中间件学习——消息队列 Kafka | 豆包MarsCode AI刷题
背景介绍
消息队列的发展历程
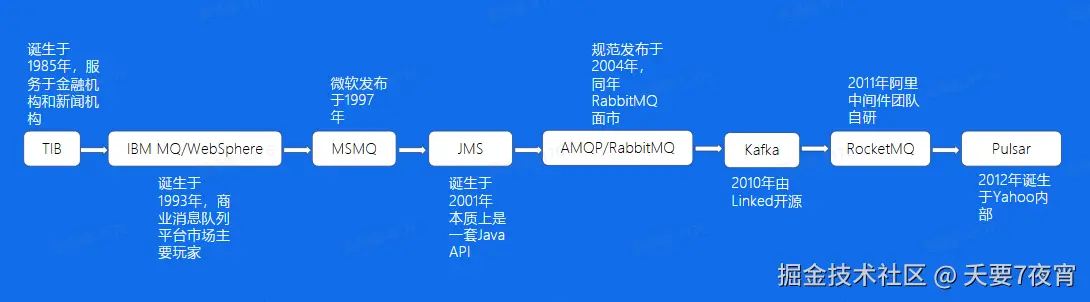
业界消息队列对比
- Kafka:分布式、分区的、多副本的日志提交服务,在高吞吐场景下发挥比较出色
- RocketMQ:低延迟、强一致、高性能、万亿级容量和灵活的可拓展性,在一些实时场景中运用比较广
- Pulsar:是下一代云原生分布式消息流平台,集消息、存储、轻量化函数式计算为一体,采用存算分离的架构设计
- BMQ:与 Pulsar 架构类似,存算分离,一开始的定时是承接高吞吐的离线业务场景,逐步替换掉对应的 Kafka 集群。

消息队列——kafka
使用场景
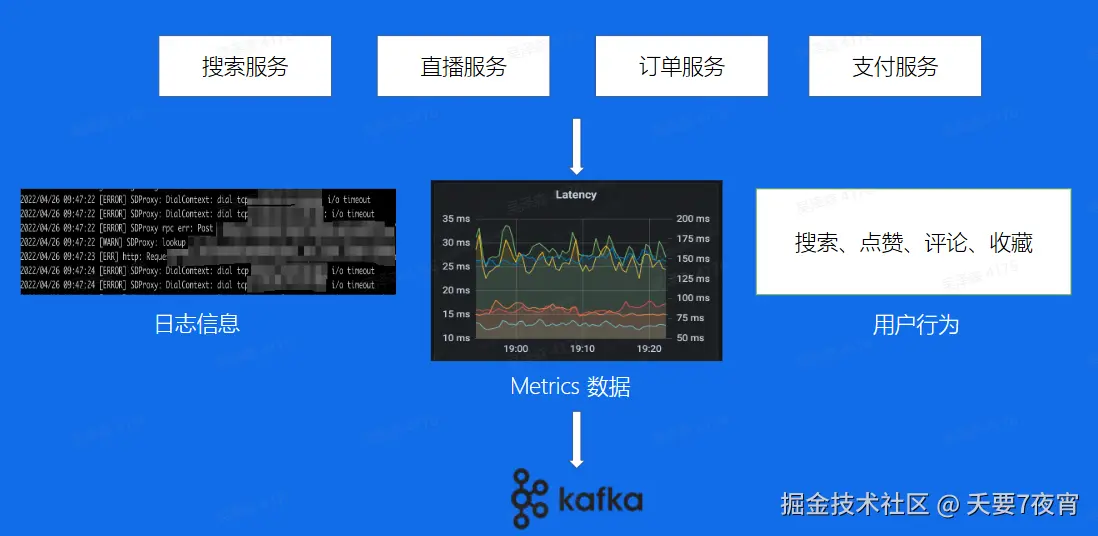
如何使用 Kafka
- 创建集群
- 新增 Topic
- 编写生产者逻辑
- 编写消费者逻辑
基本概念
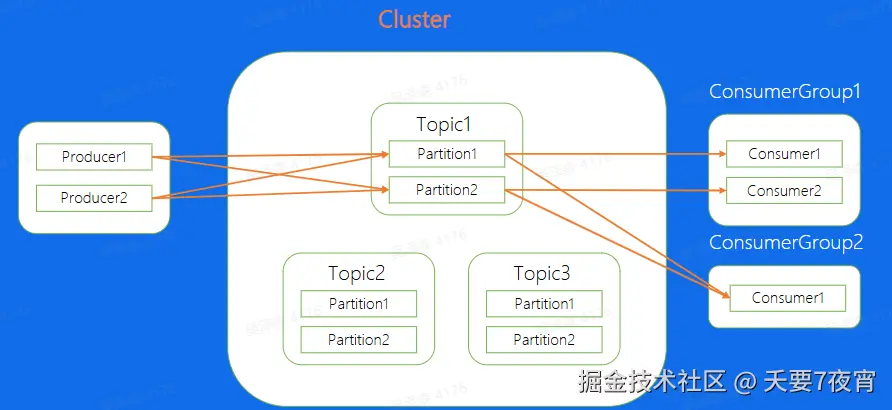
