

LangChain调研
概述
LangChain 简介
LangChain是一款用于开发由LLM驱动的应用程序的开发框架(SDK)。
 首先,我们要了解:所有开发框架(SDK)的核心价值,都是降低开发、维护成本。
LLM开发框架的价值,是让开发者可以更方便地开发基于LLM的应用。主要提供两类帮助:
首先,我们要了解:所有开发框架(SDK)的核心价值,都是降低开发、维护成本。
LLM开发框架的价值,是让开发者可以更方便地开发基于LLM的应用。主要提供两类帮助:
- 第三方能力抽象。比如 LLM、向量数据库、搜索引擎等
- 常用工具、方案封装
- 底层实现封装。比如流式接口、超时重连、异步与并行等
一款好的LLM开发框架,需要具备以下特点:
- 与外部功能解依赖
- 比如可以随意更换 LLM 而不用大量重构代码
- 更换三方工具也同理
- 经常变的部分要在外部维护而不是放在代码里
- 比如 Prompt 模板
- 各种环境下都适用
- 比如线程安全
- 方便调试和测试
- 至少要能感觉到用了比不用方便吧
- 合法的输入不会引发框架内部的报错
选对框架,事半功倍;反之,事倍功半。
目前市面上的主流LLM开发框架有很多,这里我列举三个目前比较优秀的框架来举例,如下图:
通过 图数据来源 可以了解到Langchain的大致信息,也可以让我们对于LLM开发框架的选型有一个大致方向。
- Langchain框架的模块主要包含:代理、链、索引、内存、提示、模型、模式。
- Langchain的使用主要基于Python和JS。
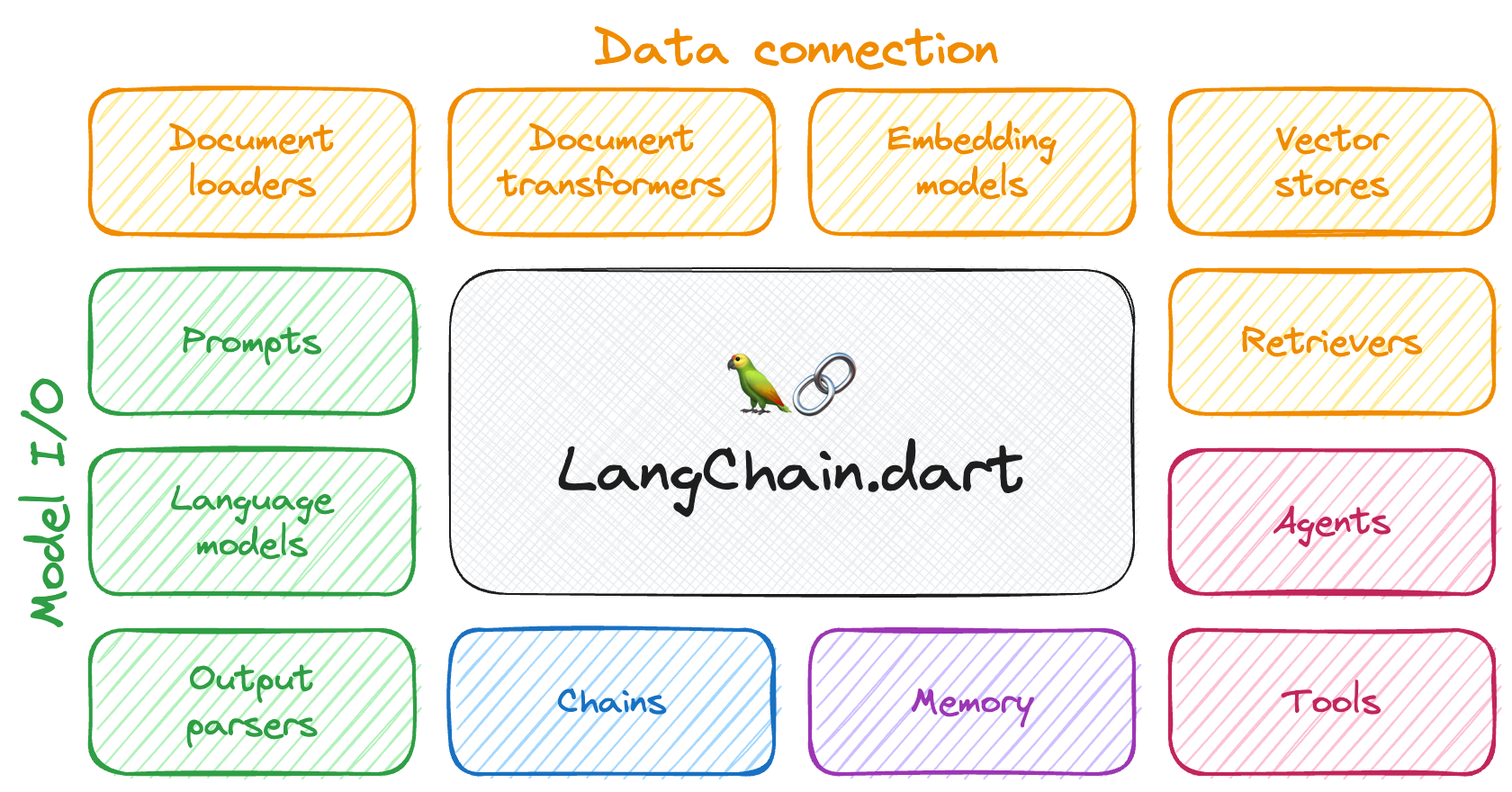
LangChain 框架组件
框架整体架构
各组件功能说明
- 模型 I/O 封装
- LLMs:大语言模型
- Chat Models:一般基于 LLMs,但按对话结构重新封装
- PromptTemple:提示词模板
- OutputParser:解析输出
- 数据连接封装
- Document Loaders:各种格式文件的加载器
- Document Transformers:对文档的常用操作,如:split, filter, translate, extract metadata, etc
- Text Embedding Models:文本向量化表示,用于检索等操作(啥意思?别急,后面详细讲)
- Verctorstores: (面向检索的)向量的存储
- Retrievers: 向量的检索
- 记忆封装
- Memory:这里不是物理内存,从文本的角度,可以理解为“上文”、“历史记录”或者说“记忆力”的管理
