

在过去的六个月里,我一直在 A 轮创业公司 Voxel51 工作,该公司是开源计算机视觉工具包 FiftyOne的创建者。作为一名机器学习工程师和开发人员布道者,我的工作是倾听我们的开源社区并为他们提供他们所需要的东西 — 新功能、集成、教程、研讨会等等。
几周前,我们为 FiftyOne 添加了对矢量搜索引擎和文本相似性查询的原生支持,以便用户可以通过简单的自然语言查询在其(通常是海量的——包含数百万或数千万个样本的)数据集中找到最相关的图像。
这让我们陷入了一个奇怪的境地:现在人们可以使用开源 FiftyOne 轻松地用自然语言查询搜索数据集,但使用我们的文档仍然需要传统的关键字搜索。
我们有大量文档,这有其优点和缺点。作为一名用户,我有时会发现,鉴于文档数量之多,要找到我想要的确切内容需要比我想象的更多的时间。
我不想让它飞走……所以我利用业余时间建造了这个:
从命令行语义搜索贵公司的文档。图片由作者提供。
因此,下面是我把我们的文档转换成语义可搜索的矢量数据库的方法:
您可以在voxel51/fiftyone-docs-search repo中找到此帖子的所有代码,并且可以使用 轻松地在编辑模式下在本地安装该包pip install -e .。
更好的是,如果您想使用此方法为自己的网站实现语义搜索,您可以继续!以下是您需要的成分:
- 安装openai _Python 包并创建一个帐户:_您将使用此帐户将您的文档和查询发送到推理端点,该端点将为每段文本返回一个嵌入向量。
- 安装qdrant-client Python 包并通过 Docker_启动_Qdrant 服务器:您将使用Qdrant为文档创建本地托管的向量索引,并针对该索引运行查询。Qdrant 服务将在 Docker 容器内运行。
将文档转换为统一格式
我公司的文档全部以 HTML 文档形式托管在docs.voxel51.com上。一个自然的起点是使用 Python 的请求库下载这些文档,然后使用Beautiful Soup解析文档。
然而,作为一名开发人员(也是我们许多文档的作者),我认为我可以做得更好。我已经在本地计算机上有一个 GitHub 存储库的工作克隆,其中包含用于生成 HTML 文档的所有原始文件。我们的一些文档是用Sphinx ReStructured Text (RST)编写的,而其他文档(如教程)则是从 Jupyter 笔记本转换为 HTML。
我(错误地)认为我越接近 RST 和 Jupyter 文件的原始文本,事情就会越简单。
RST
在 RST 文档中,各部分由仅包含=、-或字符串的行来划分_。例如,以下是来自 FiftyOne 用户指南的文档,其中包含所有三个划分符:
然后,我可以删除所有 RST 关键字,例如toctree、、code-block和button_link(还有更多),以及伴随:关键字、新块的开始或块描述符的、、和。::``..
链接也很容易维护:
no_links_section = re.sub(r"<[^>]+>_?","", section)
当我想从 RST 文件中提取节锚点时,事情开始变得棘手。我们的许多节都有明确指定的锚点,而其他节则留待转换为 HTML 时推断。
以下是一个例子:
.. _brain-embeddings-visualization:
Visualizing embeddings
______________________
The FiftyOne Brain provides a powerful
:meth:`compute_visualization() <fiftyone.brain.compute_visualization>` method
that you can use to generate low-dimensional representations of the samples
and/or individual objects in your datasets.
These representations can be visualized natively in the App's
:ref:`Embeddings panel <app-embeddings-panel>`, where you can interactively
select points of interest and view the corresponding samples/labels of interest
in the :ref:`Samples panel <app-samples-panel>`, and vice versa.
.. image:: /images/brain/brain-mnist.png
:alt: mnist
:align: center
There are two primary components to an embedding visualization: the method used
to generate the embeddings, and the dimensionality reduction method used to
compute a low-dimensional representation of the embeddings.
