

消息队列 | 青训营笔记
这是我参与「第五届青训营 」笔记创作活动的第15天
什么是消息队列
消息队列是一种使用队列作为底层存储数据结构,可以用于解决不同进程与应用程序之间通讯的分布式消息容器,也可以称为消息中间件。
- 业内常见的消息队列
- Kafka
- RocketMQ
- BMQ
- Pulsar
- RabbitMQ
- 消息队列应用的解决场景
- 系统服务突然崩溃
- 服务的能力优先,无法处理过多的业务请求
- 链路耗时长尾
- 日志存储问题
消息队列发展历程

常见消息队列对比

Kafka
使用Kafka
第一步:首先需要创建一个Kafka集群 第二步:需要在这个集群中创建个Topic,并且设置好分片数量 第三步:引入对应语言的SDK,配置好集群和Topic等参数,初始化一个生产者,调用Send方法,将你的Hello World发送出去 第四步:引入对应语言的SDK,配置好集群和Topic等参数,初始化一个消费者,调用Poll方法,你将收到你刚刚发送的Hello World
Kafka中常见概念
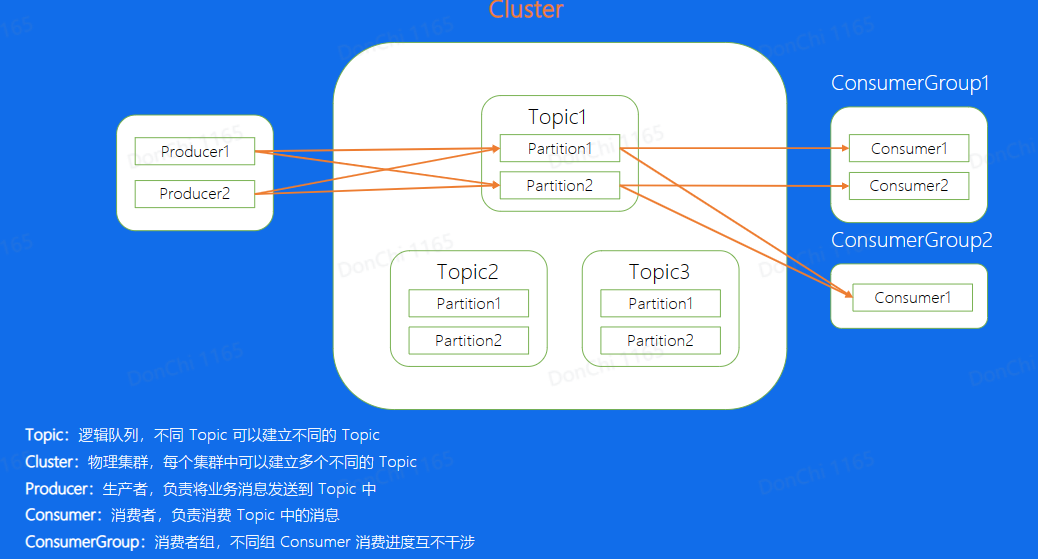
- Topic:Kafka中的逻辑队列,可以理解成每一个不同的业务场景就是一个不同的topic,对于这个业务来说,所有的数据都存储在这个topic中
- Cluster:Kafka的物理集群,每个集群中可以新建多个不同的topic
- Producer:消息的生产端,负责将业务消息发送到Topic当中
- Consumer:消息的消费端,负责消费已经发送到topic中的消息
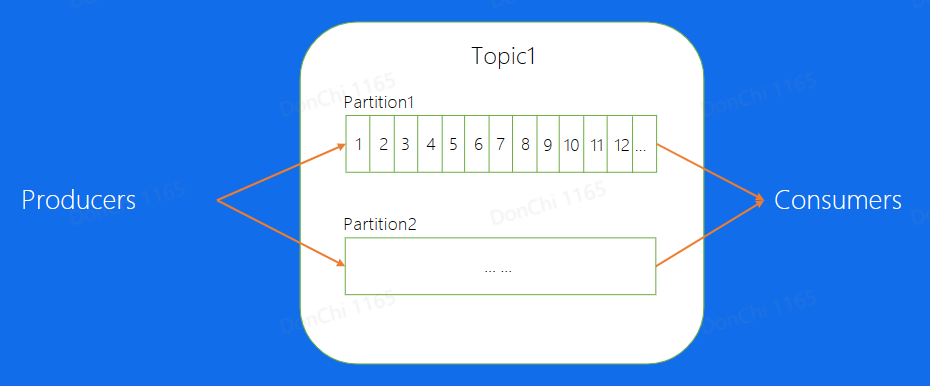