- Topic:逻辑队列,不同 topic 可以建立不同的 Topic
- Cluster:物理集群,每个集群中可以建立多个不同的 Topic
- Producer:生产者,负责将业务消息发送到 Topic 中
- Consumer:消费者,负责消费 Topic 中的消息
- Consumer Group:消费者组,不同组 Consumer 消费进度互不干涉
Offerset
Replica
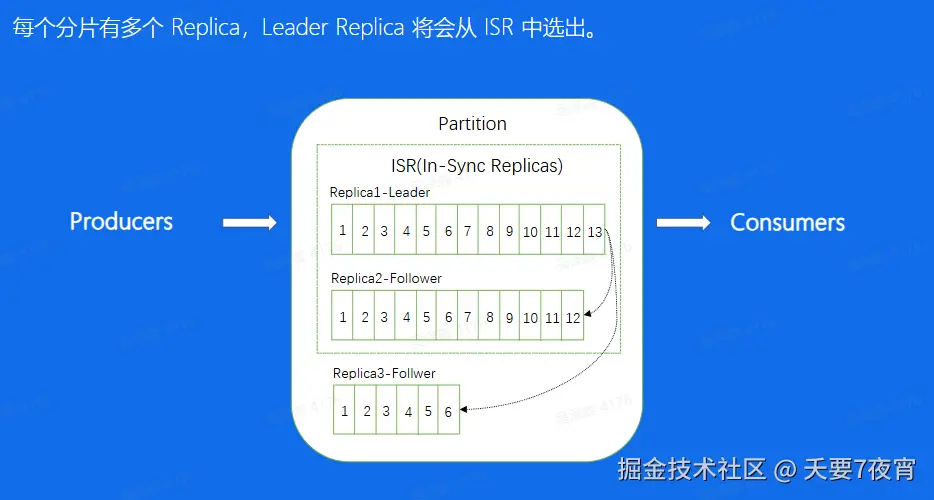
数据复制
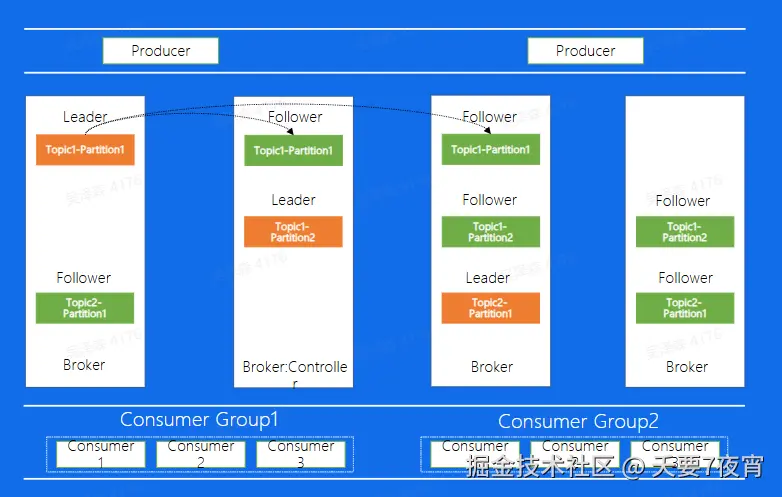
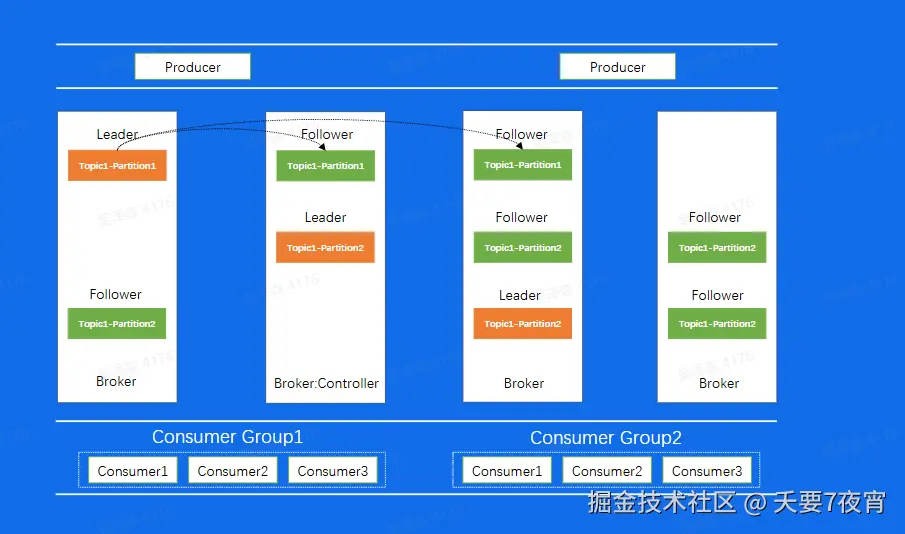
Kafka 架构
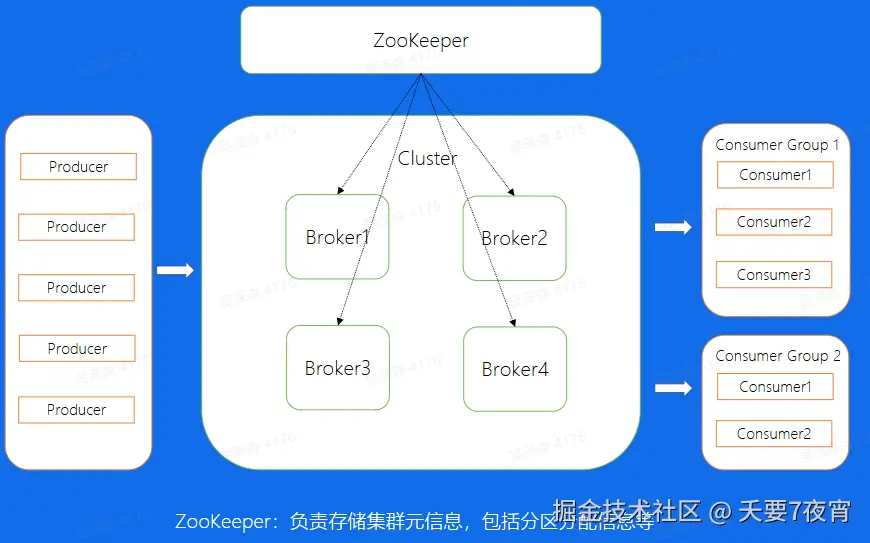
Broker 消息文件结构
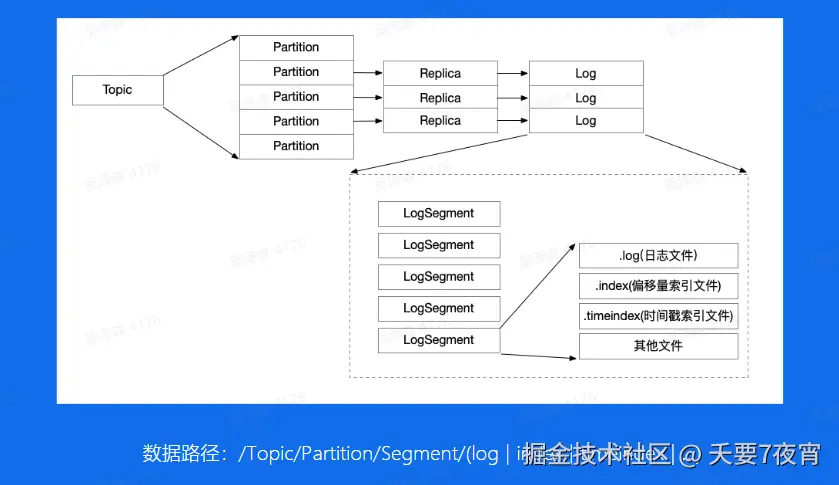
Broker——磁盘结构
