

1.分布式推理
1.什么是分布式推理
分布式推理部署是一种利用多个计算节点(如服务器、GPU或TPU等)协同完成深度学习模型推理任务的技术。它通过将计算负载分散到多个设备上,以提高处理效率、降低延迟,并支持大规模并发请求。
2. 主要目标
高性能: 加速推理速度,满足实时性需求(如自动驾驶、实时翻译)。
高吞吐: 处理大量并发请求(如推荐系统、AIGC服务)。
可扩展性: 动态扩展资源应对负载波动。
3. 关键实现方式
分布式推理是指将大模型的计算任务拆分到多个GPU设备上并行执行,以解决单卡显存不足、提升推理速度的技术。
其核心在于张量并行(Tensor Parallelism)和流水线并行(Pipeline Parallelism),其中
张量并行:将模型的权重矩阵按维度切分到不同GPU上,每个GPU负责部分计算,最终合并结果a例如,在Llama-13B等大模型推理中,单卡显存可能不足,分布式推理可显著降低显存占用并提高吞吐量。
4.不采用分布式推理的结果
如果一个大模型的应用,涉及到用户量过多,导致服务器的性能跟不上,那么最终只有一个解决方案,就是加服务器或者加显卡GPU,如果不加GPU进行分布式推理,那么出现的情况就是像DeepSeek一样服务器未响应,服务器繁忙,就是用户用的时候用不到。
为什么会这个样子呢?我们待会儿介绍完这个分布式推理的这个逻辑,你们就搞明白了。
5.高并发与分布式推理的区别
对于AI模型来讲,AI模型输入的是数据,我们的数据是带有批次的batchSize,假设现在我们在训练模型,我们的批次为十,相当于我们一次性给模型输入了十个问题,它等同于在同一时刻有十个用户向这个模型提了问题,这就是批次的含义。
如果是在推理的过程中就相当于是当前有几个用户在使用这个模型,在同一时刻有10个用户在使用这个模型,批次就相当于是10,那么模型返回的结果也是10个。这就是一个并发问题,那么高并发就是这个人数突然变得特别的多,之前10个人模型还可以跑,现在突然激增变成1000人他可能就跑不了,
相当于我们的batchSize变成1000了,这就会引发两个问题:
第一个就是你的OOM问题,显存不足了,Out of memory。
第二个问题是你的算力不足了,就是说我们批次为10的时候,它的计算速度一定要比批次为1000的时候计算速度一定要快,我们在推理模型的时候,其实跟你训练时是如出一辙的,只不过推理的过程中,它的模型只计算矩阵乘法,它不算导数,不更新参数。
所以高并发问题就是要解决我的用户量过多了怎么办?
实际上我们是要解决的是两个问题:
1.显存不足的问题
2.算力不足导致这个模型推理速度变慢的问题
解决的方式相当于之前跑这个模型,他是在一张卡上面跑的,现在用户量由十个人增加到1000个人了,这一张卡跑不动了,就增加到8张卡上面。这就是用分布式来解决这个并发的问题。
6.实际案例
案例场景:
单卡显存不足: 如QwQ-32B(320亿参数)需在双A6000显卡上部署
高并发请求: 在线服务需同时处理多用户请求,分布式推理通过连续批处理提升效率。
我们一般在做模型部署的时候,这个模型部署它是基于一套系统来做的,系统上面有它有最大的用户量的一个限制(限流),当用户量超过最大承载量以后,就会以队列的模式进行排队,这就是为什么前段时间那个DeepSeek爆火的时候,我们正常情况下,白天你去访问它的时候是访问不了的,因为我们不在队列中,我们都是通过手机号注册的,他有一个用户管理系统里面控制队列。
2.vLLM分布式推理实现
vLLM通过PagedAttention和张量并行技术优化显存管理和计算效率,支持多GPU推理。
1.核心机制
张量并行: 通过tensor_parallel_size参数指定GPU数量,模型自动拆分到多卡。
PagedAttention: 我们现在的模型都是基于Transformer构建的,Transformer的本质实际上就是一个自注意力层、前向计算层(前馈神经网络FNN)两个部分来构建的,我们要进行分布式推理的时候就涉及到一个问题,怎么把模型拆开,拆开模型就需要拆两个部分,一个是注意力机制的部分,另外一个是神经网络的部分。神经网络实际上比较好拆,因为神经网络它本身是个序列的,但是注意机制不存在顺序关系,所以PagedAttention的提出就是为了划分Transformer模型中的个注意力机制的理解,他将注意力机制的键值(KV)缓存分块存储,减少显存碎片提升利用率。