- Partition:通常topic会有多个分片,不同分片直接消息是可以并发来处理的,这样提高单个Topic的吞吐
- Offset:消息在partition中的相对位置信息,可以理解为唯一的ID,在partition内部严格递增
-
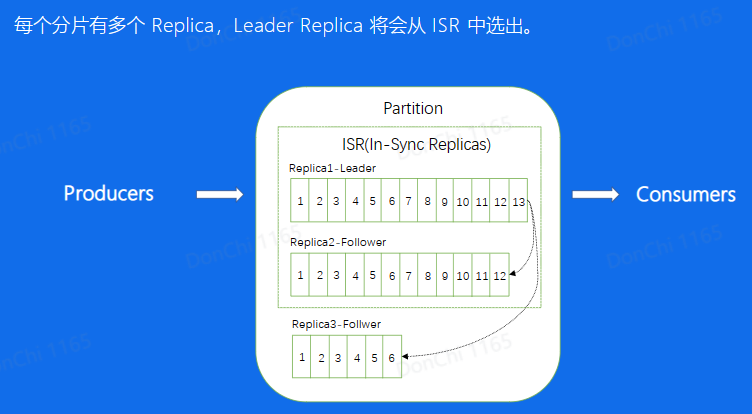
Replica:分片的副本,分布在不同的机器上,可用来容灾,Leader对外服务,Follower异步去拉取leader的数据进行同步,如果leader挂掉了,可以将Follower提升成leader再对外进行服务
-
ISR:意思是同步中的副本,对于Follower来说,始终和leader是有一定差距的,但当这个差距比较小的时候,我们就可以将这个follower副本加入到SR中,不在ISR中的副本是不允许提升成Leader的
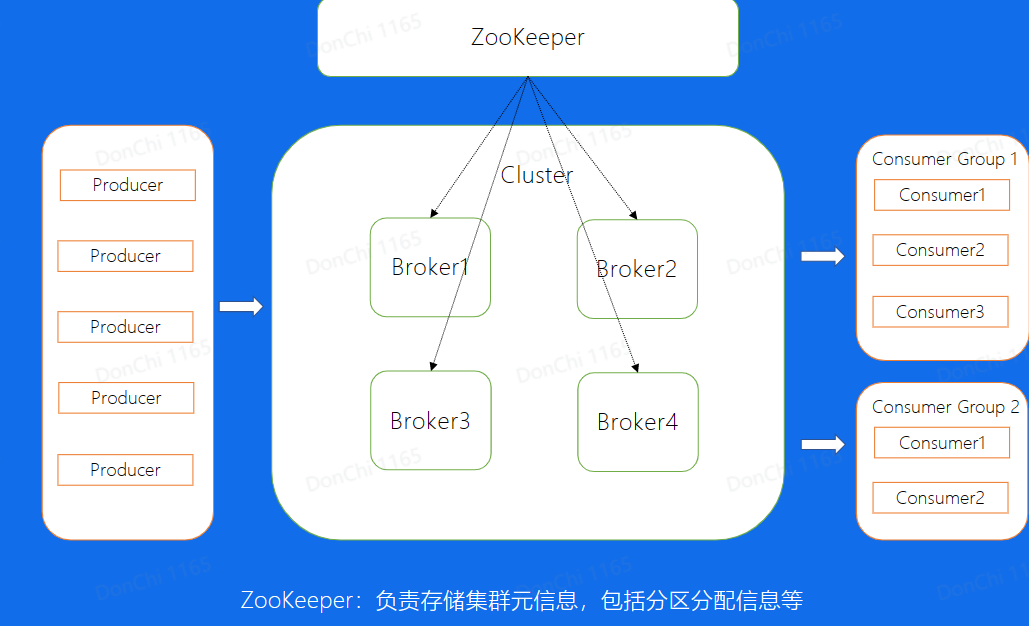
Kafka中的数据复制
图中Broker代表每一个Kafka的节点,所有的Broker节点最终组成了一个集群。整个图表示,图中整个集群,包含了4个Broker机器节点,集群有两个Topic,分别是Topic1和Topic2,Topic1有两个分片,Topica2有1个分片,每个分片都是三副本的状态。这里中间有一个Broker同时也扮演了Controller的角色,Controller是整个集群的大脑,负责对本和Broker进行分配
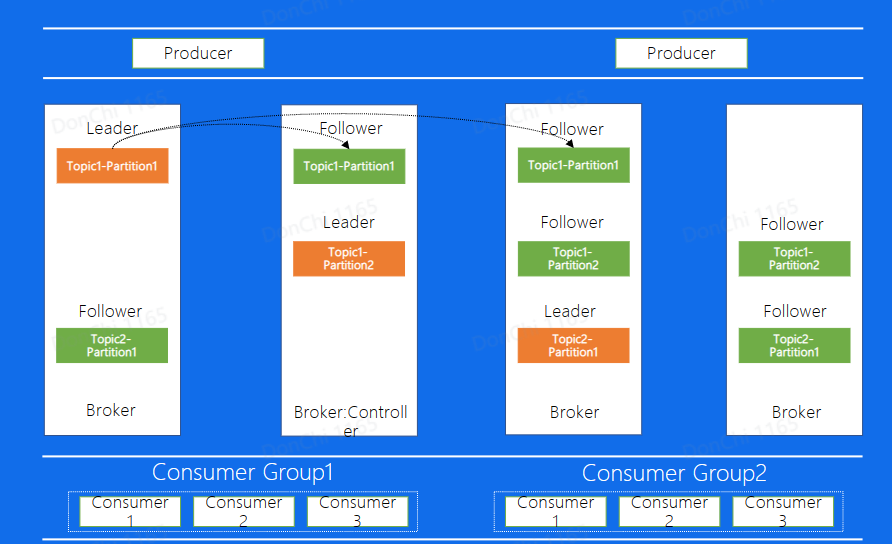
Kafka的架构
为什么Kafka可以支持高吞吐?
