来源:晓飞的算法工程笔记 公众号,转载请注明出处
论文: A Simple Image Segmentation Framework via In-Context Examples

创新点
- 探索了通用的分割模型,发现现有方法在上下文分割中面临任务模糊性的问题,因为并非所有的上下文示例都能准确传达任务信息。
- 提出了一个利用上下文示例的简单图像分割框架
SINE(Segmentation framework via IN-context Examples),利用了一个Transformer编码-解码结构,其中编码器提供高质量的图像表示,解码器则被设计为生成多个任务特定的输出掩码,以有效消除任务模糊性。
SINE引入了一个上下文交互模块,以补充上下文信息,并在目标图像与上下文示例之间产生关联,以及一个匹配Transformer,使用固定匹配和匈牙利算法消除不同任务之间的差异。- 完善了当前的上下文图像分割评估系统,实验结果表明,
SINE可以处理广泛的分割任务,包括少量样本的语义分割、少量样本的实例分割和视频目标分割。
内容概述
图像分割涉及在像素级别上定位和组织概念,比如语义分割、实例分割、全景分割、前景分割和交互分割。然而,现有的大多数分割方法都是针对特定任务量身定做的,无法应用于其他任务。
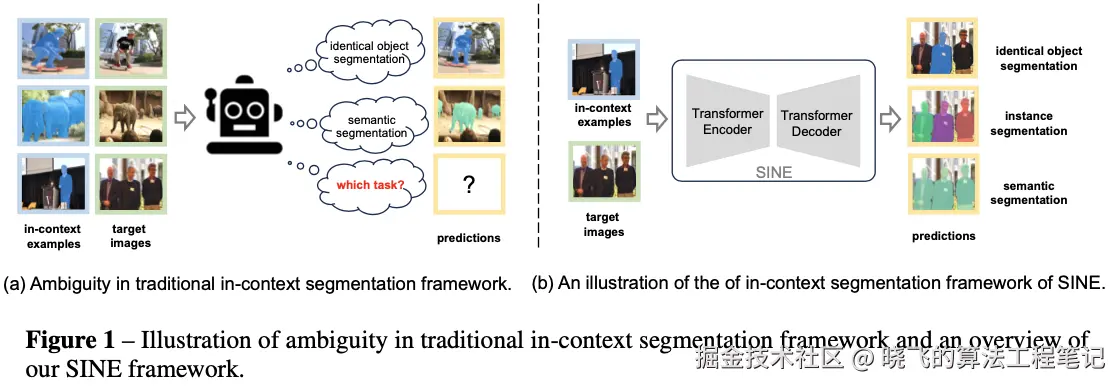
最近一些工作探索了通用分割模型,通过上下文学习解决多样且无限的分割任务。上下文分割模型需要理解上下文示例传达的任务和内容信息,并在目标图像上分割相关概念,但并不是所有的上下文示例都能准确传达任务信息。例如当提供一个特定个体的照片,是仅限于个体本身、涵盖所有人的实例分割,还是集中于语义分割?模糊的上下文示例可能使传统的上下文分割模型难以清晰地定义不同任务之间的边界,从而导致不期望的输出。
为了解决这个问题,论文提出了基于上下文示例的简单图像分割框架SINE(Segmentation framework via IN-context Examples)。受到SAM模型的启发,SINE预测针对不同复杂度任务定制的多个输出掩码。这些任务包括相同物体、实例到整体语义概念。SINE统一了现有的各种粒度的分割任务,旨在实现更广泛的任务泛化。