连续批处理: 在PagedAttention存储过后,我们推理的时候模型是持续执行的,它不会停下来,所以它还涉及到连续的批处理,比如说这一次可能是10个用户,下一次可能是20个用户,再下一次可能是30个用户,它的批次次在不断的变化,在这整个过程中,模型每次推理肯定是必须先把最开始的10个的任务执行完,再去执行后面20个人,后面20个人是插不了队的,然后这20个人执行完之后,后面的30个人再重新进来去执行他们的任务,所以在整个执行过程中,模型涉及到了批次的长度不一样。因为每一时刻的用户量都在发生变化,所以在分完块之后,它需要动态合并不同长度的请求,减少GPU空闲时间。
2.分布式推理
- 单 GPU(无分布式推理) :如果您的模型可以容纳在单个 GPU 中,您可能不需要使用分布式推理。只需使用单个 GPU 运行推理即可。
- 单节点多 GPU(张量并行推理) :如果您的模型太大,无法容纳在单个 GPU 中,但可以容纳在具有多个 GPU 的单台服务器中,则可以使用张量并行。张量并行大小是您想要使用的 GPU 数量。例如,如果您在单台服务器中有 4 个 GPU,您可以将张量并行大小设置为 4。
- 多节点多 GPU(张量并行加流水线并行推理) :如果您的模型太大,无法容纳在单个服务器上,您可以将张量并行与流水线并行结合使用。张量并行大小是您想在每个节点中使用的 GPU 数量,流水线并行大小是您想使用的服务器数量。例如,如果您在 2 台服务器中有 16 个 GPU(每台服务器 8 个 GPU),您可以将张量并行大小设置为 8,流水线并行大小设置为 2。
单节点GPU推理:
*vllm serve /root/lanyun-tmp/LLM/Qwen/Qwen2.5-1.5B-Instruct *
--tensor-parallel-size 2
多节点多 GPU推理:
*vllm serve /root/lanyun-tmp/LLM/Qwen/Qwen2.5-1.5B-Instruct *
*--tensor-parallel-size 4 *
--pipeline-parallel-size 2
1.vllm serve /root/lanyun-tmp/LLM/Qwen/Qwen2.5-1.5B-Instruct
• 使用 vLLM(一个高效的大语言模型推理框架)启动服务。
• 加载的模型是 Qwen2.5-1.5B-Instruct。
2. --tensor-parallel-size 4
• 启用 张量并行(Tensor Parallelism),将模型参数在 2 个 GPU 之间拆分。
• 适用于单机多卡场景,通过将矩阵运算分块并行加速计算。
• 例如,如果模型有 12 层,每层的计算会在 4 个 GPU 上协同完成。
3. --pipeline-parallel-size 2
• 启用 流水线并行(Pipeline Parallelism),将模型按层拆分到 2 个 GPU 上。
• 适用于模型过大无法单卡存放时,按层划分到不同设备。
• 例如,GPT-2 的 12 层可能被分成两部分(1-6 层在 GPU 0,7-12 层在 GPU 1)。
3.KV Cache缓存占用情况
上图显示:在单卡的情况下: GPU KV cache usage:0.0% 缓存占用0%,但是nvitop命令展示的窗口GPU显存占用达到了91%,这是因为即使模型没有在进行推理,模型启动后,vLLM框架会占用好显存在使用的时候进行调度。
多卡的情况:
4.分布式推理后缓存情况
前缀缓存命中率(Prefix Cache Hit Rate)表示在序列生成(如大语言模型推理)过程中,重复使用已缓存的前缀数据的效率。
1. 基本概念解释
- 前缀缓存(Prefix Cache) :
-
