

一、概述
1.1、为什么分库?
分库主要解决并发及磁盘存储的问题。
- 并发支撑: 数据库的连接数是有限,即使能调整也不是无限的。所以并发量一上来,数据库就是服务的瓶颈。 所以,当数据库的读或者写的QPS过高,导致你的数据库连接数不足了的时候,就需要考虑分库了,通过增加数据库实例的方式来提供更多的可用数据库链接,从而提升系统的并发度。
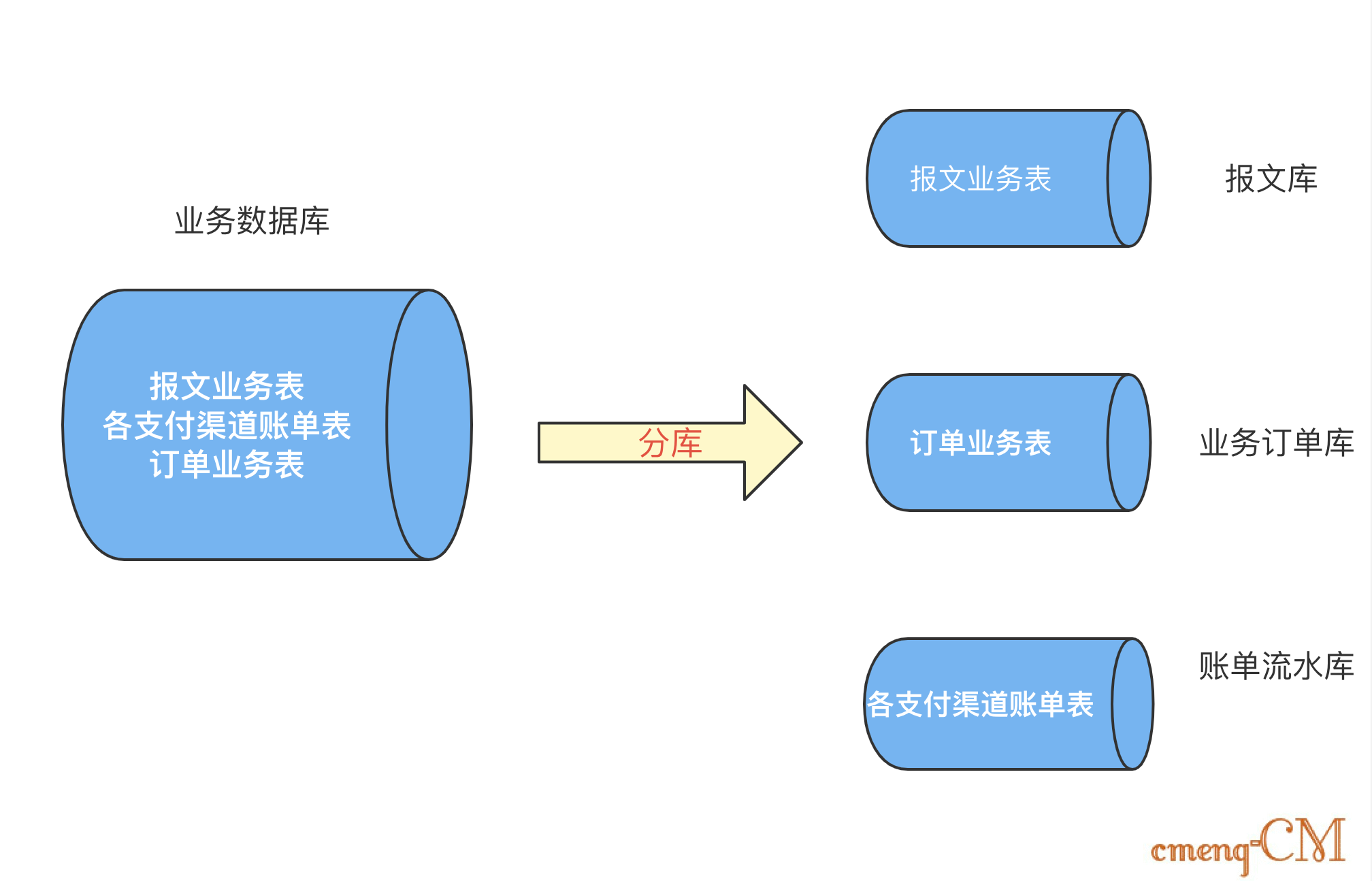
- 磁盘存储: 业务量剧增,MySQL单机磁盘容量会撑爆,拆成多个数据库,磁盘使用率大大降低。
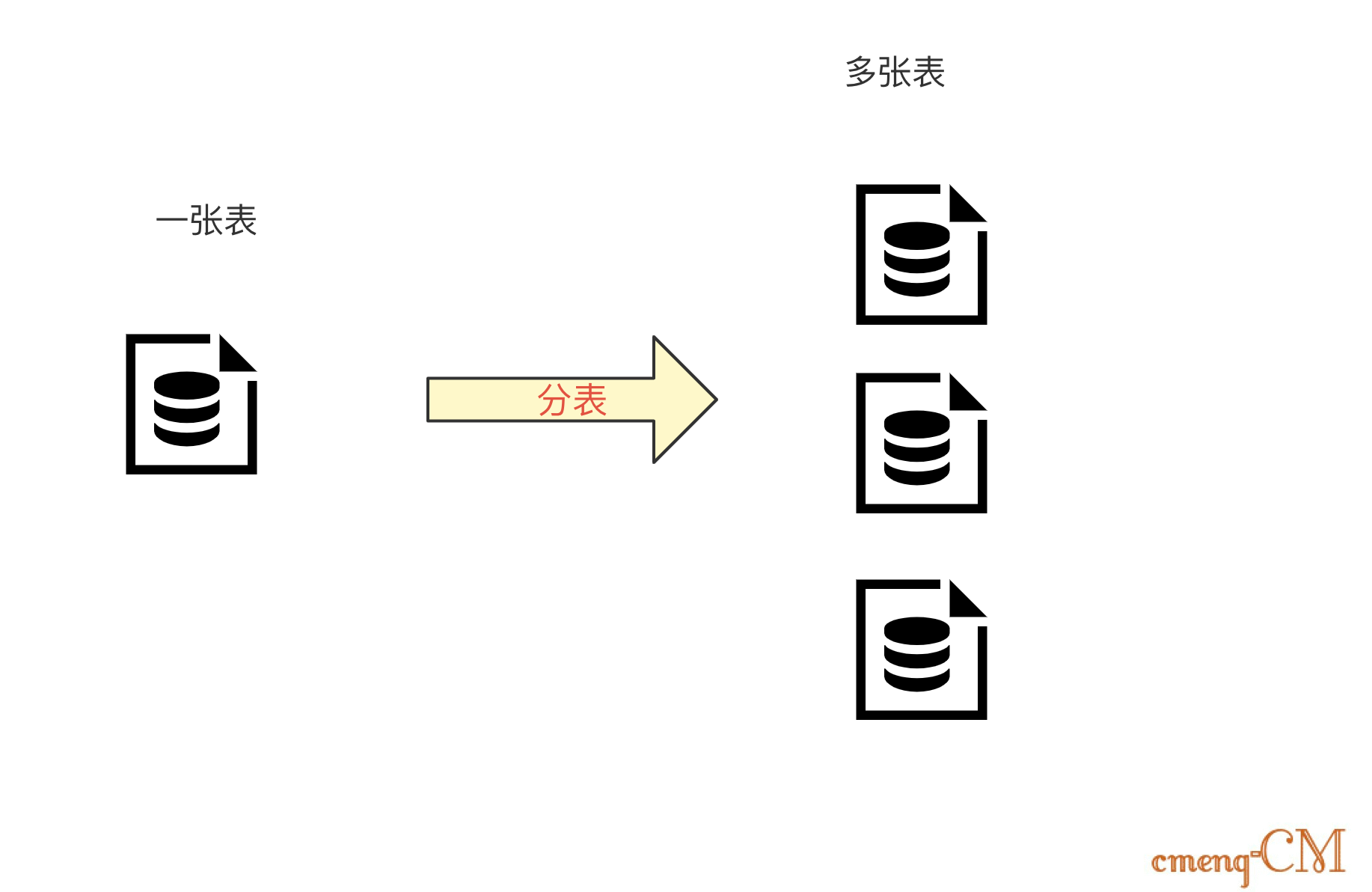
1.2、为什么分表?