Embedding methods
-----------------
The `embeddings` and `model` parameters of
:meth:`compute_visualization() <fiftyone.brain.compute_visualization>`
support a variety of ways to generate embeddings for your data:
在我们的用户指南文档中的 brain.rst 文件中(其中一部分已在上面重现),_可视化嵌入_部分有一个#brain-embeddings-visualization由 指定的锚点.. _brain-embeddings-visualization:。但是,紧随其后的_嵌入方法_子部分被赋予了一个自动生成的锚点。
另一个很快浮现出来的困难是如何处理 RST 中的表格。列表表相当简单。例如,这是我们的 View Stages 备忘单中的一个列表表:
.. list-table::
* - :meth:`match() <fiftyone.core.collections.SampleCollection.match>`
* - :meth:`match_frames() <fiftyone.core.collections.SampleCollection.match_frames>`
* - :meth:`match_labels() <fiftyone.core.collections.SampleCollection.match_labels>`
* - :meth:`match_tags() <fiftyone.core.collections.SampleCollection.match_tags>`
另一方面,网格表很快就会变得混乱。它们为文档编写者提供了极大的灵活性,但这种灵活性也使解析它们变得很麻烦。从我们的过滤备忘单中获取此表:
+-----------------------------------------+-----------------------------------------------------------------------+
| Operation | Command |
+=========================================+=======================================================================+
| Filepath starts with "/Users" | .. code-block:: |
| | |
| | ds.match(F("filepath").starts_with("/Users")) |
+-----------------------------------------+-----------------------------------------------------------------------+
| Filepath ends with "10.jpg" or "10.png" | .. code-block:: |
| | |
| | ds.match(F("filepath").ends_with(("10.jpg", "10.png")) |
+-----------------------------------------+-----------------------------------------------------------------------+
| Label contains string "be" | .. code-block:: |
| | |
| | ds.filter_labels( |
| | "predictions", |
| | F("label").contains_str("be"), |
| | ) |
+-----------------------------------------+-----------------------------------------------------------------------+
| Filepath contains "088" and is JPEG | .. code-block:: |
| | |
| | ds.match(F("filepath").re_match("088*.jpg")) |
+-----------------------------------------+-----------------------------------------------------------------------+
在表格中,行可以占用任意数量的行,列的宽度可以变化。网格表单元格内的代码块也很难解析,因为它们占用多行空间,因此其内容与其他列的内容交错。这意味着这些表格中的代码块需要在解析过程中有效地重建。
这并非世界末日,但也不理想。
Jupyter
Jupyter 笔记本解析起来相对简单。我能够将 Jupyter 笔记本的内容读入字符串列表,每个单元格一个字符串:
import json
ifile = "my_notebook.ipynb"
with open(ifile, "r") as f:
contents = f.read()
contents = json.loads(contents)["cells"]
contents = [(" ".join(c["source"]), c['cell_type'] for c in contents]
此外,各个部分都由以 开头的 Markdown 单元格划分#。
然而,考虑到 RST 带来的挑战,我决定转向 HTML 并平等对待我们所有的文档。
HTML
我使用 构建了本地安装的 HTML 文档bash generate_docs.bash,并开始使用 Beautiful Soup 解析它们。然而,我很快意识到,当 RST 代码块和带有内联代码的表格被转换为 HTML 时,虽然它们可以正确呈现,但 HTML 本身却非常笨重。以我们的过滤备忘单为例。
_在浏览器中呈现时,我们的过滤备忘单的日期和时间_部分前面的代码块如下所示:
开源 FiftyOne Docs 中的备忘单截图。图片由作者提供。
然而,原始 HTML 如下所示:
RST 备忘单已转换为 HTML。图片由作者提供。
这并非无法解析,但也远非理想。
Markdown
幸运的是,我能够通过使用markdownify将所有 HTML 文件转换为 Markdown 来克服这些问题。Markdown 具有一些关键优势,使其最适合这项工作。
- 比 HTML 更简洁:代码格式从繁琐的元素字符串简化
span为以单引号标记的内联代码片段`,以三引号标记的代码块```。这也使其易于拆分为文本和代码。 - **仍包含锚点:**与原始 RST 不同,此 Markdown 包含节标题锚点,因为隐式锚点已生成。这样,我不仅可以链接到包含结果的页面,还可以链接到该页面的特定节或子节。
- 标准化:Markdown 为初始的 RST 和 Jupyter 文档提供了几乎统一的格式,使我们能够在向量搜索应用程序中对其内容进行一致的处理。
关于 LangChain 的说明
你们中的一些人可能知道用于使用 LLM 构建应用程序的开源库LangChain,并且可能想知道为什么我不直接使用 LangChain 的文档加载器和文本分割器。答案是:我需要更多的控制权!