- 大语言模型(如LLM)通过自回归方式生成文本时,每生成一个新的词元(token),需要计算所有之前词元的注意力(Attention)键值(Key-Value, KV)状态。为了优化性能,系统会缓存这些计算结果,称为 KV缓存(KV Cache) 。
- 前缀缓存特指对输入中相同前缀部分(例如多个用户请求共享的初始提示词)的KV缓存复用。例如:
提示词1: "巴黎是法国的首都,它的地标建筑是"
提示词2: "巴黎是法国的首都,它的美食文化以"
↑↑↑↑↑↑↑↑↑
[可复用的前缀]
- 命中率(Hit Rate) :
-
- 60%的命中率 = 系统在60%的请求中找到了可复用的前缀缓存,无需重新计算;剩余的40%需要重新生成完整KV缓存。
2. 60%命中率的意义
- 性能优化:
-
- 吞吐量提升: 重复使用前缀缓存会减少计算量,直接提高响应速度。例如在批量处理100个相似请求时,60个请求复用了已有缓存,理论吞吐量可提高约0.6倍。
- 硬件成本降低: 缓存复用减少了GPU显存带宽和计算资源占用。
- 业务场景判断:
-
- **高命中率(60%+)**可能意味着:
-
-
- 用户请求的前缀相似性高(如重复的查询模板、结构化提示词)。
- 使用的缓存分块(Chunk)策略适配了实际请求长度。
-
-
- **低命中率(如30%以下)**可能表明请求差异性大或缓存配置不合理。
3.LmDeploy
LMDeploy是专为高效部署设计的框架,支持量化技术与分布式推理,尤其适合低显存环境。
lmdeploy支持python、gRPC、RESTful接口,主要支持两种轻量化,AWQ离线量化将模型转为4位或者8位的权重,KvCache在线量化,目前支持的推理引擎主要是turbomind和pytorch(turbomind比pytorch要快),提供的服务主要是api server,gradio,triton inference server。
1.lmdeploy的推理性能
1.静态推理性能
固定batch(批次),输入/输出token数量,用llama2-7b在A100(80G)的显卡上做对比,横轴为批次,纵轴是tonken的吞吐量,LMDeploy W4a16与fp16性能做对比,W4a16的推理性能是fp16的2倍多。
2.动态推理性能
真实对话,不固定长度输入,橙色:lmDeploy ,蓝色:vLLM,进行对比,计算精度分别是为FP16、BF16,推理引擎是turbomind, 是fp16的所以官网写着他的速度是vLLM的1.8倍多)
2.lmdeploy量化效果
3.为什么做Veight Only的量化?
两个基本概念
• 计算密集《compute-bound): 推理的绝大部分时间消耗在数值计算上;针对计算密集场景,可以通过使用更快的硬件计算单元来提升计算速度,比如量化为W8A8使用INT8 Tensor Core来加速计算。
• 访存密集(memory-bound): 推理时,绝大部分时间消耗在数据读取上;针对访存密集型场景,一般是通过提高计算访存比来提升性能。
• LLM是典型的访存密集型任务,常见的LLM模型是Decoder Only架构。推理时大部分时间消耗在逐个Token生成阶段(Decoding阶段),是典型的访存密集型场景。
如下图,A100的FP16峰值算力为312 TFLOPS,只有在Batch Size达到128这个量级时,计算才成为推理的瓶颈,但由于LLM模型本身就很大,推理时的KV Cache也会占用很多显存,还有一些其他的因素影响(如Persistent Batch),实际推理时很难做到128这么大的Batch Size(很多时候我们在推理大模型的时候,它的计算量没发挥出来,但是显存已经占满了) 。
- Weight Only量化一举多得
- 4 bit Weight Only量化,将FP16的模型权重量化为NT4,访存量直接降为FP16模型的1/4,大幅降低了访存成本,提高了Decoding的速度。
- 加速的同时还节省了显存,同样的设备能够支持更大的模型以及更长的对话长度
4.如何做Weight Only的量化?