分库主要解决的是并发量大的问题,那分表其实主要解决的是数据量大的问题。
数据量太大的话,SQL的查询就会变慢。如果一个查询SQL没命中索引,千百万数据量的表可能会拖垮这个数据库。
一般我们认为,单表行数超过 500 万行 或者单表容量超过 2GB 之后,才需要考虑做分库分表了,小于这个数据量,遇到性能问题先建议大家通过其他优化来解决。
1.3、即分库又分表?
当并发和数据量都起来的时候就需要即分库又分表了。切分就需要考虑怎么分了。分库分表有两种拆分机制:
- 水平拆分
- 垂直拆分
二、垂直(纵向)拆分
垂直拆分有垂直分库和垂直分表两种。
2.1、垂直分库
垂直分库: 就是根据业务耦合性将关联度低的表分别存储在不同的数据,以此来降低各个数据连接数据和磁盘占用。和微服务治理的理念非常相似,每一个独立的服务都拥有自己的数据库,需要不同业务的数据需接口调用。它的核心理念是专库专用。
2.2、垂直分表
垂直分表: 就是将表内字段进行拆分,根据使用情况及关联性,将一张表垂直切割成多张表。每张表留有原表的部分字段,多张表合起来和原表一样。
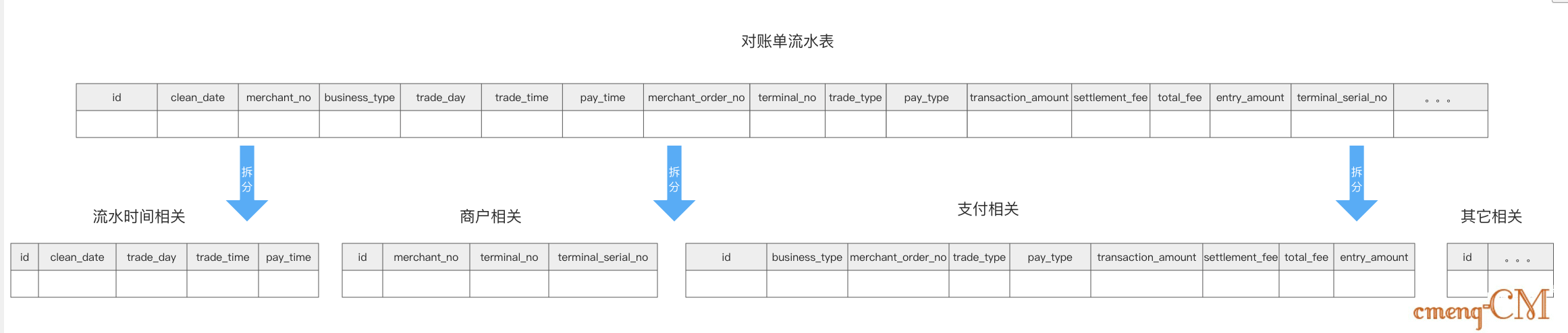
当然,分开的每张表都会保留唯一值字段,一般是主键,也可以是唯一值索引。这样也是为了方便查询命中。
三、水平拆分
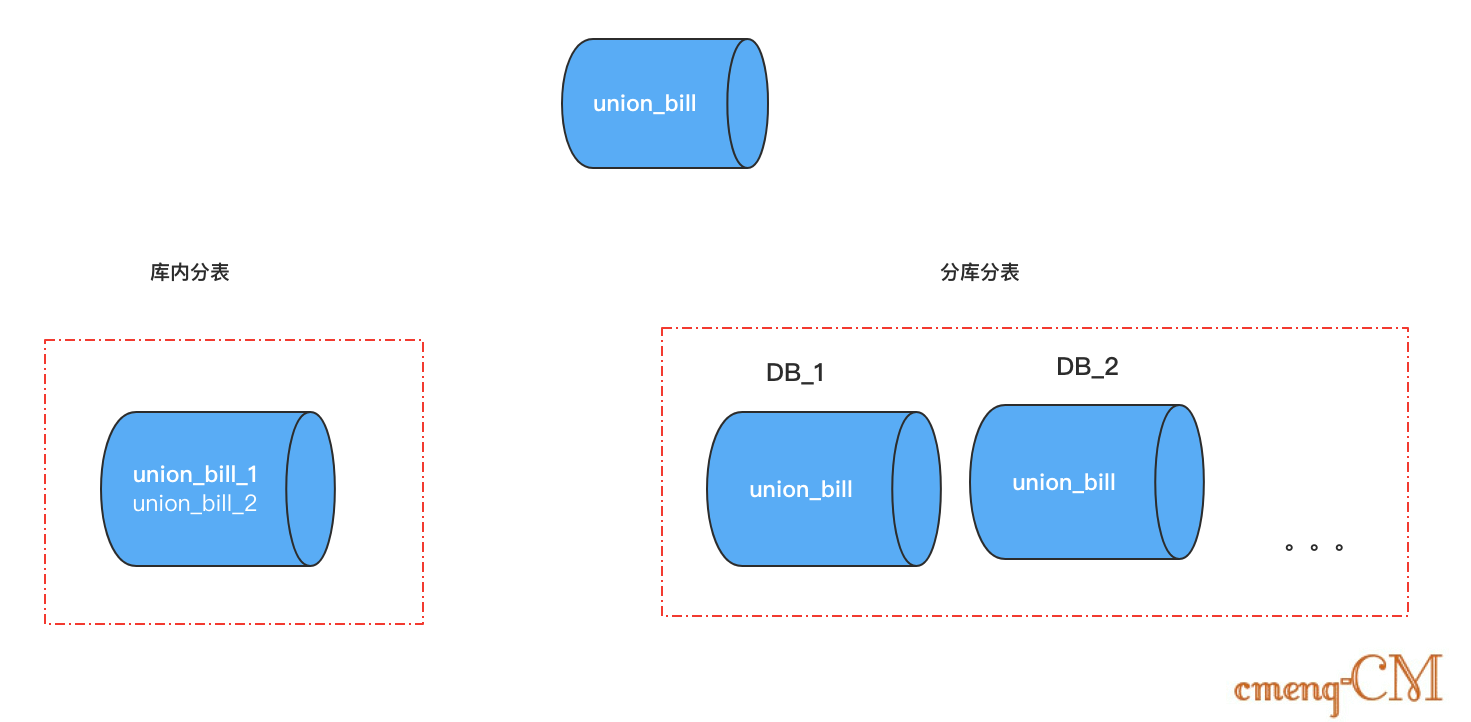
水平切分分为 库内分表 和 分库分表 ,是根据表内数据内在的逻辑关系,将同一个表按不同的条件分散到多个数据库或多个表中。
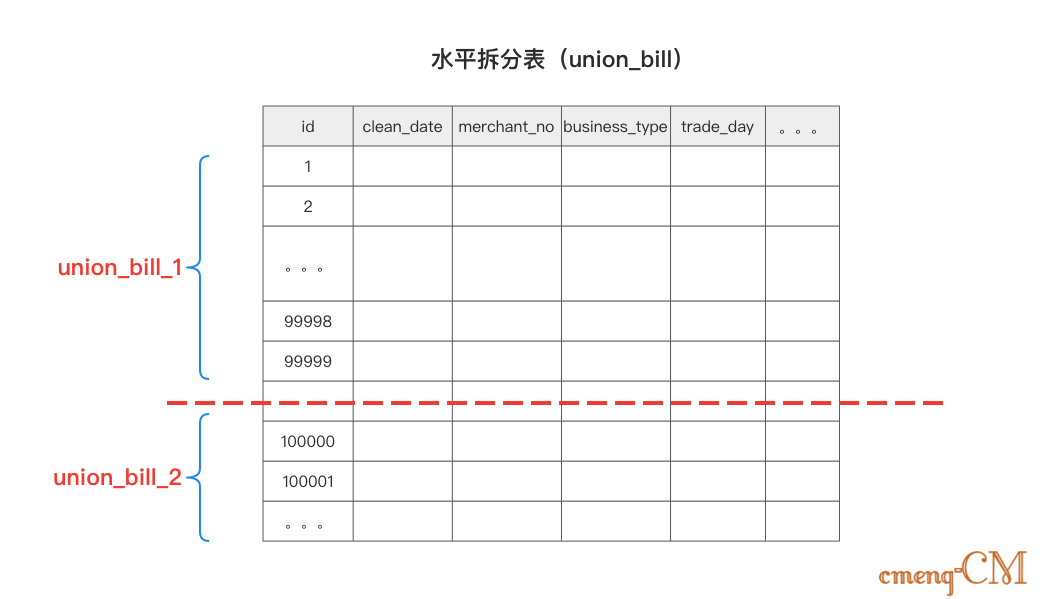
3.1、水平分表
库内分表:即水平分表,每个表中只包含一部分数据,从而使得单个表的数据量变小,达到分布式的效果。即:每张表结构完全一样,只是数据不一样。
3.2、水平分库
分库分表:即水平分库,单表分为多个结构一样且存储在不同的数据库中
3.3、分表策略——Range
Range:范围划分,比如按照时间将数据划分为每月一张表。或者根据id范围,如:【1-100000】放一张表,【100001-10000000】放在一张等依次类推。