处理文件
将文档转换为 Markdown 后,我开始清理内容并将其分成更小的部分。
打扫
清洁主要包括去除不必要的元素,包括:
- 页眉和页脚
- 表格行和列的支架 —
|例如|select()| select_by()| - 额外的换行符
- 链接
- 图片
- Unicode 字符
- 加粗 — 即
**text**→text
我还删除了从文档中具有特殊含义的字符中转义的转义符:_和*。前者用于许多方法名称,而后者通常用于乘法、正则表达式模式和许多其他地方:
document = document.replace("_", "_").replace("*", "*")
将文档拆分为语义块
清理完文档内容后,我开始将文档分成小块。
首先,我将每个文档分成几部分。乍一看,似乎可以通过查找以#字符开头的任何行来完成此操作。在我的应用程序中,我没有区分 h1、h2、h3 等(#、##、 ),因此检查第一个字符就足够了。但是,当我们意识到这也用于允许在 Python 代码中注释###时,这种逻辑会给我们带来麻烦。#
为了绕过这个问题,我将文档分成文本块和代码块:
text_and_code = page_md.split('```')
text = text_and_code[::2]
code = text_and_code[1::2]
然后,我用 来标识新节的开始,以#在文本块中开始一行。我从此行中提取了节标题和锚点:
def extract_title_and_anchor(header):
header = " ".join(header.split(" ")[1:])
title = header.split("[")[0]
anchor = header.split("(")[1].split(" ")[0]
return title, anchor
并将每个文本块或代码分配到适当的部分。
最初,我还尝试将文本块拆分为段落,假设由于一个部分可能包含有关许多不同主题的信息,因此整个部分的嵌入可能与仅涉及其中一个主题的文本提示的嵌入不同。然而,这种方法导致大多数搜索查询的顶级匹配不成比例地成为单行段落,结果作为搜索结果并没有太多信息。
查看随附的GitHub repo了解这些方法的实现,您可以在自己的文档上尝试它们!
使用 OpenAI 嵌入文本和代码块
在将文档转换、处理并拆分为字符串后,我为每个块生成了一个嵌入向量。由于大型语言模型本质上灵活且功能强大,因此我决定将文本块和代码块视为文本片段,并使用同一模型对其进行嵌入。