- 架构封装
- Chain:实现一个功能或者一系列顺序功能组合
- Agent:根据用户输入,自动规划执行步骤,自动选择每步需要的工具,最终完成用户指定的功能
- Tools:调用外部功能的函数,例如:调 google 搜索、文件 I/O、Linux Shell 等等
- Toolkits:操作某软件的一组工具集,例如:操作 DB、操作 Gmail 等等
- Callbacks
代理(Agents)
关于Agent的概念以及工作原理具体讲解可以借鉴我之前写过的一篇文章:AI Agent的概念以及工作原理 LangChain 作为一个LLM框架,用于构建和部署与语言模型交互的应用程序,特别是那些涉及到自动化决策和智能代理(Agent)的应用。它提供了一系列工具和API,让开发者能够更容易地集成和使用大型语言模型。下面是一个简单的使用示例,展示如何使用LangChain中的一个Agent进行基本的交互:
安装LangChain 首先,你需要确保你的环境中安装了LangChain。你可以通过pip来安装:
pip install langchain
创建并使用一个Agent 假设我们想创建一个简单的Agent,它能够处理关于天气信息的请求。以下是如何实现的一个基本示例:
from langchain_community.llms import OpenAI
from langchain.agents import Tool
from langchain.agents import initialize_agent
from langchain.agents import AgentType
# 配置API密钥和基础URL
openai_api_key = "" # 你的OpenAI API密钥
api_base = "" # OpenAI API的基础URL
llm = OpenAI(api_key=openai_api_key, base_url=api_base) # 创建一个OpenAI客户端,用于与OpenAI API进行交互
# 定义一个天气查询工具
weather_tool = Tool(
name="weather_query",
func=lambda location: f"Weather in {location} is sunny.", # 实际应用中需要调用天气API
description="A tool to query the weather at a specific location."
