来源:晓飞的算法工程笔记 公众号,转载请注明出处
论文: Improving Object Detection via Local-global Contrastive Learning

创新点
- 提出了一种新颖的图像到图像转换方法,用于跨域物体检测。
- 该方法为一个具有引导先验的对比学习框架,通过空间注意力掩码优化物体实例的外观,隐式地将场景划分为与目标物体实例相关的前景区域和非物体的背景区域。
- 在转换过程中,该方法并不依赖物体标注来明确体实例,而是通过对比局部与全局信息来学习表示物体。
- 在三个具有挑战性的基准上进行了多个跨域物体检测设置的实验,得到了最先进的性能。
内容概述

检测模型通常依赖于大规模的标注数据来学习具有代表性的特征,但往往难以很好地泛化到存在视觉差异的新目标领域(如阴雾天气与晴朗天气场景)。图像到图像(I2I)转换旨在缓解输入级别的这种领域差距,从而减少视觉领域中的分布转移。
高成本的配对图像(领域间)数据收集促进了业界对无配对图像到图像转换的研究,但往往会导致严重的内容畸变和形状变形,这种失败可能会对下游物体检测任务的性能产生不利影响。指明物体实例可以为改善图像转换提供了直观的方向,但这依赖于物体标注,以便在目标领域中区分物体和背景的空间图像区域,从根本上限制了它们的适用性。
对比学习通过最大化对应输入和输出区域之间的互信息,已成为解决图像到图像转换的一种有前景的策略。但现有方法将图像转换视为一个全局任务,处理具有复杂局部结构的物体的图像时效果不佳。由于物体与背景之间的视觉差异通常很大,论文认为隐式地建模背景和前景物体区域可以提升局部显著区域的转换质量,从而显著改善下游物体检测。此外,前景和背景的分离可以通过局部-全局对比学习来实现。
基于这一直觉,论文提出了一种基于对比学习的图像到图像转换框架,用于跨域物体检测。该框架引入一种结构诱导先验,通过空间注意力掩码优化物体实例的外观,能够有效地将场景解构为背景和前景区域。
整体方案
用于无配对I2I转换的对比学习
自监督表示是在对比学习机制下,通过考虑字典查找任务实现的。给定一个编码查询 q ,任务是识别在一组编码键 {k0,k1,...} 中的与查询 q 匹配的唯一正键 k+ 。使用InfoNCE损失函数来使 q 靠近 k+ 的同时,推动其远离一组替代负键 {k−} :
LNCE=−logexp(q⋅k+/τ)+∑k−exp(q⋅k−/τ)exp(q⋅k+/τ)\labeleq:nce,
通过约束输入图像和转换输出图像之间匹配的空间位置(图像块)具有高互信息,对比技术可以用于图像到图像的翻译任务。在这种情况下,查询嵌入 q 是通过编码输出图像的局部区域生成的。正键 k+ 是指输入的相应区域,而负键集 {k−} 是通过编码输入图像的不同区域进行选择的。
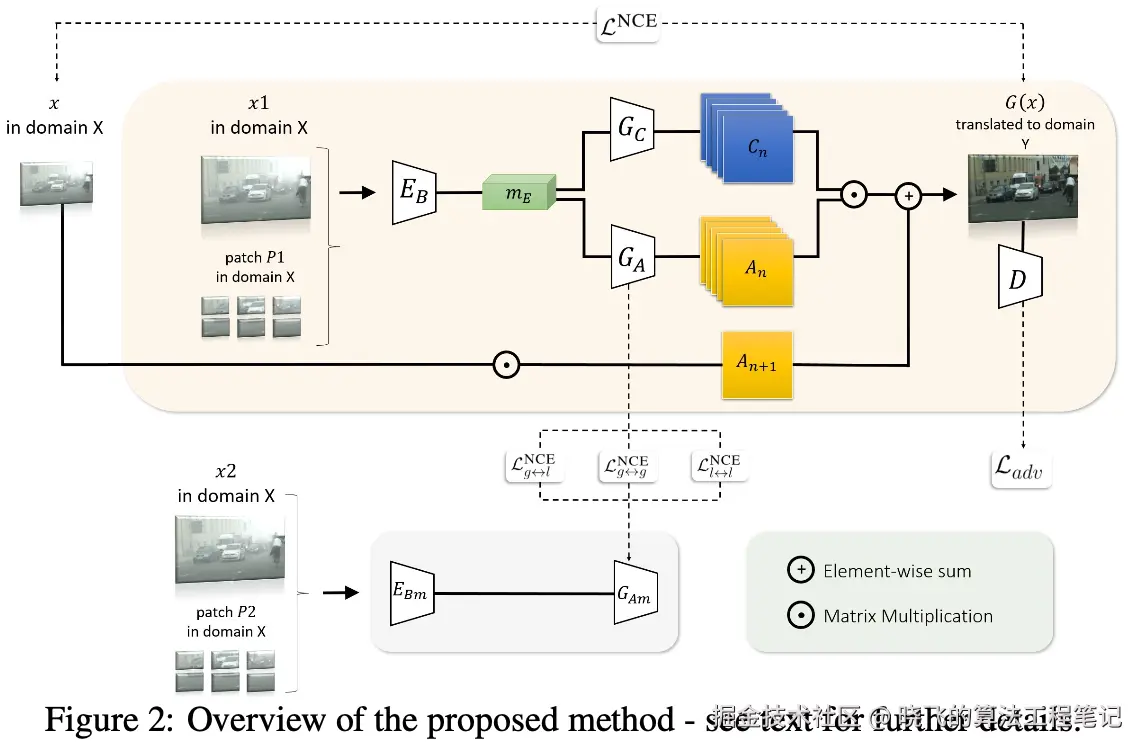
用于I2I转换的空间注意力