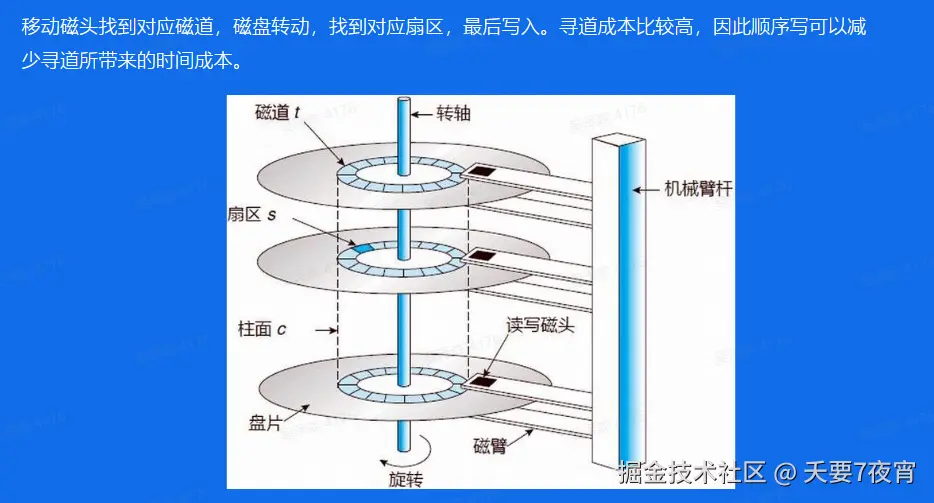
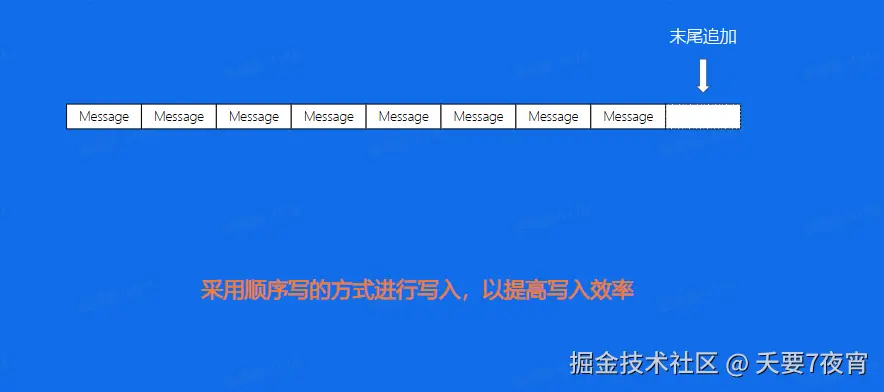
Broker——顺序写
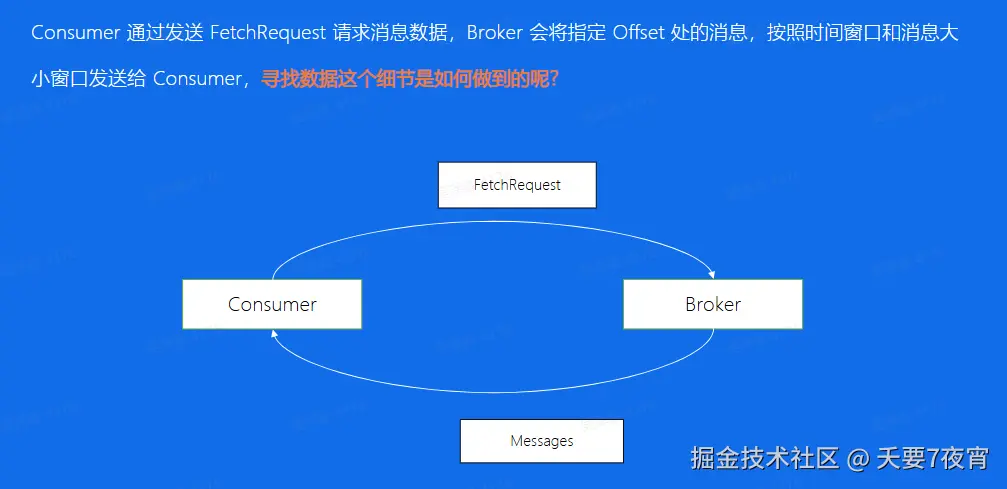
Broker 如何找到消息
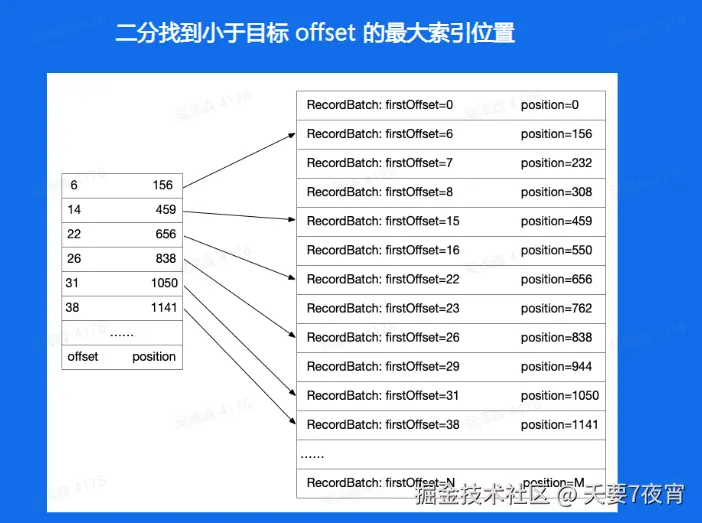
Broker 偏移量索引文件

Broker——传统数据拷贝
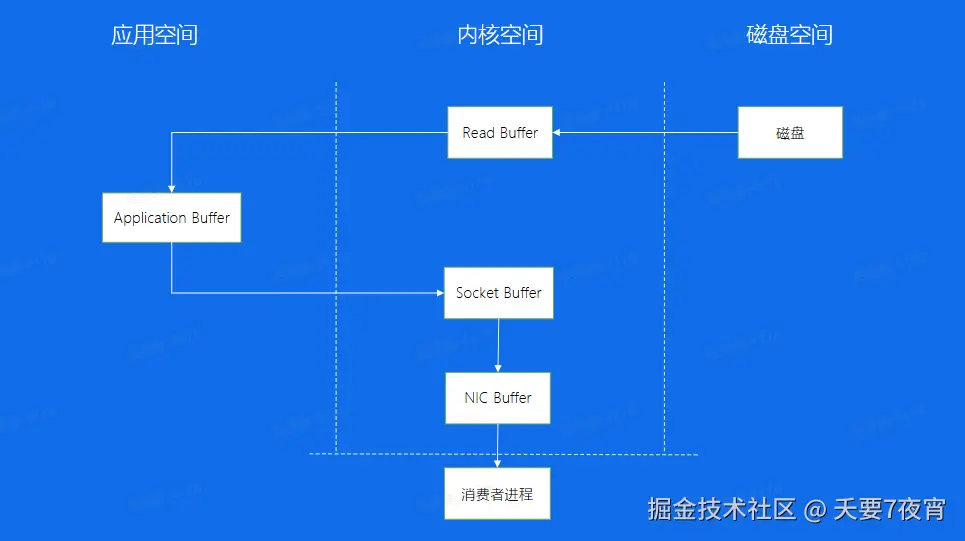
Broker——零拷贝
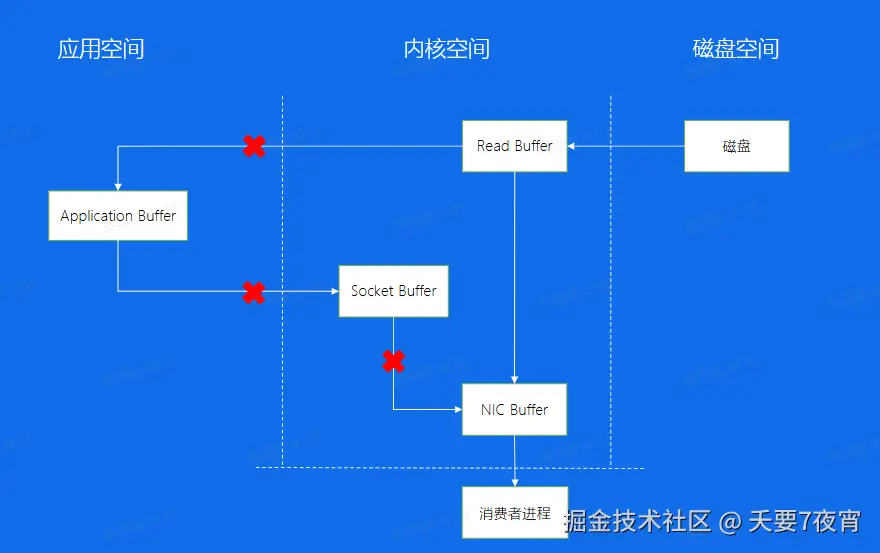
Consumer——消息接收端
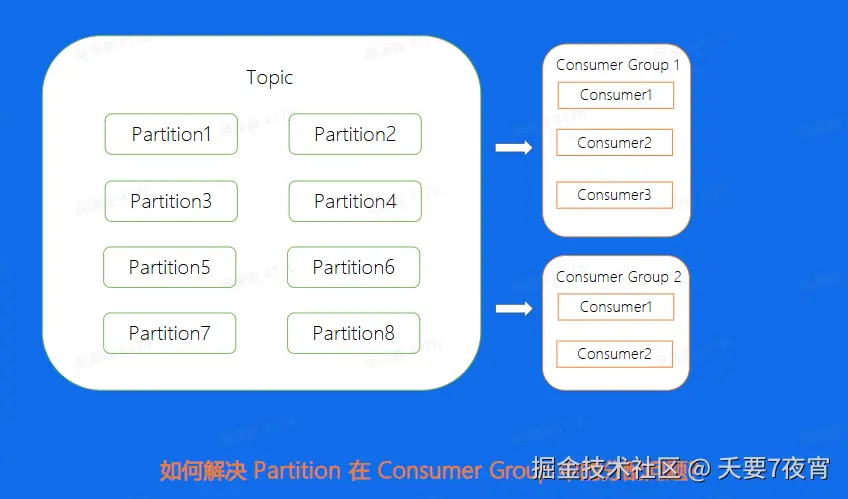
Consumer-Low Level

Consumer——High Level
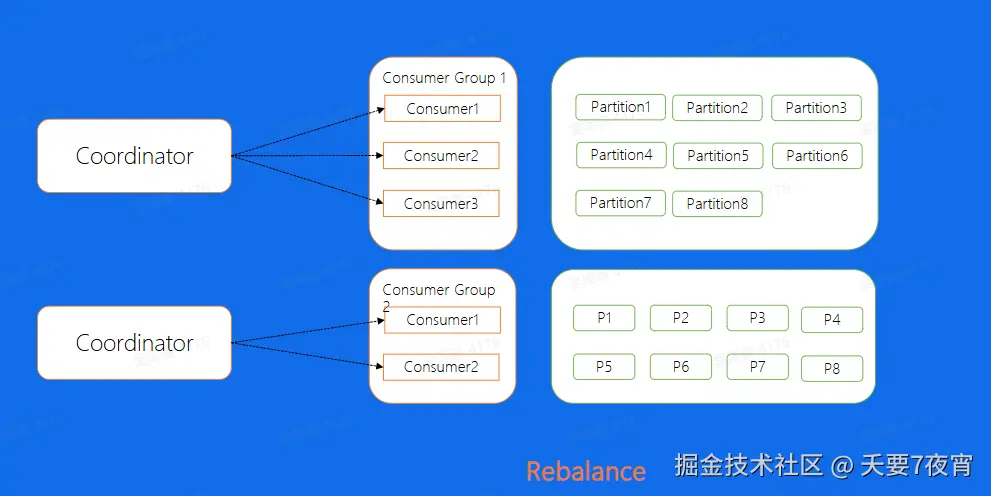