• LMDeploy使用MIT HAN LAB开源的AWQ算法,量化为4bit模型,推理时,先把4bit权重,反量化回FP16(在Kernel内部进行,从Global Memory读取时仍是4bit),依旧使用的是FP16计算
• 相较于社区使用比较多的GPTQ算法,AWQ的推理速度更快,量化的时间更短
对比不同量化等级各种算法的区别:
5.推理引擎TurboMind
1.持续批处理
请求可以及时加入batch中推理,Batch中已经完成推的请求及时退出。
下图中:
虽然S0和S1先到达,但它们被分在同一个批次[t0-t1]中,并且可能被分配到同一个计算单元或线程上。
S2虽然后到达,但它可能被分配到一个不同的GPU,这个GPU在处理完S0和S1的部分后,可能比处理S1的GPU更早空闲。
因此,S2可以在S1之前完成处理。
2.有状态的推理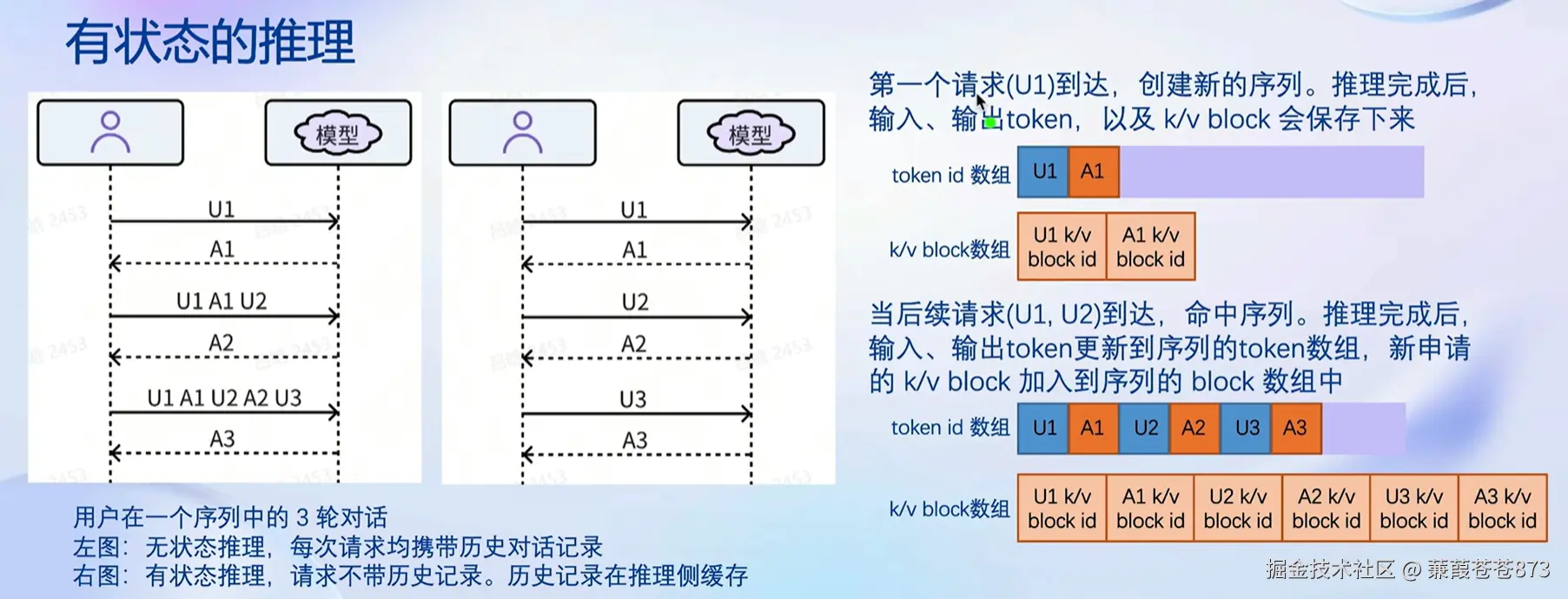
Blocked k/v cache:
Attention支持不连续的kW
block(Paged Attention)
左侧图表示:
用户与模型的交互:图中展示了用户在一个序列中的三轮对话。
• 无状态推理:在无状态推理中,每次请求都独立处理,不携带历史对话记录。这意味着每次用户发送请求(U1, U2, U3),模型都会独立处理这些请求,生成响应(A1, A2, A3),而不考虑之前的对话内容。
右侧图表示:
• 有状态推理:在有状态推理中,每次请求不仅处理当前的用户输入,还携带之前的历史对话记录。
• 第一个请求(U1):
• 创建新的序列。
• 推理完成后,输入、输出token,以及k/v block(键值对块)会被保存下来,存在显存中(这样才能满足频繁读取,有些模型,支持放在内存,通常用在显存不足,用内存来替代的地方)。
• 图中显示了token id数组和k/v block数组的存储情况。
• 后续请求(U1, U2):
• 命中序列,继续在同一序列中处理。
• 推理完成后,输入、输出token更新到序列的token数组,新申请的k/v block加入到序列的block数组中。
• 这样,模型在生成响应时会考虑之前的对话内容,从而生成更连贯和相关的回复。
具体步骤
• 第一个请求(U1):
• 输入:U1
• 输出:A1
• 存储:token id数组(U1,A1),k/v block数组(A1的k/v block id)
• 第二个请求(U1,U2):
• 输入:U1,U2
• 输出:A2
• 更新存储:token id数组(U1,A1,U2,A2),k/v block数组(A2的k/v block id加入)
• 第三个请求(U1,A1,U2,A2,U3):
• 输入:U1,A1,U2,A2,U3
• 输出:A3
• 更新存储:token id数组(U1,A1,U2,A3),k/v block数组(A3的k/v block id加入)
在有状态推理中,用户与其token以及块(k/v block)的关联是通过对话历史和上下文管理来实现的。以下是详细的解释:
• 序列管理:
• 每个序列都有一个唯一的标识符,用于管理对话历史。
• 当新的请求到达时,系统会检查是否存在与该请求相关的序列。如果存在,系统会命中序列并继续在该序列上进行推理。
• Token ID数组:
• 每个序列都有一个token ID数组,用于存储序列中所有输入和输出的token ID。
• 当新的请求到达时,新的token ID会被添加到相应的token ID数组中。
• K/V块数组:
• K/V块(键值对块)用于存储模型推理过程中的中间状态,这些状态对于生成连贯的响应至关重要。
• 每个序列都有一个K/V块数组,用于存储序列中所有请求的K/V块。
• 当新的请求到达时,新的K/V块会被添加到相应的K/V块数组中。
• 关联机制:
• 用户的每次请求都通过其token ID数组和K/V块数组与特定的序列关联。
• 系统通过这些数组来维护和更新对话历史,确保每次推理都能考虑到之前的对话内容。
总结来说,用户与其token以及K/V块的关联是通过对话历史记录、序列管理、token ID数组和K/V块数组来实现的。这些机制确保了有状态推理能够生成连贯和相关的响应。
通过这样的方式可以最大限度的减少显存占用。
3.Blocked k/v cache工作原理
图中展示的是lmdeploy的TurboMind引擎中K/V(键值对)缓存机制的讲解,特别是Blocked k/v cache的设计和工作原理。以下是对图中内容的详细解释:
左侧图示:Blocked k/v cache
• 支持功能:
• 支持分页注意力(Paged Attention)。
• 支持有状态推理(Stateful Inference)。
• 结构:
• K/V缓存被分为K部分和V部分,分别存储键(Keys)和值(Values)。
• 每个block的大小(BlockSize)由以下公式计算:BlockSize = 2 × Layers × HeadDim × Seq × B。
• Layers:模型的层数。
• HeadDim:每个注意力头的维度。
• Seq:一个block里的序列长度,默认为128。
• B:k/v数值精度对应的字节数。
• 对于llama-7b模型,2K序列长度,k/v block内存为1G。
• 状态迁移:
• 缓存状态可以迁移,包括从Free(空闲)到Active(活跃)的分配(Allocate),以及从Active到Cache的锁定(Lock)和解锁(Unlock)。
• 当缓存空间不足时,可能会发生驱逐(Evict)操作,将某些block从缓存中移除。
右侧图示:Block 状态和状态迁移
• Block 状态:
• Free:未被任何序列占用。
• Active:被正在推理的序列占用。
• Cache:被缓存中的序列占用。
• Block 状态迁移:
• 当序列S0到达时,如果有足够的空闲block,这些block会转为active状态。
• 当S0结束时,S0占用的block会转回cache状态。
• 当序列S1到达时,如果有足够的空闲block,这些block会转为active状态。
• 如果S2申请不到足够的空闲block,会驱逐S0的cache block,将其转为free状态,然后重新获取足够的free blocks(这里驱逐就相当于丢弃,等后面再来再重新计算,一般不会卸载到内存的,因为非常慢)。
• 这个过程会随着时间(t0,t1,t2,t3,t4)进行,确保每个序列在推理时都有足够的资源。
总结:
Blocked k/v cache机制通过管理block的状态(Free,Active,Cache)和在不同状态之间的迁移,有效地支持了分页注意力和有状态推理。这种设计允许TurboMind引擎在处理连续对话或序列化任务时,能够高效地利用缓存资源,提高推理性能。
比如说用DeepSeek,第一次提问他有了一个答复,第二次一问他告诉你超时了,因为他重新去申请这个缓存的时候,申请不到别人把这个队列给占了。
4.高性能的cuda内核
通过Flash attention 2对KV Cache将中间状态的缓存进行分级管理、Split-k decoding、Fast w4a16、 kv8、 算子融合这些方式来进行计算加速或者说解码加速
5.推理服务
通过:lmdeploy serve_api 模型路径 -model-name 模型名称 -server-prot 端口,来实现模型推理提供给前端或者后端使用
6.lmDeploy分布式推理
1.分布式推理实现
1.核心机制
张量并行: 通过--tp参数指定GPU数量,支持多卡协同计算
KV Cache量化:支持INT8/INT4量化,降低显存占用24% ,他是一种可以让模型在推理过程中进行量化的技术,比如说现在有一个模型是FP16位的lmDeploy推理的时候,可以做两个操作:
第一个操作:先把这个模型给它通过框架量化到int 8或者int 4,这个模型就变成一个八位的模型或者四位的一个模型了,再去直接去推理它。
第二种操作:可以先不去量化这个模型,然后这个F16的模型通过lmDeploy加载的时候,在加载过程中对它进行量化,这就是动态的显存管理,它是通过--cache-max-entry-count来控制KV缓存的比例的,这是这个lmDeploy框架的一个核心特色。
动态显存管理: 通过--cache-max-entry-count控制KV缓存比例。
缓存量化的实现: 通过缓存多轮对话过程中 attention 的 k/v,记住对话历史,从而避免重复处理历史会话。显著提升长文本多轮对话场景中的效率。就是我们通过缓存多轮对话过程中的这个attention的什么KV值,来记住对话的历史,从而避免重复处理历史会话。引入这个技术会有一个额外的开销,显存占用会变高,所以如果用lmdeploy去推理一个模型,从刚开始的时候去推理的时候的话,它显存占用会要变低一些,但是如果这个对话特别的长,显存如果不做控制就会显存溢出,因为它要将对话存到我们的显存里面。
2.进行分布式推理
lmdeploy serve api_server /root/lanyun-tmp/LLM/Qwen/Qwen2.5-1.5B-Instruct --tp 2 --model-name Qwen --server-port 23333
api_server 启动时的参数可以通过命令行lmdeploy serve api_server -h查看。
比如:--tp 设置张量并行,--session-len 设置推理的最大上下文窗口长度,