我使用了 OpenAI 的text-embedding-ada-002 模型,因为它易于使用,在 OpenAI 的所有嵌入模型中性能最高(在BEIR 基准上),而且价格最便宜。事实上,它非常便宜(0.0004 美元/1K 代币),以至于生成 FiftyOne 文档的所有嵌入仅需花费几美分!正如 OpenAI 自己所说,“我们建议在几乎所有用例中都使用 text-embedding-ada-002。它更好、更便宜、更易于使用。”
利用这个嵌入模型,您可以生成一个 1536 维的向量来表示任何输入提示,最多 8,191 个标记(约 30,000 个字符)。
首先,您需要创建一个 OpenAI 帐户,在platform.openai.com/account/api…生成一个 API 密钥,然后使用以下命令将此 API 密钥导出为环境变量:
export OPENAI_API_KEY="<MY_API_KEY>"
您还需要安装openai Python 库:
pip install openai
我围绕 OpenAI 的 API 编写了一个包装器,它接受文本提示并返回嵌入向量:
MODEL = "text-embedding-ada-002"
def embed_text(text):
response = openai.Embedding.create(
input=text,
model=MODEL
)
embeddings = response['data'][0]['embedding']
return embeddings
为了为我们所有的文档生成嵌入,我们只需将此函数应用于所有文档的每个子部分(文本和代码块)。
创建 Qdrant 向量索引
有了嵌入后,我创建了一个用于搜索的向量索引。我选择使用 Qdrant 的原因与我们选择为 FiftyOne 添加原生 Qdrant 支持的原因相同:它是开源的、免费的,而且易于使用。
要开始使用 Qdrant,您可以拉取预先构建的 Docker 映像并运行容器:
docker pull qdrant/qdrant
docker run -d -p 6333:6333 qdrant/qdrant
此外,您还需要安装 Qdrant Python 客户端:
pip install qdrant-client
我创建了 Qdrant 系列:
import qdrant_client as qc
import qdrant_client.http.models as qmodels
client = qc.QdrantClient(url="localhost")
METRIC = qmodels.Distance.DOT
DIMENSION = 1536
COLLECTION_NAME = "fiftyone_docs"
def create_index():
client.recreate_collection(
