模型设计
- First, we must define an embedding function that maps discrete text into a continuous space.
- Second, we require a rounding method to map vectors in embedding space back to words.
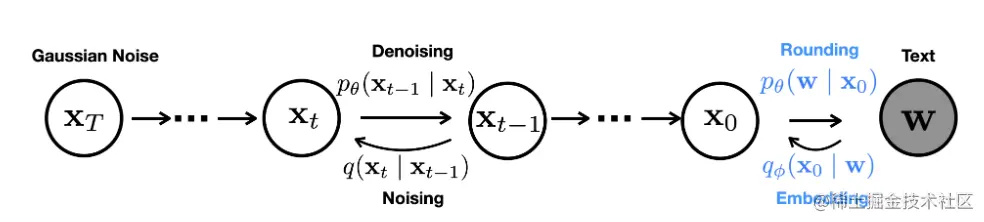
端到端训练
为了将离散文本应用到连续扩散模型上,这里设置了一个embedding函数EMB(wi)将每个词映射到词向量Rd。对于长度为n的序列w:
EMB(w)=[EMB(w1),…,EMB(wn)]∈Rnd
作者在实验中发现,使用预训练的word embedding效果不如使用随机高斯噪声初始化之后训练出来的embedding,所以加了这样一个网络,实现离散词序列w到x0的马尔科夫转换,参数化为:
qϕ(x0∣w)=N(EMB(w),σ0I)
与之对应的反向过程添加了一个可训练的舍入步骤,参数化为:
pθ(w∣x0)=i=1∏npθ(wi∣xi)
其中pθ(wi∣xi)是一个softmax分布。
因为增加了一个嵌入步骤和一个舍入步骤,添加的这两个网络是和扩散模型进行联合训练的,因此要对训练目标函数改进:
Lvlbe2e(w)Lsimple e2e(w)=qϕ(x0∣w)E[Lvlb(x0)+logqϕ(x0∣w)−logpθ(w∣x0)]],=qϕ(x0:T∣w)E[Lsimple (x0)+∥EMB(w)−μθ(x1,1)∥2−logpθ(w∣x0)].
Lsimplee2e(w)是Lvlbe2e(w)的简化版,是根据DDPM设计的目标函数。
DDPM的目标函数:
Lvlb(x0)=q(x1:T∣x0)E[logpθ(xT)q(xT∣x0)+t=2∑Tlogpθ(xt−1∣xt)q(xt−1∣x0,xt)−logpθ(x0∣x1)]
Lsimple (x0)=t=1∑Tq(xt∣x0)E∥μθ(xt,t)−μ^(xt,x0)∥2
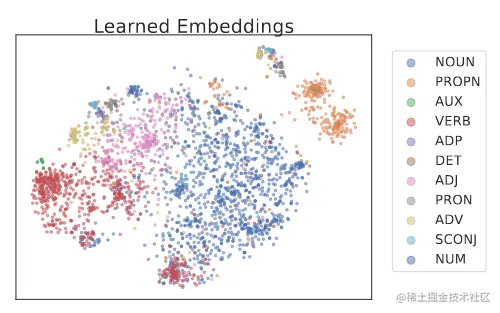
可视化之后可以看到学到的embedding是有意义的。
减少舍入误差
embedding是将离散文本映射到连续的x0上,那与之对应的反向过程就应该是将模型预测出来的x0转换回离散的文本。
舍入步骤是根据argmaxpθ(w∣x0)=∏i=1npθ(wi∣xi)选择每个位置上可能性最大的词。理想状态下通过这个舍入步骤就可以将模型输出的x0映射回离散文本,因为去噪步骤应该能让x0恰好回到某个单词的embedding上。
然而实际情况是不行的,模型输出是不会精确到某个单词的embedding。
作者认为造成上述问题的原因,是在目标函数中Lsimplee2e(x0)对x0结构的建模不够重视。
Lsimple (x0)=t=1∑TExt∥μθ(xt,t)−μ^(xt,x0)∥2
其中的μθ(xt,t)网络直接去预测时间步t去噪的pθ(xt−1∣xt)的均值。x0对单词的约束只会出现在t接近于0的项中。因此需要对目标函数进行调整,去强调x0。
作者对Lsimple 进行调整,强调模型在目标函数的每一项中都去显式地建模x0。
作者推导出一个类似于Lsimple 的使用x0参数化的公式:
Lx0-simple e2e(x0)=t=1∑TExt∥fθ(xt,t)−x0∥2
其中网络fθ(xt,t)直接去预测x0,这样会让神经网络去预测每一项的x0。
使用修改之后的目标去训练模型,模型很快就会学到让x0能回到以word embedding为中心。
clamping trick
作者将其称为clamping trick,在clamping trick中,模型将xt降噪为xt−1的生成过程:
-
通过fθ(xt,t)估计出一个x0
-
在这个估计的条件相爱对xt−1进行采样
-
xt−1=αˉfθ(xt,t)+1−αˉϵ
其中αˉt=∏s=0t(1−βs), ϵ∼N(0,I)
这一步就是用的DDPM中的那个,因为都是高斯核,所以xt可以由x0一步得到。
xt=αtxt−1+1−αtϵt−1∗=αt(αt−1xt−2+1−αt−1ϵt−2∗)+1−αtϵt−1∗=αtαt−1xt−2+αt−αtαt−1ϵt−2∗+1−αtϵt−1∗=αtαt−1xt−2+αt−αtαt−12+1−αt2ϵt−2=αtαt−1xt−2+αt−αtαt−1+1−αtϵt−2=αtαt−1xt−2+1−αtαt−1ϵt−2=…=i=1∏tαix0+1−i=1∏tαiϵ0=αˉtx0+1−αˉtϵ0
clamping trick 会将网络fθ(xt,t)的预测结果映射到接近的word embedding 序列上。
现在采样步骤就变为了:
xt−1=αˉ⋅Clamp(fθ(xt,t))+1−αˉϵ
clamping trick 迫使扩散模型降噪过程中每一步都去计算一个word embedding,使向量预测更为准确,以此减少舍入误差。
作者在这里提示将开始使用clamping trick的起始位置设置为超参数。具体原因看论文P5。
论文信息

论文地址:[2205.14217] Diffusion-LM Improves Controllable Text Generation (arxiv.org)
代码地址:XiangLi1999/Diffusion-LM: Diffusion-LM (github.com)
本文正在参加「金石计划」


