一、概述
对于无向图模型,我们可以回忆一下它的基于最大团的因子分解(Hammersley–Clifford theorem)。给定概率无向图模型,Ci,i=1,2,⋯,k为无向图模型上的最大团,则x的联合概率分布P(x)可以写为:
P(x)=Z1i=1∏kψ(xCi)Ci:最大团xCi:最大团随机变量集合ψ(xCi):势函数,必须为正Z=x∑i=1∏kψ(xCi)=x1∑x2∑⋯xp∑i=1∏kψ(xCi)
对于势函数(Potential Function),通常使用ψ(xCi)=exp{−E(xCi)},这里的E叫做能量函数(Energy Function),当使用这个势函数时,就有:
P(x)=Z1i=1∏kψ(xCi)=Z1exp{−i=1∑kE(xCi)}=Z1exp{−E(x)}
这个分布就叫做吉布斯分布(Gibbs Distribution),或者玻尔兹曼分布(Boltzmann Distribution)。
对于P(x)=Z1exp{−∑i=1kE(xCi)}的形式,可以看出这是一个指数族分布。
对于玻尔兹曼分布P(x)=Z1exp{−E(x)},这个概念最初来自统计物理学,一个物理系统中存在各种各样的粒子,而E代表系统的能量,一个物理系统有多种不同的状态,状态的概率为:
P(state)∝exp{−k⋅TE}
其中k是玻尔兹曼常数(总之就是个常数),T是系统温度,可以看出P(state)和能量函数成反比,也就是说系统的能量越大,对应的状态的概率越小,系统越不容易停留在这个状态而倾向于向低能量的稳定状态转移。
参考链接:概率图模型
二、表示
玻尔兹曼机(Boltzmann Machine,BM)是一种存在隐节点的无向图模型,它的每个节点对应一个随机变量,分为观测变量和隐变量两种。下图中的概率图就表示了一个玻尔兹曼机,其中阴影部分对应观测变量:
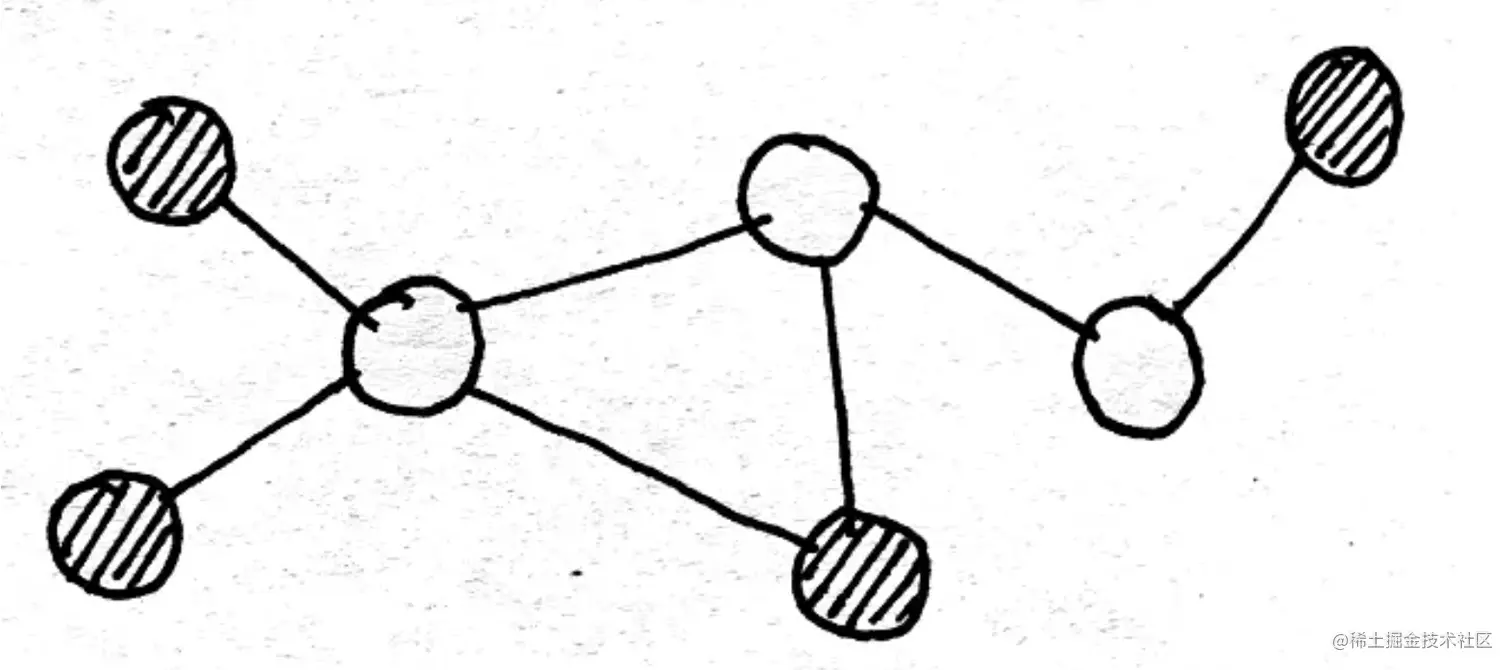
一个玻尔兹曼机的随机变量我们用向量x来表示,x中包含隐变量和观测变量,隐变量用h表示,观测变量用v表示,具体的:
x=⎝⎛x1x2⋮xp⎠⎞=(hv)h=⎝⎛h1h2⋮hm⎠⎞v=⎝⎛v1v2⋮vn⎠⎞p=m+n
玻尔兹曼机的问题在于它的推断问题很难解决,其中精确推断的方法是untrackable的,而近似推断的方法计算量太大,因此我们势必需要对模型进行一些简化,也就有了受限玻尔兹曼机(Restricted Boltzmann Machine,RBM)。