collection_name=COLLECTION_NAME,
vectors_config = qmodels.VectorParams(
size=DIMENSION,
distance=METRIC,
)
)
然后我为每个小节(文本或代码块)创建了一个向量:
import uuid
def create_subsection_vector(
subsection_content,
section_anchor,
page_url,
doc_type
):
vector = embed_text(subsection_content)
id = str(uuid.uuid1().int)[:32]
payload = {
"text": subsection_content,
"url": page_url,
"section_anchor": section_anchor,
"doc_type": doc_type,
"block_type": block_type
}
return id, vector, payload
对于每个向量,您都可以提供额外的上下文作为有效载荷的一部分。在本例中,我包含了可以找到结果的 URL(和锚点)、文档_类型_,以便用户可以指定他们是否要搜索所有文档,还是只搜索某些类型的文档,以及生成嵌入向量的字符串的内容。我还添加了块类型(文本或代码),因此如果用户正在寻找代码片段,他们可以根据该目的定制搜索。
然后我将这些向量添加到索引中,一次一页:
def add_doc_to_index(subsections, page_url, doc_type, block_type):
ids = []
vectors = []
payloads = []
for section_anchor, section_content in subsections.items():
for subsection in section_content:
id, vector, payload = create_subsection_vector(
subsection,
section_anchor,
page_url,
doc_type,
block_type
)
ids.append(id)
vectors.append(vector)
payloads.append(payload)
## Add vectors to collection
client.upsert(
collection_name=COLLECTION_NAME,
points=qmodels.Batch(
ids = ids,
vectors=vectors,
