常见的求微分方法
如何将微分应用于机器学习

我们前面的文章中已经介绍过,机器学习算法都是由上述三个部分组成: 假设类、 损失函数、 优化方法。我们的目标是优化假设类的参数,使得损失函数值能够达到最小,而优化参数这一过程中就需要对参数求偏导,从而需要利用微分操作。
数值微分
很多读者可能对微分和求导傻傻分不清,先给大家介绍一下两者的区别:
在数学和机器学习的背景下,"微分"和"求导"通常是密切相关的概念,但它们并不是完全相同的。
- 求导:这是一个操作,指的是找到一个函数的导数。导数表示函数的变化率。例如,对于函数 f(x),求导的结果是f′(x),表示f(x)在点x处的变化率。
- 微分:这是一个更广泛的概念。微分可以看作是导数的一种应用,涉及到函数在某一点处的线性近似。对于函数f(x),在点x处的微分df可以写成df=f′(x)dx,这里dx表示x的一个很小的增量。
在机器学习中,"微分"和"求导"常常被用来描述同一个过程,即计算损失函数对模型参数的变化率。但是,从严格的数学角度来看:
- 求导更侧重于找到函数的导数。
- 微分更侧重于函数值的微小变化以及这种变化的近似。
总的来说,在机器学习领域,这两个术语可以在多数情况下互换使用,但理解它们的细微区别可以帮助更深入地理解相关概念。
我们直接通过定义计算偏导数可以使用下面的定义式:
∂θi∂f(θ)=ϵ→0limϵf(θ+ϵei)−f(θ)
其中ei为单位基,即其中元素只有在θi位置处为1,其它位置处为0。
如果我们想要更高的精度,可以使用下面的式子来近似:
∂θi∂f(θ)=2ϵf(θ+ϵei)−f(θ−ϵei)+o(ϵ2)
上述式子是如何得到的呢,在高数课程中我们学习过泰勒公式,知道它是多项式近似表达函数的一个重要工具。对于在点a处具有n阶可导的函数f(x),其泰勒展开式可以表示为:
f(x)=f(a)+f′(a)(x−a)+2!f′′(a)(x−a)2+3!f′′′(a)(x−a)3+⋯+n!f′′′(a)(x−a)n+Rn(x)
其中:
- f(a)是函数在a处的值,
- f′(a)是函数在a处的一阶导数,
- f′′(a)是函数在a处的二阶导数,
- f′′′(a)是函数在a处的三阶导数,
- 依此类推,
- Rn(x)是n阶泰勒多项式的余项。
我们只需把x取θ+δ, a取θ,将泰勒公式展开到二阶导数项,得到:
f(θ+δ)=f(θ)+f′(θ)δ+21f′′(θ)δ2+o(δ2)
然后我们分别将ϵei和−ϵei代入δ,然后将两式相减,即可推导出那个精度更高的式子。
上述介绍的两种基于数值计算的微分方法,可以很好的避免误差精度问题,但是计算成本比较大,在机器学习算法中我们不使用这种方法来进行计算,而是把这种方法当作一种验证自动微分算法是否实现正确的工具。
也通常将这种数值微分计算出来的结果作为自动微分算法的单元测试案例。
δT∇θf(θ)=2ϵf(θ+ϵδ)−f(θ−ϵδ)+o(ϵ2)
符号微分
从高数课堂中,我们应该学习过下面的一些求偏导的法则:
∂θ∂(f(θ)+g(θ))=∂θ∂f(θ)+∂θ∂g(θ)
∂θ∂(f(θ)g(θ))=g(θ)∂θ∂f(θ)+f(θ)∂θ∂g(θ)
∂θ∂(f(g(θ))=∂g(θ)∂f(g(θ))∂θ∂g(θ)
通过这些法则来求偏导会导致很大的计算开销。
例如:
对于f(θ)=∏i=1nθi,可得到∂θkf(θ)=∏j=knθj,要计算所有θ的偏导数的话,需要计算n(n−2)次乘法。
计算图
上面的例子中我们发现直接对每个参数求偏导存在很大的计算开销,那么我们有什么方法能够优化这些计算开销呢?
