

动动发财的小手,点个赞吧!
在使用 R-CNN 的目标检测中,RPN 是真正的主干,并且到目前为止已被证明非常有效。它的目的是提出在特定图像中可识别的多个对象。
这种方法是由 Shaoqing Ren、Kaiming He、Ross Girshick 和 Jian Sun 在一篇非常受欢迎的论文“Faster R-CNN:Towards Real Time Object Detection with Region Proposal Networks”中提出的。这是一个非常流行的算法,引起了很多数据科学家、深度学习和人工智能工程师的关注。它具有巨大的应用,例如检测自动驾驶汽车中的物体,协助不同能力的人并帮助他们等。
1. 什么是CNN ?
CNN 翻译成卷积神经网络,这是一种非常流行的图像分类算法,通常由卷积层、激活函数层、池化(主要是 max_pooling)层组成,以在不丢失大量特征的情况下降低维度。对于这篇文章,你应该知道有一个特征图是由最后一层卷积层生成的。
例如,如果您输入猫图像或狗图像,算法可以告诉您它是狗还是猫。
但它并不止于此,强大的计算能力带来了巨大的进步。
许多预训练模型被开发为直接使用它们,而无需经历由于计算限制而训练模型的痛苦。许多模型也很受欢迎,例如 VGG-16、ResNet 50、DeepNet、ImageNet 的 AlexNet。
对于这篇特别的文章,我特别想谈谈我认为从上述论文中得出的非常聪明的算法或想法。许多人实施 Faster R-CNN 来识别对象,但该算法专门研究了算法如何在已识别对象周围获取框背后的逻辑和数学。
该算法的开发者将其称为 Region Proposal Networks,缩写为 RPN。
为了为对象所在的区域生成这些所谓的“建议”,一个小型网络在卷积特征图上滑动,该特征图是最后一个卷积层的输出。
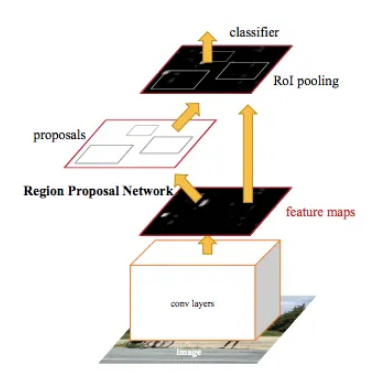
以上是 Faster R-CNN 的架构。 RPN 为对象生成建议。 RPN 本身具有专门且独特的架构。我想进一步分解RPN架构。
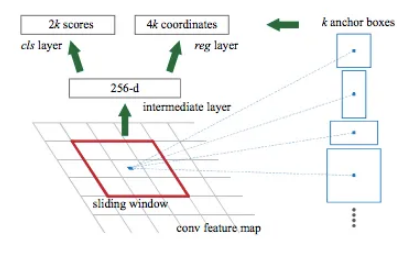
RPN 有一个分类器和一个回归器。作者引入了锚点的概念。 Anchor 是滑动窗口的中心点。对于作为 AlexNet 扩展的 ZF 模型,尺寸为 256-d,对于 VGG-16,尺寸为 512-d。分类器确定具有目标对象的提议的概率。回归对提案的坐标进行回归。对于任何图像,比例和纵横比都是两个重要参数。不知道的朋友,纵横比=图片的宽度/图片的高度,scale就是图片的大小。开发人员选择了 3 种比例和 3 种纵横比。因此,每个像素总共可能有 9 个建议,这就是 k 值的决定方式,对于这种情况,K=9,k 是锚点的数量。对于整个图像,anchors 的数量是 WHK。
该算法对平移具有鲁棒性,因此该算法的关键属性之一是平移不变性。
算法中多尺度锚点的存在导致“锚点金字塔”而不是“过滤器金字塔”,这使得它比以前提出的算法(如 Multi-Box)更省时且更具成本效益。
2. 它是如何工作的 ?
这些锚点根据两个因素分配标签:
- Intersection-over-union 最高的锚点与地面实况框重叠。
- Intersection-Over-Union Overlap 高于 0.7 的锚点。
归根结底,RPN 是一种需要训练的算法。所以我们肯定有我们的损失函数。
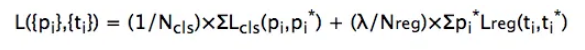
i → anchor 的索引,p → 是否是物体的概率,t → 预测边界框的4个参数化坐标的向量,*表示ground truth box。 cls 的 L 表示两个类的对数损失。
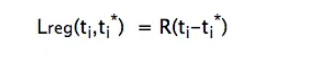
损失函数中带有回归项的p确保当且仅当对象被识别为是时,则只有回归才算数,否则p将为零,因此损失函数中的回归项将变为零。
Ncls 和 Nreg 是归一化。默认情况下,λ 默认为 10,用于在同一级别上缩放分类器和回归器。
如果您想更详细地了解,这里是论文的链接:arxiv.org/pdf/1506.01…
本文由mdnice多平台发布
