

现在每个人都在谈论ChatGPT。这个异常聪明的人工智能甚至在发布几个月后仍然让互联网眼花缭乱。在网站上提供ChatGPT是了不起的,然而,当你获得API访问权时,真正的乐趣才开始。这给了你一个很好的机会,将智能人工智能整合到你的项目和应用程序中,使它们更加强大,并引入惊人的功能。

本文为你带来一份指南,介绍如何使用OpenAI的Python库,创建你自己的Telegram机器人并将ChatGPT与之整合。这听起来可能是最简单的事情,但让我们通过介绍summaryize命令来给事情加点料,让你得到聊天中几个帖子的摘要。
这个帖子假定你有Python的基本知识。然而,我建议查看Hyperskill的Python和Flask轨道,以了解更多关于Python和用Flask开发Web应用程序的知识。
设置好一切
在直接进入代码之前,你需要做一些准备工作,以获得所有需要的访问权限。
- 在Telegram中注册你的机器人,并取回Telegram的访问令牌(使用Telegram中的@BotFather)。
- 获得对Telegram核心API的访问权,并检索
api_hash和app_id。 - 注册OpenAI并检索API访问令牌。
保存这些秘密字符串,用你的生命保护它们。任何陌生人都不应该获取它们:这可能会导致违反安全规定。
编写骨架
注意:完整的最终项目代码(分为几个阶段并有提交)可以在我的GitHub上找到,详情请参考这里:https://github.com/yellalena/telegram-gpt-summarizer
本步骤需要安装的Python库:flask、pydantic、requests和pyngrok。
让我们开始编写非常基本的Telegram机器人的代码。它应该从聊天中接收信息,并能够对它们作出回应。
第一件事是--为你的项目创建一个目录,并初始化一个Python虚拟环境。顺便说一下,如果你使用PyCharm,它将为你创建一个虚拟环境。

在这个阶段,目标被分成四个部分:
- 创建一个简单的Flask应用,有一个根路径来处理带有Telegram消息的webhook。
- 为Telegram机器人创建一个类,使其能够向聊天室发送消息。
- 使该应用程序在大互联网上可见。
- 在Telegram中注册应用地址。
这就是main.py在这一点上的样子:
app = Flask(__name__)@app.route('/', methods=["GET", "POST"])def handle_webhook(): update = Update(**request.json) chat_id = update.message.chat.id response = f"This is a response for message: {update.message.text}" app.bot.send_message(chat_id, response) return "OK", 200def run_ngrok(port=8000): http_tunnel = ngrok.connect(port) return http_tunnel.public_urldef main(): app.bot = TelegramBot(Config.TELEGRAM_TOKEN) host = run_ngrok(Config.PORT) app.bot.set_webhook(host) app.run(port=Config.PORT, debug=True, use_reloader=False)if __name__ == "__main__": main()
有几件事需要澄清:
- 我喜欢把所有配置的东西放在一个地方,所以我创建了config.py文件,它将收集和存储我们的令牌和其他来自导出的环境变量的有用信息。
- Telegram以嵌套的JSON形式发送更新,所以让我们创建一组pydantic模型来解析输入,以便以后更加方便。
- 为了将应用程序暴露在网络上,我使用ngrok。它使你的本地主机的特定端口对其他人可见,给它一个临时的公共地址。这就是为什么要确保你所暴露的端口与你运行Flask应用的端口相同。
- 最后,我初始化了机器人,并为ngrok的公共URL设置了一个webhook,这样机器人就知道它在收到任何消息时都必须与这个URL通信。
要设置webhook,你需要向你的机器人的telegram API地址发送一个请求,用你获得的秘密令牌建立。telegram机器人的代码看起来如下:
import requestsfrom config import Configclass TelegramBot: def __init__(self, token): self.token = token self.bot_api_url = f"{Config.TELEGRAM_API}/bot{self.token}" def set_webhook(self, host): host = host.replace("http", "https") set_webhook_url = f"{self.bot_api_url}/setWebhook?url={host}" response = requests.get(set_webhook_url) response.raise_for_status() def send_message(self, chat_id, message): send_message_url = f"{self.bot_api_url}/sendMessage" response = requests.post(send_message_url, json={"chat_id": chat_id, "text": message}) response.raise_for_status()
现在一切都准备好了(别忘了我省略了一些基本代码,你可以在repo中找到它),在环境变量中导出你的机器人令牌,然后点击 "运行"!这时,你就会发现,你的机器人已经开始运行了!
