

黑色星期五日志管理清单(使用 Elastic Stack)
对于这个黑色星期五,Sematext祝愿您:
- 更多的产品销售
- 更多的流量和曝光
- 更多的日志 🙂
现在,认真地说,应用程序在黑色星期五 tend to 产生更多的 logs,并且它们也 tend to 更容易崩溃,这使得这些日志更加珍贵。如果您正在使用 Elastic Stack 进行日志管理,在本文中,我们将分享一些技巧和诀窍,为此额外的流量做好准备。
如果您仍然通过 ssh 在日志中进行 grep,则在黑色星期五进行此操作可能会更加繁琐,因此您有两个选择:
- 现在开始使用 Elastic Stack。这里是完整的 ELK 教程。这应该花费您约一个小时的时间就可以开始并继续前进。不要忘记返回此帖子以获取提示! 🙂
- 使用 Sematext Logs,它会为您处理 ELK 的 E(lasticsearch) 和 K(iban)。对于这个季节来说,我们最重要的是负责扩展 Elasticsearch。您可以在 5 分钟内使用 Logstash 开始或选择另一个日志传输程序。有许多可以通过 HTTP 将数据推送到 Elasticsearch 的软件都可以与 Sematext Logs 一起使用,因为它们具有类似的 API。因此,您可以直接从应用程序或日志传输程序记录日志。
无论哪种方式,让我们继续了解诀窍。
关于 Logstash 和 Friends 的贴士
这里的重要问题是:管道是否容易使 Elasticsearch 达到最大值,或者它是否会成为瓶颈?如果您的日志直接从服务器传输到 Elasticsearch,则很少需要担心:随着您为黑色星期五旋转更多的服务器,执行和缓冲处理的管道容量也会增长。
然而,如果您的日志通过一个(或几个) Logstash 实例漏斗,则可能会出现以下情况:
- 批量大小。理想大小取决于您的 Elasticsearch 硬件,但通常您希望一次发送几 MB。庞大的批处理将对 Elasticsearch 施加不必要的压力,而微小的批处理将增加过多的开销。计算出一些(平均大小的)日志的数量,达到几 MB,您就可以做得很好。
- 发送数据的线程数。当一个日志传输程序线程经过批处理回复时,Elasticsearch 不应该处于空闲状态——它应该从另一个线程中获取数据。最佳线程数量取决于这些线程是否执行其他操作(例如在 Logstash 中,管道线程也负责解析,这可能代价高昂),并且取决于您的目标硬件。按照经验法则,每个 Elasticsearch 数据节点需要大约 4 个线程(例如 Logstash 中没有 grok 或 geoip 这样的线程)才能足以保持它们一直忙碌。如果线程有更多处理工作要做,则可能需要更多的线程。
- 处理数据同样适用于批处理工作:许多日志传输程序(包括 Logstash)批处理处理日志,并且可以在多个线程上进行此处理。
- 在所有 Elasticsearch 数据节点之间分布负载。这会防止任何一个数据节点成为热点。在 Logstash 中,指定一个目标主机数组。或者,您可以开始使用 Elasticsearch 只协调节点,并将 Logstash 指向其中两个(用于故障转移)。
- 发送数据到中央 Logstash 服务器的传输程序同样适用——负载需要在它们之间平衡。例如,在 Filebeat 中,您可以指定目标 Logstash 主机的数组(不要忘记将 loadbalance 设置为
true),或者您可以使用 Kafka 作为中央缓冲区。 - 确保有足够的内存用于处理(如果传输程序在内存中缓冲,则还用于缓冲)。对于 Logstash,默认的堆大小可能无法应对重负载,因此您可能需要在其
jvm.options文件中增加堆大小,监视 Logstash 的堆使用情况将确保。 - 如果您使用 grok 并具有多个规则,则将匹配更多日志的规则和更便宜的规则较早地放在数组中。或者使用 Ingest Nodes 代替 Logstash 进行 grok。
关于 Elasticsearch 的贴士
让我们直接进入细节:
- 刷新间隔。还有一篇旧博客文章介绍了 刷新间隔如何影响索引性能。从中得出的结论今天仍然有效:至少对于黑色星期五,您可能希望放松搜索的实时性以获得更多的索引吞吐量。
- 异步事务日志。默认情况下,Elasticsearch 会在请求后
fsync()事务日志。您可以通过设置index.translog.durability为async来放松此耐久性担保。这样,它将每 5 秒进行一次 fsync(默认值为index.translog.sync_interval),并为您节省一些珍贵的 IOPS。 - 基于大小的索引。如果您正在使用严格的基于时间的索引(如每天一个索引),则黑色星期五的流量将使索引更大。这将导致索引吞吐量的下降,如下所示(主要是因为合并而导致):
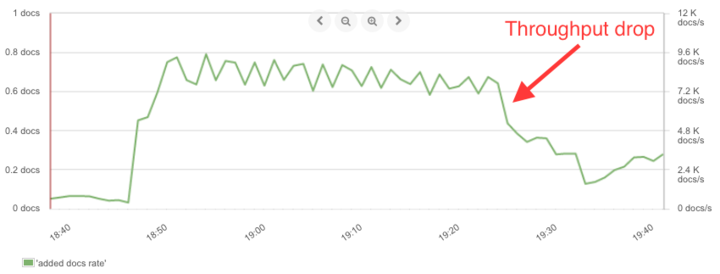
来自 SPM Elasticsearch monitor 的索引吞吐量图
为了以最高速度继续写入,您需要在它们达到“壁纸大小”之前旋转索引,该大小通常为每个分片的 5-10 GB。关键是到达一定的大小时旋转,并始终使用别名来写入最新的索引。使用 ILM 来管理该别名,或通过 Rollover Index API 实现自己的管理。
-
确保负载平衡在数据节点之间分布。否则,一些节点将成为瓶颈。这需要您的分片数与数据节点数成比例——通常是最新索引每个节点一个分片。您可以通过配置
index.routing.allocation.total_shards_per_node来扭曲 Elasticsearch 的手臂来平衡分片:例如,如果您在一个带有 2 个分片和一个副本的 4 数据节点集群上,则将 total_shards_per_node 设置为 1。 -
放松合并策略。这会稍微减慢全文搜索的速度(虽然聚合执行的速度大约相同),使用一些更多的堆和打开文件以允许更多的索引吞吐量。您可以在一些旧的 Elasticsearch 合并策略文档中找到更多细节,但是 50 个
segments_per_tier,20 个max_merge_at_once和 500MB 的max_merged_segment应该可以给您带来良好的提升。 -
不要存储不需要的东西。对于您不搜索的字段,请将
index设置为false,对于不用于聚合的字段,请将doc_values设置为false。在搜索时,请查看特定字段——您可以通过将index.query.default_field设置为message来强制执行该操作,从而使人们不会默认在所有字段中搜索。 -
使用专用主节点。这也是一种稳定性措施,即使负载使您的数据节点不响应,也可以帮助使您的集群保持一致。
在我们的 Velocity 演示文稿 中,您会发现更多的技巧和诀窍,以及关于实施上述操作的更多详细信息。但是以上的这些应该可以给您带来最大的效益(或者说,每个时间段的效益,但您知道人们对时间的评价)。
最后的话
优化和扩展 Elasticsearch 并不是什么难事,但通常需要时间、金钱或两者兼有。因此,如果您不想处理所有这些管道,我们建议将此任务委托给我们,通过使用 Sematext Logs 实现,您将获得:
