹配成功了,如果也想让这个匹配,就需要设定slop,
* 先给出slop的概念:slop是指两个项的位置之间允许的最大间隔距离
*
* @throws IOException
*/
@Test
public void phraseQueryTest() throws IOException {
String searchField = "content";
String query1 = "apache";
String query2 = "spark";
PhraseQuery.Builder builder = new PhraseQuery.Builder();
builder.add(new Term(searchField, query1));
builder.add(new Term(searchField, query2));
builder.setSlop(0);
PhraseQuery phraseQuery = builder.build();
//执行查询,并打印查询到的记录数
executeQuery(phraseQuery);
}响应
总共查询到1个文档
id:1
title:Spark
content:Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎!相近词语搜索
/**
* 相近词语搜索
* <p>
* FuzzyQuery是一种模糊查询,它可以简单地识别两个相近的词语。
*
* @throws IOException
*/
@Test
public void fuzzyQueryTest() throws IOException {
String searchField = "content";
Term t = new Term(searchField, "大规模");
Query query = new FuzzyQuery(t);
//执行查询,并打印查询到的记录数
executeQuery(query);
}响应
总共查询到1个文档
id:1
title:Spark
content:Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎!通配符搜索
/**
* 通配符搜索
* <p>
* Lucene也提供了通配符的查询,这就是WildcardQuery。
* 通配符“?”代表1个字符,而“*”则代表0至多个字符。
*
* @throws IOException
*/
@Test
public void wildcardQueryTest() throws IOException {
String searchField = "content";
Term term = new Term(searchField, "大*规模");
Query query = new WildcardQuery(term);
//执行查询,并打印查询到的记录数
executeQuery(query);
}响应
总共查询到1个文档
id:1
title:Spark
content:Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎!分词查询
/**
* 分词查询
*
* @throws IOException
* @throws ParseException
*/
@Test
public void queryParserTest() throws IOException, ParseException {
//Analyzer analyzer = new StandardAnalyzer(); // 标准分词器,适用于英文
//Analyzer analyzer = new SmartChineseAnalyzer();//中文分词
//Analyzer analyzer = new ComplexAnalyzer();//中文分词
//Analyzer analyzer = new IKAnalyzer();//中文分词
Analyzer analyzer = new IKAnalyzer();//中文分词
String searchField = "content";
//指定搜索字段和分析器
QueryParser parser = new QueryParser(searchField, analyzer);
//用户输入内容
Query query = parser.parse("计算引擎");
//执行查询,并打印查询到的记录数
executeQuery(query);
}响应
总共查询到1个文档
id:1
title:Spark
content:Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎!多个 Field 分词查询
/**
* 多个 Field 分词查询
*
* @throws IOException
* @throws ParseException
*/
@Test
public void multiFieldQueryParserTest() throws IOException, ParseException {
//Analyzer analyzer = new StandardAnalyzer(); // 标准分词器,适用于英文
//Analyzer analyzer = new SmartChineseAnalyzer();//中文分词
//Analyzer analyzer = new ComplexAnalyzer();//中文分词
//Analyzer analyzer = new IKAnalyzer();//中文分词
Analyzer analyzer = new IKAnalyzer();//中文分词
String[] filedStr = new String[]{"title", "content"};
//指定搜索字段和分析器
QueryParser queryParser = new MultiFieldQueryParser(filedStr, analyzer);
//用户输入内容
Query query = queryParser.parse("Spark");
//执行查询,并打印查询到的记录数
executeQuery(query);
}响应
总共查询到1个文档
id:1
title:Spark
content:Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎!中文分词器
/**
* IKAnalyzer 中文分词器
* SmartChineseAnalyzer smartcn分词器 需要lucene依赖 且和lucene版本同步
*
* @throws IOException
*/
@Test
public void AnalyzerTest() throws IOException {
//Analyzer analyzer = new StandardAnalyzer(); // 标准分词器,适用于英文
//Analyzer analyzer = new SmartChineseAnalyzer();//中文分词
//Analyzer analyzer = new ComplexAnalyzer();//中文分词
//Analyzer analyzer = new IKAnalyzer();//中文分词
Analyzer analyzer = null;
String text = "Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎";
analyzer = new IKAnalyzer();//IKAnalyzer 中文分词
printAnalyzerDoc(analyzer, text);
System.out.println();
analyzer = new ComplexAnalyzer();//MMSeg4j 中文分词
printAnalyzerDoc(analyzer, text);
System.out.println();
analyzer = new SmartChineseAnalyzer();//Lucene 中文分词器
printAnalyzerDoc(analyzer, text);
}三种分词响应
apache
spark
专为
大规模
规模
模数
数据处理
数据
处理
而设
设计
快速
通用
计算
引擎apache
spark
是
专为
大规模
数据处理
而
设计
的
快速
通用
的
计算
引擎apach
spark
是
专
为
大规模
数据
处理
而
设计
的
快速
通用
的
计算
引擎高亮处理
/**
* 高亮处理
*
* @throws IOException
*/
@Test
public void HighlighterTest() throws IOException, ParseException, InvalidTokenOffsetsException {
//Analyzer analyzer = new StandardAnalyzer(); // 标准分词器,适用于英文
//Analyzer analyzer = new SmartChineseAnalyzer();//中文分词
//Analyzer analyzer = new ComplexAnalyzer();//中文分词
//Analyzer analyzer = new IKAnalyzer();//中文分词
Analyzer analyzer = new IKAnalyzer();//中文分词
String searchField = "content";
String text = "Apache Spark 大规模数据处理";
//指定搜索字段和分析器
QueryParser parser = new QueryParser(searchField, analyzer);
//用户输入内容
Query query = parser.parse(text);
TopDocs topDocs = indexSearcher.search(query, 100);
// 关键字高亮显示的html标签,需要导入lucene-highlighter-xxx.jar
SimpleHTMLFormatter simpleHTMLFormatter = new SimpleHTMLFormatter("<span style='color:red'>", "</span>");
Highlighter highlighter = new Highlighter(simpleHTMLFormatter, new QueryScorer(query));
for (ScoreDoc scoreDoc : topDocs.scoreDocs) {
//取得对应的文档对象
Document document = indexSearcher.doc(scoreDoc.doc);
// 内容增加高亮显示
TokenStream tokenStream = analyzer.tokenStream("content", new StringReader(document.get("content")));
String content = highlighter.getBestFragment(tokenStream, document.get("content"));
System.out.println(content);
}
}
响应
<span style='color:red'>Apache</span> <span style='color:red'>Spark</span> 是专为<span style='color:red'>大规模数据处理</span>而设计的快速通用的计算引擎!代码我已放到 Github ,导入spring-boot-lucene-demo 项目
github spring-boot-lucene-demo
- 作者:Peng Lei
- 出处:Segment Fault PengLei `Blog 专栏
- 版权归作者所有,转载请注明出处
