单表访问方法
- 前面几节我们了解 innodb 的底层数据结构的设计,究其本源我们其实是为了更好的理解如何查询,并且如何使得查询语句更加快速的问题,这节我们就来好好讲一讲
- 首先我们先来创建一个表
CREATE TABLE index_value_table (
id INT NOT NULL AUTO_INCREMENT,
value1 VARCHAR(100),
value2 INT,
value3 VARCHAR(100),
value_part1 VARCHAR(100),
value_part2 VARCHAR(100),
value_part3 VARCHAR(100),
common_field VARCHAR(100),
PRIMARY KEY (id),
KEY idx_key1 (value1),
UNIQUE KEY idx_key2 (value2),
KEY idx_key3 (value3),
KEY idx_key_part(value_part1, value_part2, value_part3)
) Engine=InnoDB CHARSET=utf8;
- 讲一下这个表
- id 列创建了聚簇索引
- value1 列创建了idx_key1 二级索引
- value2 列创建了idx_key2 二级索引,且唯一
- value3 列创建了idx_key3 二级索引
- value_part1,value_part2,value_part3 列创建了idx_key_part 二级索引 是一个联合索引
- 现在假设这张表里面插入了100000条数据
访问方法的概念
- 我们通常把执行查询语句的方式称之为访问方法
- 我们查询执行的方案主要是有两种分类:
- 使用全表扫描进行查询
- 使用索引进行查询:使用索引进行查询也会有各种方式,具体我们可以分为
- 针对主键或唯一二级索引的等值查询 Const
- 针对普通二级索引的等值查询 ref
- 针对索引列的范围查询 range
- 直接扫描整个索引 index
- 下面我具体来说明这几个访问方法
Const:针对主键或唯一二级索引的等值查询
- 我们通常认为 通过主键和唯一二级索引列 与 常数的等值比较来定位一条记录是非常快的,所以我们也称这种访问方法为 Const,常数级别的。
- 举个例子,看这个语句:
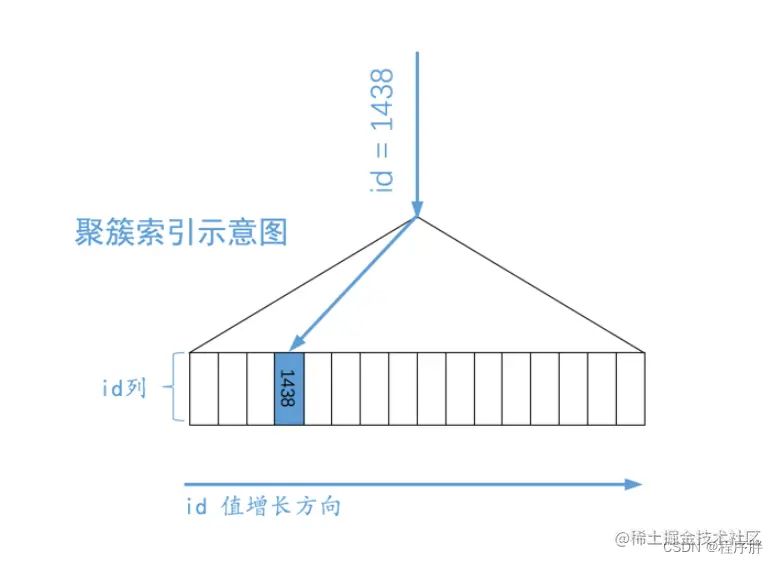
SELECT * FROM index_value_table WHERE id = 1438;