)
# 初始化Langchain的Agent
agent = initialize_agent([weather_tool], llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True)
# 使用Agent查询天气
location = "Beijing"
result = agent.run(f"Query the weather in {location}")
print(result)
!!!请注意,这个示例需要你有一个有效的OpenAI API密钥。此外,实际的应用可能需要对语言模型的回答进行进一步的处理和验证,以确保结果的准确性和可用性。 这只是一个非常基础的例子,LangChain框架的使用远不止于此。
链(Chains)
LangChain 中的 "chain" 是指链式操作或者序列化操作,它是一种将多个任务或操作按照一定的顺序组合起来,以实现特定目标的方法。在 LangChain 框架中,这个概念主要用于描述一系列基于大型语言模型(LLM)的应用程序。 chain的分类: 主要分为LLMChain,Sequential Chains,Router Chain,其中LLMChain是最基本的chain它简单的组合了LLM和promt, Sequential Chains主要包含SimpleSequentialChain和SequentialChain,对于SimpleSequentialChain来说它只是简单的将多个LLMChain串联在一起,前一个chain的输出是后一个chain的输入,所以总体上来说SimpleSequentialChain只有一个输入和一个输出,而SequentialChain则具体多个输入或输出。而Router Chain则是具有路由功能的chain ,它可以将用户的问题进行分类,从而将问题传递给特定的chain。
基于LLMChain的简单示例:
from langchain_community.chat_models import ChatOpenAI
from langchain.chains import LLMChain
from langchain.chains.retrieval_qa.prompt import PROMPT
# 使用的模型
chat = ChatOpenAI(
model_name="gpt-4-1106-preview",
temperature=0.5,
openai_api_key="",
)
# 给出的context
context = """
充值金额 charge_money
退款金额 refund_money
广告费 ad_money
充值人数 charge_people
登陆人数 login_people
"""
# 创建链
chain = LLMChain(llm=chat, prompt=PROMPT)
# 模板里有变量占位符question和context,所以这里指定这两个参数
rs = chain.run(question="和充值有关的指标有哪些?", context=context)
print(rs)
这个链的目的是根据提供的问题和上下文,使用语言模型生成一个相关的回答。在这个例子中,问题是要找出和充值有关的指标,代码中的context提供了一些可能的指标。语言模型就会根据这些信息生成一个回答。
Chain链复杂示例:
from langchain import LLMChain, PromptTemplate
from langchain.chat_models import ChatOpenAI
# 步骤一
# 接着上一节,对语言识别成指标的prompt也做一点改造,功能是:解析自然语言,转换为对应格式Json
llm = ChatOpenAI(
model_name="gpt-4-1106-preview",
temperature=0,
openai_api_key="",
base_url="",
)
# 示例
example = """
example:
Sentence:星穹铁道2022年8月充值金额、退款金额、广告费,按天、渠道
Result:
{
"metas": ["充值金额", "退款金额", "广告费"],
"dims": ["天", "渠道"],
"filters": {"游戏":"凡人修仙传", "时间":"2022年8月"}
}
"""
# 模板内容,使用了format_instructions和question占位符
template = """Recognize all the meta names, dimension names, and filters in the given sentence, return them in json format.
{format_instructions}
Sentence: {question}
Result:"""
# 限定模板接收的输入question,对format_instructions使用示例example填充
prompt_template = PromptTemplate(
input_variables=["question"],
partial_variables={"format_instructions": example},
template=template,
)
# verbose开启调试日志
split_chain = LLMChain(llm=llm, prompt=prompt_template, verbose=True)
result = split_chain.run("凡人修仙传2023年上半年的广告费、渠道费、税费,按自然月、平台、服务器")
print(result) # 会给出链的完整处理流程和对话内容
# 步骤二
# 对自然语言形成的Json做转码,换成我们自己定义的内容。
# 这里预先给出一些指标和维度的定义,并告诉AI要换掉他们,时间也要换成start_date和end_date
template = """Use the following pieces of context, convert mata and dimension and filter names to code. Convert the filters '时间' into start_date and end_date.