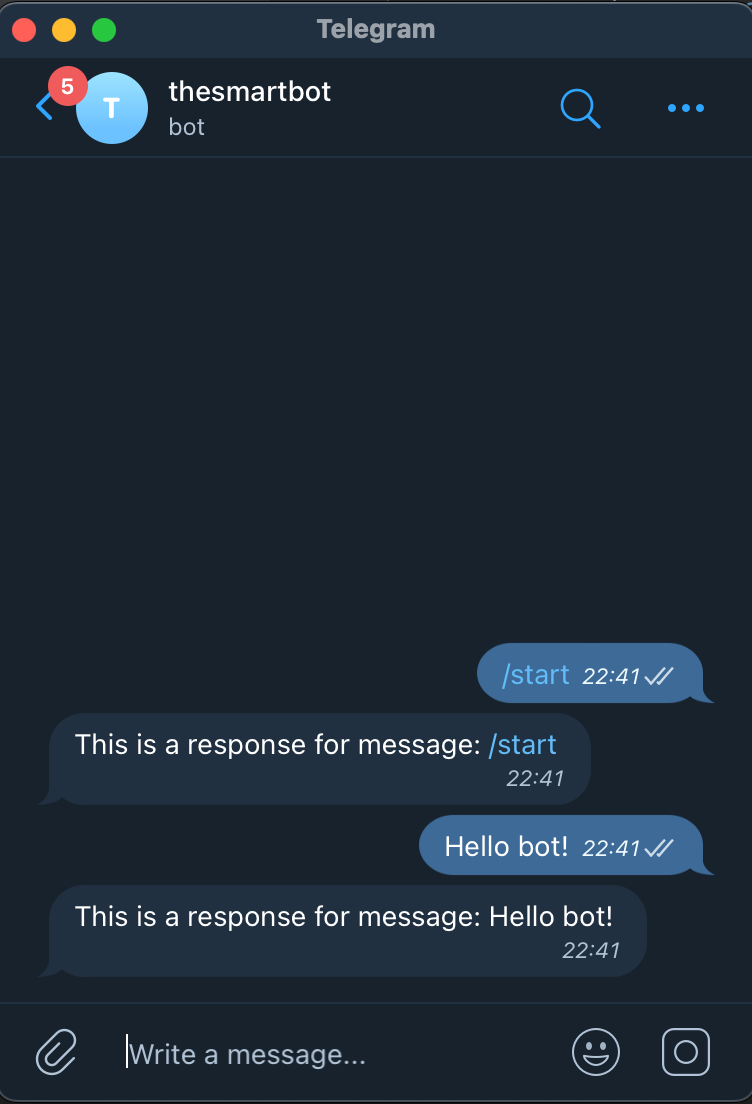
耶!它是活的!
添加一个大脑
令人惊讶的是,现在的下一步应该是为我们的智能机器人添加一撮智能。使用pip安装OpenAI的官方Python库:pip install openai.