一个很直观的想法,我们可以将一些其它式子也能用到的中间结果保存下来,那么其它式子需要用的时候就不需要再重新计算了。
我们可以用一个有向无环图(Directed Acyclic Graph,DAG)来表示式子。
如:
y=f(x1,x2)=ln(x1)+x1x2−sinx2
对于上述函数,我们可以用下面的计算图来表示:
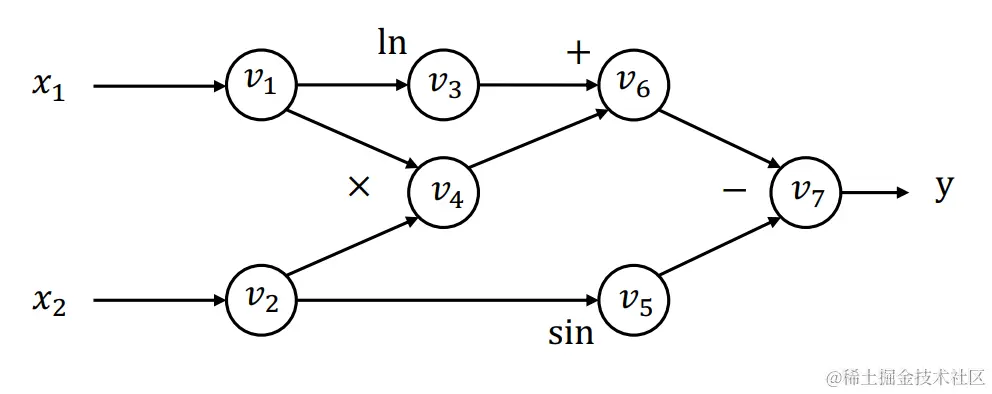
每一个节点代表一个中间结果,边代表输入输出关系。
前向计算过程如下:
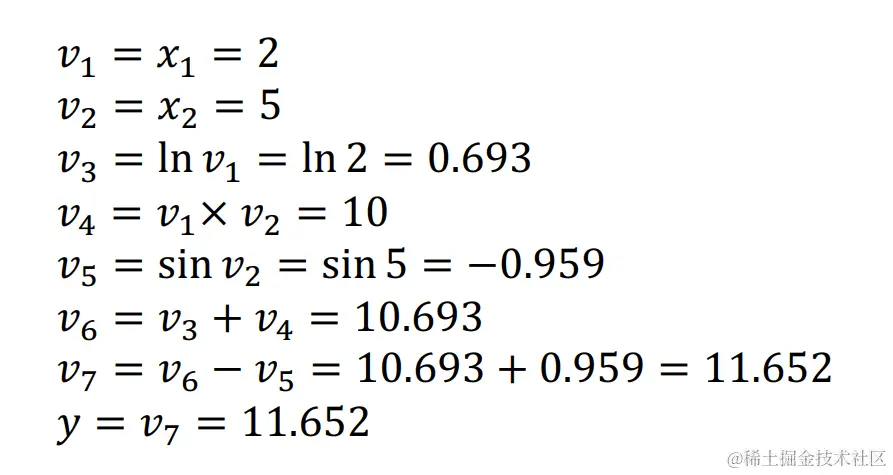
前向模式自动微分算法