指标:
充值金额 charge_money
退款金额 refund_money
广告费 ad_fee
渠道费 channel_fee
税费 tax_fee
维度:
自然月 month
天 day
游戏 game
平台 platform
服务器 server
{format_instructions}
{inputs}
Result:"""
example = """
example:
{
"metas": ["充值金额", "退款金额"],
"dims": ["天"],
"filters": {"时间":"2023年","游戏":"109,110"}
}
Result:
{
"metas": ["charge_money", "refund_money"],
"dims": ["day"],
"filters": {"start_date":"2023-01-01 00:00:00", "end_date":"2023-12-31 23:59:59", "game": "109,110"}
}
"""
prompt_template = PromptTemplate(
input_variables=["inputs"],
partial_variables={"format_instructions": example},
template=template,
)
convert_chain = LLMChain(llm=llm, prompt=prompt_template, verbose=True)
question = """
{
"metas": ["广告费", "渠道费", "税费"],
"dims": ["自然月", "平台", "服务器"],
"filters": {"游戏":"凡人修仙传", "时间":"2023年上半年"}
}
"""
result = convert_chain.run(question)
print(result)
# 步骤三
# 将前面两个链串起来,这里使用LangChain提供的顺序链
from langchain.chains import SimpleSequentialChain
# 这里的split_chain和convert_chain就是上面两段示例中的同名变量链,这里就不再复制一遍代码了
overall_chain = SimpleSequentialChain(chains=[split_chain, convert_chain], verbose=True)
result = overall_chain.run("凡人修仙传2023年上半年的广告费、渠道费、税费,按自然月、平台、服务器")
print(result)
到这里就完成了一个链的组装,后续只需要调用步骤三里的overall_chain就可以得到最后格式化的Json了。 但还有一些问题没有处理。
- 第二条链里提示的指标数太少,而一旦提供全量指标,可能会超出对话Token限制
- 自然语言识别成Json的Prompts显然还需要调优,以兼容更多对话方式
- 我们解析出来Json要怎么使用呢?或许还需要用到LangChain的Tools
索引(Indexes)
LangChain的索引(Indexes)是一种用于构建结构化文档的模块,以便大型语言模型(LLM)可以与之更好地交互。这些索引通过记录管理器(RecordManager)来跟踪文档写入向量存储的过程,为每个文档计算哈希,并存储文档哈希(包括页面内容和元数据的哈希)、写入时间等信息。
内存(Memory)
当我们在使用大型语言模型进行聊天对话时,大型语言模型本身实际上是无状态的。语言模型本身并不记得到目前为止的历史对话。每次调用API结点都是独立的。 所以要想具备聊天对话功能,那肯定是要将历史对话记录存起来,下次对话时一同输入:历史对话记录+当前对话来得到输出。
Memory可以明确地存储到目前为止的所有术语或对话。这个Memory存储器被用作输入或附加上下文到LLM中,以便它可以生成一个输出,就好像它只有在进行下一轮对话的时候,才知道之前说过什么。 示例代码:
from langchain.chat_models import ChatOpenAI
from langchain.chains import ConversationChain
from langchain.memory import ConversationBufferMemory
from langchain.memory import ConversationBufferWindowMemory
from langchain.memory import ConversationTokenBufferMemory
from langchain.memory import ConversationSummaryBufferMemory
# 1、初始化openai环境 + 模型调用
chat = ChatOpenAI(
model_name="gpt-4-1106-preview",
temperature=0,
openai_api_key="",
base_url="",
)
# 2、ConversationBufferMemory(),用于缓存所有对话记录
memory = ConversationBufferMemory()
# #也可预先向缓存区添加指定对话的输入输出
# memory.save_context({"input": "Hi"},
# {"output": "What's up"})
# print(memory.buffer) # 历史对话信息会存在memory.buffer里
#新建一个对话链
conversation = ConversationChain(
llm=chat,
memory = memory,
verbose=True #查看Langchain实际上在做什么,设为FALSE的话只给出回答,看不到绿色的输出内容
)
conversation.predict(input='你好,我是小白,也可以叫我爸爸')
# 当我们进行下一轮对话时,他会保留之前对话的提示(若不需要这些提示,可在构建ConversationChain设置:verbose=False)
conversation.predict(input='1+1=?')