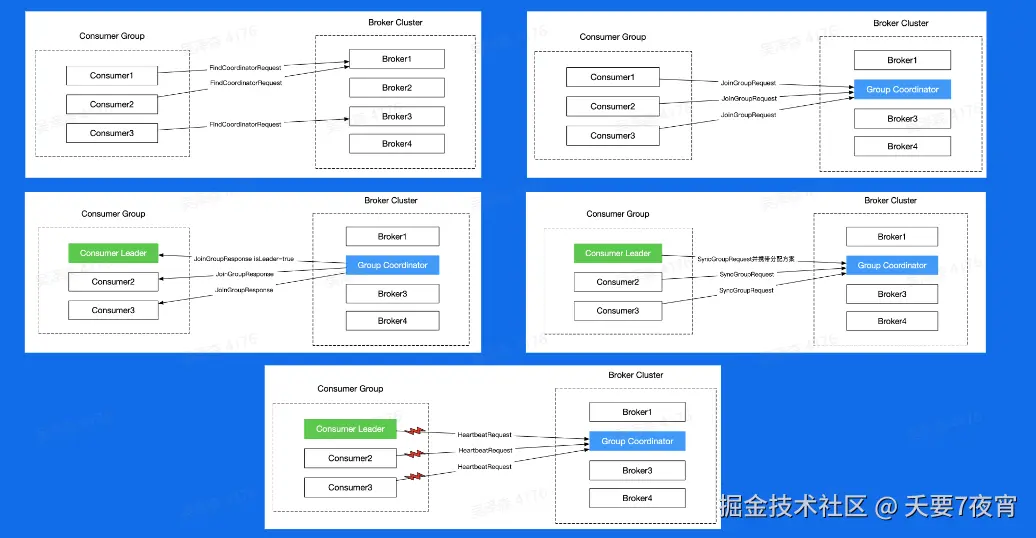
Consumer Rebalance
kafka-数据复制问题
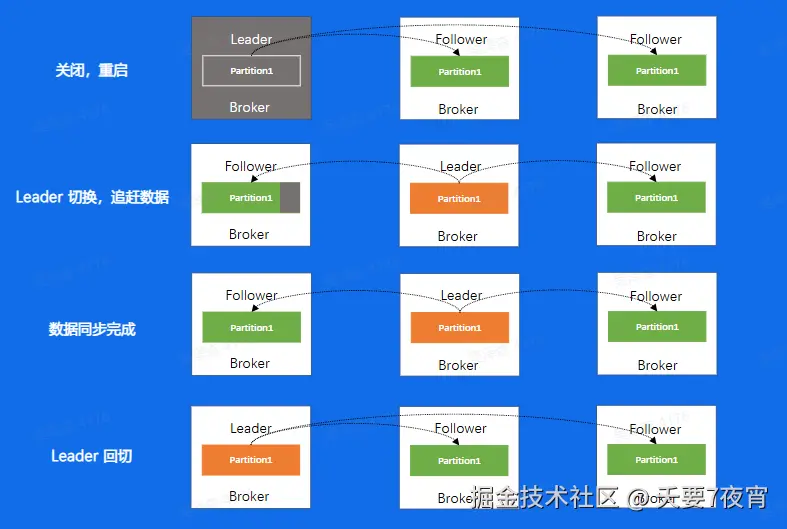
kafka-重启操作
Kafka 替换、扩容、缩容
一、Kafka 替换流程
1. 规划新集群
- 确定新 Kafka 集群的硬件资源,包括服务器数量、CPU、内存、存储等配置,确保新集群能够满足业务需求。
- 配置新集群的网络,保证新集群与旧集群以及生产者和消费者之间能够进行通信。
- 安装和配置新的 Kafka 软件版本,设置好相关参数,如 broker.id(每个 broker 需要有唯一的标识符)、zookeeper.connect(连接 Zookeeper 的地址)等。
2. 数据迁移
- 对于有状态的数据(主题数据、偏移量等),需要进行迁移。如果数据量较小,可以使用 Kafka 自带的工具(如 kafka - console - consumer 和 kafka - console - producer)将旧集群主题中的数据导出并导入到新集群相应的主题中。