Producer
-
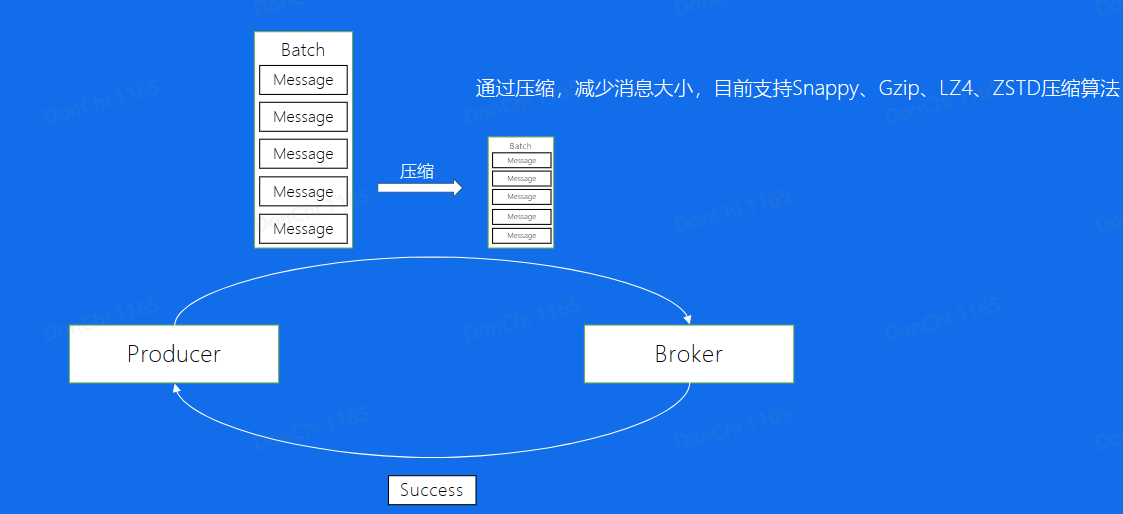
批量发送:Producer将许多Message打包成一个Batch,一并发送可以减少IO次数,从而加强发送能力
-
数据压缩:对于一个Batch,使用压缩算法可以进一步减小消息大小
Broker
-
顺序写:对于消息使用顺序写入的方式,利用了物理存储设备顺序读写速度高的特性

-
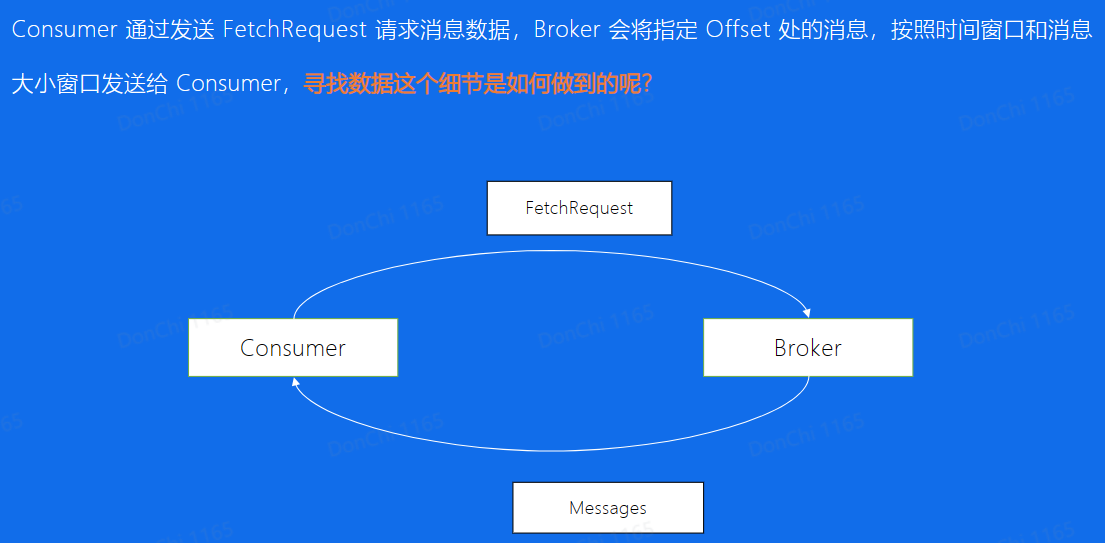
消息索引:Consumer向Broker请求消息文件消费,Broker使用二分思想查找消息文件

-
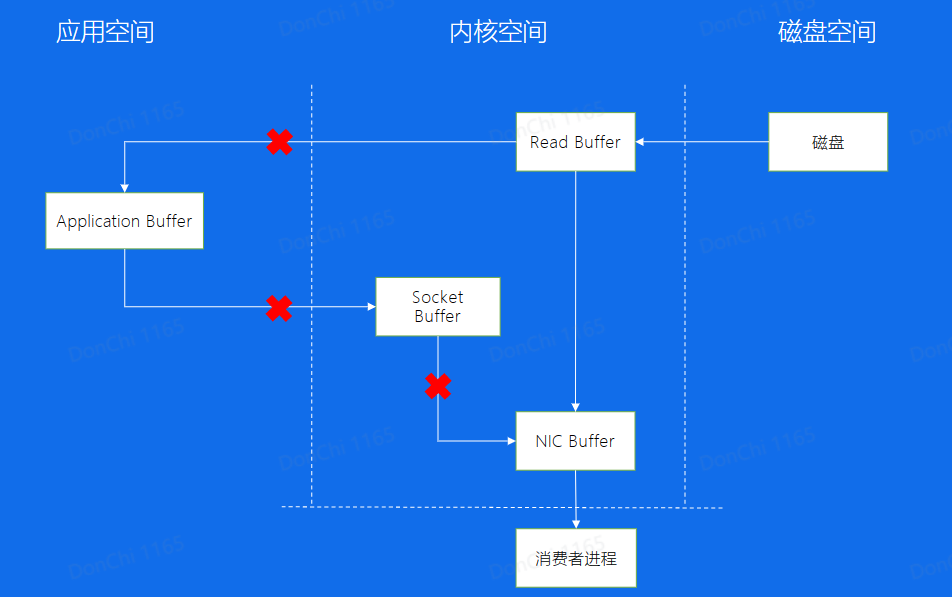
零拷贝:Consumer从Broker中读取数据,通过sendfile的方式,将磁盘读到os内核缓冲区后,直接转到socket bufferi进行网络发送 Producer生产的数据特久化到broker,采用mmap文件映射,实现顺序的快速写入