之后,我们就可以创建一个辅助类来与人工智能沟通。
import openaiclass OpenAiHelper: def __init__(self, token, model="gpt-3.5-turbo"): openai.api_key = token self.model = model def get_response(self, message_text): response = openai.ChatCompletion.create(model=self.model, messages=[{"role": "user", "content": message_text}]) return response.choices[0].message.content
API为你的项目推荐了各种模型。当然,最受欢迎的是GPTs。GPT-4是最近闹得最凶的一个,但是(也正因为如此)它现在的访问量有限,所以为了方便测试,我选择了GPT-3。没有什么大不了的,你总是可以选择你最喜欢的哪一个,只要改变你传递给帮助器的字符串名称即可。
不要忘记在配置中添加OPENAI_TOKEN 属性,让我们在代码中使用帮助器。
首先,当然是在main() 方法中实例化它:
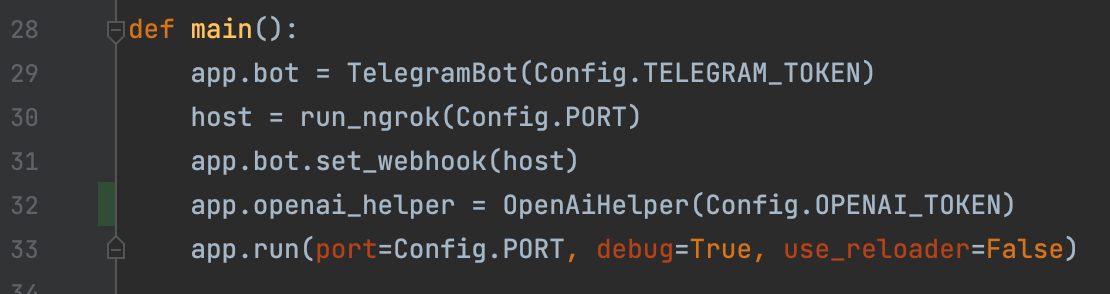
在main()中初始化OpenAI帮助器
然后从视图函数中调用这个家伙,就像这样:
response = app.openai_helper.get_response(update.message.text)
Whoosh!魔法正在发生!
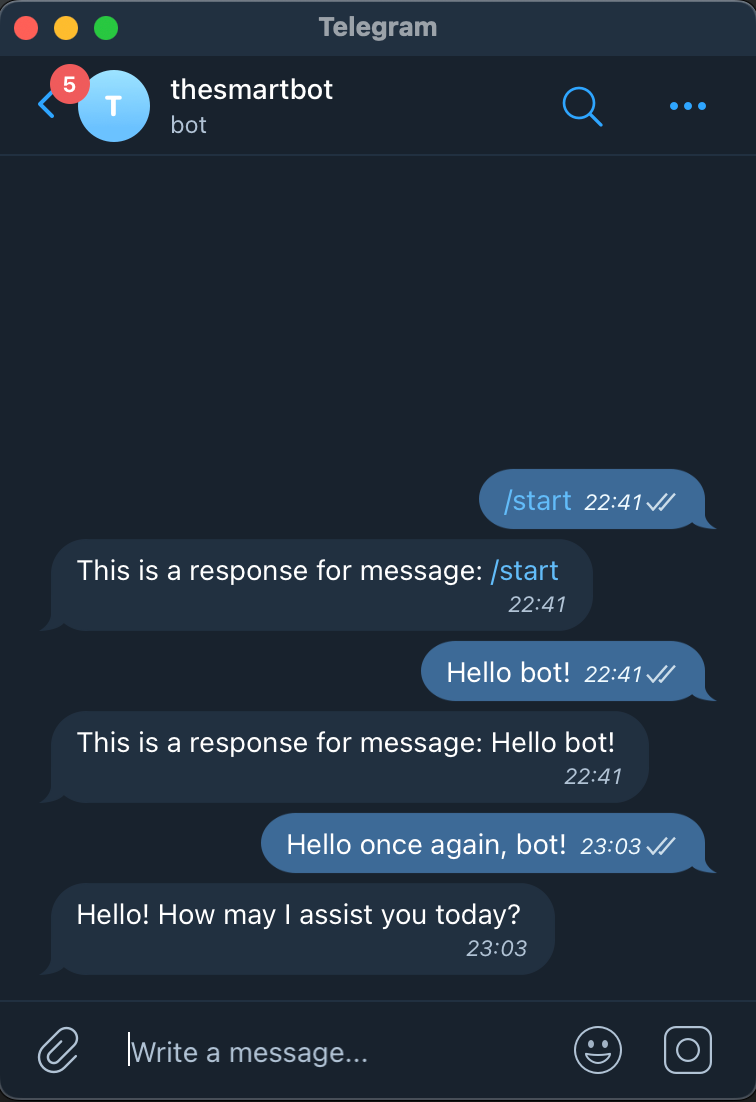
Whoosh!魔法正在发生!
总结一下吧!
