

项目编号:BS-BD-011
一,环境介绍
语言环境:Python3.8
数据库:Mysql: mysql5.7
WEB框架:Django
开发工具:IDEA或PyCharm
二,项目简介
随着计算机技术发展,计算机系统的应用已延伸到社会的各个领域,大量基于大数据的广泛应用给生活带来了十分的便利。所以把热门旅游景点数据分析管理与现在网络相结合,利用计算机搭建热门旅游景点数据分析系统,实现热门旅游景点数据分析的信息化。则对于进一步提高热门旅游景点数据分析管理发展,丰富热门旅游景点数据分析管理经验能起到不少的促进作用。
系统阐述的是使用热门旅游景点数据分析系统的设计与实现,对于Python、B/S结构、MySql进行了较为深入的学习与应用。主要针对系统的设计,描述,实现和分析与测试方面来表明开发的过程。开发中使用了 django框架和MySql数据库技术搭建系统的整体架构。利用这些技术结合实际需求开发了具有个人中心、门票信息管理、名宿信息管理、系统管理等功能的系统,最后对系统进行相应的测试,测试系统有无存在问题以及测试用户权限来优化系统,最后系统达到预期目标。
热门旅游景点数据分析系统综合网络空间开发设计要求。目的是将传统管理方式转换为在网上管理,完成热门旅游景点数据分析管理的方便快捷、安全性高、交易规范做了保障,目标明确。热门旅游景点数据分析系统功能主要包括个人中心、门票信息管理、名宿信息管理、系统管理等进行管理。
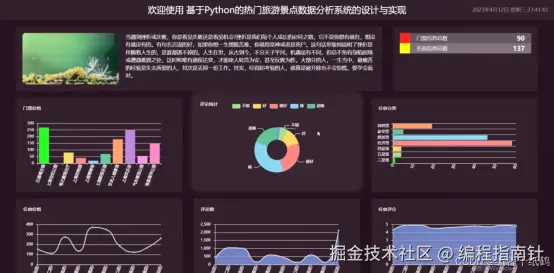
 编辑
编辑
三,系统展示
系统登录,在登录页面正确输入用户名和密码后,点击登录进入操作系统进行操作;如图5-1所示。 编辑
图5-1系统登录界面
编辑
编辑
编辑
编辑
编辑
四,核心代码展示
# 数据爬取文件
import scrapy
import pymysql
import pymssql
from ..items import MenpiaoxinxiItem
import time
import re
import random
import platform
import json
import os
import urllib
from urllib.parse import urlparse
import requests
import emoji
# 门票信息
class MenpiaoxinxiSpider(scrapy.Spider):
name = 'menpiaoxinxiSpider'
spiderUrl = 'https://piao.qunar.com/ticket/list.htm?keyword=北京®ion=北京&from=mpshouye_hotcity&page={};https://piao.qunar.com/ticket/list.htm?keyword=上海®ion=上海&from=mpshouye_hotcity&page={};https://piao.qunar.com/ticket/list.htm?keyword=成都®ion=成都&from=mpshouye_hotcity&page={}'
start_urls = spiderUrl.split(";")
protocol = ''
hostname = ''
headers = {
'cookie': 'SECKEY_ABVK=52wqhYvvn6DwWQMPe0vae2C9PRAya2qX3mKGAeYzP5g=; BMAP_SECKEY=7tjPB9bODmDlZEXqvtvEulQHb3cD5tBb9Ga4bb0FZpDtjLdCfJ_lP4l8HXOBhb3N8Lx2QOIZUk37L0OHam0RNR5nLb8qg8C0sek_qdMf2hM_fPFdJsx_OLc02-dEssdLJPpdCrh-JQEDf3LYxP0k-r1dBmun_ERCXeRg7VPgGHxQg2vNGDZwBdpg_oB_rtDL; QN1=00009180306c494e3058d5d8; QN300=organic; QN99=890; QunarGlobal=10.66.75.12_3e944b47_1847a302978_-7ab2|1668497419274; qunar-assist={"version":"20211215173359.925","show":false,"audio":false,"speed":"middle","zomm":1,"cursor":false,"pointer":false,"bigtext":false,"overead":false,"readscreen":false,"theme":"default"}; QN205=organic; QN277=organic; csrfToken=3h4rnshx7yA8tKvMPcnbfp7CHwQB7UqV; QN601=feca515cdd9ef1176581492e698b76b9; QN163=0; QN269=5BA55CB064B711EDB04FFA163E0BBFA6; _i=DFiEuoOFUXwlpY-ethPvHErWHOgw; QN48=000089002f10494e305856d9; fid=bfd77176-1cb2-443f-aba2-8fd8ceb10e82; quinn=e3670956fde2ca7b106c8bf736512b30f2cfd558e7c2c547f96287676db26093e994fcb9c9c486054688a35ebf94da4d; HN1=v1e394ee0243a6418bdb97ca1d9962471e; HN2=qunngslnusrrl; QN71=NTkuMzcuMzQuMjQwOuaiheW3njox; ariaDefaultTheme=null; QN57=16684975044280.7157504715096659; Hm_lvt_15577700f8ecddb1a927813c81166ade=1668497505; QN267=1242544949d58508ca; _vi=99e89Q7EeJVkt9z1Ml4G2pB-xxS_Lx_tpqqlaCkjXGu3lMeE16y0JAHDMk5itSTamzBmteIskT4igse-muIK-kq_HUP4JgYI3-zq0fEXKEo4ufkA0aLYtYdR-HWpdPR67kvkghTzoWtjxo_dEUTho4sQ4squt70g32xrdflWafFP; QN58=1668557583989|1668557583989|1; Hm_lpvt_15577700f8ecddb1a927813c81166ade=1668557584; JSESSIONID=0A58E08B1B8F5C1FB21C1DB4CA5500C1; QN271=833af849-0bdf-4005-935c-438e868fd707; __qt=v1|VTJGc2RHVmtYMTgzRXIxdVE0VHR0NlZaRGNTY0t0ZGsvYnFSTTR6WlBFb295eXE1cU92Vjkvd2Y3Y2R6TjBxUFJGN0xhdzZqWGV3enI4TnFQT2g1ZU95ZUJsU2R0ZW1GZ2NkdWM1S0Qyc0RyWkxyWS8vK2Yra2QyREpTWGpCYk5aOWNKR2pJVU9oOForejZxOEh0cXgrUXBUTG1aWHBGWVJxYTFJWlh2K0ZjPQ==|1668557590728|VTJGc2RHVmtYMStvK29QUVpjQnhKTTk3M2dHOWZXK2xvTTR1ejVTT0ZMZmlucjVjci9xUFpReE9LRjljd3JpYlNpd1hIZFNVUHBLZ2FmbjdpeUpuR2c9PQ==|VTJGc2RHVmtYMTltZWJMVlluZEhldjhmL2RyWmhaR0dSbkVaWmd4N1FzU2NZclpGeHkraWdEb1Mwa3Fremk2aW5zQWNSZGJab2pPYVJiMy94SWVSZG5nVlZmU0gxMVc5OTUvZjFhOXhvT254Q0tzQkFQRUtQNXRXMUZRZ2JRZjNSZnAwVmdaY2RudVlMZjRxT2w0K1JWSXBUU2hyMkFsK0xwQmNLQmFRc3pERktlbi9qcDZkekVkSVhWa2hyTWpVcnR1ZzBIeUhoVFNlOTNiRTN0UGFBSDNXS2NtK2ptQ0NoaEMwWDg0cWgzc2F4YUtjRVZnUnpKeHlZU0VmY2RmOFJTbGtCWm0rL3ZTaUZwRkxGRWFZQUUydEJvM2hEUzJmUS9zR01pcVlCMU1wcUhyZXFUY2hQcXYzNHR3WnBGNGthaDZEUkJYY1YyUXcvU2U5eHBtUVJDMm11MDRoZE9SUWJjd1hQN25VQU9Gb0ZKOUJxbjI3RnNhMzljYXZHMHQzbzc5MGs4c1BpWUVpaXlIRURoWDFUL2thNGFFcWgyR0ZLRnVndExaOTdFNGZnVDNOQkJDWkVwbTh4T0FDNDUzM3JuQVplVHg2cmZxRDJ6b1BzZEZoUEpwd2grMEhwSHJyMGN6U0ExOFU4TmFITTdkR05Wc1Rmb3ZTVmsrMXNuUE1tYWpseGZ2UTdkcGRGNWsvOTE3L21OdVVDOTNLWmlkdmE2NjBoRnhnZlYwMDhpOEtTRlRYZHAvay9NSFV3MHYrMXltL1FqaUtkQW5vdmJNZmZ3dmtmeFl3QllBVmpsbzAzUUNPeVNYZE15MlQvY1MyNEpFUWVZWi9jN2drRDZsdzN6aEE4RWZWYlozR0ZTZk5PbUo4RS9qMzZzUlVMQjFCWDR0MmdGWlB2Mmc9'
}
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
def start_requests(self):
plat = platform.system().lower()
if plat == 'linux' or plat == 'windows':
connect = self.db_connect()
cursor = connect.cursor()
if self.table_exists(cursor, '08375_menpiaoxinxi') == 1:
cursor.close()
connect.close()
self.temp_data()
return
pageNum = 2 + 1
for url in self.start_urls:
if '{}' in url:
for page in range(1, pageNum):
next_link = url.format(page)
yield scrapy.Request(
url=next_link,
headers=self.headers,
callback=self.parse
)
else:
yield scrapy.Request(
url=url,
headers=self.headers,
callback=self.parse
)
# 列表解析
def parse(self, response):
_url = urlparse(self.spiderUrl)
self.protocol = _url.scheme
self.hostname = _url.netloc
plat = platform.system().lower()
if plat == 'windows_bak':
pass
elif plat == 'linux' or plat == 'windows':
connect = self.db_connect()
cursor = connect.cursor()
if self.table_exists(cursor, '08375_menpiaoxinxi') == 1:
cursor.close()
connect.close()
self.temp_data()
return