Consumer
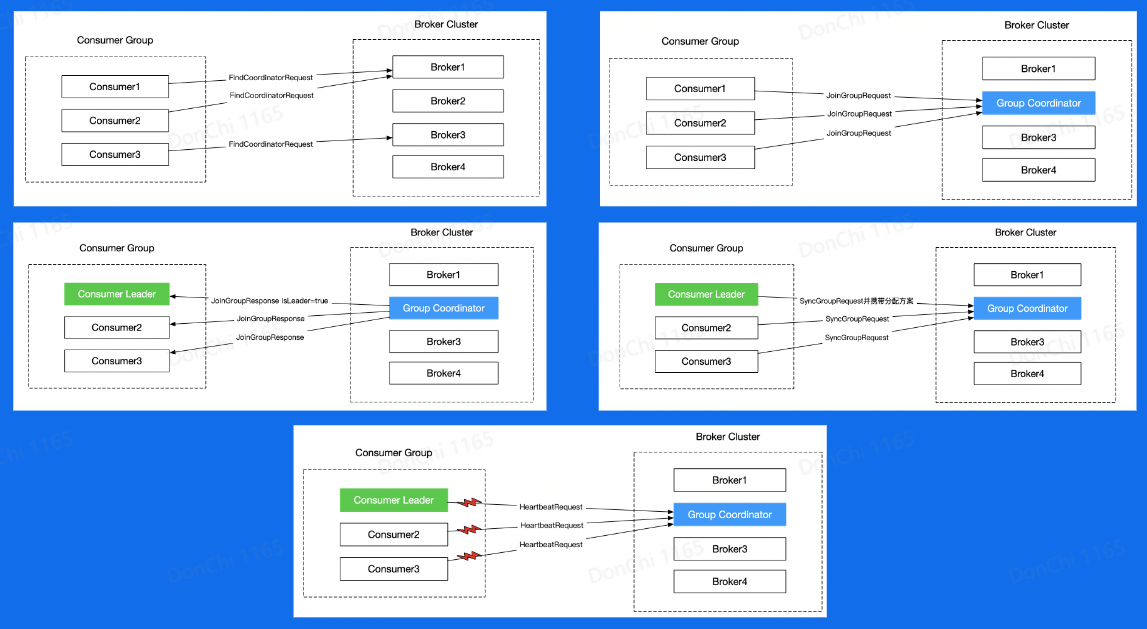
- Rebalance
Kafka的缺点
- 重启操作、替换、扩容和缩容等涉及数据复制的问题,因为固有设计导致运维成本高
- 对于负载不均衡场景,解决方案复杂
- 没有自己的缓存,完全依赖PageCache
- Controller和Coordinator和Broker都处于同一个进程中,大量IO会使得性能下降。
BMQ
兼容Kafka协议,存算分离,云原生消息队列
架构图
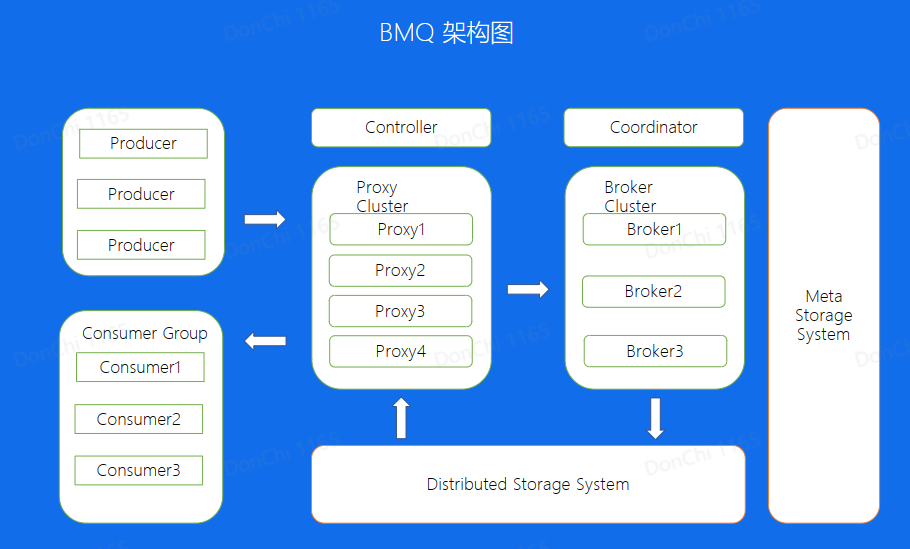
下层分布式存储使用HDFS
BMQ文件结构
对于Kafka分片数据的写入,是通过先在Leader上面写好文件,然后同步到Follower上,所以对于同一个副本的所有Segment都在同一台机器上面。