

你的 AI Agent 正在"浪费"每一次对话:OpenClaw-RL 如何让 Agent 越用越聪明
每天,全球数以亿计的 AI Agent 正在与用户进行交互。
它们回答问题、执行代码、操作 GUI、完成各种任务。但你可能没有意识到:这些 Agent 正在系统性地丢弃它们最宝贵的学习资源——你与它们的每一次互动。
当你对 Agent 的回答不满意,重新问了一遍;当你说"不是这样,你应该先检查文件再修改";当终端返回一个报错信息……这些反馈本应成为 Agent 进化的养料,却被当作"下一步的上下文"用完即弃。
来自普林斯顿大学的研究团队提出了 OpenClaw-RL,一个让 Agent 仅通过正常使用就能持续进化的框架。核心理念简单到令人拍案:每一次交互产生的"下一状态信号",都是免费的训练数据。
被忽视的金矿:Agent 浪费了什么?
研究团队敏锐地识别出两种被系统性浪费的信号:
浪费 1:评价性信号(Evaluative Signals)
想象一下:
- 用户问了一个问题,Agent 回答后,用户重新问了一遍 → 这说明答案不满意
- Agent 执行代码,终端返回 "Test Passed" → 这说明操作成功
- GUI Agent 点击了一个按钮,界面没有任何变化 → 这说明操作可能错了
这些"下一状态"本身就是天然的奖励信号,根本不需要人工标注!但现有系统要么完全忽略它们,要么只在离线数据集上使用。
浪费 2:指导性信号(Directive Signals)
比评价更宝贵的是指导。
当用户说:"你应该先检查文件再编辑",这句话不仅告诉 Agent"你错了",还告诉它具体哪里错了、应该怎么改。同样,一个详细的代码报错信息往往隐含着修复方向。
现有的强化学习方法(如 RLHF、DPO)使用标量奖励,把这些丰富的语义信息压缩成一个数字。这就像老师只告诉学生"60分",却不解释哪道题错了、怎么改正。
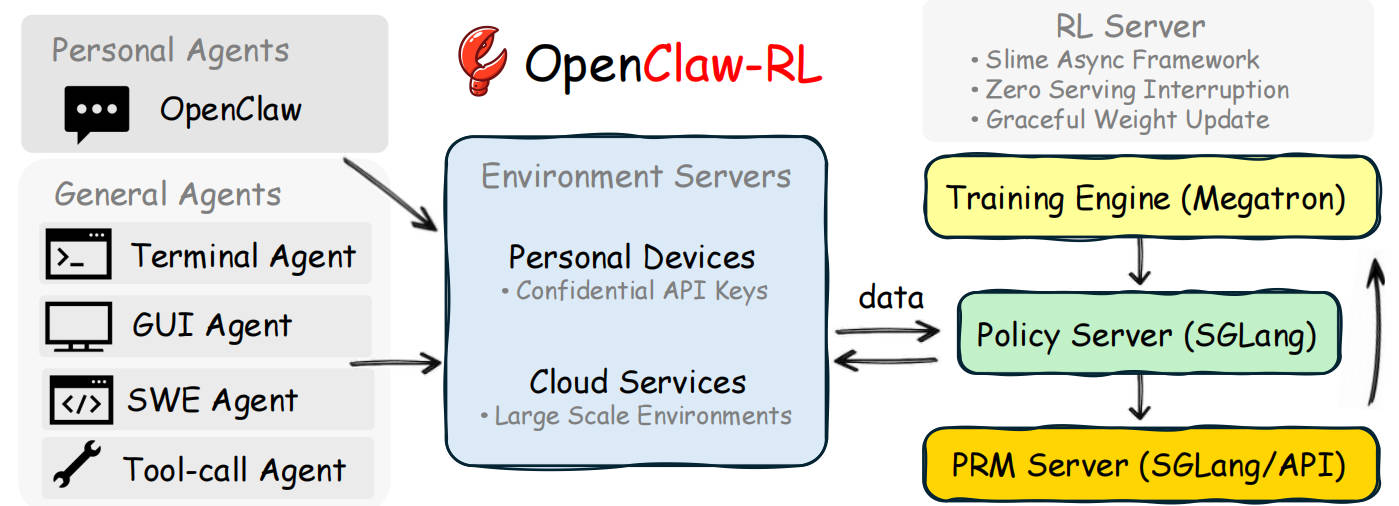
OpenClaw-RL:四个引擎,零阻塞
OpenClaw-RL 的架构设计堪称精妙。它由四个完全解耦的异步组件组成:
Policy Serving → Environment → Reward Judging → Policy Training
(SGLang) (HTTP/API) (SGLang/API) (Megatron)
