专栏
DeepSpeed简介
- DeepSpeed 是由微软开发的开源深度学习优化库,旨在加速大规模模型的训练和推理。它通过创新的内存优化、分布式训练技术和高效的通信策略,显著降低了训练大模型所需的计算资源和时间。DeepSpeed 支持 ZeRO(Zero Redundancy Optimizer)技术,能够有效减少显存占用,使训练超大规模模型成为可能。此外,DeepSpeed 还提供了混合精度训练、梯度累积、模型并行等功能,适用于从单机到多节点的各种硬件环境。DeepSpeed 广泛应用于自然语言处理、计算机视觉等领域,是训练和部署大模型的强大工具。
DeepSpeed 实践
- 因为之前装vllm分布式ray集群的时候用的cuda 11.8版本,现将其升级到cuda 12.5版本, 注意关于cuDNN, PyTorch会使用自带的库,通常位于 PyTorch 安装目录中
nvcc --version

升级cuda(可选,如果你的已经是cuda12.x版本则忽略)
- 注: 后面介绍的蒸馏技术也需要要升级cuda版本,这样坑少一些
- 执行下面命令, 能在/usr/local看到cuda-12.5目录
cd /usr/local
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-ubuntu2204.pin
sudo mv cuda-ubuntu2204.pin /etc/apt/preferences.d/cuda-repository-pin-600
wget https://developer.download.nvidia.com/compute/cuda/12.5.0/local_installers/cuda-repo-ubuntu2204-12-5-local_12.5.0-555.42.02-1_amd64.deb
sudo dpkg -i cuda-repo-ubuntu2204-12-5-local_12.5.0-555.42.02-1_amd64.deb
sudo cp /var/cuda-repo-ubuntu2204-12-5-local/cuda-*-keyring.gpg /usr/share/keyrings/
sudo apt-get update
sudo apt-get -y install cuda-toolkit-12-5
vim ~/.bashrc
export PATH=/usr/local/cuda-12.5/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda-12.5/lib64:$LD_LIBRARY_PATH
export LIBRARY_PATH=/usr/local/cuda-12.5/lib64:$LIBRARY_PATH
export CUDA_LAUNCH_BLOCKING=1
source ~/.bashrc
gcc升级(可选)
sudo apt-get purge gcc g++
sudo apt install gcc-12
sudo ln -s /usr/bin/gcc-12 /usr/bin/gcc
gcc --version

nvida驱动重新安装
- 执行下面命令,然后reboot重启,我这边遇到conda activate xxx环境被搞坏了删掉重装才生效DeepSpeed分布式多机多卡部署
sudo apt-get update
sudo apt-get upgrade
sudo apt-get install nvidia-driver-555
重新安装torch等
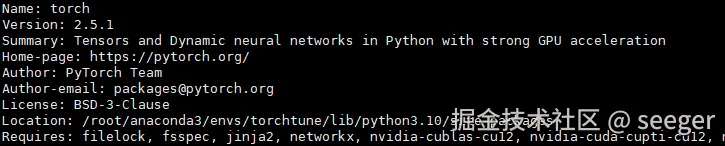
pip show torch
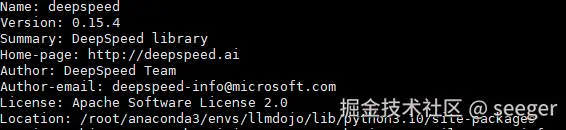
pip show deepspeed
ssh免密
- 这边用两台机器做DeepSpeed多机多卡测试,需要处理两台机器的ssh免密, 我这边端口是20022不是传统的22这个要根据你们自己的端口进行更改
ssh-keygen -t rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
ssh -p 20022 root@xxx cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
scp -P 20022 ~/.ssh/authorized_keys root@xxx:~/.ssh/authorized_keys
cd ~/.ssh
sudo chmod 755 ~/.ssh
sudo chmod 644 authorized_keys
ssh-add
# 更改配置
vim ~/.ssh/config
Host *
Port 20022
# 测试
ssh -p 20022 root@xxx
sudo apt install pdsh
vim /etc/pdsh/rcmd_default
ssh
cat /etc/pdsh/rcmd_default
- 查看/etc/ssh/sshd_config有个参数Port是否是我这边更改的20022,是的话pdsh就可以连了
简单测试NCCL是否可通
python -m torch.distributed.launch --nproc_per_node=2 --nnodes=2 --node_rank=0 --master_addr=xxx --master_port=29500 /usr/local/nccl_test.py
# nccl_test.py 具体代码
import os
import torch
import torch.distributed as dist
def run():
rank = int(os.environ['RANK'])
world_size = int(os.environ['WORLD_SIZE'])
local_rank = int(os.environ['LOCAL_RANK'])
dist.init_process_group("nccl")
tensor = torch.ones(1).to(local_rank)
dist.all_reduce(tensor, op=dist.ReduceOp.SUM)
if rank == 0:
print(f"All-reduce result: {tensor.item()}")
print(f"Expected result: {world_size}")
if tensor.item() == world_size:
print("NCCL test passed successfully!")
