

昨天 Google Research 发了一篇博客,当天美光跌 3%、西部数据跌 4.7%、闪迪暴跌 5.7%。今天 A 股开盘,兆易创新跌停,佰维存储跌超 10%。一篇学术论文,凭什么让全球存储芯片板块集体跳水?
先说结论:这篇论文做了什么?
一句话:Google 找到了一种方法,让 AI 运行时的"记忆"只占原来的六分之一,而且效果完全不变。
这就好比你家冰箱突然升级了,原来只能存 100 瓶水的空间,现在能存 600 瓶,而且每瓶水的品质一模一样。
这项技术叫 TurboQuant,论文将在 ICLR 2026(机器学习领域顶会)上正式发表。
为什么芯片股会跌?
要理解这个,先要知道 AI 公司现在最大的"痛"是什么。
AI 的隐藏成本:不是训练,是推理
大家都知道训练 GPT-5 很贵——据说花了几十亿美元。但很多人不知道的是,运行 AI 比训练 AI 更烧钱。
训练是一次性的,但"推理"(就是你每天跟 ChatGPT、Claude、Gemini 聊天时背后发生的事)是 7×24 小时不间断的。全球几亿用户,每个人的每次提问都要消耗 GPU 算力和内存。
训练成本:一次性投入(比如 10 亿美元训练一个模型)
推理成本:持续投入(每天服务几亿用户,每天都在烧钱)
Meta:2026 年资本开支预算 $270 亿
Google:数据中心投入 $500 亿+
微软:$800 亿+
瓶颈在哪?KV Cache(键值缓存)
当你跟 AI 对话时,AI 需要"记住"你之前说了什么。这个记忆就存储在一个叫做 KV Cache(键值缓存) 的地方。
问题是:对话越长,这个缓存就越大,GPU 内存就越紧张。
打个比方:
- 你跟 AI 聊了 1000 个字 → 缓存占 1GB 内存
- 你让 AI 读一整本书(128K 上下文)→ 缓存占 几十 GB 内存
一张顶级 H100 显卡只有 80GB 显存。光是一个用户的长对话就能吃掉一大半。所以 AI 公司需要疯狂买显卡和内存——这就是为什么英伟达和存储芯片公司过去两年涨疯了。
TurboQuant 的颠覆:同样的内存,服务 6 倍用户
TurboQuant 把 KV Cache 从 16 位压缩到 3 位——缩小了 6 倍——而且准确率完全不变。
这意味着:
- 原来 1 张 GPU 只能服务 100 个用户 → 现在能服务 600 个