与SegGPT相比,SINE能够在可训练参数更少的情况下有效地解决上下文分割中的任务模糊性问题,而SegGPT仅输出语义分割结果。此外,论文进一步将少样本实例分割引入当前的评估系统,以便全面评估这些模型。
SINE
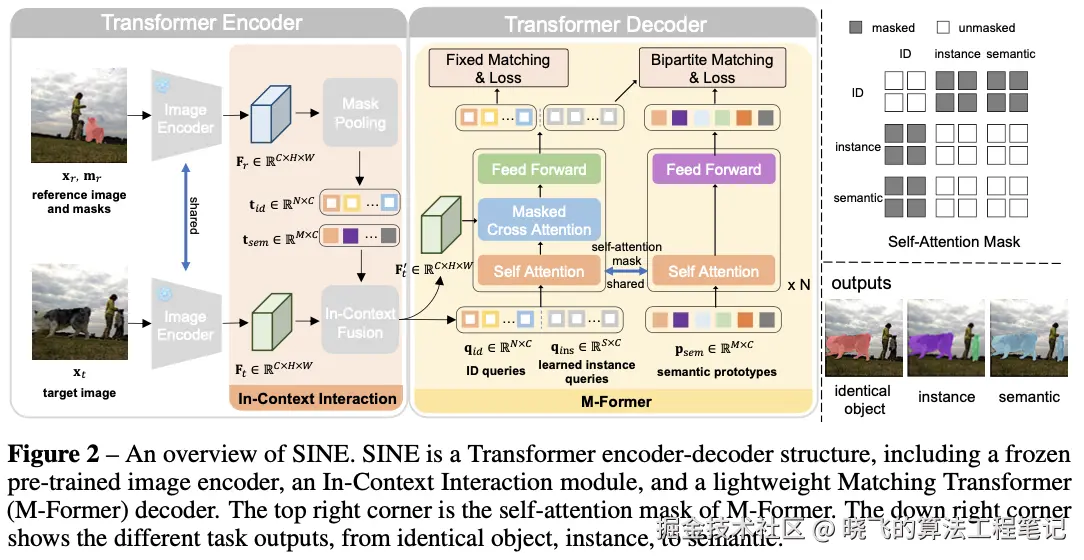
SINE是一个基于查询的分割模型,遵循DETR和Mask2Former的设计。使用相同对象(ID)查询 qid 来识别和定位目标图像中与参考图像中具有相同对应关系的对象,使用可学习的实例查询 qins∈RS×C 来识别和定位目标图像中与参考图像具有相同语义标签的对象。
SINE基于经典的Transformer结构,引入了一些针对上下文分割任务的有效设计,包括一个冻结的预训练图像编码器、一个上下文交互模块和一个轻量级匹配Transformer (M-Former) 解码器。
上下文交互
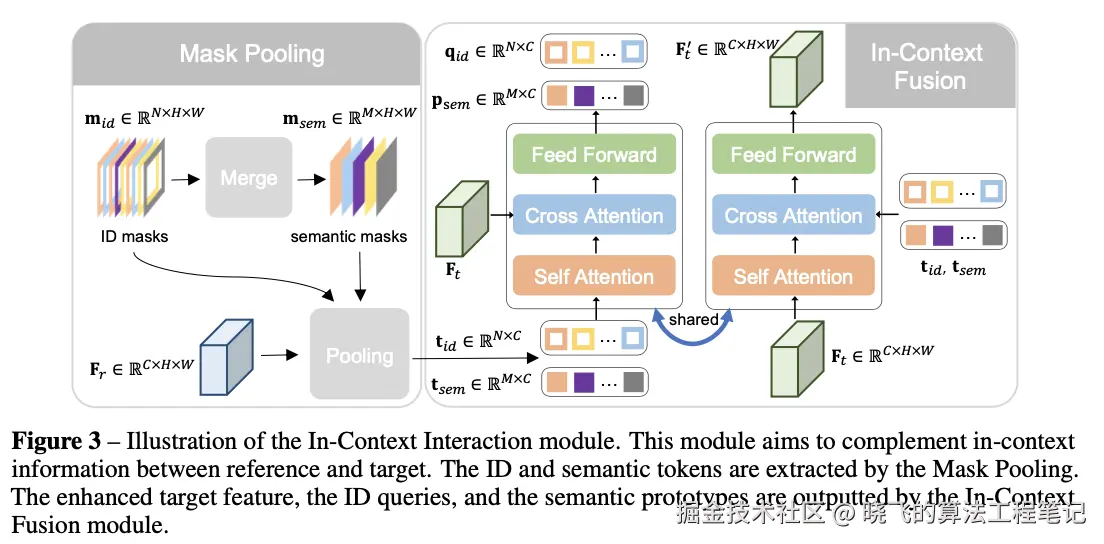
上下文交互的目的是补充上下文信息,并在参考图像特征和目标图像特征之间产生关联。
为每个掩码分配不同的ID标签,将参考掩码 mr 转换为ID掩码 mid∈RN×H×W ,通过将具有相同类别标签的掩码合并来得到语义掩码 msem∈RM×H×W ,其中 N 和 M 分别是ID掩码和语义掩码的数量。
然后,使用这些掩码对参考特征 Fr 进行池化,获得提ID标记 tid∈RN×C 和语义标记 tsem∈RM×C 。
上下文融合模块该模块是一个Transformer块,包括自注意力机制、交叉注意力机制和前馈网络,实现参考特征和目标特征之间的上下文关联:
⟨qid,psem,Ft′⟩=InContextFusion(tid,tsem,Ft;θ),
这些标记 ( tid 和 tsem ) 和目标特征 ( Ft ) 通过这个共享模块进行融合,在交叉注意力中它们彼此作为键和值,从而可以获得增强后的目标特征 Ft′ 、ID查询 qid 和语义原型 psem 。
匹配Transformer