else:
print("NCCL test failed!")
dist.destroy_process_group()
if __name__ == "__main__":
run()
# 主节点执行nproc_per_node根据各自机器gpu情况来写
python -m torch.distributed.launch --nproc_per_node=2 --nnodes=2 --node_rank=0 --master_addr=NODEA --master_port=29500 /usr/local/nccl_test.py
# 备节点执行
python -m torch.distributed.launch --nproc_per_node=1 --nnodes=2 --node_rank=1 --master_addr=NODEA --master_port=29500 /usr/local/nccl_test.py


执行多机多卡加速
- 注意多台机器环境设置完之后所有的路径要一致,记住是所有包含miniconda之类的。多头64我又只有三个gpu导致只有两台机器两个gpu运行。
- 我在测试时有执行下面命令ens3是我的网卡地址,gloo理论这个设置没起作用,这边只是记录下
export CUDA_VISIBLE_DEVICES="0,1"
export NCCL_SOCKET_IFNAME="ens3"
export NCCL_TIMEOUT="60"
export NCCL_IB_DISABLE="1"
export NCCL_DEBUG="INFO"
export NCCL_P2P_DISABLE="1"
export NCCL_P2P_LEVEL="NVL"
export NCCL_IBEXT_DISABLE="1"
export TORCH_DISTRIBUTED_BACKEND="gloo"
- 由于显卡资源有限,我的deepspeed使用的是zero2阶段,你们可以自由选择,下面是我的ds_zero2_v2.yaml配置
compute_environment: LOCAL_MACHINE
debug: false
deepspeed_config:
deepspeed_hostfile: /root/hostfile
deepspeed_multinode_launcher: pdsh
offload_optimizer_device: cpu
zero3_init_flag: false
zero_stage: 2
distributed_type: DEEPSPEED
downcast_bf16: 'no'
machine_rank: 0
main_process_ip: NODEA
main_process_port: 21011
main_training_function: main
mixed_precision: 'bf16'
num_machines: 2
num_processes: 3
rdzv_backend: static
same_network: true
tpu_env: []
tpu_use_cluster: false
tpu_use_sudo: false
use_cpu: false
- /root/hostfile文件, NODEA改成你主节点ip,NODEB备节点ip, slots是你的显卡张数
NDOEA slots=2
NDOEB slots=1
- 主节点或者备节点执行deepspeed加速,CUDA_VISIBLE_DEVICES=0,1看你显卡数量
CUDA_VISIBLE_DEVICES=0,1 accelerate launch --config_file /usr/local/src/LLM-Dojo/rlhf/ds_config/ds_zero2_v2.yaml xxx.py
--model_name_or_path /usr/local/Llama-3.2-1B-Instruct/Llama-3.2-1B-Instruct \
-- xxxx各种各样的配置
nvidia-smi
- 下面是我使用KD蒸馏时候的deepspeed多机多卡加速日志,可以看到使用了pdsh还有配置的export nccl都正确使用了,格式被我简化了
cmd = pdsh -S -f 1024 -w NODEA,NODEA
export PYTHONPATH="/root"
export SHELL="/bin/bash"
export CONDA_EXE="/root/miniconda3/bin/conda"
export PWD="/root"
export LOGNAME="root"
export XDG_SESSION_TYPE="tty"
export CONDA_PREFIX="/root/miniconda3/envs/llmdojo"
export MOTD_SHOWN="pam"
export HOME="/root"
export LANG="en_US.UTF-8"
export XDG_SESSION_CLASS="user"
export TERM="xterm"
export USER="root"
export CONDA_SHLVL="1"
export DISPLAY="localhost:10.0"