- 原来需要 6 台服务器 → 现在 1 台就够了
- 原来一年的推理成本 1 亿 → 现在可能只要 2000 万
华尔街一算账:如果所有 AI 公司都用这个技术,那它们需要买的内存芯片可能少了一大半。
存储芯片公司的股价,自然就崩了。
普通人能听懂的技术解析
TurboQuant 到底做了什么"魔法"?我用一个搬家的类比来解释。
传统压缩:搬家时每个箱子都要贴标签
想象你要搬家,有 1000 本书要打包。传统方法是:
- 每 10 本书装一个箱子
- 每个箱子外面贴一张"详细清单"(列出里面每本书的名字、页数、重量)
- 清单本身也占空间——100 个箱子就有 100 张清单
这就是传统量化方法的问题:压缩数据本身省了空间,但压缩过程中产生的"标签"(规范化常数)又把空间吃回来了。号称压缩到 3 位,实际上因为标签的存在,相当于 4-5 位。
TurboQuant 的办法:换一种打包方式,根本不需要标签
TurboQuant 分两步走:
第一步:PolarQuant(极坐标变换)
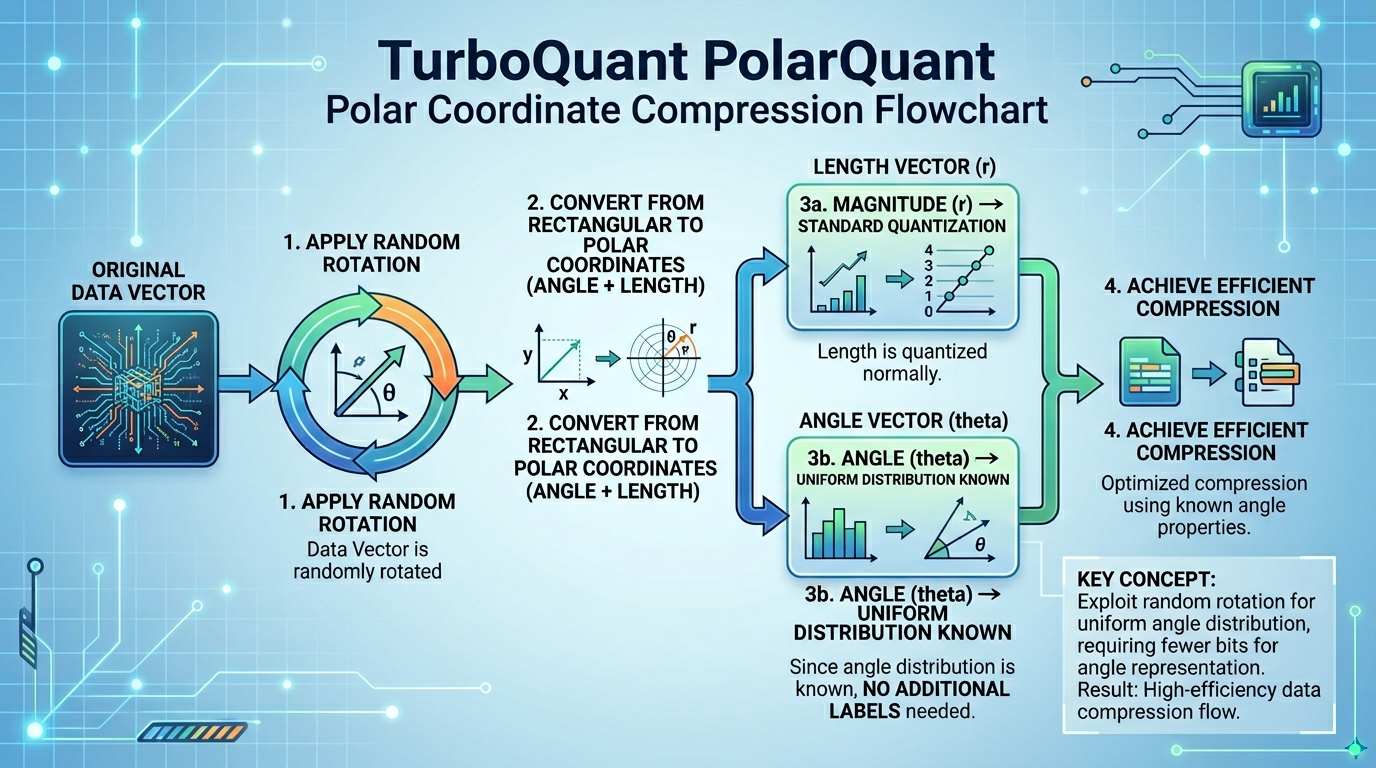
传统方法用"东走 3 步、北走 4 步"来描述位置——每个数字的范围都不确定,需要额外标签来记录范围。
PolarQuant 换了一种描述方式:"总共走 5 步,方向 37 度"。角度的范围是固定的(0° 到 360°),不需要额外标签来记录范围。
一个类比:就像国际象棋用"e4"(列+行)两个字符就能描述任意位置,而不需要每次都说"从左数第 5 列,从下数第 4 行"。
第二步:QJL(1 比特纠错)
第一步压缩后会有微小误差。QJL 用一种数学技巧(Johnson-Lindenstrauss 变换),只用 1 个比特(就是一个 +1 或 -1)就能把这个误差消除掉。
类比:就像 GPS 定位有个 3 米的误差,QJL 相当于一个"微调信号",只用一个开关(往左/往右)就把你修正到精确位置。
两步合起来的效果
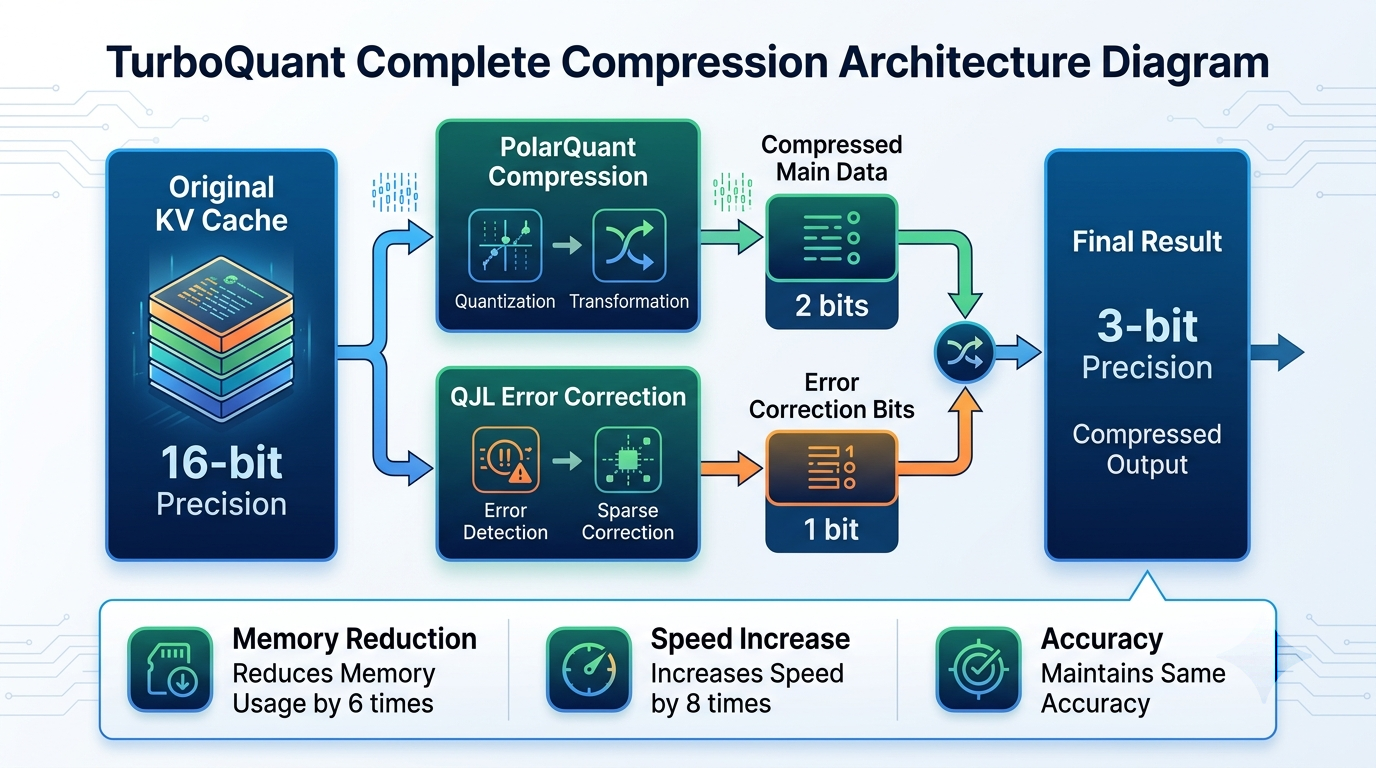
用 3 位就做到了别人 16 位才能做到的事。而且不需要重新训练模型,直接拿来就能用。
影响有多大?三个层面
1. 对 AI 公司:推理成本暴降
VentureBeat 的报道标题是:"Google 新算法让 AI 内存速度提升 8 倍,成本削减 50% 以上"。