list = response.css('div#search-list div[class~="sight_item"]')
for item in list:
fields = MenpiaoxinxiItem()
if '(.*?)' in '''h3.sight_item_caption a.name::attr(href)''':
fields["laiyuan"] = re.findall(r'''h3.sight_item_caption a.name::attr(href)''', response.text, re.DOTALL)[0].strip()
else:
fields["laiyuan"] = self.remove_html(item.css('h3.sight_item_caption a.name::attr(href)').extract_first())
detailUrlRule = item.css('h3.sight_item_caption a.name::attr(href)').extract_first()
if self.protocol in detailUrlRule:
pass
elif detailUrlRule.startswith('//'):
detailUrlRule = self.protocol + ':' + detailUrlRule
else:
detailUrlRule = self.protocol + '://' + self.hostname + detailUrlRule
fields["laiyuan"] = detailUrlRule
yield scrapy.Request(url=detailUrlRule, meta={'fields': fields}, headers=self.headers, callback=self.detail_parse, dont_filter=True)
# 详情解析
def detail_parse(self, response):
fields = response.meta['fields']
try:
if '(.*?)' in '''div.mp-description-detail div.mp-description-view span.mp-description-name::text''':
fields["biaoti"] = re.findall(r'''div.mp-description-detail div.mp-description-view span.mp-description-name::text''', response.text, re.S)[0].strip()
else:
if 'biaoti' != 'xiangqing' and 'biaoti' != 'detail' and 'biaoti' != 'pinglun' and 'biaoti' != 'zuofa':
fields["biaoti"] = self.remove_html(response.css('''div.mp-description-detail div.mp-description-view span.mp-description-name::text''').extract_first())
else:
fields["biaoti"] = emoji.demojize(response.css('''div.mp-description-detail div.mp-description-view span.mp-description-name::text''').extract_first())
except:
pass
try:
if '(.*?)' in '''div#mp-slider-content div.mp-description-image img::attr(src)''':
fields["fengmian"] = re.findall(r'''div#mp-slider-content div.mp-description-image img::attr(src)''', response.text, re.S)[0].strip()
else:
if 'fengmian' != 'xiangqing' and 'fengmian' != 'detail' and 'fengmian' != 'pinglun' and 'fengmian' != 'zuofa':
fields["fengmian"] = self.remove_html(response.css('''div#mp-slider-content div.mp-description-image img::attr(src)''').extract_first())
else:
fields["fengmian"] = emoji.demojize(response.css('''div#mp-slider-content div.mp-description-image img::attr(src)''').extract_first())
except:
pass
try:
if '(.*?)' in '''div.mp-description-onesentence::text''':
fields["miaoshu"] = re.findall(r'''div.mp-description-onesentence::text''', response.text, re.S)[0].strip()
else:
if 'miaoshu' != 'xiangqing' and 'miaoshu' != 'detail' and 'miaoshu' != 'pinglun' and 'miaoshu' != 'zuofa':
fields["miaoshu"] = self.remove_html(response.css('''div.mp-description-onesentence::text''').extract_first())