这一步需要安装的Python库:quart、telethon。
我打赌你一定有过这样的经历--你被加入了一个聊天群,群里的朋友喜欢讨论有趣的事情或者分享一些新闻或想法。你有很多事情要做,你已经错过了聊天中的所有乐趣。接下来你看到的是--那里有一百条未读信息。如果有人能给您简要介绍一下那里发生的事情,而不是阅读所有的内容,这不是很好吗?嗯,GPT当然可以做到这一点。我们只需要问它。
这就是乐趣的开始。由于某些原因,Telegram的机器人API不允许机器人读取对话历史。我们有webhooks,也有明确的GetUpdates()方法,但它们只在有人提到机器人的情况下起作用。另一个选择是,如果机器人被添加为管理员,就可以得到所有的更新,但这种方法也有一些缺点。首先,你需要为这些信息设置整个存储空间。第二,如果你想总结机器人加入聊天之前的对话,怎么办?不是我们的情况。
很明显,这不是放弃的理由。Telegram提供了核心API,这个API可以帮助检索聊天记录。唯一的问题是,它是异步的。而最流行的Python库,Telethon,也是异步的。而Flask是同步的。呃--哦。
这就是标题中提到的神秘的Quart出现在舞台上的地方。Quart是使用async、await和ASGI网络服务器(而不是同步和WSGI)重新实现的Flask API。在我们的案例中,它的主要优势是语法基本上是一样的。让我们做一个快速的代码重组。
变化很简单。首先,调整导入,将每个Flask改为Quart:

然后,让所有网络应用的方法都变成异步。并等待所有的属性和方法,现在已经成为异步的了:
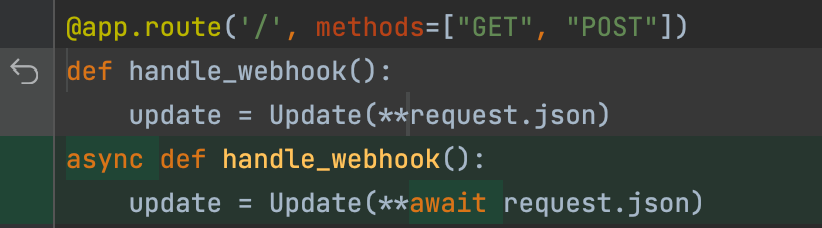
request.json属性现在是异步的,需要在代码中等待。
如果你不确定什么是异步Python,我鼓励你查看Telethon文档中关于异步基础知识的这一部分。
我还移动了ngrok和TelegramBot,在一个单独的方法中启动它们,用@app.before_serving 。这是一个Quart内置的装饰器,它将确保这个方法里面的所有东西都会在网络应用启动和服务之前运行。这是必要的,这样机器人和助手就可以和主程序在同一个事件循环中被初始化。
@app.before_servingasync def startup(): host = run_ngrok(Config.PORT) app.bot = TelegramBot(Config.TELEGRAM_TOKEN) app.bot.set_webhook(host) app.openai_helper = OpenAiHelper(Config.OPENAI_TOKEN)
运行应用程序也有一些变化,但不多。Hypercorn是用于异步运行Quart的ASGI服务器,如果我们想指定一个应用程序的端口,我们需要在配置中完成。注意,main() 现在也是异步的,使用asyncio运行:
async def main(): quart_cfg = hypercorn.Config() quart_cfg.bind = [f"127.0.0.1:{Config.PORT}"] await hypercorn.asyncio.serve(app, quart_cfg)if __name__ == "__main__": asyncio.run(main())
就这样了。让我们检查一下这些变化对我们的机器人是否顺利。运行,文本,输入:
它正在说话。很好。现在,为人工智能获取聊天记录来进行总结。让我们在Telethon库的帮助下使用Telegram的核心API。在那里,我们将需要你的最后两个秘密字符串--把它们也作为环境变量导出。
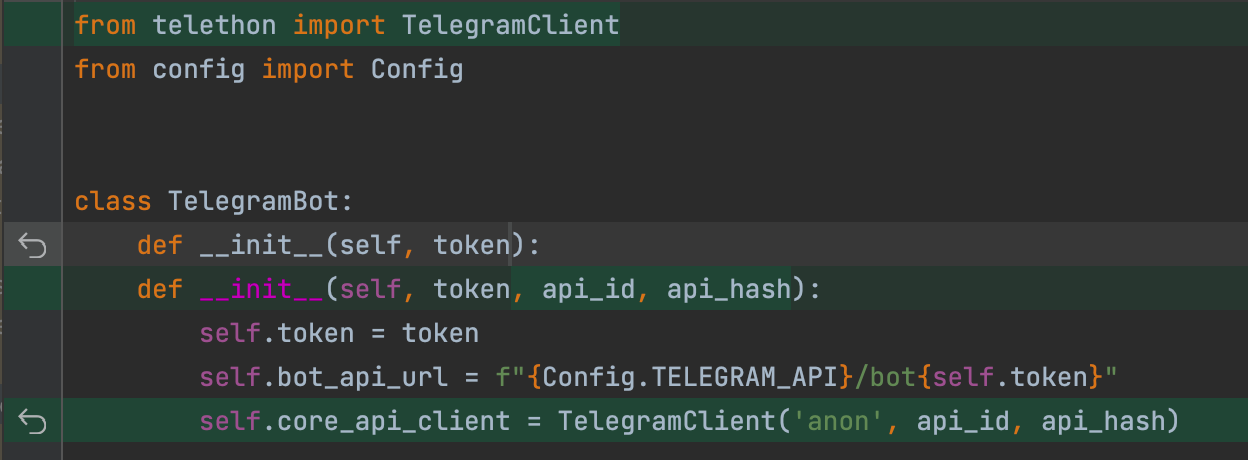
