哈希表基本原理
- 数组通过下标访问数据的一种拓展
- 核心:利用哈希函数,将键值映射到数组上(bucket)
Hash Function 哈希函数
- 哈希函数是用来将一个字符串(或任何其他类型)转化为小于哈希表大小且大于等于零的整数
- 一个好的哈希函数:
哈希函数案例
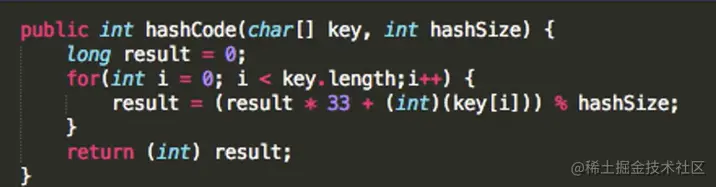
- 一种广泛使用的哈希函数算法是使用数值33(Times 33算法)
hashcode("abcd") = (ascii(a) * 33 ^ 3 + ascii(b) * 33 ^ 2 + ascii(c) * 33 + ascii(d)) % HASH_SIZE
= (97 * 33 ^ 3 + 98 * 33 ^ 2 + 99 * 33 + 100) % HASH_SIZE
= 3595978 % HASH_SIZE
- 其中
HASH_SIZE 表示哈希表的大小
- 给出一个字符串作为key和一个哈希表的大小,返回这个字符串的哈希值
哈希冲突
- 无论使用什么 hash function,都需要考虑冲突问题
- 为啥会有冲突
- 表面原因:有一些key会map到相同的index上
- 本质:无限空间往有限空间映射
如何解决冲突
- 设计好的hash函数
- 改变哈希索引
- Open hashing
- Closed hashing
- 扩容
- 装填因子 Load factor: size/capacity
- Java: LF > 0.75, resize()
闭散列:开放定址法
// 被占用了就往后找
hash = (hash(key) + i) % HASH_SIZE
i = 0, 1, 2, 3 ...
- 插入/查找/删除怎么做?
- 插入:先用hash(key)除以HASH_SIZE,如果冲突了就线性探测找空位
- 查找:第一步同插入,如果发现不是就线性探测往后找
- 删除:第一步同插入,如果发现不是就线性探测往后找,找到后删除并标记为删除
- 二次探测/双重散列
// 二次探测
hash = (hash(key) + i^2) % HASH_SIZE
i = 0, 1, 2, 3 ...
双重散列:hash1冲突了就换hash2
开散列:拉链法
- 每个 bucket 对应一条链表,哈希值相同的元素直接连接在对应链表中
- 链表的头节点存储在哈希表中
- 拉链法的极端情况?
- Java 8:数组 + 链表 + 红黑树
- Java 7:数组 + 链表
扩容:重哈希 rehashing
- 哈希表容量的大小在一开始是不确定的,在需要的时候,可以对底层数组进行扩容
- 一种简单的策略:如果哈希表存储元素太多,将哈希表容量扩大一倍,并将所有的key的哈希值重新计算映射到新的bucket上
动手实现HashMap
属性
private static final int DEFAULT_INIT_CAPACITY = 16;
private static final float DEFAULT_LOAD_FACTOR = 0.75f;
class Node<K, V> {
K key;
V value;
Node<K, V> next;
public Node(K key, V value, Node<K, V> next) {
this.key = key;
this.value = value;
this.next = next;
}
}
private int initCapacity;
private float loadFactor;
private int size;
private Node<K, V>[] table;
构造器
public MyHashMap(){
this(DEFAULT_INIT_CAPACITY, DEFAULT_LOAD_FACTOR);
}
public MyHashMap(int initCapacity, float loadFactor) {
this.initCapacity = initCapacity;
this.loadFactor = loadFactor;
}
哈希函数
private int hash(K key) {
return key.hashCode() % this.table.length;
}
解决哈希冲突
装填因子(扩容)
private void resize(int newCapacity) {
System.out.println("Resizing: " + this.initCapacity);
Node[] newTable = new Node[newCapacity];
this.initCapacity = newCapacity;
System.out.println("Resizing: " + this.initCapacity);
for (Node<K, V> node : table) {
while (node != null) {
int index = hash(node.getKey());
Node<K, V> newNode = new Node<>(node.getKey(), node.getValue(), null);
if (newTable[index] != null) {
Node<K, V> head = newTable[index];
while (head.getNext() != null) {
head = head.getNext();
}
head.setNext(newNode);
} else {
newTable[index] = newNode;
}
node = node.getNext();
}
this.table = newTable;
}
}
方法实现
/**
* Put key-value entry into my hash map.
* @param key specific key。
* @param value value
* @return null if add new entry, old value if key exists(update)
*/
public V put(K key, V value) {
int index = hash(key)
// 看这个下标节点有没有东西
Node<K, V> node = table[index]
// 哈希桶为空,直接插入新节点
if (node == null) {
this.table[index] = new Node<>(key, value, null)
return null
}
// 哈希桶不为空,两种情况:1. key存在,更新value 2. key不存在,新增key-value
while (node != null) {
if (node.key == key) {
V oldValue = node.value
node.value = value
return oldValue
}
if (node.getNext() == null) {
node.setNext(new Node<>(key, value, null))
return null
}
node = node.next
}
table[index] = new Node<>(key, value, null)
return null
}
private int hash(K key) {
return key.hashCode() % this.table.length
}
/**
* Get related value by specific key.
* @param key specific key.
* @return null if key not exists, otherwise, return value with the specific key.
*/
public V get(K key) {
// 确定哈希桶:key -> index
int index = hash(key)
Node<K, V> node = table[index]
while (node != null) {
if (node.getKey() == key) {
return node.getValue()
}
node = node.getNext()
}
return null
}
/**
* Remove related value by specific key.
* @param key specific key
* @return null if key not exists, otherwise, return the value to be removed with the specific key.
*/
public V remove(K key) {
// 确定哈希桶:key -> value
int index = hash(key)
Node<K, V> node = table[index]
// 针对于链表头节点的逻辑
if (node == null) {
return null
}
if (node.getKey() == key) {
// 1. 保存被删掉node的next
Node<K, V> temp = node.getNext()
// 2. node的next节点设置为null
node.setNext(null)
table[index] = temp
return node.getValue()
}
Node<K, V> preNode = node
Node<K, V> curNode = node.getNext()
// 针对于非头节点的逻辑
while (curNode != null) {
if (curNode.getKey() == key) {
preNode.setNext(curNode.getNext())
curNode.setNext(null)
return curNode.getValue()
}
preNode = curNode
curNode = curNode.getNext()
}
return null
}