payloads=payloads
),
)
查询索引
创建索引后,可以通过使用相同的嵌入模型嵌入查询文本,然后在索引中搜索类似的嵌入向量来完成对索引文档的搜索。使用 Qdrant 向量索引,可以使用 Qdrant 客户端的命令执行基本查询search()。
为了使我公司的文档可搜索,我希望允许用户按文档部分以及编码块的类型进行筛选。在向量搜索中,筛选结果同时仍确保top_k返回预定数量的结果(由参数指定)称为_预筛选_。
为了实现这一点,我编写了一个程序过滤器:
def _generate_query_filter(query, doc_types, block_types):
"""Generates a filter for the query.
Args:
query: A string containing the query.
doc_types: A list of document types to search.
block_types: A list of block types to search.
Returns:
A filter for the query.
"""
doc_types = _parse_doc_types(doc_types)
block_types = _parse_block_types(block_types)
_filter = models.Filter(
must=[
models.Filter(
should= [
models.FieldCondition(
key="doc_type",
match=models.MatchValue(value=dt),
)
for dt in doc_types
],
),
models.Filter(
should= [
models.FieldCondition(
key="block_type",
match=models.MatchValue(value=bt),
)
for bt in block_types
]
)
]
)
return _filter
内部_parse_doc_types()和_parse_block_types()函数处理参数为字符串或列表值或为 None 的情况。
然后我编写了一个函数query_index(),它接受用户的文本查询,进行预过滤,搜索索引,并从有效负载中提取相关信息。该函数返回一个形式为 的元组列表(url, contents, score),其中分数表示结果与查询文本的匹配程度。