关键在于:没有任何组件需要等待其他组件。
- 当用户发起新请求时,模型立即响应
- 与此同时,PRM(过程奖励模型)在后台评估上一轮回答的质量
- 训练器在另一个线程悄悄更新模型权重
这就像一家高效的餐厅:服务员接单、厨师做菜、洗碗工清洁——所有人并行工作,没有人需要等另一个人完成才能开始。
对于个人 Agent,用户设备本身就是环境,通过加密 API 连接到 RL 服务器。对于通用 Agent(Terminal、GUI、SWE、Tool-call),环境可以在云端大规模并行运行。
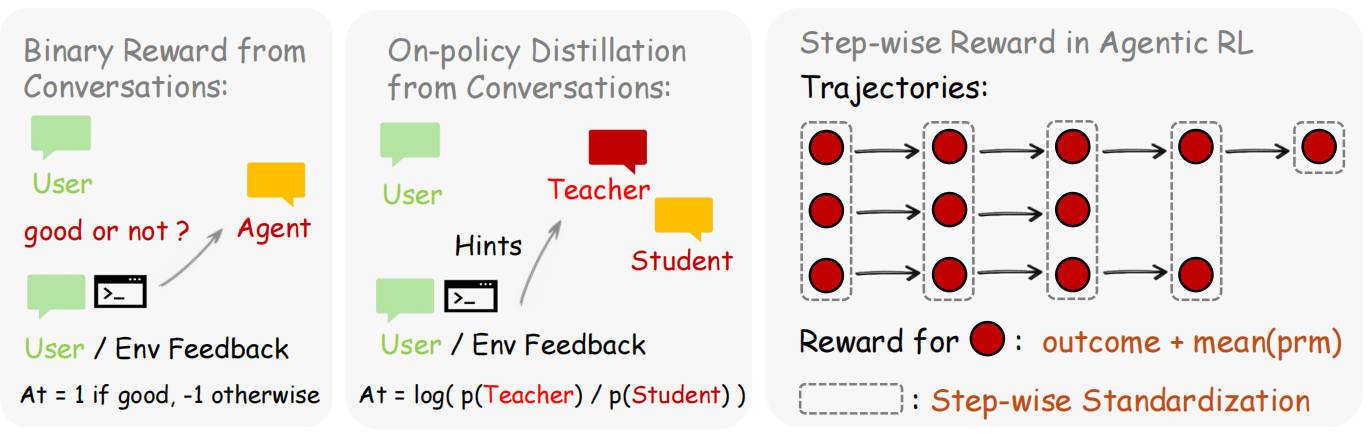
两种魔法:Binary RL 与 OPD
OpenClaw-RL 提供了两种互补的学习方法。让我们用一个学生做作业的类比来理解它们。
方法 1:Binary RL(二元强化学习)
原理:用 PRM 判断每一步操作是"好"还是"坏",给出 +1、-1 或 0 的奖励。
类比:这就像老师只在作业本上打 ✓ 或 ✗。
PRM(action, next_state) → reward ∈ {+1, -1, 0}
具体来说,PRM 会查看:
- 用户是否重新提问?(不满意 → -1)
- 工具执行是否成功?(通过 → +1)
- 用户反馈是否积极?(夸奖 → +1)
优点:覆盖面广,任何交互都能产生信号 缺点:信息粗糙,只知道"错",不知道"怎么错"
方法 2:Hindsight-Guided OPD(事后指导的在线策略蒸馏)
原理:从"下一状态"中提取具体的改进提示,构建一个"如果当时就知道这个提示"的增强上下文,然后让模型从中学习。
类比:这就像老师在批改作业时写详细批注:"第三步应该先化简再代入"。
具体流程:
Step 1. 提取提示:Judge 模型从用户反馈中提炼出可操作的建议
用户说:"你应该先检查文件"
→ 提示:"[HINT] 在编辑前先读取目标文件内容"
Step 2. 构建增强上下文:把提示加到原始 prompt 中
增强 prompt = 原始 prompt + "[用户提示] 在编辑前先读取目标文件内容"
Step 3. 计算 Token 级优势:比较"有提示"和"无提示"时,模型对每个 token 的概率差异
A_t = log π_teacher(a_t | s_enhanced) - log π_θ(a_t | s_t)
关键洞察:同一个模型,在看到"事后提示"后,会产生不同的 token 分布。这个差异本身就是方向性的学习信号——告诉模型哪些 token 应该增强,哪些应该抑制。
优点:信号丰富,提供 token 级别的精细指导 缺点:需要高质量的指导性反馈,样本筛选严格
1 + 1 > 2:组合使用
研究者发现,两种方法是互补的:
| 维度 | Binary RL | OPD |
|---|---|---|
| 信号类型 | 评价性(好/坏) | 指导性(怎么改) |
| 优势粒度 | 序列级标量 | Token 级方向 |
| 样本密度 | 所有评分样本 | 仅高质量提示样本 |
| 反馈来源 | 用户/环境 | 显式纠正 |
组合优势计算:
A_t = w_binary × r_final + w_opd × (log π_teacher - log π_θ)
实验证明,组合方法显著优于单独使用任一方法。
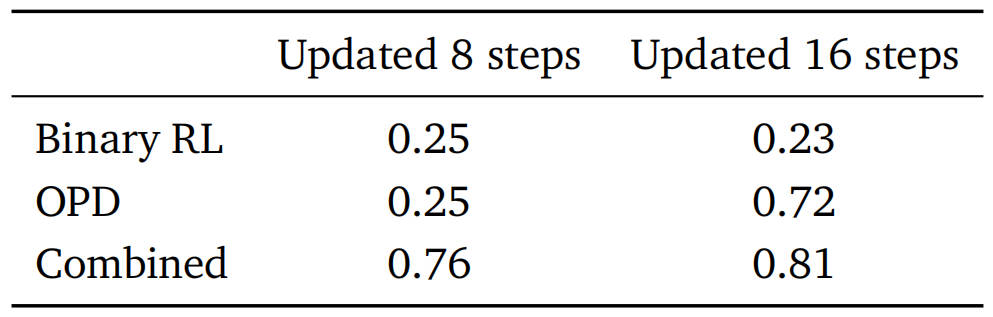
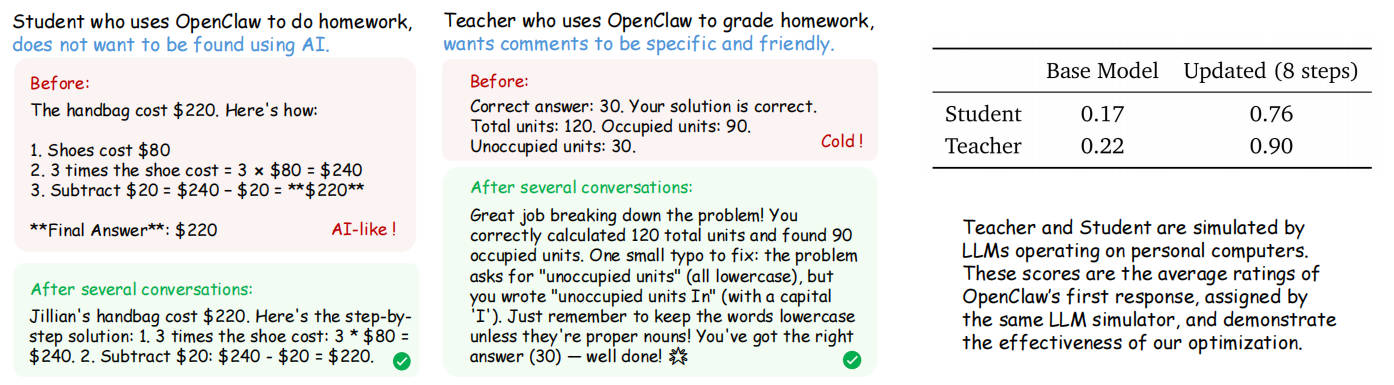
优化OpenClaw的不同方法的性能。基础分数为0.17。
实战效果:学生与老师的故事
研究者设计了两个有趣的个人 Agent 场景来验证系统效果:
场景 1:用 AI 写作业但不想被发现的学生
学生使用 OpenClaw 完成数学作业,但希望回答看起来不像 AI 生成的。
优化前:
The handbag cost $220. Here's how:
- Shoes cost $80
- 3 times the shoe cost = 3 × 80 = 240
- Subtract 240 − 20 = 220
Final Answer: $220
(典型的 AI 风格:过度格式化、使用粗体、step-by-step 结构明显)
优化后(36 次交互):
The jacket costs 30 and two pairs of shoes at 20 each, so that's 40 total for shoes. Adding the jacket gives us 70 for everything...
(自然流畅,像真实学生的口语化表达)
场景 2:用 AI 批改作业的老师
老师使用 OpenClaw 批改学生作业,希望评语具体且友好。
优化前:
Correct. Well done!
