一、torch.nn.LayerNorm() 归一化
层归一化是一种用于神经网络中的归一化技术,类似于批归一化(Batch Normalization),但是在不同维度上进行归一化。
重要参数
`normalized_shape`:要归一化的张量的形状。
`eps`:用于数值稳定性的小值,防止分母为零。
为什么使用LayerNorm()
1. `减少内部协变量偏移(Internal Covariate Shift)` :层归一化有助于减少神经网络中的内部协变量偏移,即每一层输入的分布在训练过程中的变化。这有助于网络的收敛速度和稳定性。
2. `适用于小批量训练和低延迟推理`:相对于批归一化,层归一化更适用于小批量训练和低延迟推理,因为它在单个样本上进行归一化,而不是整个批次。
3. `适用于序列数据`:层归一化在处理序列数据时特别有用,因为它在每个时间步骤(序列中的每个位置)上进行归一化,而不会引入时间相关性问题。
4. `无需计算均值和方差`:相对于批归一化,层归一化不需要计算均值和方差,因此计算成本较低。
5. `减少训练和推理中的依赖性`:层归一化对于不同样本的归一化是独立的,因此减少了训练和推理过程中的依赖性,有助于网络的泛化性能
批归一化
torch.nn.BatchNorm1d
torch.nn.BatchNorm2d
torch.nn.BatchNorm3d
二、循环神经网络 - GRU
1 什么是GRU
GRU是循环网络的一种,是为了解决长期记忆和反向传播中的梯度等问题而提出的一种神经网络结构,是一种用于处理序列数据的神经网络。
2 GRU输入输出结构