def query_index(query, top_k=10, doc_types=None, block_types=None): vector = embed_text(query) _filter = _generate_query_filter(query, doc_types, block_types)
results = CLIENT.search(
collection_name=COLLECTION_NAME,
query_vector=vector,
query_filter=_filter,
limit=top_k,
with_payload=True,
search_params=_search_params,
)
results = [
(
f"{res.payload['url']}#{res.payload['section_anchor']}",
res.payload["text"],
res.score,
)
for res in results
]
return results
编写搜索包装器
最后一步是提供一个干净的界面供用户根据这些“矢量化”文档进行语义搜索。
我编写了一个函数print_results(),它接受查询、来自的结果query_index()和一个score参数(是否打印相似度分数),并以易于解释的方式打印结果。我使用丰富的Python 包来格式化终端中的超链接,以便在支持超链接的终端中工作时,单击超链接将在默认浏览器中打开页面。如果需要,我还使用webbrowser自动打开顶部结果的链接。
以丰富的超链接显示搜索结果。图片由作者提供。
对于基于 Python 的搜索,我创建了一个类FiftyOneDocsSearch来封装文档搜索行为,以便一旦对象FiftyOneDocsSearch被实例化(可能使用搜索参数的默认设置):
from fiftyone.docs_search import FiftyOneDocsSearch
fosearch = FiftyOneDocsSearch(open_url=False, top_k=3, score=True)
您可以通过调用此对象在 Python 中进行搜索。例如,要查询“如何加载数据集”的文档,您只需运行:
fosearch(“How to load a dataset”)
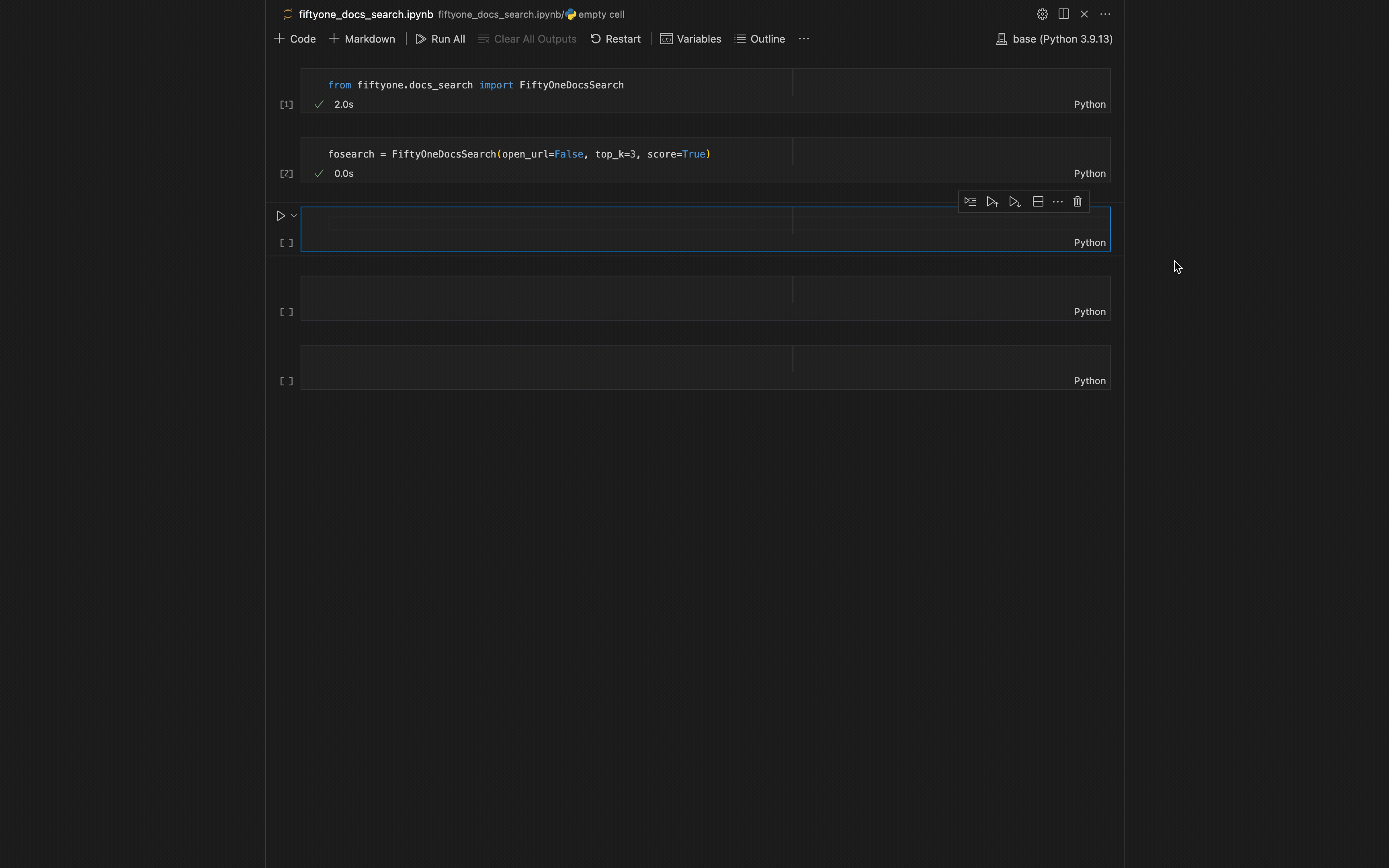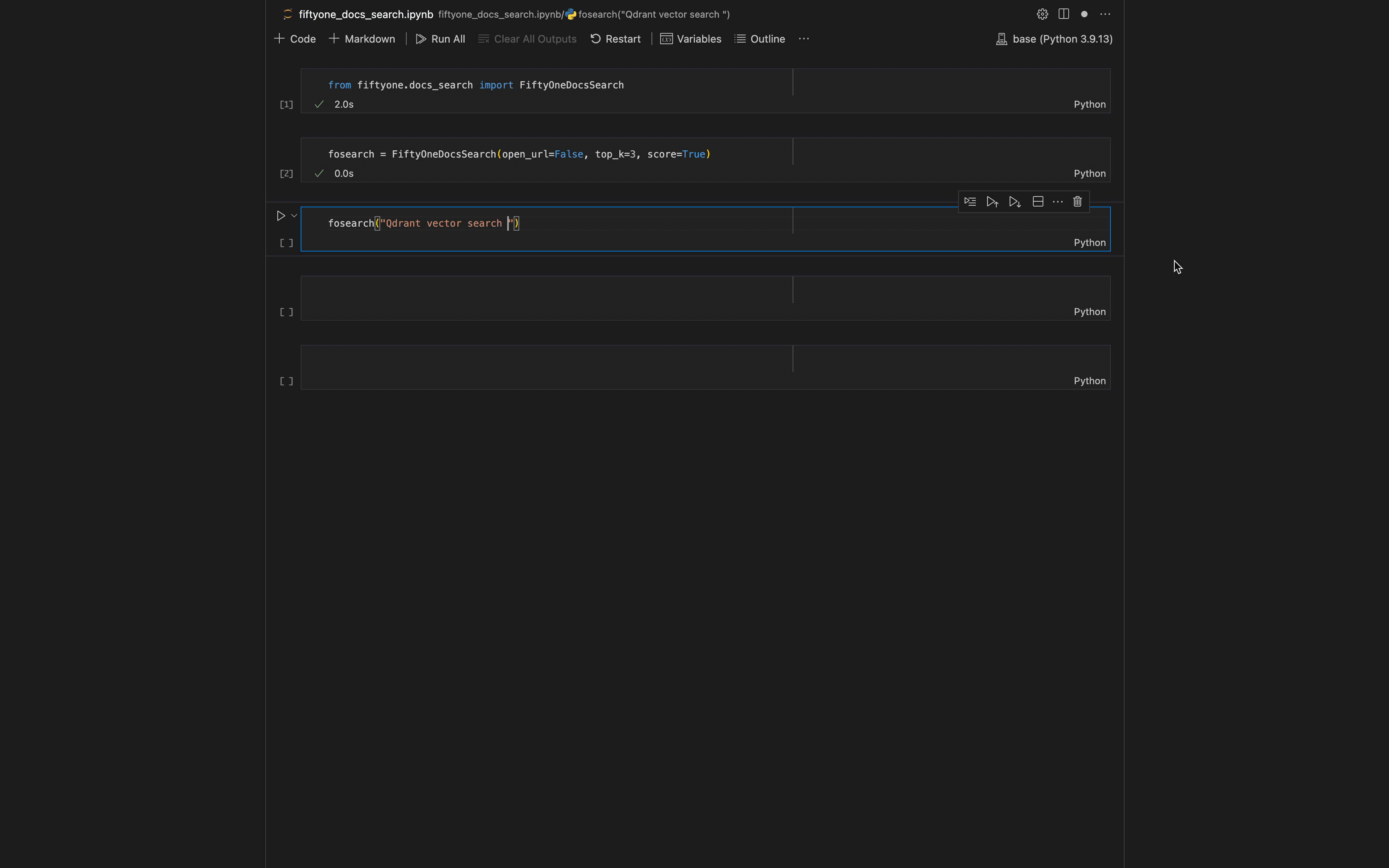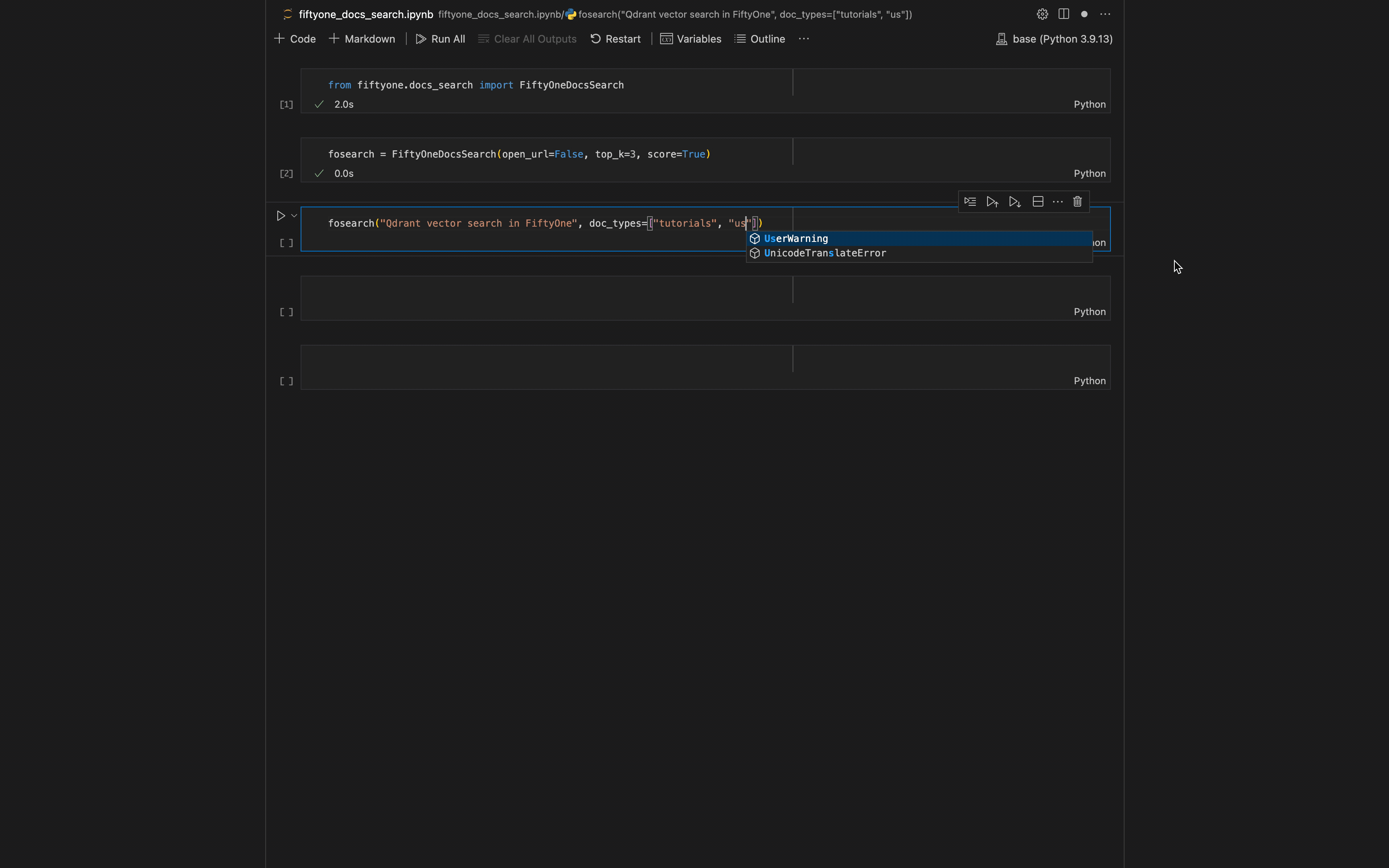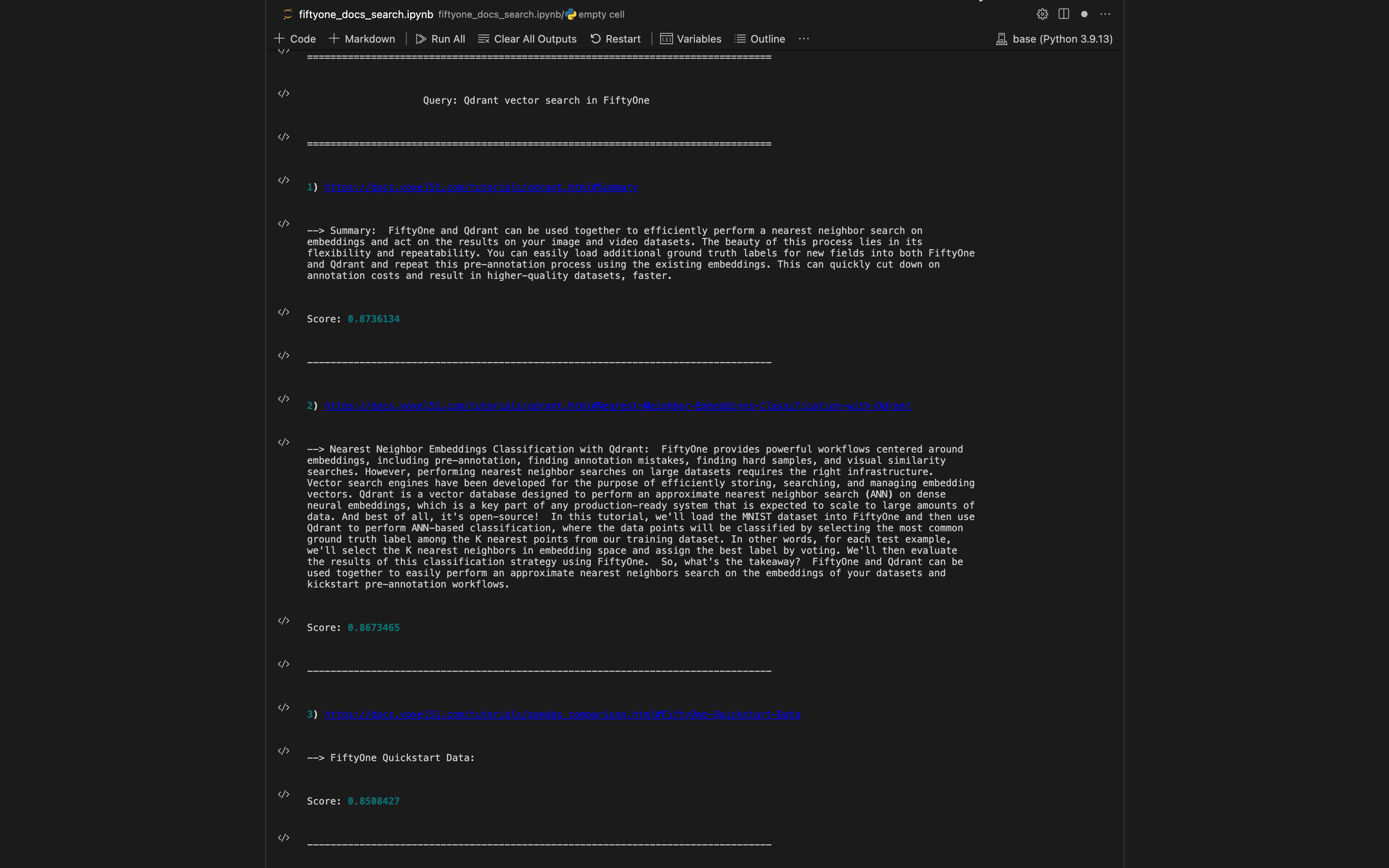
使用 Python 流程对贵公司的文档进行语义搜索。图片由作者提供。
