

概述
一个最基本的阅读器实现需要拿到以下数据
- 搜索:通过书名/作者搜索到对应的书籍,能展示最基本的信息(封面、书名、作者)
- 书籍详情:书籍详情中展示封面、书名、作者、分类、简介、章节目录等信息
- 章节内容
原理
- 定向解析第三方书源请求地址、返回数据,维护一套解析表
- 数据获取:
- h5:因为涉及到跨域问题,得启用后端服务器去请求地址去爬数据
- app:无跨域问题,直接使用 uni.request 请求就行 # 什么是跨域
- ua:app端 ua 是固定的 # 默认User Agent,大部分网站的反爬虫机制也没有那么严格
- 数据解析:使用# Cheerio
- Cheerio 是一个在 Node.js 环境中实现了 jQuery 核心功能的库,它专为服务器端的 HTML 解析和操作而设计。它允许开发者在 Node.js 中使用 jQuery 风格的语法,轻松地操作 HTML 或 XML 文档,而无需在浏览器环境中运行。
- Cheerio 可以跨平台运行,可维护性强
- 因为环境不同,所以需要维护两套解析服务
观察网站请求可以发现,小说搜索请求了
/tag/地址,请求参数为key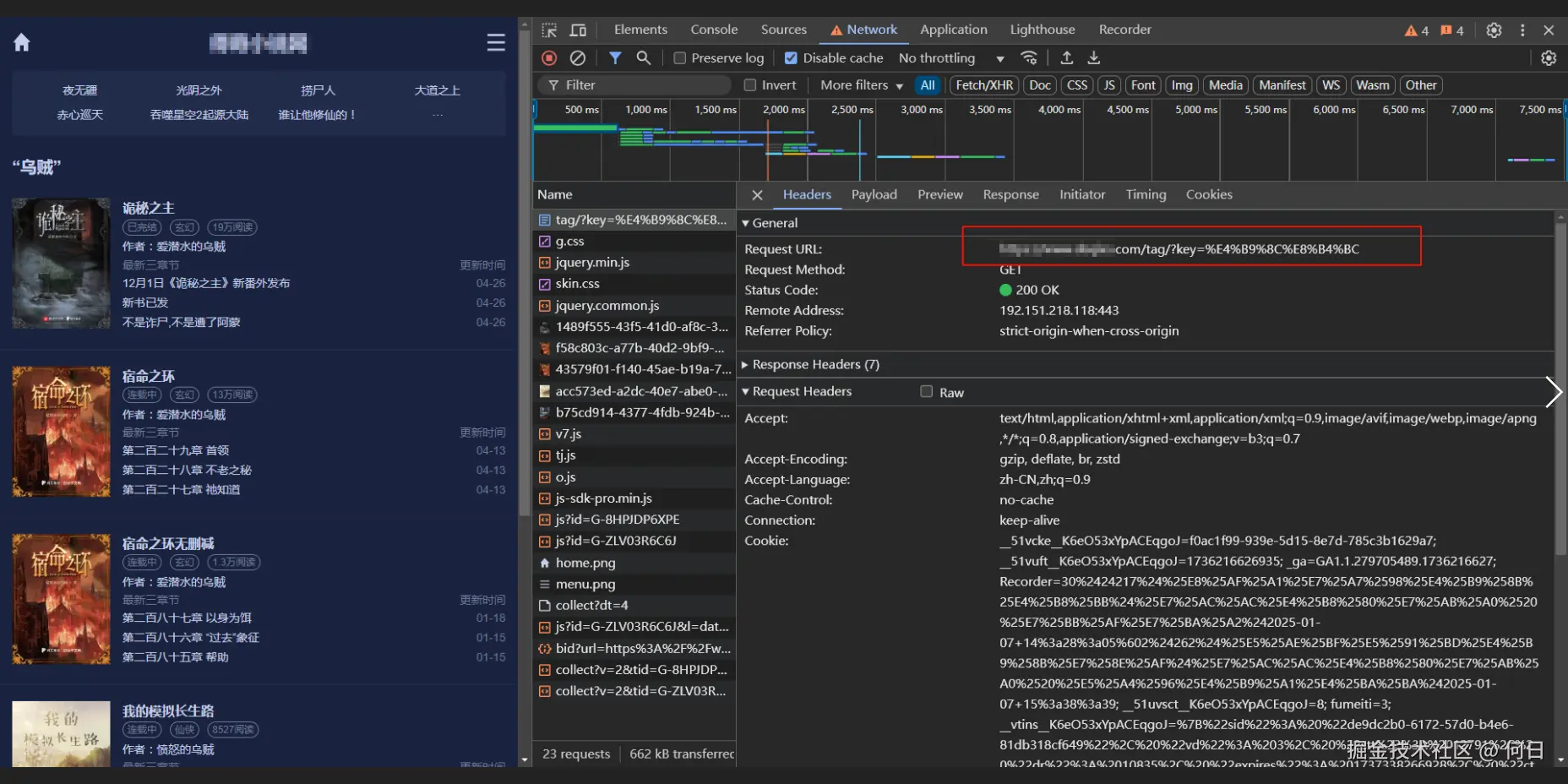
搜索书籍数据解析
最终实现只是解析返回的html结构,得到想要的数据
- 观察返回html结构
- 封面地址:对应 container 下面的 item 的 a 标签下面的 img 的src属性
- 书名:对应 container 下面的 item 的 itemtxt 下面 h3 下面 a 标签的text
- pathname:
/xiaoshuo/30/点进去发现就是目录页
- 解析规则配置
- 小说列表:
$(rules.wrapContainer.selector)得到每一个book - 遍历,根据配置规则进行处理得到小说信息
- 小说列表:
function paraseSearchContent(res: string, item: any) {
const bookList: searchBookList[] = [];
const { rules } = item.search;
const $ = cheerio.load(res);
// 第一步:获取类
const wrapperContainer = $(rules.wrapContainer.selector);
// 第二步:遍历每个元素,提取其内部具体内容
wrapperContainer.each((index, element) => {
// 封面 书名 作者 目录地址 分类 最新章节 最近更新时间
const { image, bookName, author, pathname, categories, latestChapter } = rules.infomation;
const bookInfo = {
origin: item.origin,
bookName: "",
author: "",
image: "",
pathname: "",
categories: "",
latestChapter: "",
};
// [key, keyRules]
const handlers = [
["image", image],
["bookName", bookName],
["author", author],
["pathname", pathname],
["categories", categories],
["latestChapter", latestChapter],
];
type HanderKeys = "image" | "bookName" | "author" | "pathname" | "categories" | "latestChapter";
handlers.forEach((arr) => {
const key: HanderKeys = arr[0];
const rule = arr[1];
if (!rule) return;
const ele = $(element).find(rule.selector);
if (ele) {
// 处理 封面,默认取src属性
if (key === "image") {
bookInfo[key] = ele.attr(rule.attr || "src") || "";
} else if (key === "pathname") {
// 处理 目录页地址,默认取 href 属性
bookInfo[key] = ele.attr(rule.attr || "href") || "";
} else {
// 处理其他内容,取text值
bookInfo[key] = ele.text() || "";
}
// 有的链接地址是一个相对路径,拼接得到完整地址
if (rule.subPath) {
bookInfo[key] = `${item.origin}${bookInfo[key]}`;
}
}
// 选择第几个元素,针对于不方便通过类筛选的情况
if (rule?.hasOwnProperty("nthchild")) {
const num = rule.nthchild;
if (ele?.length >= num + 1) {
const text = ele.eq(num).text() || "";
bookInfo[key] = text;
}
}
// 处理文本内容
if (rule?.handler) {
Object.entries(rule.handler).forEach(([type, value]) => {
switch (type) {
case "replace":
bookInfo[key] = bookInfo[key].replace(new RegExp(value as string, "g"), rule.handler?.replaceValue || "");
break;
default:
break;
}
});
}
bookInfo[key] = bookInfo[key].trim();
});
bookList.push(bookInfo);
});
return bookList;
}
目录详情的解析
和小说搜索类似,只是配置了不同的规则
export const getCatalogs = async (params: { url: string }) => {