- 因为条件筛选是聚簇索引,我们知道底层是B+树,B+树叶子节点中的记录是按照索引列排序的,我可以通过二分查找快速的找到对应的ID列的记录,并且找到的时候刚好是叶子节点,所以可以快速地把记录拉出来,执行过程图:
- 在举一个二级索引的例子,看这条语句
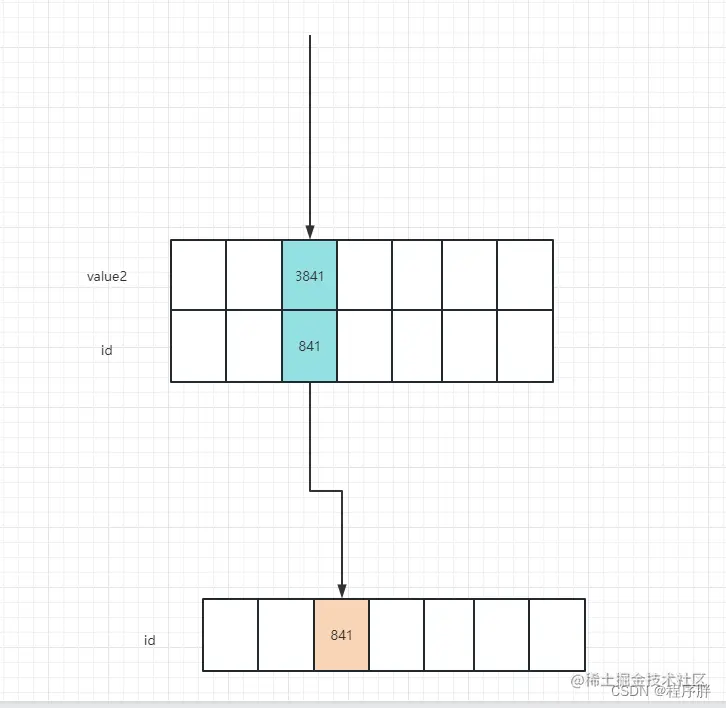
SELECT * FROM index_value_table WHERE value2 = 3841;
- 二级索引跟聚簇索引的差别是,多一层查询,我们需要先二分查找,找到对应的值和他的主键,再通过主键去聚簇索引的B+树中找到对应的数据,所以应该也是很快,执行图如下:
Ref:针对普通二级索引的等值查询
- 因为聚簇索引和唯一的二级索引的等值查询,查询到的记录只会有一条,但是普通的二级索引可能会有很多条,所以当我们找那些等值索引的主键时,我们会回表的消耗会比唯一的二级索引消耗大,但是跟全表搜索比性能还是要高很多的,所以我们通常把这种搜索条件为二级索引列与常数等值比较,采用二级索引来执行查询的访问方法称为:ref
- 举个例子:
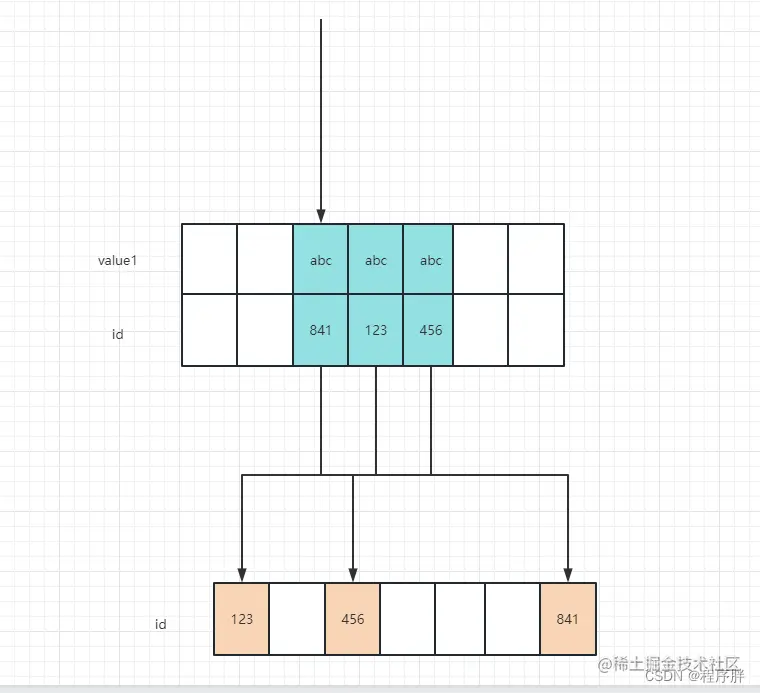
SELECT * FROM index_value_table WHERE value1 = 'abc';
- 这个查询的查询过程:
- 先从idx_key1 的索引树用二分查找定位到value1 中为abc 的记录,因为时连续的,然后找到这些记录对应的主键值
- 从聚簇索引树中,通过这些主键定位到完整的记录
- 但这种还是会有一些特殊情况:
- 二级索引存在NULL的情况:不论是普通的二级索引,还是唯一二级索引,它们的索引列对包含NULL值的数量并不限制,所以我们采用key IS NULL这种形式的搜索条件最多只能使用ref的访问方法,而不是const的访问方法。
- 对于某个包含多个索引列的二级索引来说,只要是最左边的连续索引列是与常数的等值比较就可能采用ref的访问方法,比如下面几个
SELECT * FROM index_value_table WHERE key_part1 = 'abc';SELECT * FROM index_value_table WHERE key_part1 = 'abc' AND key_part2 = 'def';SELECT * FROM index_value_table WHERE key_part1 = 'abc' AND key_part2 = 'def' AND key_part3 = 'ghi';