这不是夸张。在 H100 GPU 上实测,4 位 TurboQuant 计算注意力的速度是 32 位原版的 8 倍。这意味着同一张卡能同时处理 8 倍的请求量。
2. 对硬件行业:格局可能改写
富国银行分析师指出:TurboQuant 直接冲击了 AI 系统的内存成本曲线。如果大规模采用,整个行业需要采购的内存芯片数量可能大幅减少。
但也有人持谨慎态度:压缩算法早就有,为什么之前没改变采购量?原因是杰文斯悖论——当某项资源的使用效率提升时,人们不会少用它,反而会用得更多。存储变便宜了,大家可能会选择让 AI 处理更长的文档、更多的用户,而不是少买芯片。
3. 对普通用户:更便宜、更快的 AI
这才是最直接的影响:
- 更长的上下文窗口:以前 128K 就是极限,以后可能 1M 成为标配
- 更快的响应速度:同样的硬件,处理速度快 8 倍
- 更便宜的订阅价格:AI 公司成本降低,最终会传导到定价
不确定性在哪?
别急着下结论,有几个问题还没答案:
-
是不是只有 Google 能用? 论文用的是开源模型(Gemma、Llama、Mistral),理论上所有人都能用。但实际工程化落地还需要时间。
-
生产环境能复现吗? 实验室 benchmark 和真实生产环境之间往往有差距。ICLR 2026(今年 4 月)会有更多同行评审。
-
杰文斯悖论:计算机历史上,每次效率提升都没有让硬件需求减少,反而催生了更多应用。AI 也可能如此——内存效率提高 6 倍,大家可能选择把上下文扩大 6 倍,而不是少买 6 倍的内存。
写在最后
TurboQuant 是那种"一看论文摘要就知道会炸"的工作。它不是小修小补,而是从数学根基上找到了一条近乎最优的压缩路径——理论上已经接近信息论的下界了。
这意味着,在这条路上,后人很难再做出本质性的超越。
对于关注 AI 的普通人来说,记住一件事就够了:AI 正在变得越来越便宜,而这个趋势不会停。 TurboQuant 只是最新的一个里程碑。
📎 延伸阅读
- Google Research 原文博客(英文)
- TurboQuant 论文原文(ICLR 2026)
- 21 经济网:谷歌新算法声称能"6 倍压缩 KV 缓存",存储芯片板块低开低走
📬 想获取 TurboQuant 论文的中文翻译摘要 + KV Cache 技术入门资料包?关注我,私信「TurboQuant」即可获取。