就会存在之前所说到的单分片过大导致负载不均衡的问题,但在BMQ集群中,因为对于单个副本来讲,是随机分配到不同的节点上面的,因此不会存在Kafks的负载不均问题
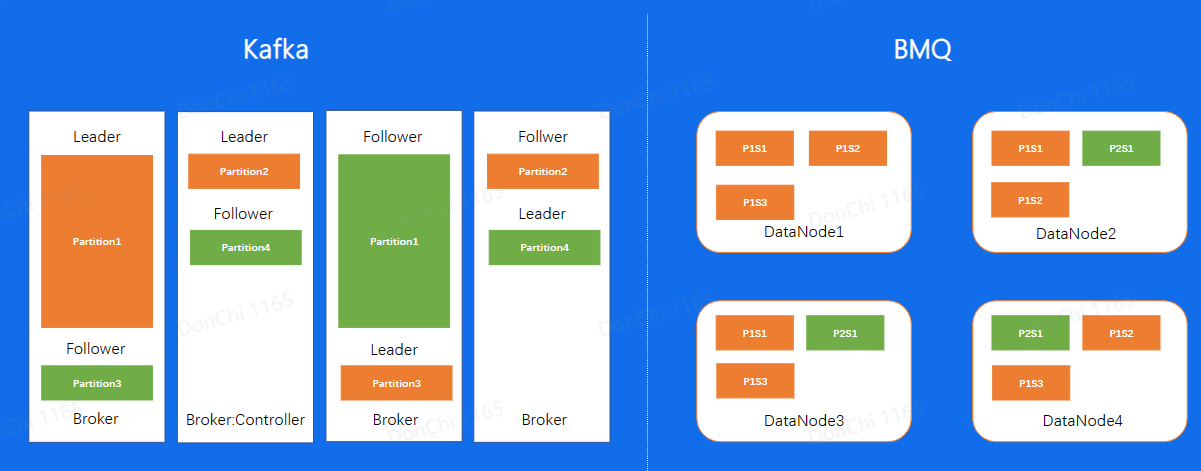
BMQ读写流程
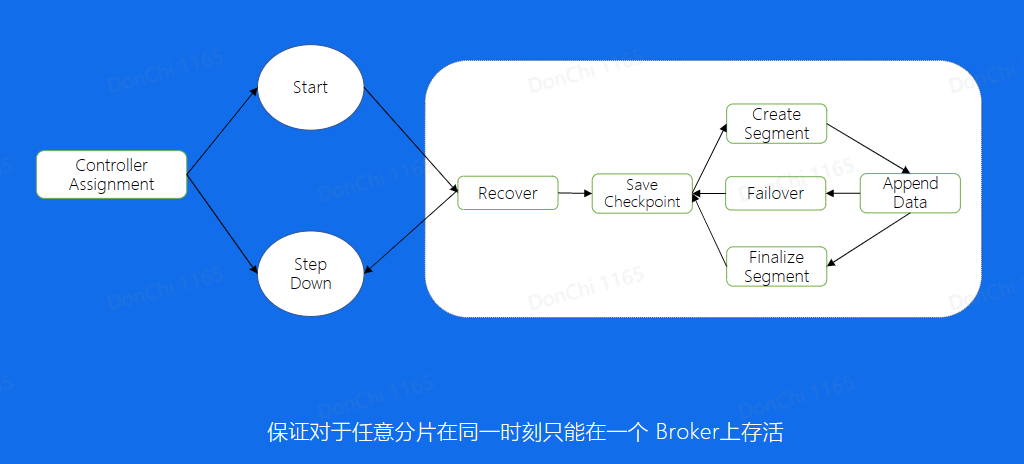
写文件Failover
建立一个新的文件,会随机挑选与副本数量相同的数据节点进行写入,如果挑选的节点出现了问题,无法写入。此时重新寻找正常的节点进行写入,保证了写入的可用性。

写入状态机
BMQ高级特性
泳道
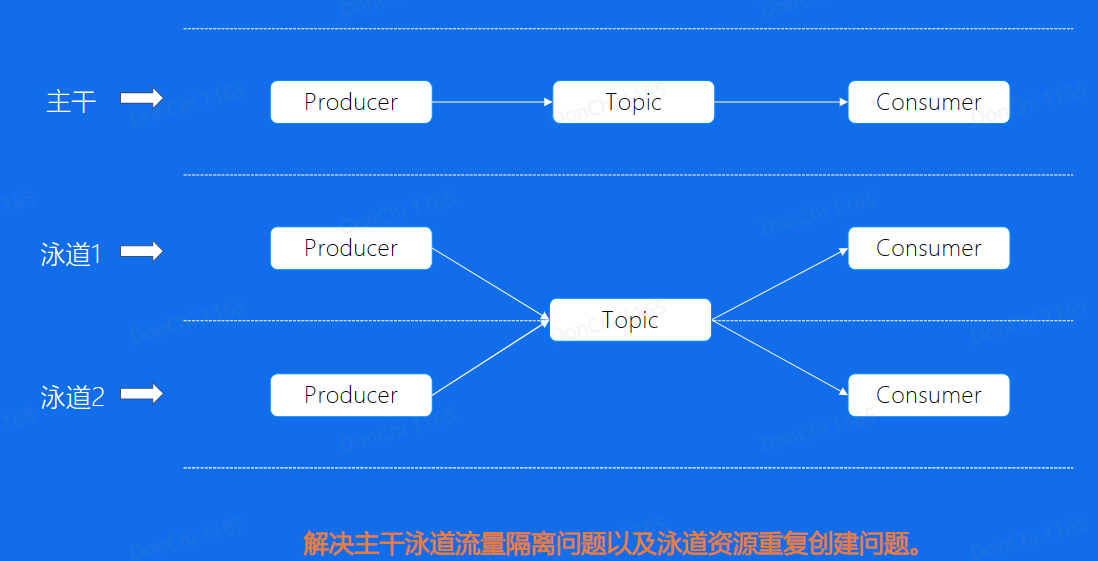
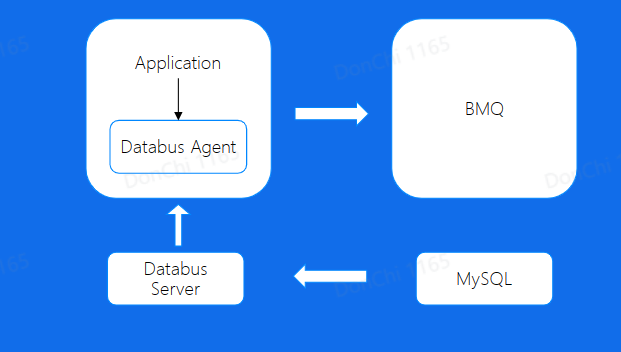
Databus
直接使用原生SDK的问题
- 客户端配置复杂
- 不支持动态配置
- 对于latency不是很敏感的业务,batch效果不佳
