- 3D建模和动画
建模软件:例如Blender、Maya或3ds Max,用于创建虚拟人的3D模型。
面部动画:使用Blend Shapes(混合变形)或骨骼动画技术实现面部的动态变化。表情和口型可以通过控制点来操控。
UV映射和纹理:处理虚拟人的皮肤、表情纹理,让角色看起来更真实。
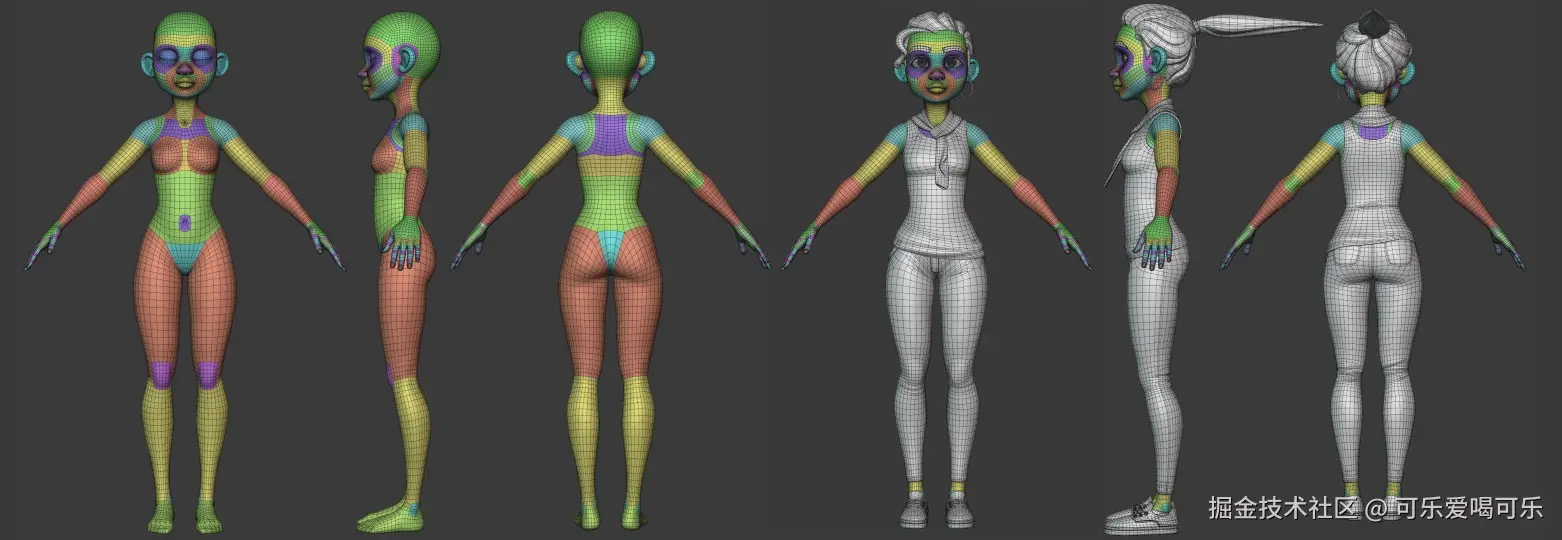
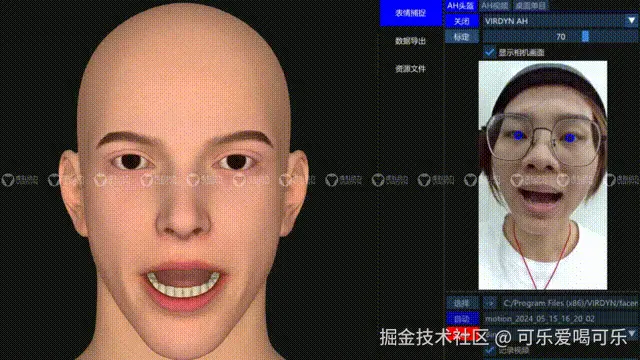
- 面部捕捉(Facial Motion Capture)
摄像头设备:例如iPhone的TrueDepth摄像头、专业面部捕捉设备(如Faceware或Dynamixyz),用于捕捉真实人类的面部表情。
实时捕捉技术:通过摄像头捕捉面部表情并映射到虚拟角色上。通过AI算法将捕捉到的面部关键点转化为虚拟角色的面部动作。
- 实时渲染引擎
Unreal Engine 或 Unity:这些引擎支持高质量的实时渲染和动画展示。它们可以使用面部捕捉数据进行实时驱动虚拟人的口型和表情。
Metahuman Creator(虚幻引擎中的数字人工具):用于快速创建高质量的虚拟人并支持面部动画的实时生成。
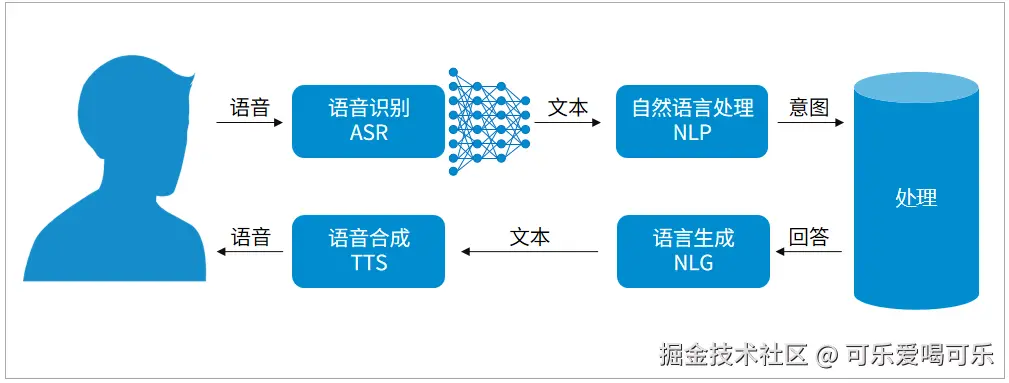
- 语音驱动口型同步(Lip Sync)
Viseme生成器:根据语音自动生成与声音同步的口型(Viseme),工具如Adobe Character Animator、Rhino或JALI或Audio2Face等
语音识别与AI:结合深度学习模型,如Google的Tacotron或Facebook的Wave2Lip,将语音内容转换为虚拟人的嘴唇动作。

- 人工智能与机器学习
深度学习模型:训练面部表情、语音驱动的AI模型,通过GAN(生成对抗网络)或RNN(递归神经网络)生成更加逼真的表情。
Pose Estimation模型:例如OpenPose或MediaPipe,可以实时捕捉人体和面部的姿态和表情。
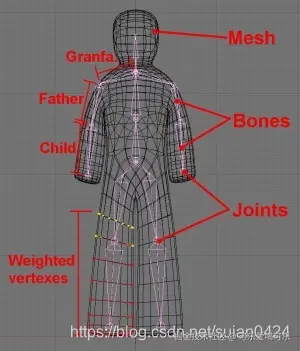
- 骨骼驱动动画
通过骨骼系统控制角色的面部骨骼,可以实现复杂的面部表情变化。这通常与动画系统或AI结合,进行表情的自动生成。
- 音频处理与合成
TTS(Text-to-Speech)系统:结合虚拟人的口型,自动生成自然的语音。通过合成的语音驱动虚拟人,完成更真实的对话。
音频分析工具:例如Praat或其他音频分析软件,用于分析语音中的声音特征并同步虚拟人的口型。
参考资料:
GitHub - YUANZHUO-BNU/metahuman_overview: 数字人资料整理