conversation.predict(input='我叫什么名字')
# memory.buffer存储了当前为止所有的对话信息:
print(memory.buffer)
# 添加指定的输入输出内容到记忆缓存区:
memory = ConversationBufferMemory() #新建一个空的对话缓存记忆
memory.save_context({"input": "Hi"}, #向缓存区添加指定对话的输入输出
{"output": "What's up"})
print(memory.buffer) #查看缓存区结果
# Human: Hi
# AI: What's up
# 3、ConversationBufferWindowMemory()
# 因为现在chatgpt都是按输入 / 输出的token数收费的,所以如果长期对话,那保留来所有历史对话记录,那得多烧钱啊,每次输入一大堆。
# 对话缓存窗口记忆:只保留一个窗口大小的对话缓存区窗口记忆。它只使用最近的n次交互。这可以用于保持最近交互的滑动窗口,以便缓冲区不会过大。
# 用法和上面一样
memory = ConversationBufferWindowMemory(k=1) # k=1表明只保留一个对话记忆
print(memory.buffer) # 历史对话信息会存在memory.buffer里
#新建一个对话链
conversation = ConversationChain(
llm=chat,
memory = memory,
verbose=False #查看Langchain实际上在做什么,设为FALSE的话只给出回答,看到不到下面绿色的内容
)
print(conversation.predict(input="你好, 我叫小白"))
print(conversation.predict(input="1+1等于多少?"))
print(conversation.predict(input="我叫什么名字?"))
# 你好小黑!很高兴认识你。我是一个AI助手,我可以回答你的问题或者和你聊天。有什么我可以帮助你的吗?
# 1+1等于2。这是一个非常简单的数学问题。
# 很抱歉,我无法知道您的名字。
# 4、ConversationTokenBufferMemory()
# 对话token缓存记忆:使用对话token缓存记忆,内存将限制保存的token数量。如果token数量超出指定数目,它会切掉这个对话的早期部分
# 以保留与最近的交流相对应的token数量,但不超过token限制。
# 用法和上面一样
memory = ConversationTokenBufferMemory(llm=chat, max_token_limit=10) # 因为要算token,所以加llm的tokenizer进来切token计算
print(memory.buffer) # 历史对话信息会存在memory.buffer里
#新建一个对话链
conversation = ConversationChain(
llm=chat,
memory = memory,
verbose=False #查看Langchain实际上在做什么,设为FALSE的话只给出回答,看到不到下面绿色的内容
)
# 5、ConversationSummaryBufferMemory()
# 对话摘要缓存记忆:不将内存限制为基于最近对话的固定数量的token或固定数量的对话次数窗口,而是使用LLM编写到目前为止历史对话的摘要,并将其保存。
# 用法和上面一样
memory = ConversationSummaryBufferMemory(llm=chat, max_token_limit=20) # 因为要算token和摘要,所以加llm的tokenizer进来切token计算
print(memory.buffer) # 历史对话信息会存在memory.buffer里
#新建一个对话链
conversation = ConversationChain(
llm=chat,
memory = memory,
verbose=False #查看Langchain实际上在做什么,设为FALSE的话只给出回答,看到不到下面绿色的内容
)
# 瞧一瞧是不是真的对历史对话有摘要功能
memory.save_context({"input": "小白喜欢小黑"}, {"output": "听说好像确实是这样的"})
memory.save_context({"input": "小黑也喜欢小白"}, {"output": "应该是"})
memory.save_context({"input": "他们喜欢小黄"}, {"output": "是的"})
# 也就是将历史对话摘要后转成了SystemMessage
print(memory.load_memory_variables({})['history'])
模型(Models)
Models 一般是大模型供应商提供的大语言模型,是语言模型的接口,是所有应用的核心。langchain为不同的模型作了接口。主要分为三类。