在受限玻尔兹曼机中,连接只存在于隐变量与观测变量之间,而隐变量与观测变量内部是无连接的,因此也就得到了一个两层的结构:
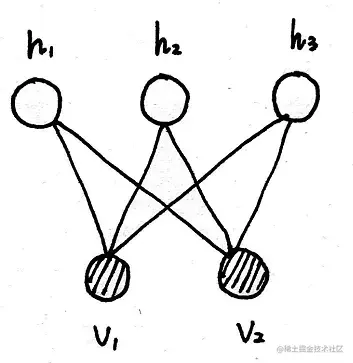
受限玻尔兹曼机的概率公式为:
P(x)=Z1exp{−E(x)}
也就是:
P(v,h)=Z1exp{−E(v,h)}
对于能量函数,在受限玻尔兹曼机中采用以下形式来表示,其中参数是W,α,β:
E(v,h)=−(hTWv+αTv+βTh)
因此概率P(v,h)也就可以写成:
P(v,h)=Z1exp{−E(v,h)}=Z1exp{hTWv+αTv+βTh}=Z1exp{hTWv}exp{αTv}exp{βTh}=Z1edgei=1∏mj=1∏nexp{hiwijvj}nodevj=1∏nexp{αjvj}nodehi=1∏mexp{βihi}
上面这个式子也和受限玻尔兹曼机的因子图一一对应:
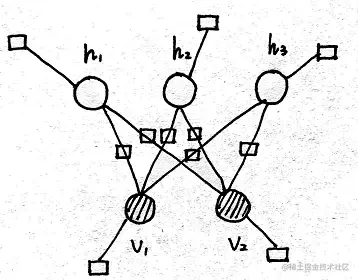
有关因子图的参考链接:概率图模型
受限玻尔兹曼机的参数估计这一篇就不具体介绍了,会在后面配分函数那一篇介绍,下面只推导一下受限玻尔兹曼机的推断问题。
三、推断
- 后验概率
后验概率包括P(h∣v)、P(v∣h),对于一个无向图,满足局部Markov性质,即:
P(hl∣h−l,v)=P(hl∣Neighbour(hl))=P(hl∣v)
也就是在给定v的条件下,h的各个分量之间是条件独立的,对于概率P(h∣v)也就可以改写成:
P(h∣v)=l=1∑mP(hl∣v)
最初的RBM被用来设计解决二值问题,因此这里我们考虑Binary RBM,也就是h和v的随机变量都是二值的。推断问题是在模型的参数已经得出的前提下进行的,也就是说联合概率P(v,h)已经得出,对于后验概率P(h∣v)的求解,我们希望能够凑出联合概率的形式,考虑概率P(hl=1∣v):
P(hl=1∣v)=P(hl=1∣h−l,v)=P(h−l,v)P(hl=1,h−l,v)=P(hl=1,h−l,v)+P(hl=0,h−l,v)P(hl=1,h−l,v)
对于联合概率P(v,h),在给定hl时,我们可以尝试把P(v,h)拆成与hl相关和不相关的两个部分:
E(h,v)=−(i=1∑mj=1∑nhiwijvj+j=1∑nαjvj+i=1∑mβihi)=−⎝⎛Δ1i=1,i=l∑mj=1∑nhiwijvj+Δ2hlj=1∑nwljvj+Δ3j=1∑nαjvj+Δ4i=1,i=l∑mβihi+Δ5βlhl⎠⎞