- 如果数据量较大,可以考虑使用更高效的数据迁移工具,或者编写自定义脚本。例如,使用 MirrorMaker 工具,它可以在不同的 Kafka 集群之间进行数据复制。在迁移过程中,需要注意数据的一致性和完整性,确保没有数据丢失或损坏。
3. 切换生产者和消费者
- 逐步将生产者的消息发送目标从旧集群切换到新集群。这可能需要修改生产者的配置文件,将 bootstrap.servers 属性指向新集群的 broker 地址。
- 对于消费者,同样修改配置文件,将其指向新集群,并且根据迁移情况,正确设置消费者组的偏移量,以确保消费者能够从正确的位置开始消费消息。在切换过程中,需要密切监控生产者和消费者的状态,确保消息的正常发送和接收。
4. 验证和清理
- 在切换完成后,对新集群进行全面验证,包括检查消息的发送和接收是否正常、消息的顺序是否正确、数据的完整性等。
- 确认新集群稳定运行后,可以选择关闭旧集群,清理旧集群的数据和相关配置,释放资源。
二、Kafka 扩容流程
1. 硬件资源准备
- 根据扩容需求,准备新增的服务器或虚拟机,确保其硬件配置(如 CPU、内存、磁盘空间等)符合 Kafka 集群的要求。
- 将新节点加入到集群所在的网络环境中,确保新节点与现有节点之间能够相互通信。
2. 安装和配置 Kafka 软件
- 在新节点上安装 Kafka 软件,安装步骤与现有节点相同。
- 配置新节点的 broker.id,确保每个 broker 在集群中有唯一的标识符。同时,配置 zookeeper.connect 参数,使其能够连接到集群使用的 Zookeeper 服务器。
3. 集群配置更新
- 对 Kafka 集群的配置文件进行更新,将新节点的信息添加到 broker 列表中。例如,在 server.properties 文件中的 broker.list 属性或者类似的配置项中添加新节点的地址和端口。
- 根据需要,调整其他集群级别的参数,如副本分配策略(如果要重新平衡副本分布)等。
4. 数据同步和重新平衡