我还使用了argparse来通过命令行提供此文档搜索功能。安装软件包后,可以使用以下 CLI 搜索文档:
fiftyone-docs-search query "<my-query>" <args
只是为了好玩,因为fiftyone-docs-search query有点麻烦,我给我的.zsrch文件添加了一个别名:
alias fosearch='fiftyone-docs-search query'
使用此别名,可以从命令行搜索文档:
fosearch "<my-query>" args
结论
在此之前,我已经把自己塑造成了我公司开源 Python 库 FiftyOne 的重度用户。我编写了许多文档,并且每天都在使用(并将继续使用)该库。但是将我们的文档转变为可搜索数据库的过程迫使我更深入地了解我们的文档。当你为他人构建某些东西时,这总是一件很棒的事情,而且它最终也会帮助你!
以下是我了解到的情况:
- Sphinx RST 很麻烦:虽然可以生成漂亮的文档,但解析起来有点麻烦
- 不要对预处理太过痴迷: OpenAI 的 text-embeddings-ada-002 模型非常擅长理解文本字符串背后的含义,即使它的格式略有不同。提取词干并费力地删除停用词和杂项字符的日子已经一去不复返了。
- 最好使用语义上有意义的小片段:将文档拆分成尽可能小的有意义的片段,并保留上下文。对于较长的文本,搜索查询与索引中部分文本之间的重叠部分很可能会因片段中相关性较低的文本而变得模糊。如果将文档拆分得太小,则存在索引中的许多条目包含很少语义信息的风险。
- 向量搜索功能强大:只需进行少量提升,无需任何微调,我就能显著提高我们文档的可搜索性。从初步估计来看,这种改进的文档搜索返回相关结果的可能性比旧的关键字搜索方法高出两倍多。此外,这种向量搜索方法的语义性质意味着用户现在可以使用任意措辞、任意复杂的查询进行搜索,并保证获得指定数量的结果。
如果您发现自己(或他人)不断挖掘或筛选大量文档以寻找特定信息,我鼓励您根据自己的使用情况调整此流程。您可以修改此流程以适用于您的个人文档或公司档案。如果您这样做,我保证您将从这次体验中以全新的眼光看待您的文档!
您可以使用以下几种方法将其扩展为您自己的文档!
- 混合搜索:将矢量搜索与传统关键字搜索相结合
- 走向全球:使用Qdrant Cloud在云端存储和查询集合
- 整合网络数据:使用请求直接从网络下载 HTML
- 自动更新:每当底层文档发生变化时,使用Github Actions触发嵌入的重新计算
- 嵌入:将其包装在 Javascript 元素中,并将其作为传统搜索栏的替代品
用于构建包的所有代码都是开源的,可以在voxel51/fiftyone-docs-search repo 中找到。