export SHLVL="1"
export XDG_SESSION_ID="4885"
export CONDA_PYTHON_EXE="/root/miniconda3/bin/python"
export XDG_RUNTIME_DIR="/run/user/0"
export CONDA_DEFAULT_ENV="llmdojo"
export XDG_DATA_DIRS="/usr/local/share:/usr/share:/var/lib/snapd/desktop"
export PATH="/root/miniconda3/envs/llmdojo/bin:/usr/local/cuda-12.5/bin:/root/miniconda3/condabin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/snap/bin:/root/miniconda3/bin"
export DBUS_SESSION_BUS_ADDRESS="unix:path=/run/user/0/bus"
export SSH_TTY="/dev/pts/0"
export _="/root/miniconda3/envs/llmdojo/bin/accelerate"
export CUDA_MODULE_LOADING="LAZY"
export ACCELERATE_MIXED_PRECISION="bf16"
export ACCELERATE_CONFIG_DS_FIELDS="deepspeed_hostfile,deepspeed_multinode_launcher,offload_optimizer_device,zero3_init_flag,zero_stage,mixed_precision"
export ACCELERATE_USE_DEEPSPEED="true"
export ACCELERATE_DEEPSPEED_ZERO_STAGE="2"
export ACCELERATE_DEEPSPEED_OFFLOAD_OPTIMIZER_DEVICE="cpu"
export ACCELERATE_DEEPSPEED_ZERO3_INIT="false"
export CUDA_LAUNCH_BLOCKING="1"
export LIBRARY_PATH="/usr/local/cuda-12.5/lib64:"
export LD_LIBRARY_PATH="/usr/local/cuda-12.5/lib64:"
export CUDA_VISIBLE_DEVICES="0,1"
export NCCL_SOCKET_IFNAME="ens3"
export NCCL_TIMEOUT="60"
export NCCL_IB_DISABLE="1"
export NCCL_DEBUG="INFO"
export NCCL_P2P_DISABLE="1"
export NCCL_P2P_LEVEL="NVL"
export NCCL_IBEXT_DISABLE="1"
export TORCH_DISTRIBUTED_BACKEND="gloo"
cd /root
/root/miniconda3/envs/llmdojo/bin/python -u -m deepspeed.launcher.launch --world_info=eyIxODMuNi4yMTEuMTk4IjogWzBdLCAiMTIxLjMyLjIzNi4yMzgiOiBbMF19 --node_rank=%n --master_addr=NODEA --master_port=21011 --no_local_rank /usr/local/src/LLM-Dojo/rlhf/train_gkd.py --model_name_or_path /usr/local/Llama-3.2-1B-Instruct/Llama-3.2-1B-Instruct --teacher_model_name_or_path /usr/local/llama-3-7B-lora-trans-export --dataset_name /usr/local/src/LLM-Dojo/converted_data.json --learning_rate 2e-5 --per_device_train_batch_size 3 --gradient_accumulation_steps 2 --output_dir gkd-model2 --logging_steps 2 --dataset_batch_size 3 --num_train_epochs 1 --gradient_checkpointing --lmbda 0.5 --beta 0.5 --use_peft --lora_r 8 --lora_alpha 16 --trust_remote_code --bf16 --save_strategy steps --save_steps 180 --save_total_limit 5 --warmup_steps 0 --lr_scheduler_type cosine --seq_kd True --torch_dtype auto
参考文章