对于前向微分计算,我们定义vi˙=∂x1∂vi,我们同样可以通过迭代计算图来计算vi˙
前向自动微分计算过程如下:
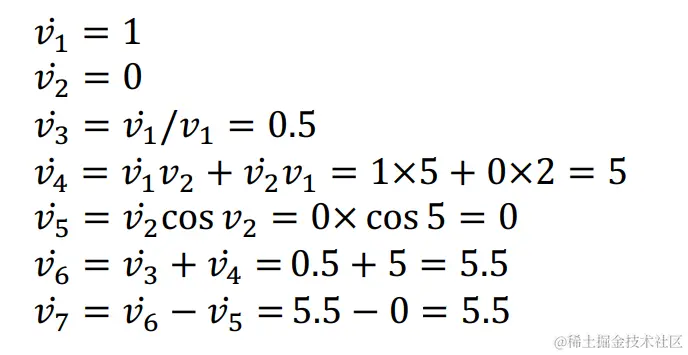
通过前向自动微分算法,我们得到了∂x1∂y=v7˙=5.5
前向模式自动微分算法的缺陷
对于一个f:Rn→Rk的假设函数,我们需要对n个输入,将计算图计算n次来求各自参数的梯度,当n比较小而k比较大时,这种计算方式开销还不算很大。
但是在深度学习中,我们的假设函数通常是具有很多参数(即n值很大)的,而输出通常是一个标量(即k=1)。
在这种情况中,前向自动微分算法的计算开销就比较大了,我们需要使用其它的自动微分算法来改善这种计算开销。