使用Databus
- 简化消息队列客户端复杂度
- 解耦业务与Topic
- 缓解集群压力,提高吞吐
Mirror
多机房部署,使用Mirror解决跨Region读写的问题
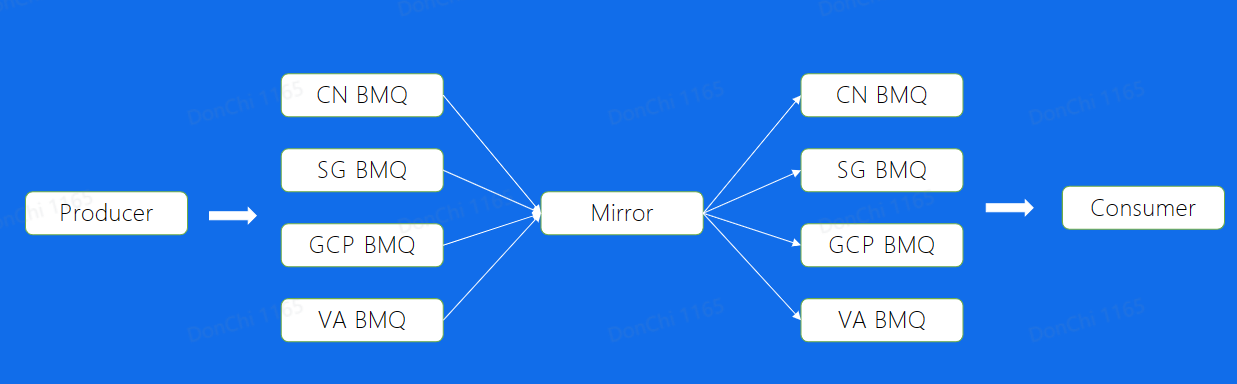
保持最终一致的解决思想,解决跨Region读写问题,可能无法保证时效性
Index
通过非Offset和时间戳的方式查询Message,而是其他业务字段
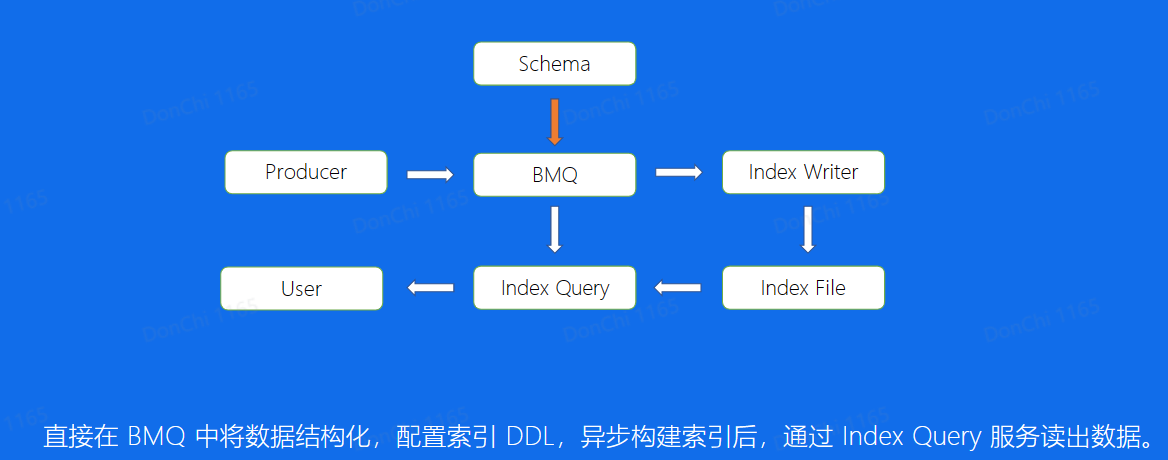
Parquet
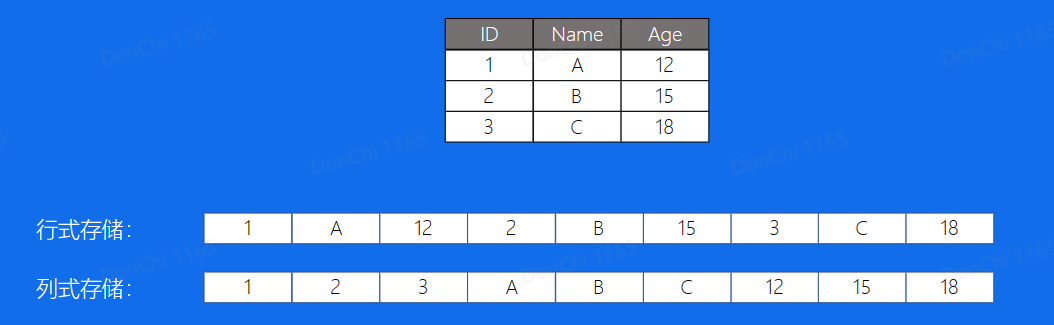
Apache Parquet:列式存储结构
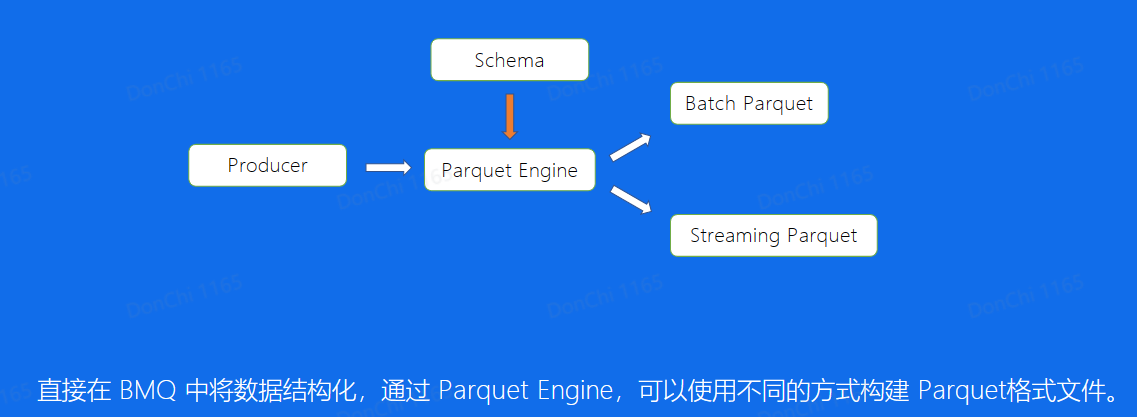
使用Parquet解决Index中的业务字段查询问题
RocketMQ
与Kafka的概念区别
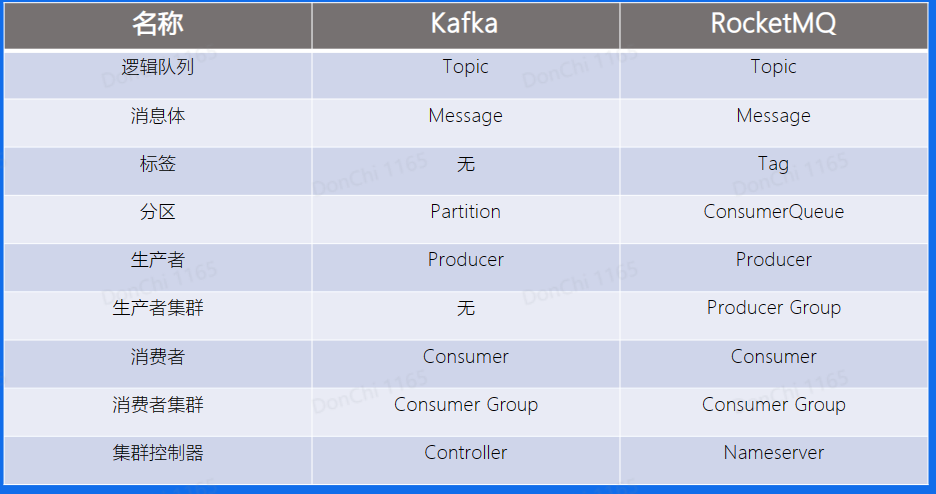
RocketMQ的基本概念
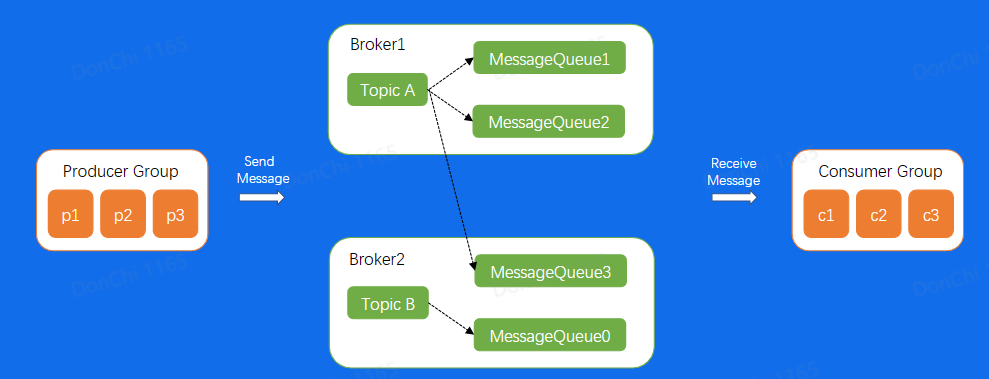
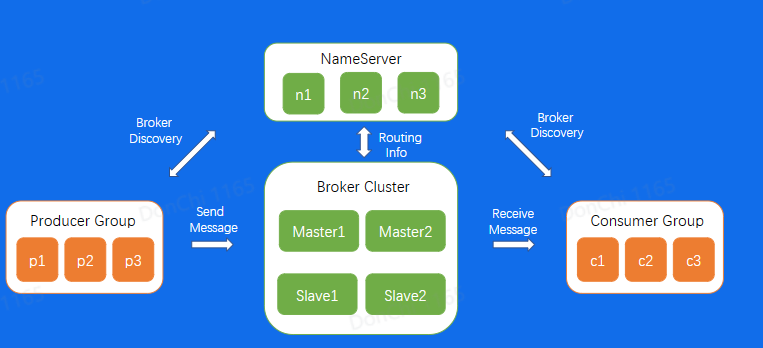
RocketMQ架构
数据流也是通过Producer发送给Broker集群,再由Consumer进行消费
Broker节点有Master和Slave的概念
NameServer为集群提供轻量级服务发现和路由
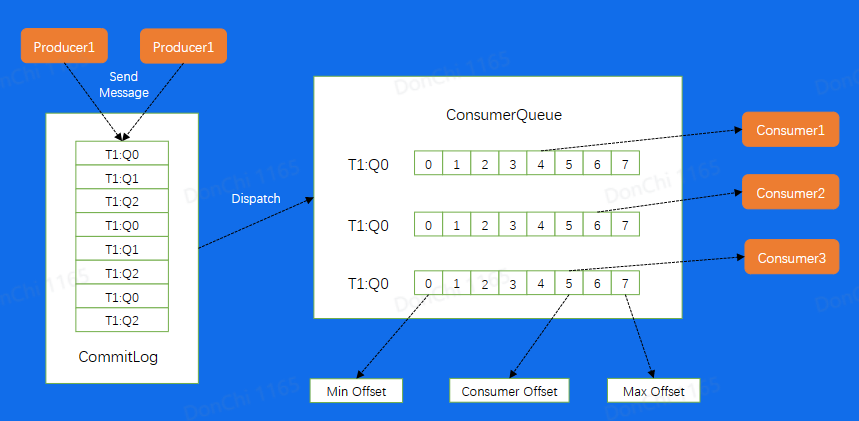
存储模型
对于一个Broker而言,所有消息都会添加到一个CommitLog之上,然后按照不同Queue重新Dispatch到不同的Consumer中。其中ConsuemrQueue不是存储真正的数据,而是消息在CommitLog上的位置,相当于是Queue的密集索引。
高级特性
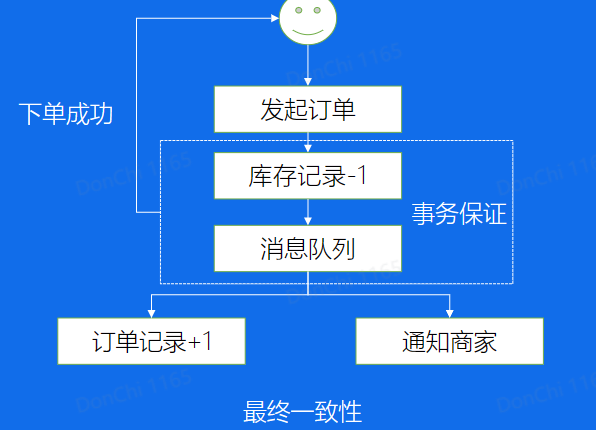
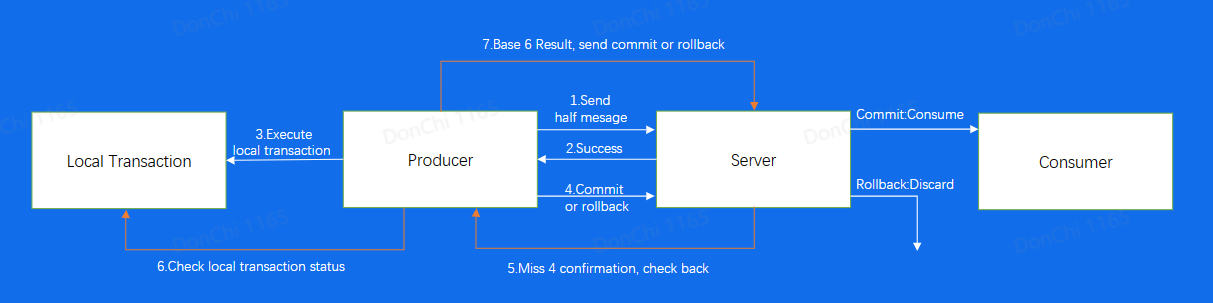
事务消息
延迟发送
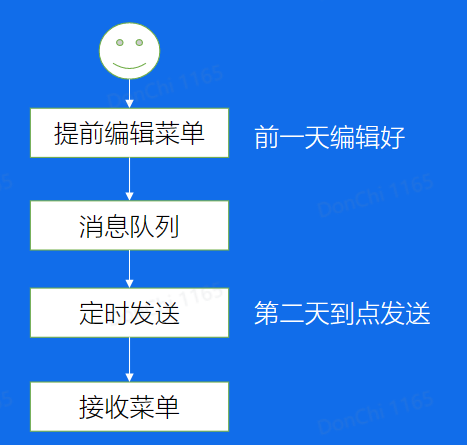
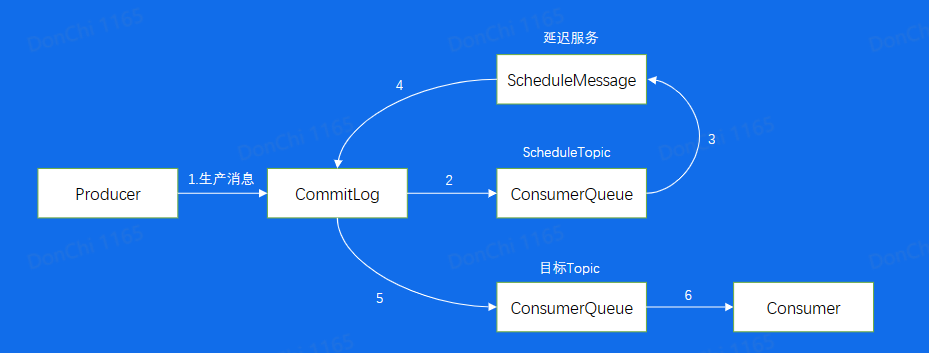
当延迟消息进入CommitLog后,由于特殊格式而被ConsumerQueue这个ScheduleTopic拉取,进行执行延迟服务,到了服务时间,再将消息重新包装成正常的消息,发送回CommitLog。此时就可以被目标Topic拉取了。
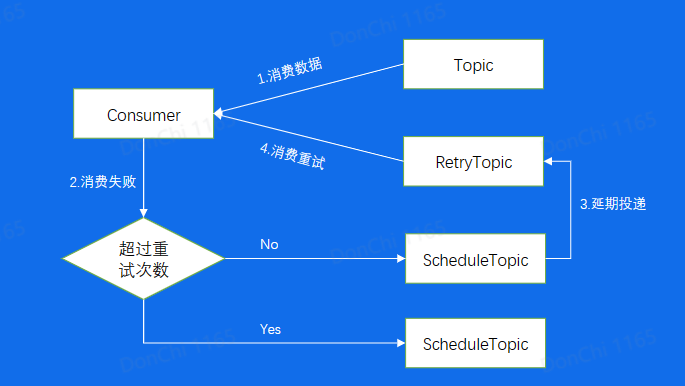
消费重试和死信队列
对于处理失败的消息,使用死信队列处理
引用参考
走进消息队列 副本.pptx - 飞书云文档 (feishu.cn)