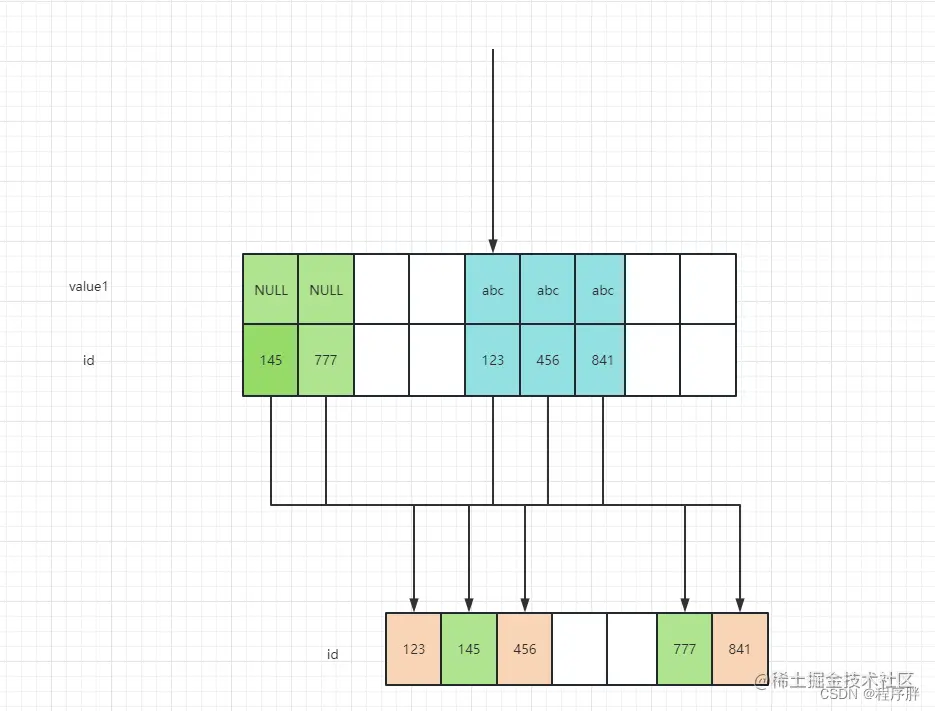
- 不仅想找出某个二级索引列的值等于某个常数的记录,还想把该列的值为NULL的记录也找出来,sql如下:
SELECT * FROM index_value_table WHERE value1 = 'abc' OR value1 IS NULL;,这种时候的访问方法也是ref,但有点特殊叫 ref_or_null ,执行过程如下:
- 先从idx_key1 的索引树用二分查找定位到value1 中为abc 和 value1 是 null 的记录,然后找到这些记录对应的主键值
- 从聚簇索引树中,通过这些主键定位到完整的记录
Range:针对索引列的范围查询
- 我们查询当然不止是等值查询,还会有范围查询,当我们是范围查询这种更加复杂的搜索条件的时候怎么办呢?
- 举个例子:
SELECT * FROM index_value_table WHERE value2 IN (1438, 6328) OR (value2 >= 38 AND value2 <= 79);
- 这种情况我们查询可以有两种,一个是全表查询,一个是通过二级索引+回表的方式执行,当然是采用第二个啦,我们来看看如何查询
- 因为条件复杂,所以这个时候不再是简单的等值查询,而是通过value2列的值匹配下面三个范围中任何一个算在内
- 值等于 1438
- 值等于 6328
- 值在 38 和 79 之间
- 然后通过遍历索引树找到对应的主键进行回表
- 这种通过范围查询的访问方法称之为 range
Index:直接扫描整个索引
- 这个访问方法通过例子来说明比较简单,看下面的sql
SELECT value_part1, value_part2, value_part3 FROM index_value_table WHERE value_part2 = 'abc';
- 这个查询有一个问题,就是搜索条件不符合最左匹配原则,所以无法触发ref 和 range 访问,那他会不会触发索引查询呢?
- 答案是会,主要有两个原因
- 查询字段里面只有三个列,这三个列还都是联合索引 idx_key_part 中的字段
- 搜索条件的value_part2 也是这个联合索引的字段
- 索引我们可以直接通过遍历 idx_key_part 这个索引树来获取数据,这肯定比全表查询要快,而我们通常把这种遍历二级索引树的执行方法称之为 index
All:全表查询