反向模式自动微分算法
在介绍反向模式自动微分算法时,我们还是使用前面的这个例子:
y=f(x1,x2)=ln(x1)+x1x2−sinx2
计算图还是:
我们定义: vi=∂vi∂y,我们可以通过计算图反向迭代计算viˉ,计算过程如下:
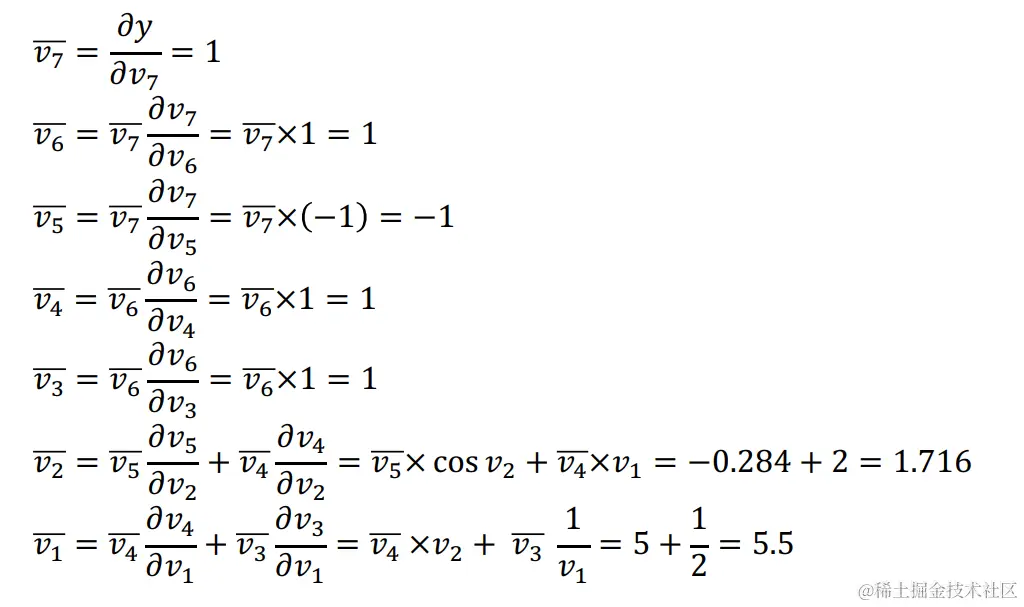
求偏导中的一种特殊情况
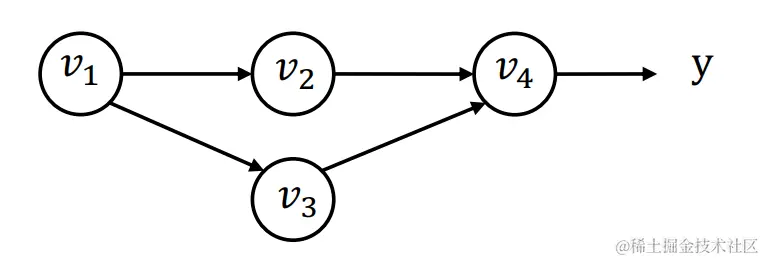
当v1同时作为多条路径的输入(如v2、v3)
这种情况要如何计算微分呢?我们可以把假设函数写成y=f(v2,v3)这种形式,那么对v1求偏导就可以写成:
v1=∂v1∂y=∂v2f(v2,v3)∂v1∂v2+∂v3f(v2,v3)∂v1∂v3=v2∂v1∂v2+v3∂v1∂v3
定义vi→j=vj∂vi∂vj,其中j是每个和i相邻接的计算图节点, 那么我们可以得到
vi=j∈next(i)∑vi→j
通过计算和i节点相邻接的j节点的梯度,然后将它们相加得到i节点处的梯度
反向自动微分算法
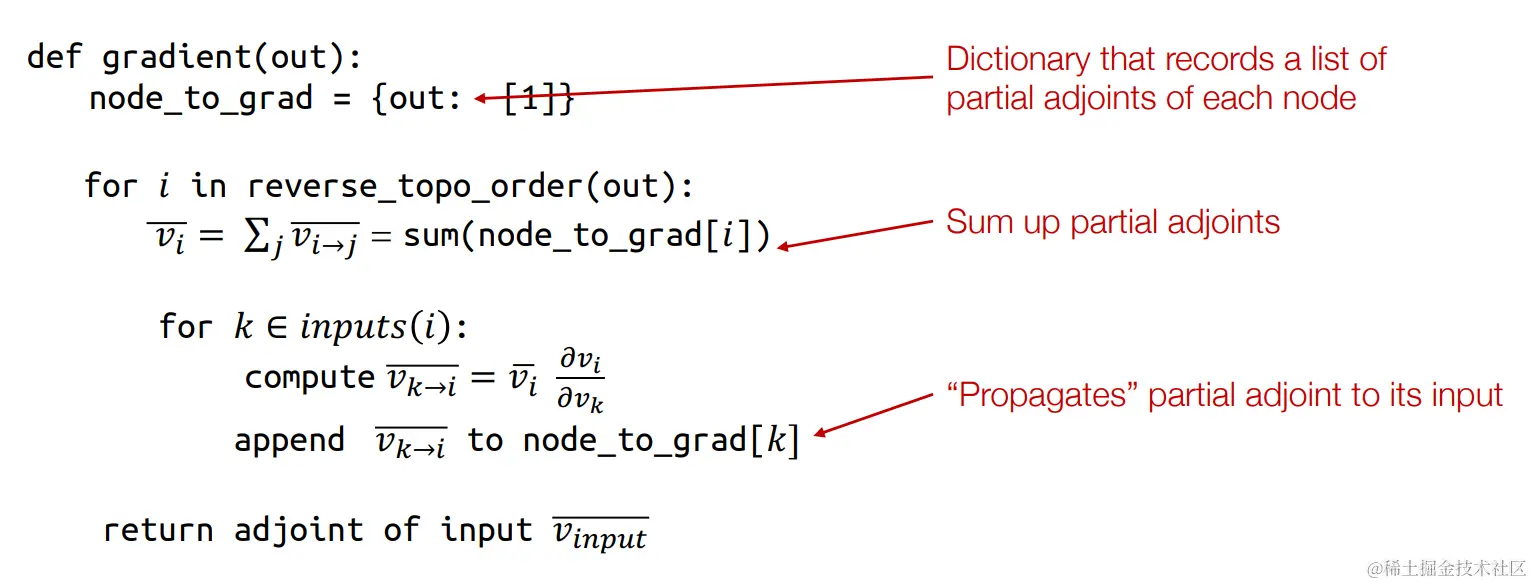
反向自动微分算法案例
使用反向自动微分算法计算,我们需要重新构建一个计算图,我们以下面的例子开始,一步步的介绍反向自动微分的过程:
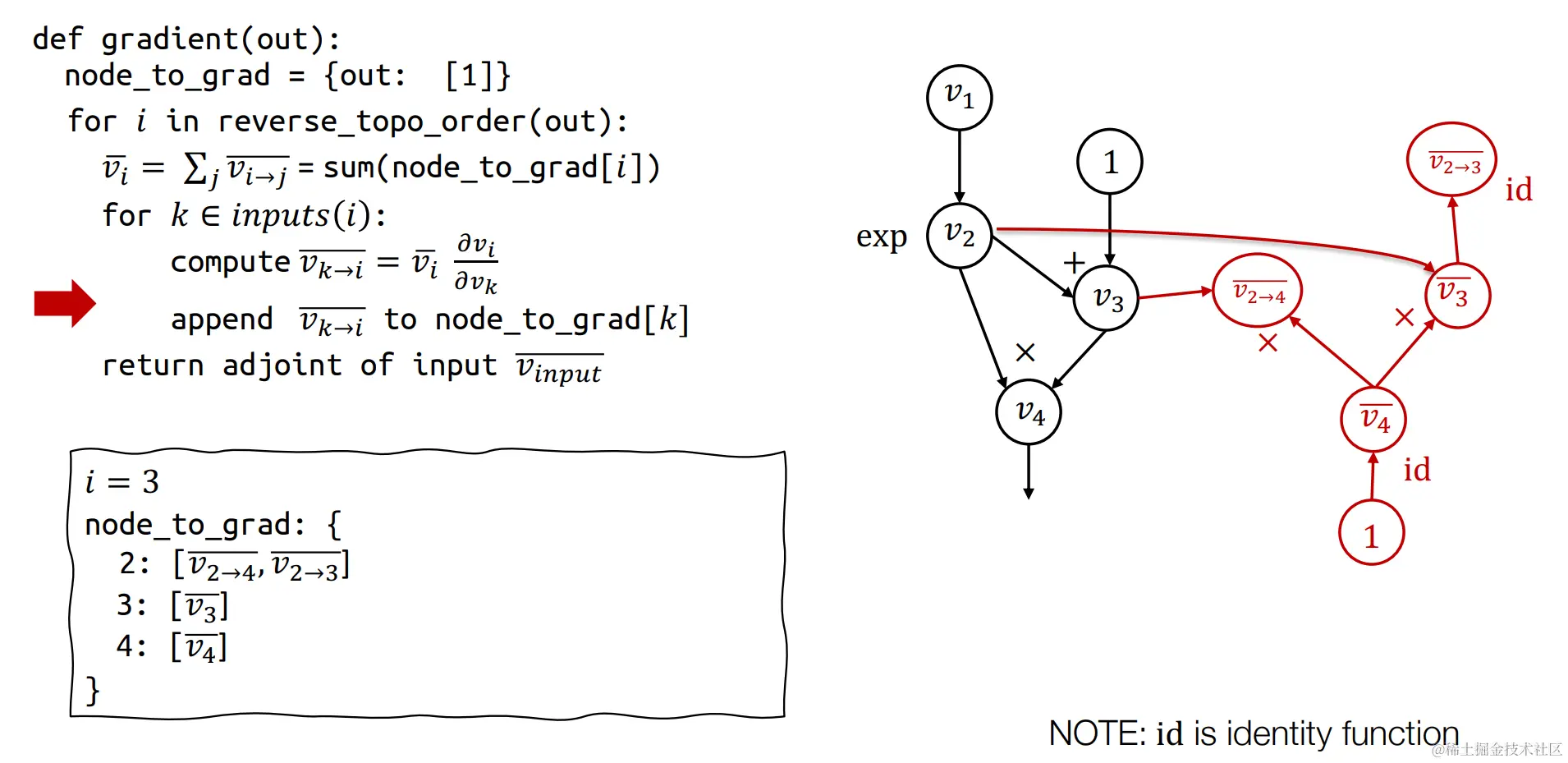
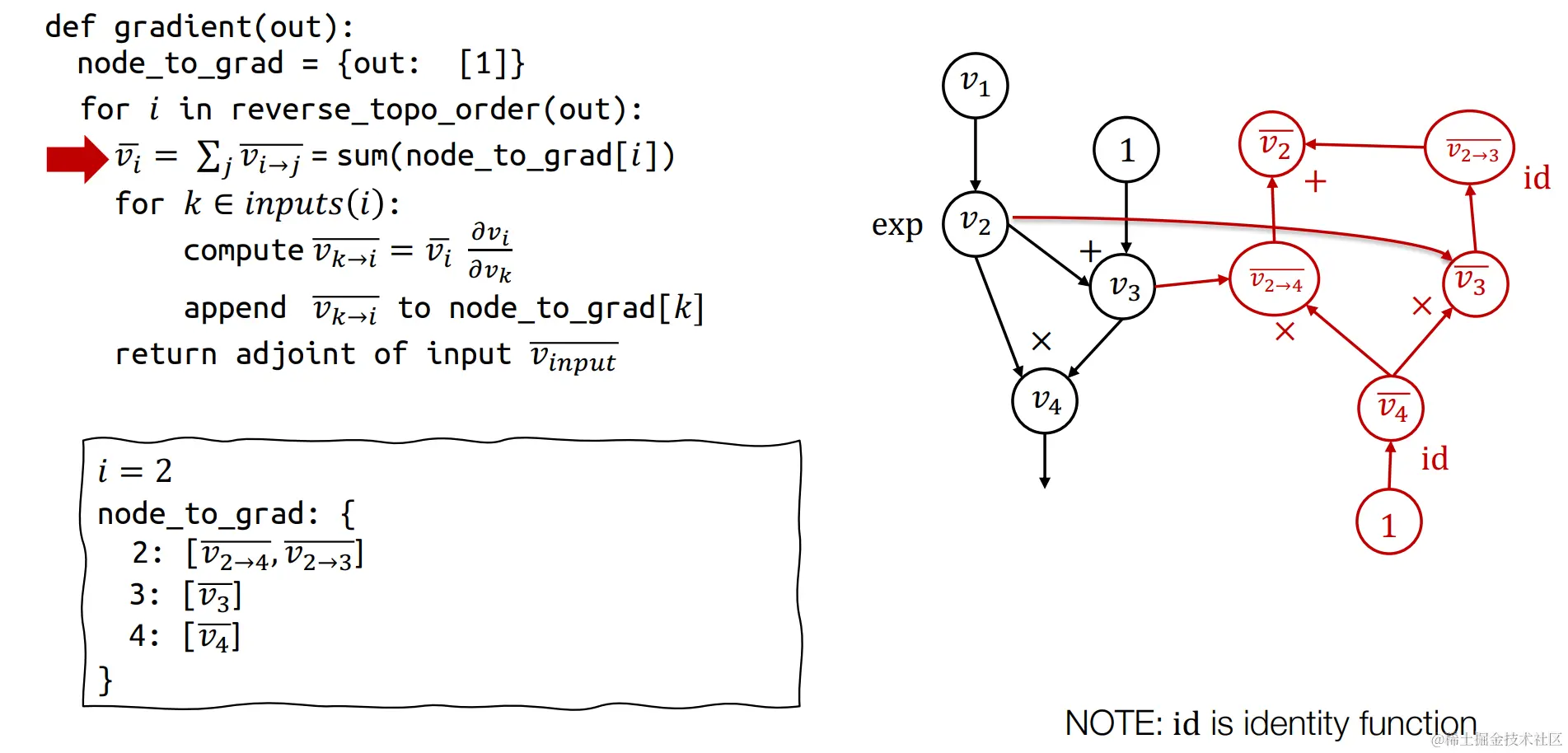
 左侧为反向自动微分算法伪代码,右侧为原始正向计算图,下面我们来构建反向自动微分计算图
左侧为反向自动微分算法伪代码,右侧为原始正向计算图,下面我们来构建反向自动微分计算图
 首先构建第一个反向微分的节点v4,v4=∂v4∂v4=1,
首先构建第一个反向微分的节点v4,v4=∂v4∂v4=1,id是恒等函数。
 其中v4=v2v3,那么∂v3∂v4=v2, 而v3=v4∂v3∂v4,代入得v3=v4v2,同理可推的v2→4=v4v3,故得到上述红线构建的计算图。