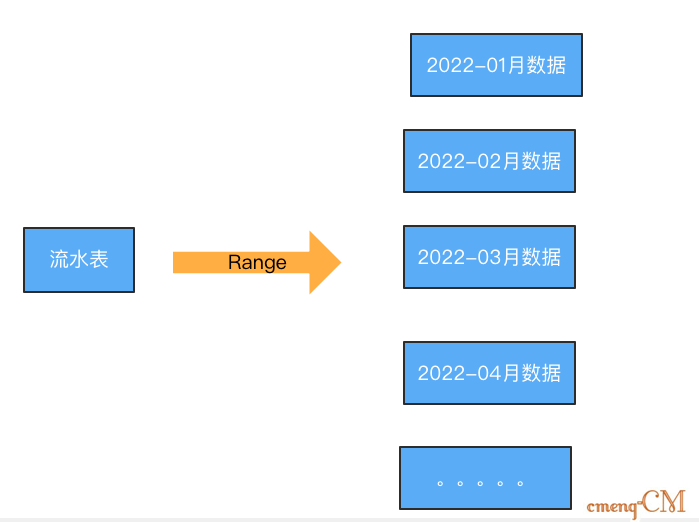
优缺点:
- 优点:是自带水平扩展,不需要过多干预。
- 缺点:存在热点数据,比如某个月请求暴增。
3.4、分表策略——mod/hash+mod
mod: 取余模式,指定路由的key(一般是id)通过分表的数量进行取余,然后根据余数指定将数据存储入表中。 hash+mod:在取余之前,针对路由的key进行Hash取值,取值后再取余。这种方式与 HashMap的key 存储机制类似。
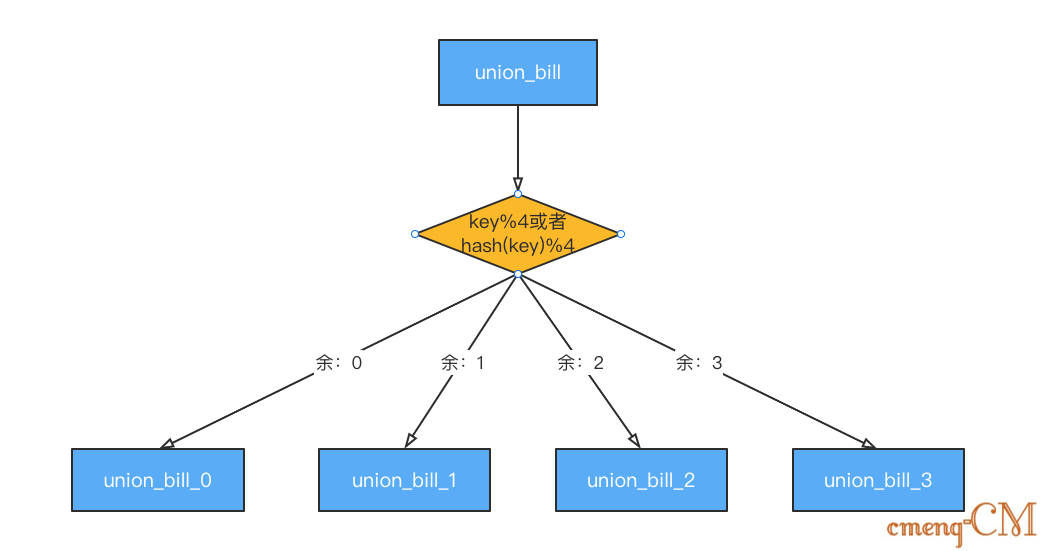
分表数量:具体分表数量要根据业务的实际情况,以及对未来业务发展情况及数据量级增加情况进行划分。此处扩展较为麻烦,比如原数据 16%4 分配在表 union_bill_0 中,扩展表数量为 8 后,数据存储在 16%8 表 union_bill_2 中,此种方式在扩展表时,需要针对历史数据进行数据迁移。
优缺点:
- 优点:不存在热点数据。
- 缺点:不利于水平扩展。