let content = (await getDeepthHtml(params.url)) as bookInfo;
const result = handlerCatelogs(content);
return Promise.resolve(result);
};
const getDeepthHtml = async (url: string, content: AnyObject = {}) => {
try {
let res = (await api.getCatalogsByApp(url)) as string;
if (res) {
const parse = URLPolyfill(url);
const targetSource = source.find((i) => i.origin === parse.origin);
if (targetSource) {
const $ = cheerio.load(res);
const { wrapContainer, infomation, pagination, redirect } = targetSource.catalogs.rules;
let info = {
bookName: "",
author: "",
image: "",
categories: "",
latestChapter: "",
latestUpdateTime: "",
description: "",
};
const reflect = [
["bookName", infomation.bookName],
["author", infomation.author],
["image", infomation.image],
["categories", infomation.categories],
["latestChapter", infomation.latestChapter],
["latestUpdateTime", infomation.latestUpdateTime],
["description", infomation.description],
];
type HanderKeys =
| "bookName"
| "author"
| "image"
| "categories"
| "latestChapter"
| "latestUpdateTime"
| "description";
reflect.forEach((arr: any) => {
const key: HanderKeys = arr[0];
const rule = arr[1];
let node = $(rule.selector);
if (rule?.hasOwnProperty("nthchild")) {
const num = rule.nthchild;
if (node?.length >= num + 1) {
node = node.eq(num);
}
}
if (rule.type === "element") {
if (rule.attr) {
info[key] = node.attr(rule.attr) || "";
} else {
info[key] = node.text() || "";
}
if (rule.subPath) {
info[key] = `${parse.origin}${info[key]}`;
}
} else {
info[key] = node.attr("content") || "";
}
// 处理文字信息
if (rule?.handler) {
Object.entries(rule.handler).forEach(([type, value]) => {
switch (type) {
case "replace":
info[key] = info[key].replace(new RegExp(value as string, "g"), rule.handler?.replaceValue || "");
break;
default:
break;
}
});
}
});
if (!content.isParse) {
content = {
isParse: true,
origin: parse.origin,
pathname: parse.pathname,
links: [],
...info,
};
}
const wrapperContainer = $(wrapContainer.selector);
wrapperContainer.each((index, element) => {
let href = $(element).attr("href");
if (redirect) {
href = `${parse.pathname}${href}`;
}
content.links.push({
href,
text: $(element).text(),
});
});
if (redirect) {
let node = $(redirect.selector);
if (redirect?.hasOwnProperty("nthchild")) {
const num = redirect.nthchild;
if (node?.length >= num + 1) {
node = node.eq(num);
}
}
const redirectUrl = node.attr("href");
if (redirectUrl) {
const nextUrl = `${parse.origin}${redirectUrl}`;
content = await getDeepthHtml(nextUrl, content);
}
}
if (pagination) {
const nextPagination = $(pagination.selector).last();
let nextPath = nextPagination.attr("href");
let nextButtonName = nextPagination.text();
if (nextPath && nextButtonName === "下一页") {
const nextUrl = pagination.fullpath