else:
fields["miaoshu"] = emoji.demojize(response.css('''div.mp-description-onesentence::text''').extract_first())
except:
pass
try:
if '(.*?)' in '''span.mp-description-address::text''':
fields["weizhi"] = re.findall(r'''span.mp-description-address::text''', response.text, re.S)[0].strip()
else:
if 'weizhi' != 'xiangqing' and 'weizhi' != 'detail' and 'weizhi' != 'pinglun' and 'weizhi' != 'zuofa':
fields["weizhi"] = self.remove_html(response.css('''span.mp-description-address::text''').extract_first())
else:
fields["weizhi"] = emoji.demojize(response.css('''span.mp-description-address::text''').extract_first())
except:
pass
try:
if '(.*?)' in '''span#mp-description-commentscore''':
fields["dianping"] = re.findall(r'''span#mp-description-commentscore''', response.text, re.S)[0].strip()
else:
if 'dianping' != 'xiangqing' and 'dianping' != 'detail' and 'dianping' != 'pinglun' and 'dianping' != 'zuofa':
fields["dianping"] = self.remove_html(response.css('''span#mp-description-commentscore''').extract_first())
else:
fields["dianping"] = emoji.demojize(response.css('''span#mp-description-commentscore''').extract_first())
except:
pass
try:
if '(.*?)' in '''span.mp-description-commentCount a::text''':
fields["pinglun"] = re.findall(r'''span.mp-description-commentCount a::text''', response.text, re.S)[0].strip()
else:
if 'pinglun' != 'xiangqing' and 'pinglun' != 'detail' and 'pinglun' != 'pinglun' and 'pinglun' != 'zuofa':
fields["pinglun"] = self.remove_html(response.css('''span.mp-description-commentCount a::text''').extract_first())
else:
fields["pinglun"] = emoji.demojize(response.css('''span.mp-description-commentCount a::text''').extract_first())
except:
pass
try:
if '(.*?)' in '''span.mp-description-qunar-price''':
fields["jiage"] = re.findall(r'''span.mp-description-qunar-price''', response.text, re.S)[0].strip()
else:
if 'jiage' != 'xiangqing' and 'jiage' != 'detail' and 'jiage' != 'pinglun' and 'jiage' != 'zuofa':
fields["jiage"] = self.remove_html(response.css('''span.mp-description-qunar-price''').extract_first())
else:
fields["jiage"] = emoji.demojize(response.css('''span.mp-description-qunar-price''').extract_first())
except:
pass
try:
if '(.*?)' in '''div.mp-charact-intro div.mp-charact-desc''':
fields["tese"] = re.findall(r'''div.mp-charact-intro div.mp-charact-desc''', response.text, re.S)[0].strip()
else:
if 'tese' != 'xiangqing' and 'tese' != 'detail' and 'tese' != 'pinglun' and 'tese' != 'zuofa':
fields["tese"] = self.remove_html(response.css('''div.mp-charact-intro div.mp-charact-desc''').extract_first())
else:
fields["tese"] = emoji.demojize(response.css('''div.mp-charact-intro div.mp-charact-desc''').extract_first())