--cache-max-entry-count 调整 k/v cache 的内存使用比例等等。
--cache-max-entry-count 这个参数不建议去设置,因为我们不填参数的情况下,它是默认进行配置的
--model-name Qwen 指定后在api调用时:
chat_complition = client.chat.completions.create(messages=chat_history,model="/root/lanyun-tmp/LLM/Qwen/Qwen2.5-1.5B-Instruct")
就可以修改为:
chat_complition = client.chat.completions.create(messages=chat_history,model="Qwen")
#多轮对话
from openai import OpenAI
#定义多轮对话方法
def run_chat_session():
#初始化客户端
client = OpenAI(base_url="http://localhost:23333/v1/",api_key="lmDeploy")
#初始化对话历史
chat_history = []
#启动对话循环
while True:
#获取用户输入
user_input = input("用户:")
if user_input.lower() == "exit":
print("退出对话。")
break
#更新对话历史(添加用户输入)
chat_history.append({"role":"user","content":user_input})
#调用模型回答
try:
chat_complition = client.chat.completions.create(messages=chat_history,model="Qwen")
#获取最新回答
model_response = chat_complition.choices[0]
print("AI:",model_response.message.content)
#更新对话历史(添加AI模型的回复)
chat_history.append({"role":"assistant","content":model_response.message.content})
except Exception as e:
print("发生错误:",e)
break
if __name__ == '__main__':
run_chat_session()
显存占用情况:同样是只启动没推理的情况下,显存占用也比vLLM少
7.模型量化
1.AWQ离线量化
export HF_MODEL=/root/lanyun-tmp/LLM/Qwen/Qwen2.5-1.5B-Instruct
export WORK_DIR=/root/lanyun-tmp/LLM/Qwen/Qwen2.5-1.5B-Instruct-4bit
lmdeploy lite auto_awq \
$HF_MODEL \
--calib-dataset 'ptb' \
--calib-samples 128 \
--calib-seqlen 2048 \
--w-bits 4 \
--w-group-size 128 \
--batch-size 1 \
--work-dir $WORK_DIR
参数详解:
| 参数 | 说明 | 示例值 | 作用分析 |
|---|---|---|---|
$HF_MODEL | 原始模型的路径(必填) | /root/lanyun-tmp/LLM/Qwen/Qwen2.5-1.5B-Instruct | 指向未量化的HF格式模型目录,如Huggingface仓库本地路径 |
--work-dir | 量化后模型的输出目录 | /root/lanyun-tmp/LLM/Qwen/Qwen2.5-1.5B-Instruct-4bit | 保存量化后的模型文件、配置和校准数据 |
--calib-dataset | 校准数据集类型 | ptb(Penn Treebank) | 用于量化时激活值统计的基准数据集,常见选择: - ptb:小型通用文本 - c4:大规模网络文本 - pile:学术文本混合 |
--calib-samples | 校准样本数量 | 128 | 从数据集中选取的样本数量,影响量化精度: - 样本越多 → 量化误差越小,但耗时增加 - 推荐范围:128-512 |
--calib-seqlen | 每个校准样本的序列长度 | 2048 | 单样本的token长度,应与实际推理场景匹配: - 长文本场景(如文档摘要)需增大此值 |
--w-bits | 权重(Weight)量化位宽 | 4 | 权重被量化为4-bit(默认使用INT4格式),对比: - 8:更高精度,但体积翻倍 - 若省略此参数 → 默认FP16/BF16不量化 |