为了有效地进行上下文分割并消除任务模糊性,M-Former实现了一个双路径的Transformer解码器,共享自注意力层。一路径用于与查询( qid 和 qins )交互,提取与目标图像中的上下文示例相关的特征。第二路径用于增强语义原型 psem 以实现更准确的匹配。这两条路径共享自注意力层,以便将语义从 psem 分配给 qins 。
M-Former共有 N 个块,整体的过程如下:
⟨qidl,qinsl,pseml⟩=MFormerl(qidl−1,qinsl−1,pseml−1;θl,Ft′),
对于实例分割,使用更新后的语义原型 psem 作为分类器,并让 y^ins={y^insi}i=1S 表示 S 个实例预测的集合。使用匈牙利损失来学习SINE,通过计算预测 y^insi 和GT yj 之间的分配成本以解决匹配问题,即 −pi(cj)+Lmask(m^insi,mj) ,其中 (cj,mj) 是GT对象的类别和掩码, cj 可能为 ∅ 。 pi(cj) 是第 i 个实例查询对应类别 cj 的概率, m^insi 表示其预测的掩码。 Lmask 是一种二元掩码损失和Dice损失:
LHungarian(y^ins,y)=∑j=1S[−logpσ(j)(cj)+1cj=∅Lmask(m^insσ(j),mj)],
其中 σ(j) 表示二分匹配的结果索引。
为了赋予SINE预测同一对象的能力,使用图像中同一实例的不同裁剪视图作为参考-目标图像对。设 y^id={y^idi}i=1N 表示 N 个ID预测的集合。
由于参考ID和目标ID之间的关系是固定的且可以准确确定,可以在预测和GT之间执行固定匹配,损失可以写为:
LID(y^id,y)=∑i=1N[−logpi(ci)+1ci=∅Lmask(m^idi,mi)],
其中 (ci,mi) 是GT的类别和掩码, ci∈{1,∅} , ci=1 表示一个对象同时出现在参考图像和目标图像中。总损失为 L=LHungarian+LID 。
一旦训练完成,SINE的全部能力在推理过程中得以释放,能够解决上下文示例中的模糊性并为不同的分割任务输出预测。
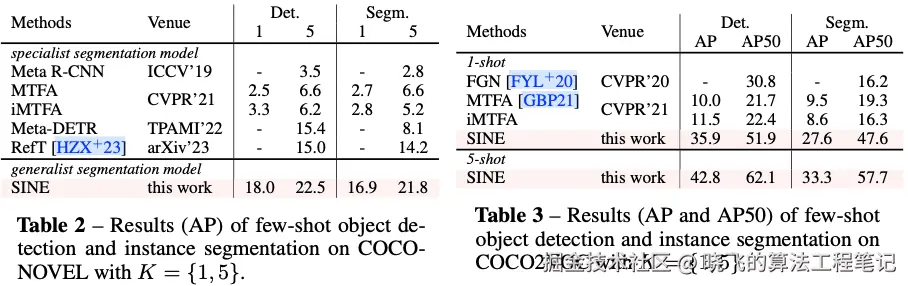
主要实验

如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】