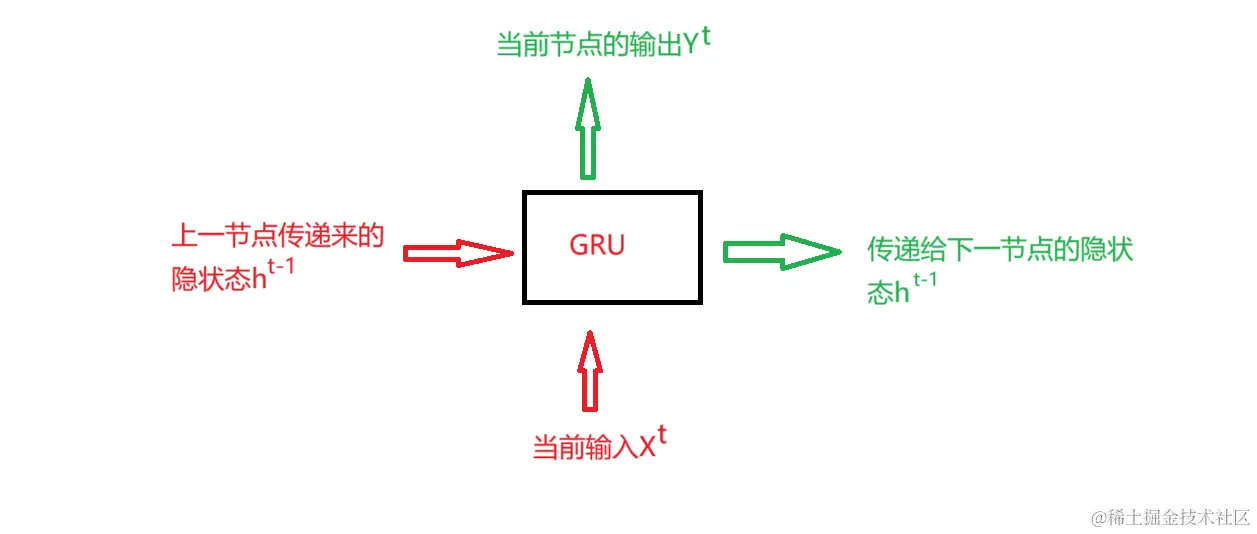
3 GRU和LSTM
GRU和LSTM在很多情况下实际表现上相差无几,`但是GRU更易于计算`
GRU 2014年提出
LSTM 1997提出
4 GRU的内部结构
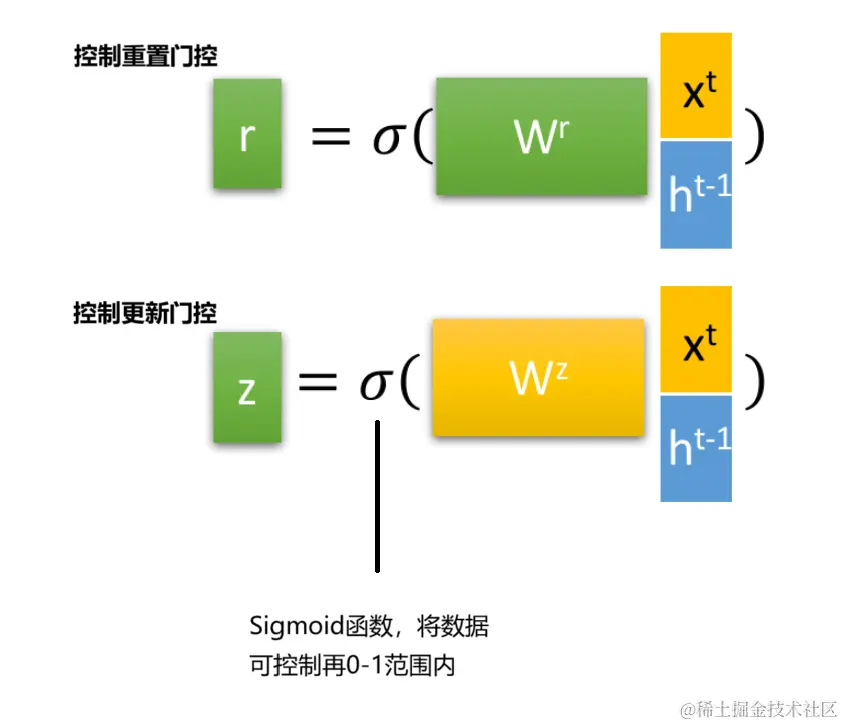
重置门
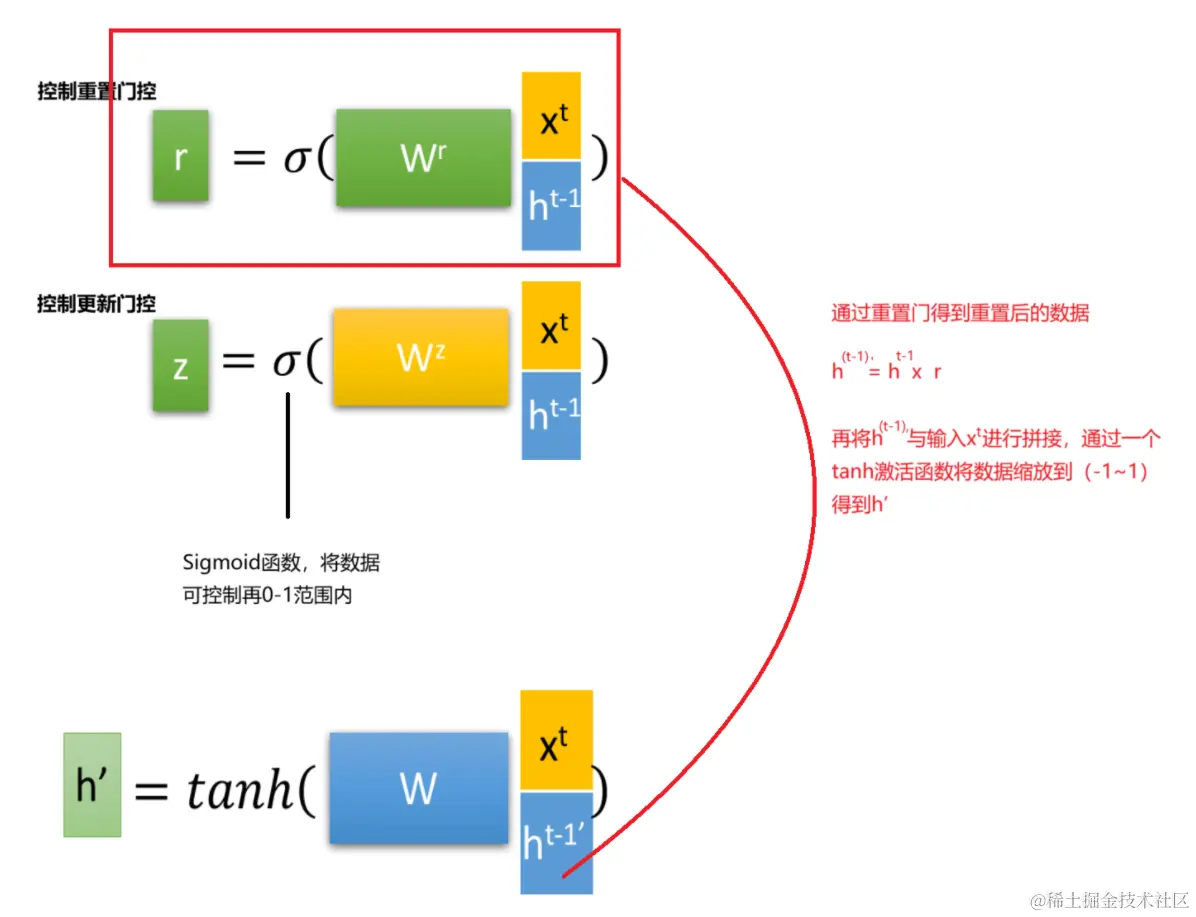
更新门
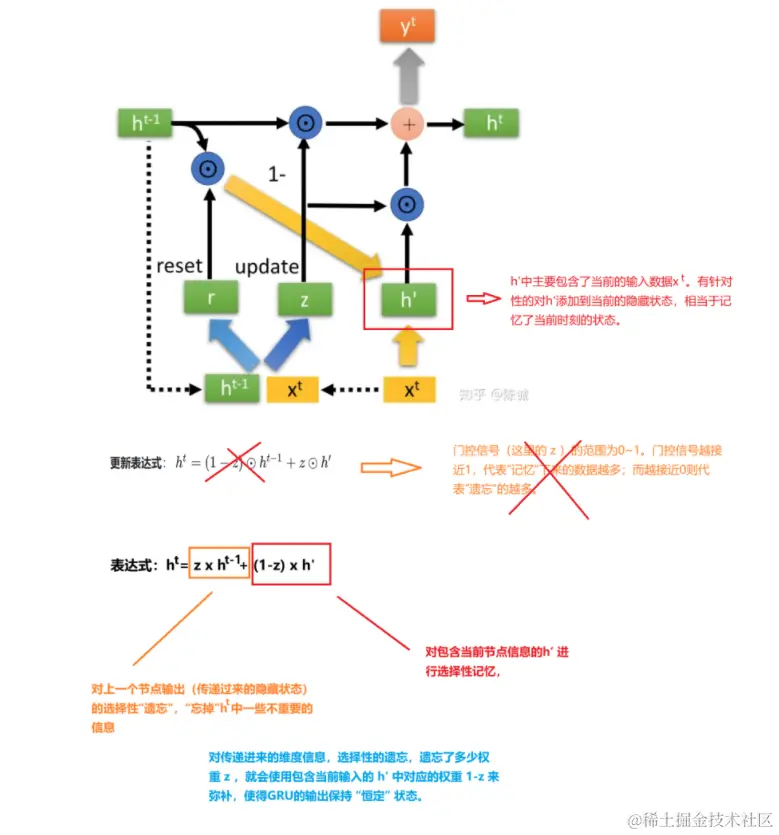
GRU很聪明的一点就在于,使用了同一个门控就同时可以进行遗忘和选择记忆,而LSTM则要使用多个门控
参考:
Pytorch2.0 深度学习从零开始学
知乎:https:


