梯度下降
基本概念
这个不赘述了
x(k)←x(k−1)+t∇f(x)
这里t是步长。
其思想就是在前点利用二阶近似来拟合邻域,然后在邻域里找局部最小值。二阶近似为f(y)=f(x)+∇f(x)T(y−x)+2t1∣∣y−x∣∣22。这里把二阶导的Hessen矩阵用t代替了,然后关于y求梯度=0,可以得到y=x+t∇f(x)。
步长设置
太大会震荡不收敛,太小会训练太慢,如何选取合适的步长?
backtracking
初始化t=t0,每次迭代,如果f(x−t∇f(x))>f(x)−αt∣∣∇f(x)∣∣22,则t=βt,之后梯度下降。这里α一般是1/2,0<β<1
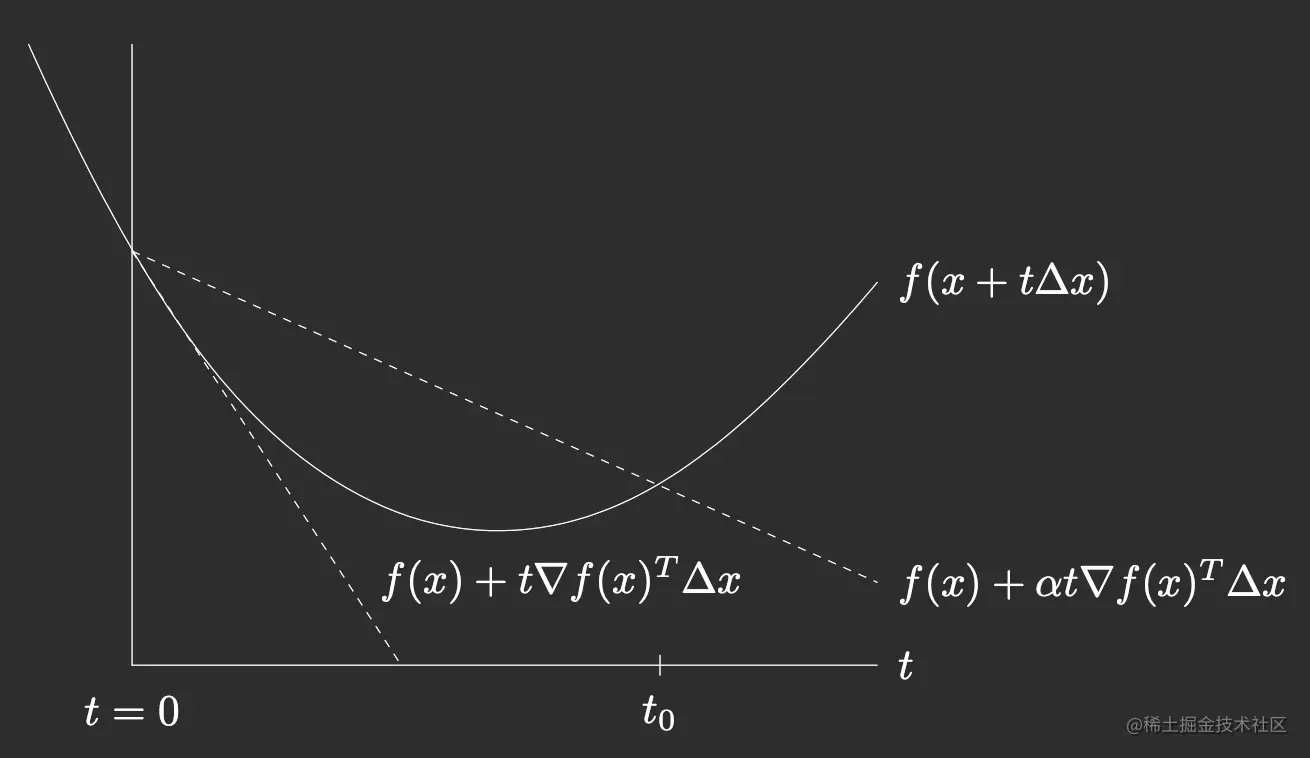 这个图很直观,这里的Δx=−∇f(x)(沿着负梯度前进)。实线是实际的函数图,两条虚线是在当前x的线性近似,如果乘α会减缓近似的那条直线下降的速度。这样相当于把近似夹在了一个空间里。如果实线大于了上面那条虚线,那么说明现在的近似不太对,或者说t有点偏大了,因此shrink一下。
这个图很直观,这里的Δx=−∇f(x)(沿着负梯度前进)。实线是实际的函数图,两条虚线是在当前x的线性近似,如果乘α会减缓近似的那条直线下降的速度。这样相当于把近似夹在了一个空间里。如果实线大于了上面那条虚线,那么说明现在的近似不太对,或者说t有点偏大了,因此shrink一下。
exact 最速下降法
就说前面我们使用f(x)的二阶近似找的,那我直接找最佳可以吗,这个理论上可以但不太现实,即直接找t=argmins≥0f(x−s∇f(x))
收敛分析
先来一个前置知识:李比希次连续
∣∣f(x)−f(y)∣∣2≤L∣∣x−y∣∣2
再来一个前置,矩阵的范数,注意它和向量范数有区别。
∣∣A∣∣p=x=0max∣∣x∣∣p∣∣Ax∣∣p
- p取1时,矩阵的最大列和。
- p取2时,矩阵ATA特征值根号的最大值。
- p取无穷,矩阵的最大行和。
对于凸函数f,如果他的一阶导数是李比希次连续,那么∣∣∇f(y)−∇f(x)∣∣2≤L∣∣x−y∣∣2。
如果是二次可微,则对任意x它的Hessian矩阵最大特征值不会超过L,因此∣∣∇2f∣∣2<L,所以∇2f(x)≤LI,这里表示半负定。
收敛性分析的一般思路:
最终目标是要构造一个形如∣f(xk)−p∗∣∣f(xk+t)−p∗∣≤ϵ。以此建立t和ϵ的关系。
关键是lhs怎么构造。这里一般基于递推构造,即首先构造f(xk+1)和f(xk)的不等关系。
最后分析收敛程度,横轴是迭代轮次,纵轴是log(f(xk)−p∗),看向下的趋势。
重要定理
对于固定的步长t=1/L,f(x(k))−f∗≤2tk∣∣x0−x∗∣∣22,如果是backtracking的方法,则t替换成β/L即可。
在初始点确定、参数确定的情况下,右侧随着k增大而减小,因此收敛率为O(1/k),从另一个角度看,相当于实现ϵ-optimal需要O(1/ϵ)步。
如果函数不仅仅是导数李比希次,还能够强凸(f(x)−2m∣∣x∣∣22,此时有∇2f(x)≥mI),那么收敛速度还可以更快,对于固定的t≤2/(m+L),有
f(x(k))−f∗≤γk2L∣∣x(0)−x∗∣∣22
其中γ=O(1−m/L),这样是指数的速度,换句话说ϵ-optimal只需要O(log(1/ϵ))的复杂度。
这里补充一下p阶收敛的知识,设e=∣xk−x∗∣表示第k步的绝对误差。limk→∞ekpek+1=c成立的p就是收敛阶数。
二次型上的小应用
f(β)=21(y−Xβ)T(y−Xβ),那么这是一个没有限制条件的二次型凸优化问题
- 先来讨论李比希次条件,∇2f(β)=XTX,因此如果∇2f≤LI,则L=λmax(XTX)。
- 再分析强凸条件,需要保证f(x)−2m∣∣x∣∣22是凸的,即∇2f≥mI,所以m=λmin(XTX)。因此如果这个矩阵的列数大于行数,一定不满秩,最小特征值为0,那就没发保证强凸了。
停止定理
如果f强凸,且参数为m,那么∣∣∇f(x)∣∣2≤2mϵ→f(x)−f∗≤ϵ
Newton法
前面梯度下降法对于二阶近似直接把hassian矩阵近似掉了。Newton法就是不去近似,直接写出来。即
f(y)=f(x)+∇f(x)T(y−x)+21(y−x)TH(x)(y−x)
那么∇f(y)=0处应该为极小值,所以有
∇f(x)T+H(x)(y−x)=0
因此y=x−H−1(x)∇fT(x)。这就是迭代更新公式。可以很明显看到和梯度下降的区别,就是学习率从t的近似变成了hassian矩阵的拟。
如果矩阵是正定的,并且初始值合适,可以保证二阶收敛。
缺点也很明显:计算Hassian矩阵太复杂,还得求逆(未必有),可能收敛于鞍点。位了保证正定可逆,采用强迫正定策略,即H(x)+αI再求逆。
另外最速下降法的思路在这里一样可以用,就是依然再更新时添加步长,y=x−tH−1(x)∇fT(x)。t=argmintf(x−tH−1(x)∇fT(x))
应对不可导情况:次梯度法
次梯度
一种梯度概念的推广, 其定义是一个闭区间中的任意值,区间左右端点分别是左导数和右导数。
例如f(x)=∣x∣,在x=0的时候导数很容易求,但在x=0处不可导,但是利用次梯度的概念,其次梯度为[−1,1]中的任何数。
次微分就是把整个区间看作一个整体。它的性质有:
- 如果可导,次微分就是一个单点即导数。
- 反过来也成立,如果次微分只包含一个单点,那这个单点就是导数。
- 凸函数的次微分非空。
- 最优化条件:f(x∗)=minf(x)⇔0∈∂f(x∗)。即极值点处的次微分包含0。
eg Lasso问题
βmin21∣∣y−Xβ∣∣22+λ∣∣β∣∣1
极值点满足0∈∂(21∣∣y−Xβ∣∣22+λ∣∣β∣∣1)。
分情况讨论
- βi=0,那么次微分就一个值,满足最优化条件必须得等于0,因此XT(y−Xβi)=λsgn(βi)
- 对于βi=0的情况,那么此时绝对值的次微分为[−1,1],为了让0在整个loss的次微分里,需要满足−XT(y−Xβi)−λ≤0 且−XT(y−Xβi)+λ≥0,即∣∣XT(y−Xβi)∣∣≤λ
在X=I的情况下,上面的两个情况简化为
- yi−βi=λsgn(βi),βi=0
- ∣yi−βi∣≤λ,βi=0
尝试求出β,如果βi的解为0,那意味着∣yi∣≤λ,否则,yi−βi=λsgn(βi),因此βi=[Sλ(y)]i
- yi−λ,(yi>λ)
- 0,(∣yi∣≤λ)
- yi+λ,(yi<−λ)。
形状类似阶梯型。被称为软阈值。
次梯度法
适用于凸的未必可微函数。就是梯度下降的梯度替换成了次梯度,替换方法就是从次微分区间里任选一个值。还要注意次梯度并不保证每次都下降,因此不能只记录当前值,还得维护最优值。
步长可以定长或衰减,但是不能应用最速下降。收敛率为O(1/ϵ2),慢于梯度下降。
应对不可导:proximal gradient
近端梯度也是一种应对不可导的方法。
考虑凸优化问题f(x)=g(x)+h(x),我们把优化目标拆分成两块,其中g是凸且可微的,h凸不可微,但他是闭函数(sublevel test凸)。
在这种情况下,我们发现其实即使只有g的梯度也可以找到一个合适的优化方向。即xk=proxtk,h(xk−1−tk∇g(xk−1))。
首先明确符号表示proxtk,h(n(x))=argminu{h(u)+2tk1∣∣u−n(x)∣∣22}。
然后把前面说的proxtk,h(xk−1−tk∇g(xk−1))带入看
xk=proxtk,h(xk−1−tk∇g(xk−1))=argumin{h(u)+2tk1∣∣u−(xk−1−tk∇g(xk−1))∣∣22}=argumin{h(u)+2tk1∣∣u−xk−1+tk∇g(xk−1)∣∣22}=argumin{h(u)+2tk∣∣∇g(xk−1)∣∣22+∇g(xk−1)T(u−xk−1)+2tk1∣∣u−xk−1∣∣22}=argumin{h(u)+g(xk−1)+∇g(xk−1)T(u−xk−1)+2tk1∣∣u−xk−1∣∣22}≈argumin{h(u)+g(u)}
这里前四行都很简单,到第5行的代换,是因为外面是关于u的argmin,这说明所有和u无关的项都可以随意替换。于是替换凑成了一个关于g在xk−1的二阶Taylor展开。
上面的推导说明利用prox选取的xk可以让原问题进一步变小。然后重新写一下迭代式
xk=xk−1−tkGtk(xk−1),Gt(x)=t1(x−proxt,h(x−t∇g(x)))
步长选择tk,可以固定,也可以使用线性搜索,不断衰减t=βt直到g(x−tGt(x))不超过g(x)的二阶近似值。这个很神奇,g括号里面就是下一步的x值,我们只要求这个值在g函数上是减小的,丝毫没考虑h,就可以保证迭代收敛了。
应对不可导:坐标下降法
对于f(x)可以写成g(x)+∑h(xi)的情况,g是可微凸函数,h是凸的。
使用坐标下降求最小值,对于x0=(x10,...,xn0),先固定n-1个维度,把其中一个维度作为变量,求最小。这一步因为只有一个变量,所以一维搜索或者求导很容易得到。
求完再求第二个维度,以此类推,得到x1=(x11,...,xn1)。直至两次迭代的坐标点距离很近。
坐标下降的顺序任意、关键是一次一个坐标更新,否则可能不收敛。可以把任意一个坐标推广成一部分坐标。如果是全部坐标那就是梯度下降。