--w-group-size | 分组量化大小 | 128 | 将权重矩阵按组分割后独立量化: - 值越小 → 量化粒度越细,精度越高,但计算开销越大 - 值越大 → 压缩率更高,速度更快 - 典型值:64/128/256 |
--batch-size | 校准时的批处理大小 | 1 | 校准过程中的批次大小,影响显存占用和速度: - 低值(如1) → 减少显存占用,适合小内存GPU - 高值(如8) → 加速校准,但需足够显存 |
绝大多数情况下,在执行上述命令时,可选参数可不用填写,使用默认的即可。比如量化 /root/lanyun-tmp/LLM/Qwen/Qwen2.5-1.5B-Instruct 模型,命令可以简化为:
lmdeploy lite auto_awq /root/lanyun-tmp/LLM/Qwen/Qwen2.5-1.5B-Instruct --work-dir /root/lanyun-tmp/LLM/Qwen/Qwen2.5-1.5B-Instruct-4bit
开学术加速在执行上面的命令不然访问HuggingFace贼慢:source /etc/network_turbo
量化后:
2.W8A8量化
int8 量化:lmdeploy lite smooth_quant /root/lanyun-tmp/LLM/Qwen/Qwen2.5-1.5B-Instruct --work-dir /root/lanyun-tmp/LLM/Qwen/Qwen2.5-1.5B-Instruct -int8 --quant-dtype int8
fp8 量化:lmdeploy lite smooth_quant /root/lanyun-tmp/LLM/Qwen/Qwen2.5-1.5B-Instruct --work-dir /root/lanyun-tmp/LLM/Qwen/Qwen2.5-1.5B-Instruct -fp8 --quant-dtype fp8
3.Key-Value(KV) Cache 量化
lmDeploy版本要求:v0.4.0,支持在线 kv cache int4/int8 量化,量化方式为 per-head per-token 的非对称量化。原来的 kv 离线量化方式移除。
从直观上看,量化 kv 有利于增加 kv block 的数量。与 fp16 相比,int4/int8 kv 的 kv block 分别可以增加到 4 倍和 2 倍。这意味着,在相同的内存条件下,kv 量化后,系统能支撑的并发数可以大幅提升,从而最终提高吞吐量。
但是,通常,量化会伴随一定的模型精度损失。我们使用了 opencompass 评测了若干个模型在应用了 int4/int8 量化后的精度,int8 kv 精度几乎无损,int4 kv 略有损失。详细结果放在了精度评测章节中。大家可以参考,根据实际需求酌情选择。
LMDeploy kv 4/8 bit 量化和推理支持如下 NVIDIA 显卡型号:
- volta 架构(sm70): V100
- 图灵架构(sm75):20系列、T4
- 安培架构(sm80,sm86):30系列、A10、A16、A30、A100
- Ada Lovelace架构(sm89):40 系列
- Hopper 架构(sm90): H100, H200
总结来说,LMDeploy kv 量化与前面的方法相比具备以下优势:
- 量化不需要校准数据集
- 支持 volta 架构(sm70)及以上的所有显卡型号
- kv int8 量化精度几乎无损,kv int4 量化精度在可接受范围之内
- 推理高效,在 llama2-7b 上加入 int8/int4 kv 量化,RPS 相较于 fp16 分别提升近 30% 和 40%
通过 LMDeploy 应用 kv 量化非常简单,只需要设定 quant_policy 参数。 LMDeploy 规定 qant_policy=4 表示 kv int4 量化,quant_policy=8 表示 kv int8 量化。
在线量化推理命令:lmdeploy serve api_server /root/lanyun-tmp/LLM/Qwen/Qwen2.5-1.5B-Instruct --quant-policy 8
这种量化的优势在于我们的模型依然是什么16位的。但是我们推理模型的时候,是以八位的形式来推理的,它的推理速度会更快,但是从nvitop看显存占用是看不出来的,因为这个显存的占用是由框架来分配的,所以用nvitop看它是一模一样的,它最大的区别在于,现在模型可以输入更长的长度。
4.如何计算模型的体积
以一个7B模型为例,就是我们模型所需要的显存是多少?