论文提出了一种以注意力驱动的方案,学习将输入图像 x 分解为前景和背景区域,并鼓励翻译模型专注于优化前景物体的外观。
方案采用编码器-解码器架构,其中编码器 EB 作为特征提取器,将输入图像 x 编码低维度的图像表示 mE=EB(x) 。解码器将 mE 作为输入,分为两个组件:1)内容生成器 GC 生成一组 n 个内容图 {Ct∣t∈[0,n−1]} 。2)注意力生成器 GA 输出一组 n+1 个注意力掩码 {At∣t∈[0,n]} 。
通过对生成的前景内容图进行加权求和得到转换后的图像 G(x) ,权重由相应的注意力掩码给出,并加上一个额外的表示图像的背景内容:
G(x)=t=1∑nforeground(Ct⊙At)+background(x⊙An+1).\labeleq:fb
使用在公式1中找到的InfoNCE损失来训练生成器,该损失在图像块级别上强制内容和结构的一致性。为了确保转换后的图像与源域 Y 的外观相匹配,进一步加入经过标准对抗损失训练的鉴别模块 D :
Ladv=−Ey∼YlogD(y)−Ex∼Xlog(1−D(G(x)))\labeleq:adv.
鉴别器然后最小化标准二分类任务的负对数似然,这等同于最小化模型输出分布与真实源域分布 Y 之间的Jensen-Shannon(JS) 散度。
局部全局对比学习
为了进一步引导转换任务关注包含具有语义意义的内容的图像区域,在注意力生成器上引入了额外的损失 LGA ,该损失利用了局部和全局图像块之间的关系,完整的优化目标为:
LG=Ladv+LNCE+LGA\labeleq:total1.
对 x 应用两种不同的随机增强,生成变换后的图像 x1 和 x2 ,并相应地得到两组变换后的图像块 P1 和 P2 。为了获得用于对比学习的局部和全局表征,在注意力生成器 GA 上附加了两个投影头以及引入了动量复制的 GAm 和 EBm (权重使用指数移动平均进行更新),生成两组全局和局部特征表征 {fAx1,fAx2,fAx1p,fAx2p} 和 {fAmx1,fAmx2,fAmx1p,fAmx2p} ,计算这些特征集中的所有对之间的 LNCE 以优化模型的区分能力,负对则从内存库中抽取。
最后,定义多尺度监督以提高模型识别显著区域的能力。在 GA 的每一层输出处引入额外的局部和全局MLP层,并计算每新特征集的infoNCE损失。
因此,对 GA 的无监督损失可以表示如下:
LGA=i=1∑LwiLg↔gNCE+i=1∑LwiLg↔lNCE+i=1∑LwiLl↔lNCE,\labeleq:detco
其中 L 是 GA 中的层数, wi 是一个权重参数,用于控制每层贡献的重要性。
通过将上述损失附加到 GA 模块的特征上,能够鼓励注意力生成器提高对语义内容的敏感性,并关注对目标检测任务重要的转换区域。
主要实验


如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】