其中v4=v2v3,那么∂v3∂v4=v2, 而v3=v4∂v3∂v4,代入得v3=v4v2,同理可推的v2→4=v4v3,故得到上述红线构建的计算图。
同理,我们采用上述的推导方式,可以逐渐构造出反向自动微分的计算图
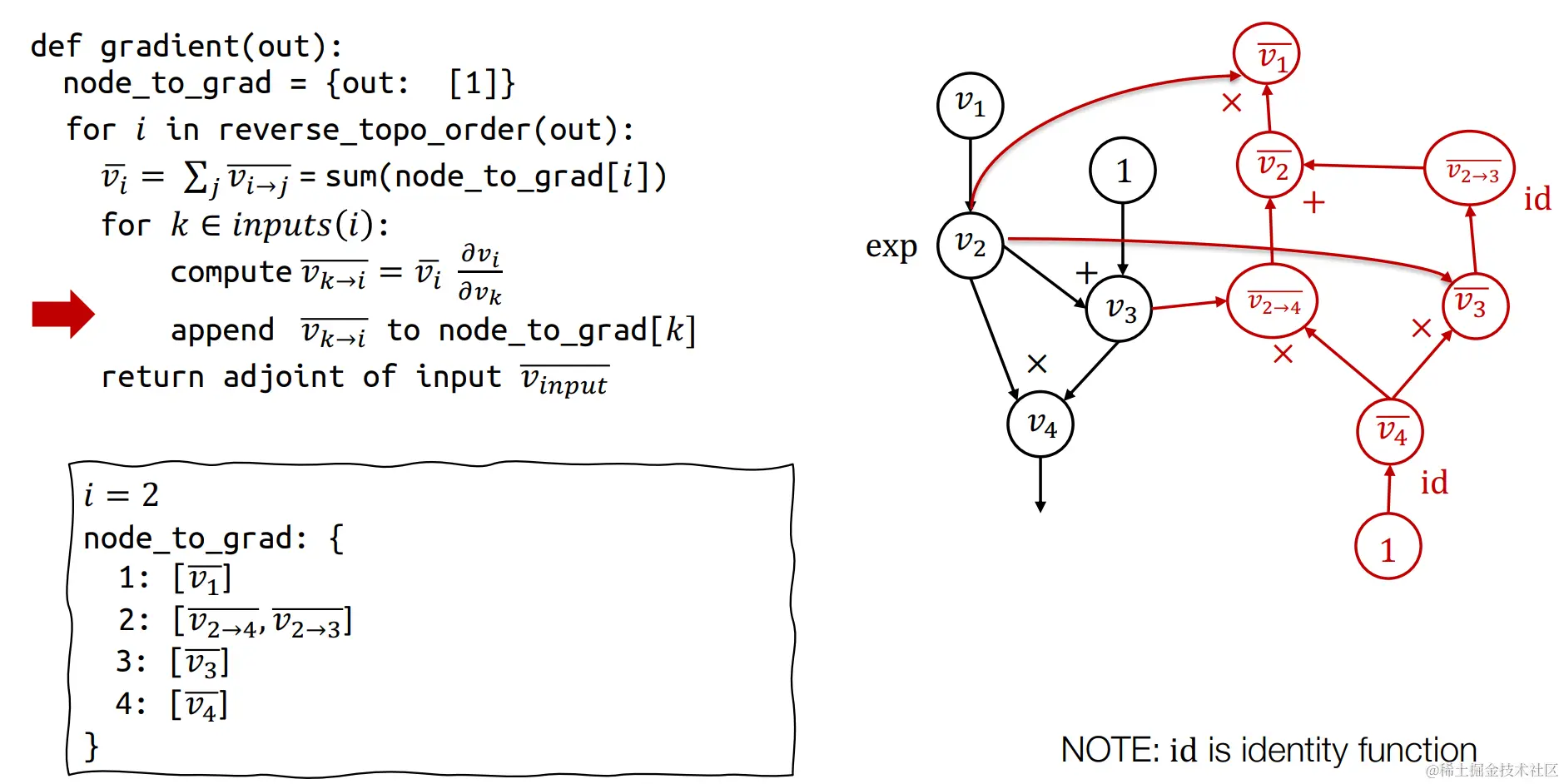
反向传播 VS 反向自动微分
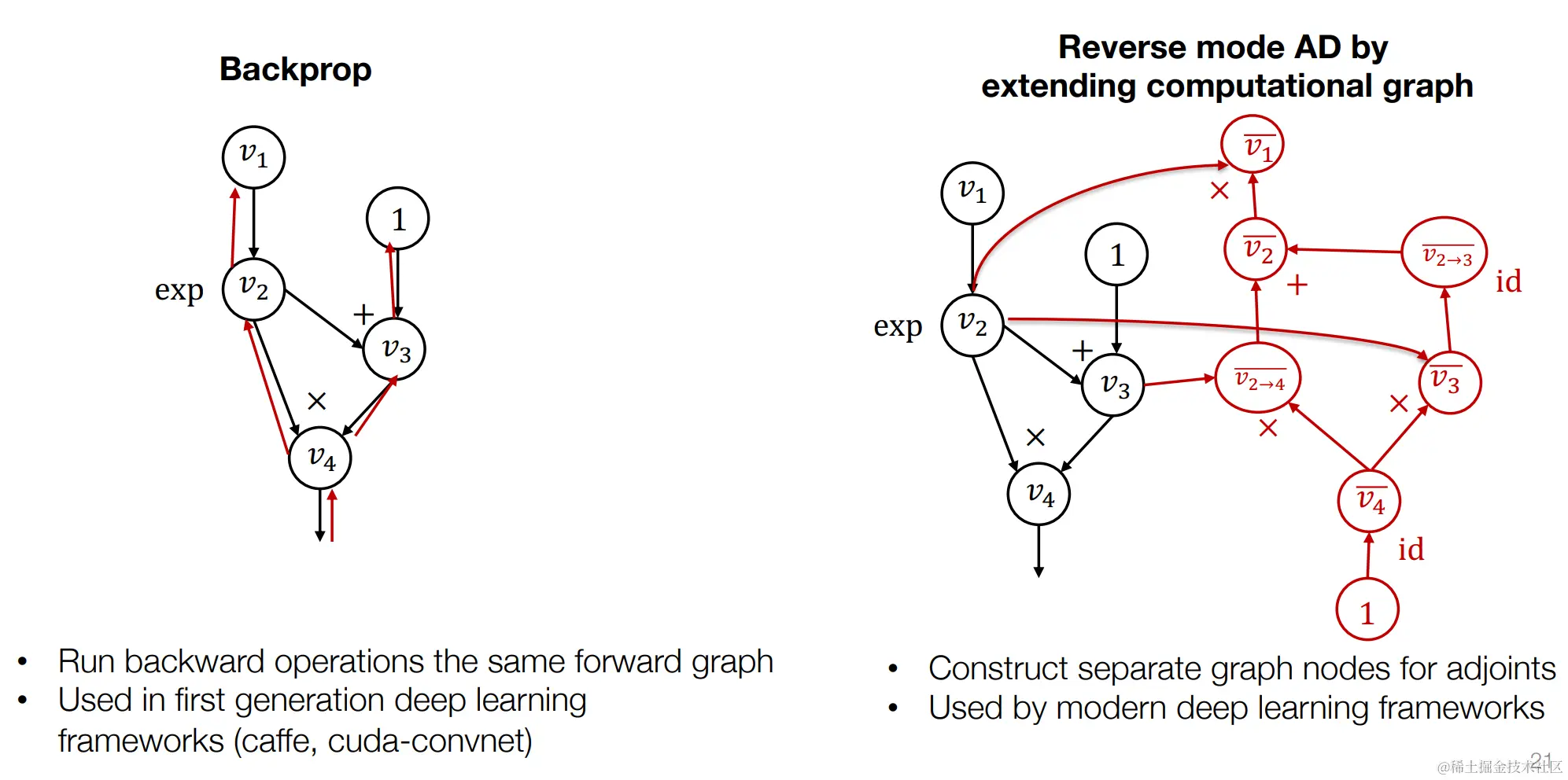
第一种方案是在原来的前向计算图上运行反向传播操作,这种方案可以节省一部分内存,但是这种方式,只能得到反向的梯度,如果我们要对梯度在求梯度的话就无法继续操作了。这也是一些老的深度学习框架中使用的方法。