第一类:输入和输出都是字符串。封装在langchain.llms中。可以使用下面的属性获取LLMs列表:
>>> from langchain import llms
>>> llms.__all__
['AI21', 'AlephAlpha', 'AmazonAPIGateway', 'Anthropic', 'Anyscale',
'Arcee', 'Aviary', 'AzureMLOnlineEndpoint', 'AzureOpenAI', 'Banana',
'Baseten', 'Beam', 'Bedrock', 'CTransformers', 'CTranslate2', 'CerebriumAI',
'ChatGLM', 'Clarifai', 'Cohere', 'Databricks', 'DeepInfra', 'DeepSparse',
'EdenAI', 'FakeListLLM', 'Fireworks', 'ForefrontAI', 'GigaChat', 'GPT4All',
'GooglePalm', 'GooseAI', 'GradientLLM', 'HuggingFaceEndpoint', 'HuggingFaceHub',
'HuggingFacePipeline', 'HuggingFaceTextGenInference', 'HumanInputLLM',
'KoboldApiLLM', 'LlamaCpp', 'TextGen', 'ManifestWrapper', 'Minimax',
'MlflowAIGateway', 'Modal', 'MosaicML', 'Nebula', 'NIBittensorLLM', 'NLPCloud',
'Ollama', 'OpenAI', 'OpenAIChat', 'OpenLLM', 'OpenLM', 'PaiEasEndpoint',
'Petals', 'PipelineAI', 'Predibase', 'PredictionGuard', 'PromptLayerOpenAI',
'PromptLayerOpenAIChat', 'OpaquePrompts', 'RWKV', 'Replicate', 'SagemakerEndpoint',
'SelfHostedHuggingFaceLLM', 'SelfHostedPipeline', 'StochasticAI', 'TitanTakeoff',
'TitanTakeoffPro', 'Tongyi', 'VertexAI', 'VertexAIModelGarden', 'VLLM',
'VLLMOpenAI', 'WatsonxLLM', 'Writer', 'OctoAIEndpoint', 'Xinference',
'JavelinAIGateway', 'QianfanLLMEndpoint', 'YandexGPT', 'VolcEngineMaasLLM']
第二类 chat model 聊天模型,虽然它是llm的包装,但它的接口基于消息而不是文本。
还是用.__all__方法可以获取聊天模型列表:
>>> langchain_community.chat_models.__all__
[
"LlamaEdgeChatService",
"ChatOpenAI",
#...
#省略若干行
#...
"ChatYuan2",
"ChatZhipuAI",
]
最后一类是文本嵌入模型(text-embedding-model) 从原理上来看,嵌入模型与以上的两种模型有本质不同。嵌入模型的思路是将字符串组成的空间映射到嵌入空间,这个嵌入空间是一个连续向量空间,且嵌入空间与原本的字符空间是同构的。这样做的目的有两点:
-
嵌入空间可以降维和升维,可以更好的提取语义特征。
-
连续向量空间的数学工具更多,可以更好的应用分类、预测、搜索等算法。比如前文的知识库搜索中用到的向量相似度就是利用连续向量空间中的距离来进行搜索的方法。
知道Embedding模型在知识库中的作用即可:一方面知识库中的文档是以embedding的形式储存在向量库;另一方面是llm模型在检索知识库时是在embedding空间进行的,具体来说是用户的query和向量库进行向量相似度的计算,最终得出结果。
依然可以用
.__all__属性查看供应商提供的所有embedding。
提示(Prompt)
prompt比较好理解,我们与模型对话到得到答案的步骤大体分为三部分:输入-->等待大模型回答-->输出。
所谓prompt提示词,就是通过在输入层对我们向大模型输入的问题进行不断地细分、优化,不断尝试更加标准的过程,是提供给语言模型的自然语言描述,用于指导模型生成期望的输出。
在Langchain作用于创建和管理工作流中的自然语言提示词的功能。在Langchain中,包括定义提示词模板、动态插入变量、以及管理提示词的版本和历史记录等功能。
LangChain 与本地模型部署