- 新节点加入后,Kafka 会自动进行数据同步,将部分主题分区的副本分配到新节点上,以实现负载均衡。这个过程是由 Kafka 的控制器(Controller)自动管理的。
- 可以通过 Kafka 提供的工具(如 kafka - reassign - partitions.sh)来手动触发分区重新分配,确保数据在集群中的合理分布。在重新分配过程中,需要注意监控集群的性能和数据一致性。
5. 性能测试和监控
- 完成扩容后,对集群进行性能测试,检查消息的吞吐量、延迟等指标是否满足预期。
- 持续监控集群的状态,包括各个节点的资源使用情况(CPU、内存、磁盘 I/O、网络 I/O)、主题分区的分布情况等,确保集群稳定运行。
三、Kafka 缩容流程
1. 数据迁移(可选)
- 如果要删除的节点上存储有重要数据,并且希望将这些数据迁移到其他节点上,可以使用 Kafka 的分区重新分配工具(如 kafka - reassign - partitions.sh)将该节点上的分区副本迁移到其他节点。
- 在迁移过程中,需要注意确保数据的完整性和一致性,并且监控迁移进度和集群状态。
2. 集群配置更新
- 在缩容之前,修改 Kafka 集群的配置文件,将需要删除的节点从 broker 列表中移除。例如,从 server.properties 文件中的 broker.list 属性或者类似的配置项中删除要删除节点的地址和端口。
- 根据需要,调整其他与集群拓扑相关的参数,如副本分配策略等。
3. 关闭节点
- 停止要删除的 Kafka 节点上的 Kafka 服务。可以通过操作系统的服务管理工具或者直接执行 Kafka 的停止脚本(如 bin/kafka - server - stop.sh)来关闭服务。
- 确认节点上的 Kafka 服务已完全停止后,可以选择将该节点从集群的网络环境中移除,释放硬件资源。
4. 重新平衡和监控
- 在节点删除后,Kafka 集群会自动进行重新平衡,调整剩余节点上的分区副本分布。可以通过监控工具观察重新平衡的过程和集群的状态。
- 持续监控集群的性能指标,如消息吞吐量、延迟等,确保缩容后集群能够稳定高效地运行。