? `${parse.origin}${parse.pathname}${nextPath}`
: `${parse.origin}${nextPath}`;
content = await getDeepthHtml(nextUrl, content);
}
}
}
}
} catch (error) {
console.log(error);
return content;
}
return content as bookInfo;
};
const handlerCatelogs = (content: bookInfo) => {
const array = content.links || [];
type LinkType = {
href: string;
text: string;
};
// 过滤重复的 href
const uniqueArray = Array.from(new Set(array.map((item) => item.href))).map((href) =>
array.find((item) => item.href === href),
) as LinkType[];
// 按照 xxxx.html 从小到大排序
uniqueArray.sort((a, b) => {
const numA = parseInt(a?.href?.split("/")?.pop()?.split(".html")[0] || "0");
const numB = parseInt(b?.href?.split("/")?.pop()?.split(".html")[0] || "0");
return numA - numB;
});
content.links = uniqueArray;
content.origins = [
{
origin: content.origin,
pathname: content.pathname,
},
];
return content;
};
注意
handlerCatelogs里有对章节列表做了一个简单的处理,过滤了重复的 href 和按照 xxxx.html 从小到大排序。绝大部分站点都是按照这个规则排序,但是也有特殊情况,所以这样的处理方式是不准确的。- 最好是在配置里面单独维护章节元素的选择器和重复处理,并在
getDeepthHtml里新增对应的解析内容
章节内容的解析
和章节解析类似
const getDeepthPage = async (url: string, content: AnyObject = {}) => {
try {
const res = (await api.getContentByApp(url)) as string;
if (res) {
const parse = URLPolyfill(url);
const targetSource = source.find((i) => i.origin === parse.origin);
if (targetSource) {
const $ = cheerio.load(res);
const { wrapContainer, titleContainer, pagination, lineBreak } = targetSource.content.rules;
if (!content.isParse) {
content = {
isParse: true,
text: "",
title: $(titleContainer.selector).text() || "",
};
}
if (lineBreak === "br") {
const txtElement = $(wrapContainer.selector);
// 将 <br> 标签替换为 \n
const modifiedHtml = txtElement.html()?.replace(/<br\s*\/?>/g, "\n");
// 获取修改后的文本内容
const text = cheerio.load(modifiedHtml || "").text();
content.text += text;
} else {
$(wrapContainer.selector).each((index, element) => {
const text = $(element).text();
content.text += `${text}\n`;
});
}
if (pagination) {
const nextPagination = $(pagination.selector).last();
const nextPath = nextPagination.attr("href") || "";
const nextPathText = nextPagination.text();
if (nextPath.startsWith("/") && nextPathText === "下一页") {
content = await getDeepthPage(`${parse.origin}${nextPath}`, content);
}
}
}
}
} catch (error) {
console.log(error, "error");
return content;
}
return content as ContentParser;
};
相关
- 耗时三个月,我高仿了一个起点小说阅读器
- 从零开始手撸一个阅读器--排版引擎的实现(1)
- 从零开始手撸一个阅读器--换源功能的实现(3)
- 从零开始手撸一个阅读器--数据结构与数据缓存(4)
- 从零开始手撸一个阅读器--夜间/白天主题色切换(5)
总结
其实书源解析的实现很简单,难点在于对各个书源的维护。
- 不同网站的请求方式不同,返回结构也不同(get,post,html,json等)。还有的网站做了一些反爬虫措施(时间限制,ua,ip限制等), 要支持这些不同类型的书源就需要单独每一种类型的站点做定制化配置。都是一些比较繁琐的工作。
- 不同网站对移动端和pc端的处理也不尽相同(有的是重定向到一个 m.xxx.com新地址,有的是通过ua标识针对不同端返回不同的html结构,还有的未作处理),要想更完善的实现书源管理,需要兼容不同端和不同站点。
- 第三方网站的具有不稳定性,网站任何一项变动都有可能导致书源解析的内容不准确。所以得及时维护每个书源的解析配置。