使用公共AI服务(如OpenAI的ChatGPT)的主要问题之一是将您的私人数据暴露给提供商的风险。对于商业用途,这仍然是考虑采用AI技术的公司最担心的问题。 很多时候,大家都希望创建自己的语言模型,根据自己公司的数据集(例如销售见解,客户反馈等)进行训练,不希望将所有这些敏感数据暴露给OpenAI等AI提供商。因此,理想的方法是在本地训练自己的LLM(大语言模型),而不需要将数据上传到公网。
LangChain-chatchat, 用官网自己的话来说就是: 基于 Langchain 与 ChatGLM 等大语言模型的本地知识库问答应用实现。 一种利用 langchain 思想实现的基于本地知识库的问答应用,目标期望建立一套对中文场景与开源模型支持友好、可离线运行的知识库问答解决方案。 接下来,我将通过Langchai-chatchat来演示langchain与本地模型部署的一些经验:
部署 LangChain-Chatchat
官网有三种安装方式:
- autoDL
- docker
- 本地部署
第一种其实比较方便和实惠,机器配置不够也可以跑模型,每个小时几块钱,而且都是autoDL有对应的镜像可以直接运行,非常的便捷。
第二种大概有40G的包,部署也算比较方便。
我搞的是第三种本地部署,虽然比较麻烦,但是在自己机器上部署方便调试,也更容易去了解整个项目是怎么运行的,对于学习来说是比较好的。
- 首先根据GitHublangchain-chatchat项目的描述,我们得创建一个合适的虚拟环境,我的本地环境是MacPro M2,Python虚拟环境创建的是3.11
- 接着,激活虚拟环境,并且在本地创建一个命名为langchain-chatchat 的文件夹,在终端中cd 到文件夹中
- 运行 git clone github.com/chatchat-sp… 拉取项目
- cd 进 Langchain-Chatchat 文件夹,安装所有环境依赖 pip install -r requirements.txt pip install -r requirements_api.txt pip install -r requirements_webui.txt
!!!请注意,LangChain-Chatchat 0.2.x 系列是针对 Langchain 0.0.x 系列版本的,如果你使用的是 Langchain 0.1.x 系列版本,需要降级您的Langchain版本。
模型下载:
- cd Langchain-Chatchat
- git lfs install
- git clone huggingface.co/THUDM/chatg…
- git clone huggingface.co/BAAI/bge-la…
初始化知识库和配置文件:
- python3 copy_config_example.py
- python3 init_database.py --recreate-vs
配置文件修改:
配置文件在cd Langchain-Chatchat/configs 中
【basic_config.py、kb_config.py、model_config.py、prompt_config.py、server_config.py 】这些文件都有不同的作用,由于我是用Mac M2来运行的,因此需要修改model_config.py这个文件。具体根据自己的模型需要修改。
一键启动:
- cd 回到 Langchain-Chatchat文件夹
- 运行 python3 startup.py -a
运行成功会出现两个URL,随便复制一个进去浏览器即可。
附录
参考文献与资料链接
官方文档(以 Python 版为例)
- 功能模块:python.langchain.com/docs/get_st…
- API 文档:api.python.langchain.com/en/latest/l…
- 三方组件集成:python.langchain.com/docs/integr…
- 官方应用案例:python.langchain.com/docs/use_ca…
- 调试部署等指导:python.langchain.com/docs/guides…
AI Agent的概念以及工作原理:juejin.cn/post/734936…
star-history数据来源:star-history.com/#langchain-…
chain链详细讲解:juejin.cn/post/731682…
Chain链讲解:t.csdnimg.cn/iZGrK
Memory:t.csdnimg.cn/LJO0D
chatgpt是如何计算token数的,可参考这:www.zhihu.com/question/59…
openai开源的计算token数量的库tiktoken:github.com/openai/tikt…
Langchain基础之models讲解:t.csdnimg.cn/azQOR
Langchain-chatchat本地部署教学:blog.csdn.net/weixin_4472…