第二种方案重新构造了一个反向微分的计算图,这会比前一种方式多使用一些内存,但是这种方式的好处是:梯度仍然是一个计算图,我们可以使用同样的方法来计算梯度的梯度。目前主流的深度学习框架都是使用这种方式(如:pytorch、tensorflow)
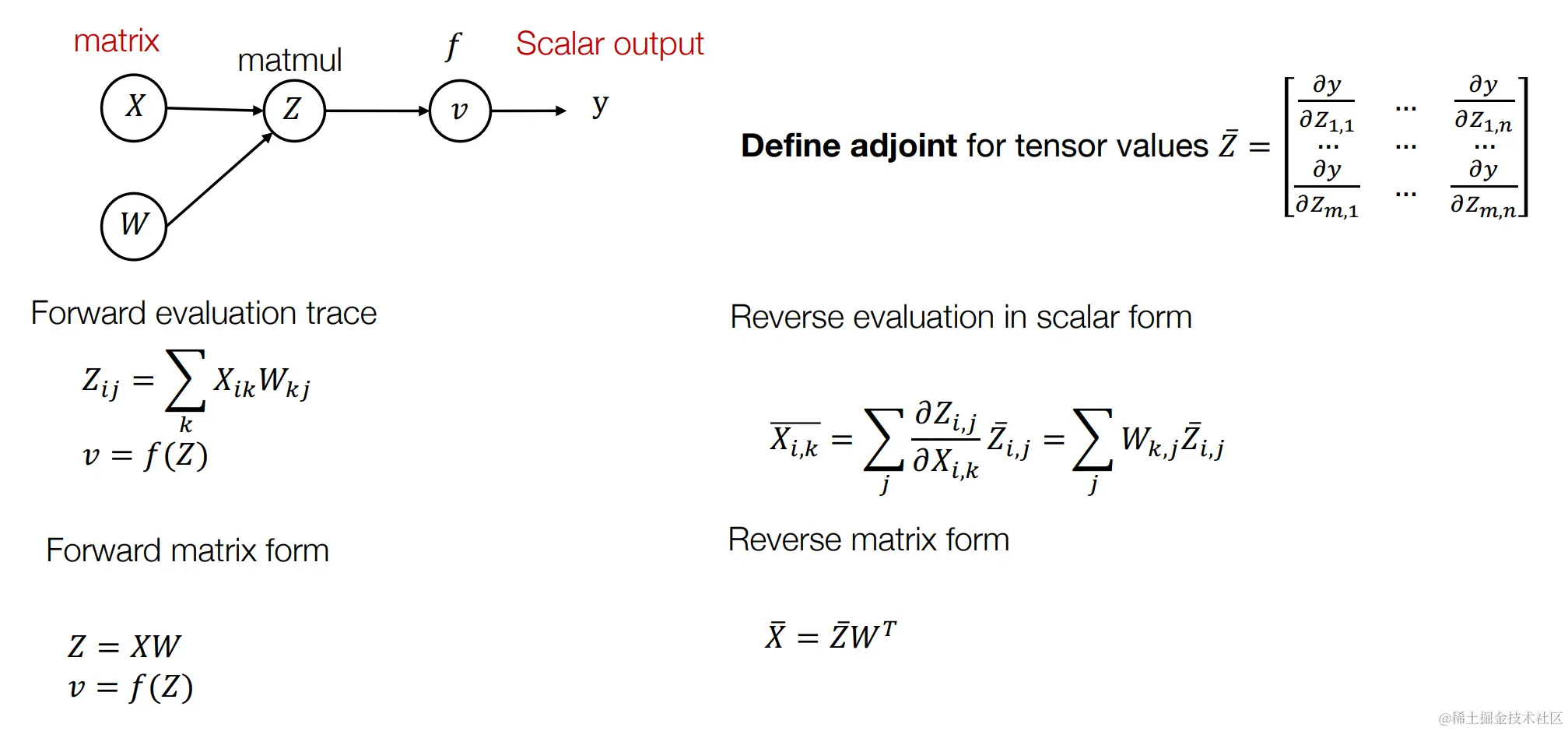
对张量(Tensors)使用反向模式自动微分算法
张量(tensor)是数学和物理学中的一个重要概念,广泛应用于机器学习和深度学习领域。张量可以被看作是多维数组,能够表示标量、向量、矩阵以及更高维度的数据结构。