TelegramBot在__init__ 方法中略有变化:它将需要有一个新的core_api_client 属性来初始化Telethon的客户端,当然,你需要把Core API的秘密作为参数传递。
而这个小方法将负责检索历史记录:
async def get_chat_history(self, chat_id, limit=30): if not self.core_api_client: return [] history = await self.core_api_client.get_messages(chat_id, limit) result = [f"{message.sender.first_name} {message.sender.last_name}: {message.message} \n" for message in history if not message.action] result.reverse() return '\n'.join(result)
Telethon的get_messages除了limit ,还有很多不同的参数可以传递。例如,它可以反转历史,或者以日期而不是消息的数量来限制它。这很有趣,你可以用任何你喜欢的方式调整你自己的机器人。
好了,我们几乎完成了。最后的工作是在webhook处理程序中添加一个总结选项。这就是得到答案的样子:
if update.message.text.startswith("/summarize"): history = await app.bot.get_chat_history(chat_id) response = app.openai_helper.get_response("Please, briefly summarize the following conversation history:\n" +\ history) else: response = app.openai_helper.get_response(update.message.text) app.bot.send_message(chat_id, response)
让我们看看它的绽放!
在你第一次运行应用程序后,它会要求你登录到Telegram。这没关系:要想获得信息历史和其他核心API提供给我们的私人数据,这是必须的。输入你用来访问Telegram核心API的同一个电话号码。你会在你的应用程序内收到一个验证码,之后你就可以开始了。

将机器人添加到与朋友的对话中,并要求提供摘要:
就这样了!你可以继续做无穷无尽的事情:添加处理除文本外的其他类型的消息,配置要从聊天中总结的消息数量,等等。去做吧,别忘了把你的代码推送到GitHub上。编码愉快!:)
不要忘记跳转到Hyperskill网站,继续学习用Python和Flask开发Web应用程序。这里有一些主题的链接,你可能会发现对这个项目很有用:
- 错误处理程序:如果你不正确地处理错误,你的应用程序很有可能在运行时失败或向用户显示难看的回溯。为了避免这种情况,请阅读错误的类型以及如何在Flask应用程序中处理它们是最好的。
- 日志:在测试和调试应用程序时,这是最重要的事情之一。编写有意义的、可读的日志是软件开发者必须做的。看看这个主题,了解如何在Python中进行日志记录。
- SQLAlchemy介绍:当你决定要存储一些应用程序的数据时,无论是任何用户信息还是对话历史,你都需要与数据库沟通。本主题向你介绍了SQLAlchemy的基础知识,它使你与数据库的工作变得简单而方便。
Hyperskill是一个基于项目的学习平台,提供个性化的课程和各种轨道,帮助来自不同背景的人通过在线教育获得市场相关的技能。它不仅给你扎实的理论片段,而且允许你立即练习技能--实践使学习更完美。
你觉得这篇文章有帮助吗?请击掌并关注Hyperskill和我,以便以后阅读更多的内容 :)
