PDF.js是Mozilla提供支持的一个通用的、基于web标准的平台,用于解析和呈现PDF的插件。
有些时候文件太大时,需要有切片加载的功能,可以做以下配置,一般情况下是不需要更改什么的。
==最关键的是需要让后端支持分片下载和头部字段返回==
1. 第一步先检查响应头中是否出现Accept-Ranges: bytes (表明服务器支持分片加载)。
2.第二步检查响应头中是否出现=='Access-Control-Expose-Headers':'Accept-Ranges,Content-Range'==是最关键的。因为往往很多后端程序员都忘记了加上这个响应头。而这直接导致了我们任何的设置都是不生效的,实现不了分片加载,因为浏览器默认只允许js读取以下七种如图所示的响应头。而Accept-Ranges头部字段默认是不允许被js读取的,未经过后端设置暴露Accept-Range字段,此时是不能通过js获取到该字段的值,即使这时候已经在浏览器开发工具中看到该接口的响应头中出现了此字段。

配置好后,此时我们应该看到响应头是这样的:
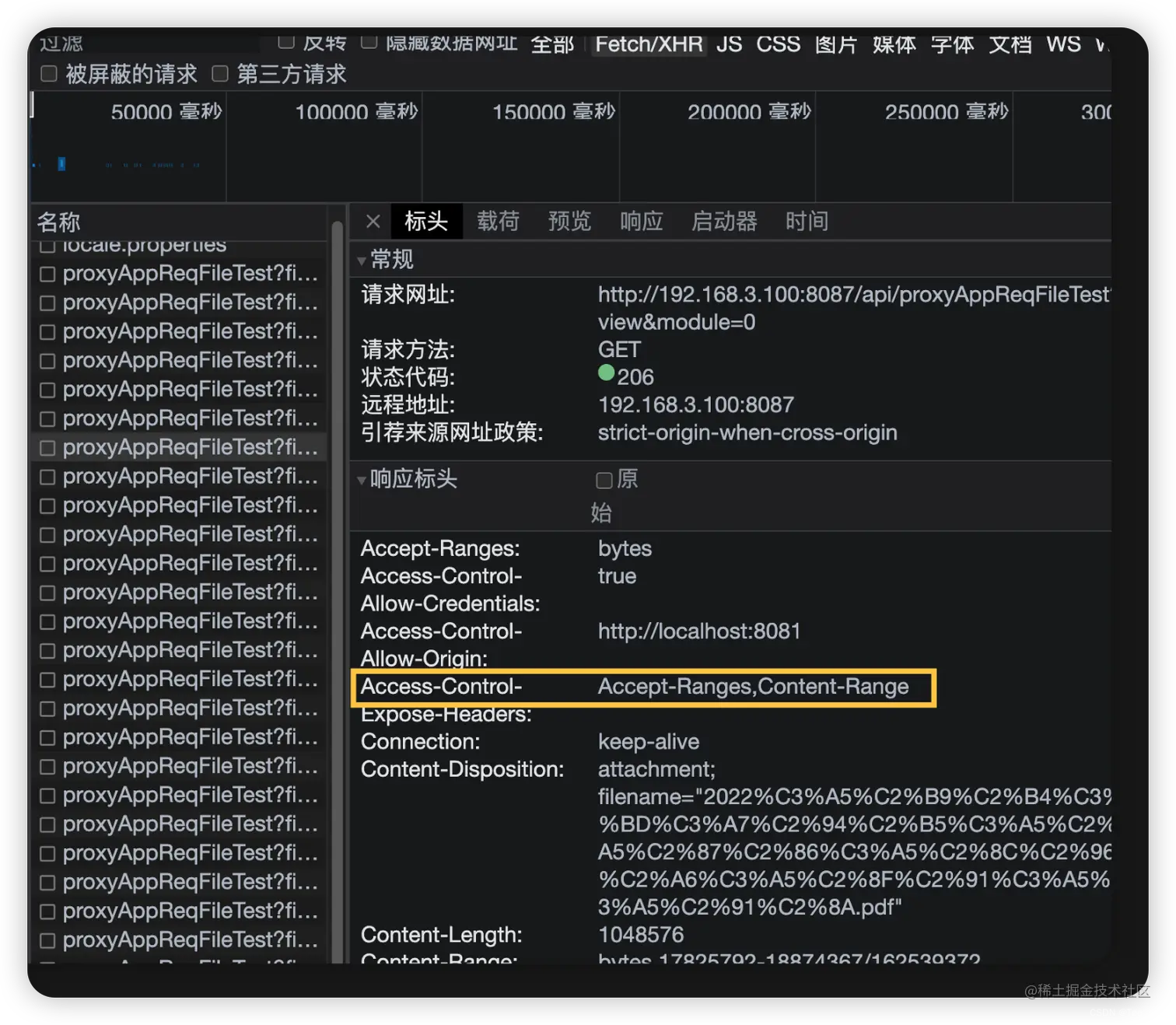
有些时候找了半天找不出原因,往往就是没有暴露头字段。导致没有获取到头字段。再比如导出表格时候需要获取到头字段content-dispositon(内容处置)中的文件名,如果此时后端没有设置=='Access-Control-Expose-Headers':'content-disposition'==。前端通过js也是获取不到的,即使你在响应头字段中确切的看到它已经出现了,只是你获取不到而已。

PDF.js插件中切片配置相关属性如下:
##### 1 "disableAutoFetch": true,
##### 2 "disableFontFace": false,
##### 3 "disableRange": false,
##### 4 "disableStream": true,