最终得到E(h,v)的以下形式:
Δ2+Δ5=hl(j=1∑nwljvj+βl)=hl⋅Hl(v)Δ1+Δ3+Δ4=H^l(h−l,v)∴E(h,v)=hl⋅Hl(v)+H^l(h−l,v)
因此对于P(hl=1∣v)的分子和分母分别有:
分子=Z1exp{Hl(v)+H^l(h−l,v)}分母=Z1exp{Hl(v)+H^l(h−l,v)}+Z1exp{H^l(h−l,v)}
最终得到概率P(hl=1∣v),发现这个概率其实是关于Hl(v)的sigmoid函数:
P(hl=1∣v)=Z1exp{Hl(v)+H^l(h−l,v)}+Z1exp{H^l(h−l,v)}Z1exp{Hl(v)+H^l(h−l,v)}=1+exp{H^l(h−l,v)−Hl(v)−H^l(h−l,v)}1=1+exp{−Hl(v)}1=σ(Hl(v))=σ(j=1∑nwljvj+βl)
类似地也可以得到P(hl=0∣v),求得P(hl∣v),也就求得了后验概率P(h∣v),求解P(v∣h)的过程与求解P(h∣v)的过程是完全对称的,这里就不再赘述。
- 边缘概率
首先将权重矩阵W写成行向量的形式,注意这里的wi是行向量:
W=[wij]m×n=⎝⎛w1w2⋮wm⎠⎞
为了求解边缘概率P(v),我们只需要将h积分掉:
P(v)=h∑P(h,v)=h∑Z1exp{−E(v,h)}=h∑Z1exp{hTWv+αTv+βTh}=Z1h1∑h2∑⋯hm∑exp⎩⎨⎧与h有关hTWv+与h无关αTv+与h有关βTh⎭⎬⎫=Z1exp{αTv}h1∑h2∑⋯hm∑exp{hTWv+βTh}=Z1exp{αTv}h1∑h2∑⋯hm∑exp{i=1∑m(hiwiv+βihi)}=Z1exp{αTv}h1∑h2∑⋯hm∑exp{h1w1v+β1h1}exp{h2w2v+β2h2}⋯exp{hmwmv+βmhm}=Z1exp{αTv}h1∑exp{h1w1v+β1h1}h2∑exp{h2w2v+β2h2}⋯hm∑exp{hmwmv+βmhm}=Z1exp{αTv}(1+exp{w1v+β1})(1+exp{w2v+β2})⋯(1+exp{wmv+βm})
至此这个概率也就求出来了,不过我们还可以进行进一步的变换以发现一些其他的结论:
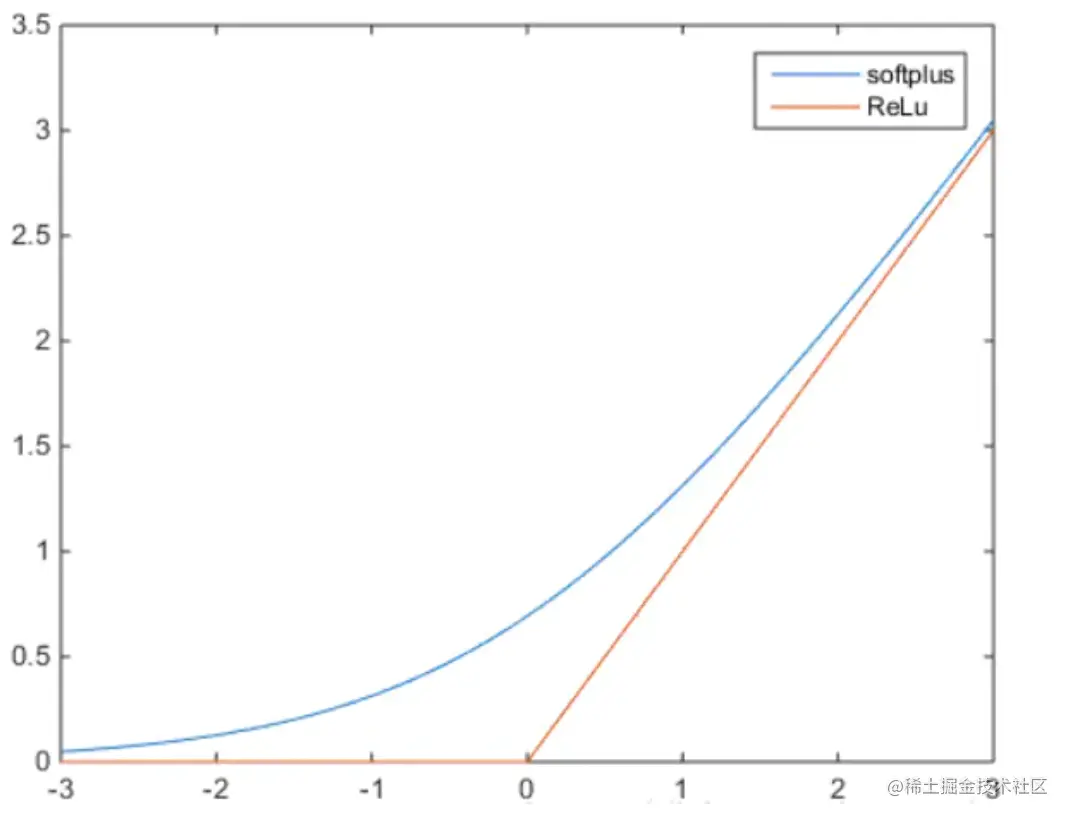
P(v)=Z1exp{αTv}(1+exp{w1v+β1})(1+exp{w2v+β2})⋯(1+exp{wmv+βm})=Z1exp{αTv}exp{log(1+exp{w1v+β1})}exp{log(1+exp{w2v+β2})}⋯exp{log(1+exp{wmv+βm})}=Z1exp{αTv+i=1∑mlog(1+exp{wiv+βi})}
这里的log(1+ex)就是softplus函数,它的图像与Relu函数对比如下:
四、总结
受限玻尔兹曼机是由一个可见层和一个隐藏层组成的双层神经网络。它们之间的节点是全连接的,但同一层的节点之间没有连接。
RBM的学习过程包括两个阶段:训练阶段和抽样阶段。
-
训练阶段:
- 初始化可见层和隐藏层的权重矩阵和偏置向量。
- 对于每个训练样本,通过正向传播计算隐藏层的激活,并通过反向传播更新权重和偏置,使得重构样本与原始样本的误差最小化。
- 重复上述步骤,直到达到收敛条件。
-
抽样阶段:
- 给定一个可见层的样本,通过正向传播计算隐藏层的激活概率。
- 根据隐藏层的激活状态,通过反向传播计算可见层的重构样本。
- 重复上述步骤,可以生成新的样本。
RBM的特点和应用:
- RBM是一种无监督学习算法,不需要标注数据进行训练。
- 它可以用于特征学习,通过学习隐含特征的表示,可以在后续任务中提取更有意义的特征。
- RBM也可以用于降维,通过训练一个具有较少隐藏节点的RBM,可以将高维数据映射到低维空间。
- 受限玻尔兹曼机还可以应用于协同过滤任务,如推荐系统,通过学习用户和物品之间的相关性,为用户提供个性化的推荐。
受限玻尔兹曼机也存在一些挑战和限制:
- 训练过程中的收敛速度通常较慢,尤其是在大规模数据和复杂网络结构的情况下。
- 在训练过程中,需要采样和计算概率分布,这可能会导致计算成本较高。
- 受限玻尔兹曼机对于数据的分布假设较为简单,可能无法捕捉到复杂的数据结构和高阶关系。
总结而言,受限玻尔兹曼机是一种重要的无监督学习模型,用于学习数据的概率分布和隐含特征的表示。它在特征学习、降维和协同过滤等任务中发挥重要作用。
此模型之后提出了一些改进和扩展的模型,如深度信念网络(Deep Belief Networks,DBN)、变分自编码器(Variational Autoencoders,VAE)和生成对抗网络(Generative Adversarial Networks,GAN)。这些模型在受限玻尔兹曼机的基础上进行了扩展,提供了更强大和灵活的建模能力。