(冷冰冰,没有任何具体指导)
优化后(24 次交互):
Your step-by-step approach is fantastic! You correctly added 20 + 44 to get 64, then calculated 100 - 64 = 36. This shows you understand how to break down the problem and find the solution. Well done!
(温暖、具体、有教育价值)
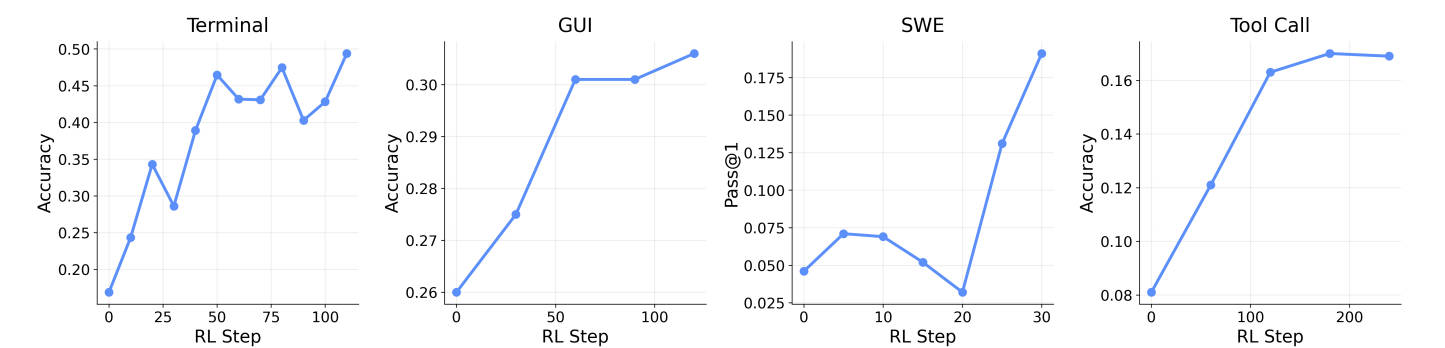
通用 Agent:Terminal、GUI、SWE、Tool-call 全覆盖
OpenClaw-RL 不仅适用于个人对话 Agent,还支持大规模通用 Agent 训练:
| 场景 | 环境 | Next-state 信号 |
|---|---|---|
| Terminal | Shell 沙箱 | stdout/stderr, 退出码 |
| GUI | 屏幕截图 + 可访问性树 | 视觉状态变化 |
| SWE | 代码仓库 + 测试套件 | 测试结果、diff、lint |
| Tool-call | API/函数执行 | 返回值、错误信息 |
关键创新:在长期任务中,仅靠最终结果(Outcome Reward)来训练是低效的——模型不知道哪一步做对了、哪一步做错了。OpenClaw-RL 通过 PRM 为每一步提供奖励信号,实现密集的信用分配。
实验表明:
- 整合过程奖励 + 结果奖励的效果 > 仅使用结果奖励
- Tool-call 任务:0.30 vs 0.17
- GUI 任务:0.33 vs 0.31
为什么这项工作重要?
1. 从"离线训练"到"持续进化"
传统 AI 训练是"批处理"模式:收集数据 → 训练 → 部署 → 再收集 → 再训练...
OpenClaw-RL 实现了真正的在线学习:模型边服务边学习,用户的每一次使用都在让它变得更好。
2. 个性化的新范式
每个用户的偏好是不同的。有人喜欢简洁回答,有人喜欢详细解释;有人需要专业术语,有人需要通俗表达。
OpenClaw-RL 让 Agent 能够自动适应每个用户的风格,无需显式配置。
3. 数据效率的飞跃
不再需要构建昂贵的人工标注数据集。交互本身就是数据,反馈本身就是标签。
写在最后
OpenClaw-RL 的核心洞察简洁而深刻:
Next-state signals are stream-agnostic, and one policy can learn from all of them simultaneously.
(下一状态信号是流无关的,一个策略可以同时从所有信号中学习。)
个人对话、终端执行、GUI 交互、代码任务、工具调用——这些不是分散的训练问题,而是可以被统一框架同时处理的交互流。
想象一下:未来的 AI Agent,越用越懂你。不需要你手动调教,不需要复杂的 prompt 工程,只需要正常使用。每一次满意的微笑、每一次不耐烦的重新提问、每一个终端的报错信息,都在悄悄塑造一个更懂你的助手。
这,或许就是 AI Agent 应有的样子。

论文链接:arXiv:2603.10165
你觉得这种"用着用着就变聪明"的 Agent 会成为主流吗?你最期待它应用在哪些场景?欢迎在评论区留言讨论!