except:
pass
try:
if '(.*?)' in '''div.mp-charact-content div.mp-charact-desc''':
fields["kaifangshijian"] = re.findall(r'''div.mp-charact-content div.mp-charact-desc''', response.text, re.S)[0].strip()
else:
if 'kaifangshijian' != 'xiangqing' and 'kaifangshijian' != 'detail' and 'kaifangshijian' != 'pinglun' and 'kaifangshijian' != 'zuofa':
fields["kaifangshijian"] = self.remove_html(response.css('''div.mp-charact-content div.mp-charact-desc''').extract_first())
else:
fields["kaifangshijian"] = emoji.demojize(response.css('''div.mp-charact-content div.mp-charact-desc''').extract_first())
except:
pass
id = fields["jiage"] = re.findall(r'"sightInfo":{.*?"sightId": "(.*?)",.*?"img"', response.text, re.S)[0].strip()
detail_res = requests.post('https://piao.qunar.com/ticket/detail/getTickets.json?sightId={}'.format(id))
detail_json = json.loads(detail_res.text)
detail_json_data = detail_json.get('data')
fields["jiage"] = detail_json_data.get('qunarPrice')
return fields
# 去除多余html标签
def remove_html(self, html):
if html == None:
return ''
pattern = re.compile(r'<[^>]+>', re.S)
return pattern.sub('', html).strip()
# 数据库连接
def db_connect(self):
type = self.settings.get('TYPE', 'mysql')
host = self.settings.get('HOST', 'localhost')
port = int(self.settings.get('PORT', 3306))
user = self.settings.get('USER', 'root')
password = self.settings.get('PASSWORD', '123456')
try:
database = self.databaseName
except:
database = self.settings.get('DATABASE', '')
if type == 'mysql':
connect = pymysql.connect(host=host, port=port, db=database, user=user, passwd=password, charset='utf8')
else:
connect = pymssql.connect(host=host, user=user, password=password, database=database)
return connect
# 断表是否存在
def table_exists(self, cursor, table_name):
cursor.execute("show tables;")
tables = [cursor.fetchall()]
table_list = re.findall('('.*?')',str(tables))
table_list = [re.sub("'",'',each) for each in table_list]
if table_name in table_list:
return 1
else:
return 0
# 数据缓存源
def temp_data(self):
connect = self.db_connect()
cursor = connect.cursor()
sql = '''
insert into `menpiaoxinxi`(
id
,laiyuan
,biaoti
,fengmian
,miaoshu
,weizhi
,dianping
,pinglun
,jiage
,tese
,kaifangshijian
)
select
id
,laiyuan
,biaoti
,fengmian
,miaoshu
,weizhi
,dianping
,pinglun
,jiage
,tese
,kaifangshijian
from `08375_menpiaoxinxi`
where(not exists (select
id
,laiyuan
,biaoti
,fengmian
,miaoshu
,weizhi
,dianping
,pinglun
,jiage
,tese
,kaifangshijian
from `menpiaoxinxi` where
`menpiaoxinxi`.id=`08375_menpiaoxinxi`.id
))
limit {0}
'''.format(random.randint(10,15))
cursor.execute(sql)
connect.commit()
connect.close()