首先:7B的这个B是什么,他代表7Billion也就是70亿个参数
然后:查看模型的配置文件:torch_dtype:bfloat16 现在大多数模型都是16位的,bfloat16代表的意思就是每个参数用的是16位的浮点数。
位(bit): 计算机中最小的数据单位,表示二进制的一位(0 或 1)。
字节(Byte): 计算机中最基本的存储单位,1 字节 = 8 位,能表示 2⁸ = 256 种不同状态(如字符或数值)。
1.确定参数量: (例如7B参数 = );
2.确定数据类型占用字节: 上面是bfloat16 代表每个参数占用2个字节的存储空间;
3.计算总字节数: = ;
4.转换标准:
5.转换为GB:
6.模型推理部署:上面得出来7B的模型需要占用显存的大小是14GB,但是显存至少需要16个G才能推理这个模型,因为服务器还会有其他程序来占用这个显存,如果是微调训练,那还涉及到了中间层的存储和反向传播过程,它需要比这个空间要大得多。
7.有人访问时如何计算显存:假设模型的max_length为8000,hidden_size=1000(这个是模型的维度d_model),就相当于是8000个参数,1个人提问推理时占用显存为:8000×1000×2=16000000=16MB(实际会占用更高因为还有位置编码,注意力掩码等那些东西),所以的模型在推理时显存的占用应该控制在90%左右。
8.常见的问题:
厂商标注的显存24GB和系统显示的GiB不同?
因为厂商按 十进制GB(10^9 Byte) 标称的,操作系统按二进制GiB(1024^3 Byte) 统计的。
例如:一块标称24 GB显存的显卡,系统会显示为:
Gibibyte(GiB): 是二进制的存储容量单位,全称为 Gibi Binary Byte,主要用于精确衡量计算机内存、显存、文件大小等场景。
5.模型部署
定义 : 将训练好的模型在特定软硬件环境中启动的过程,使模型能够接收输入并返回预测结果,为了满足性能和效率的需求,常常需要对模型进行优化,例如模型压缩和硬件加速
产品形态: 云端、边缘计算端、移动端
计算设备: CPU、GPU、NPU、TPU等
1.大模型的特点
内存开销巨大:
- 庞大的参数量,7B模型仅权重就需要14+G内存
- 采用自回归生成token,需要缓存Attention的kN,带来巨大的内存开销
动态shape :
- 请求数不固定
- Token逐个生成,且数量不定
相对视觉模型,LLM结构简单:
- Transformers结构,大部分是decoder--only
2.大模型部署挑战
设备 :
- 如何应对巨大的存储问题?
- 低存储设备(消费级显卡、手机等)如何部署?
推理 :
- 如何加速token的生成速度 如何解决动态shape,让推理可以不间断
- 如何有效管理和利用内存
服务 :
- 如何提升系统整体吞吐量?
- 对于个体用户,如何降低响应时间?
3.大模型部署方案
技术点:
- 模型并行
- transformer计算和访存优化
- 低比特量化
- Continuous Batch:动态合并不同长度的请求到一个计算批次,最大化GPU利用率,通过窗口期缓冲来实现,比如我们调用大模型时,可能会等个几秒,将不同的批次合并到一起使得每次访问模型的批次尽可能都相等
- Page Attention:借鉴OS内存分页机制,高效管理KV Cache
方案:
- huggingface transformers
- 专门的推理加速框架
| 云端 | 移动端 |
|---|---|
| LmDeploy, vLLM, tensorrt-llm, DeepSpeed | llama.cpp, mlc-llm |
