

At the database layer, sharding and replication are widely used approaches to scale out the database system. However, if we only rely on a cluster of DB instances to serve all read and write traffic, we will quickly get into problems such as high resource footprint, long request-handling latency, etc. Many production systems have uneven read/write traffic distribution. User-facing apps, in particular, may have orders of magnitude higher read traffic than write traffic. Cache is widely used to offload traffic from DB in such cases, while in the mean time reduce the request-handling latency, which helps to optimize user interaction experience.
From CAP principle, we know that a distributed system cannot achieve consistency, availability and resistance to network partition at the same time. In the real world, network partition can hardly be avoided, that is, a system can only choose either consistency or availability but not both when network partitioning happens. Cache systems are no exception to this rule, and how to design for cache consistency is always a key issue for any backend system.
Cache consistency may involve multiple storage systems: there is data consistency between cache and DB (ground truth), and there is data consistency between multiple layers of cache. Let’s focus on the first category of cache consistency in this post. Data consistency between cache and DB sometimes is called “double-write” consistency, because the same data is stored in the DB, as well as in the cache.
Further, there are different consistency levels. Strong consistency usually means if we read a data record immediately after write (could be write from other clients), we should see the data just wrote. In contrast, other weak consistency levels do not provide such guarantee — as stale read may happen. The most widely used weak consistency level is eventual consistency, meaning that the system only guarantees that after some time since the write succeeded, client then should be able to read that data record. There are other weak consistency levels as well, such as “read-your-own-write”, which provides stronger consistency guarantee, but lower than strong consistency. Eventual consistency is usually acceptable for most cache systems. Even though eventual consistency is a very “weak” consistency level, it still requires a good amount of careful design, otherwise the system will end in a “perpetual inconsistent” state.
Design for eventual consistency in cache-aside systems
Cache-aside is the most widely used cache architecture. In this architecture, the client communicates with both DB and cache, while DB and cache do not directly communicate.
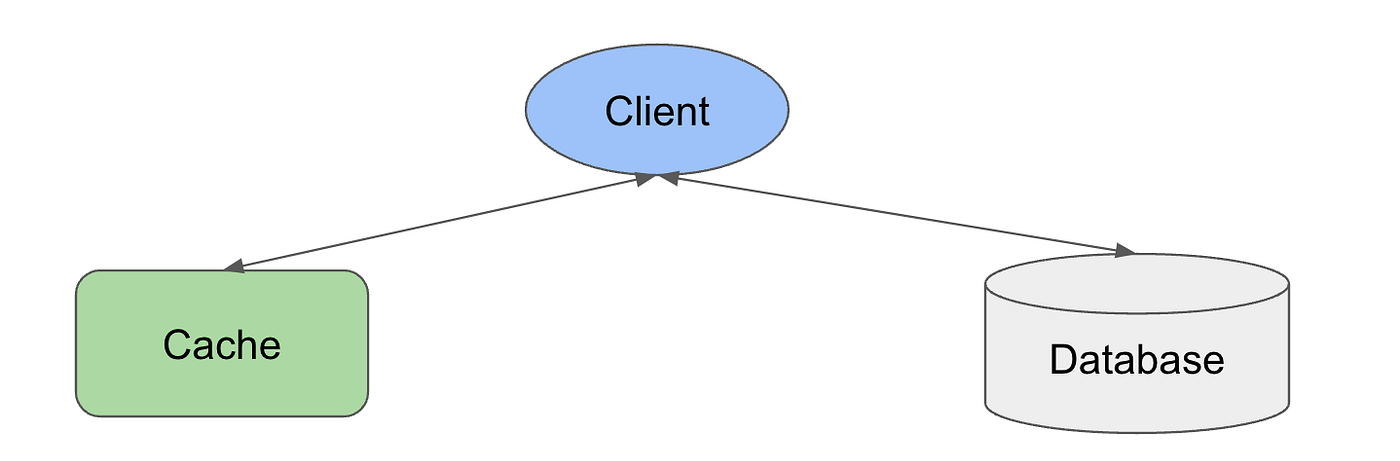
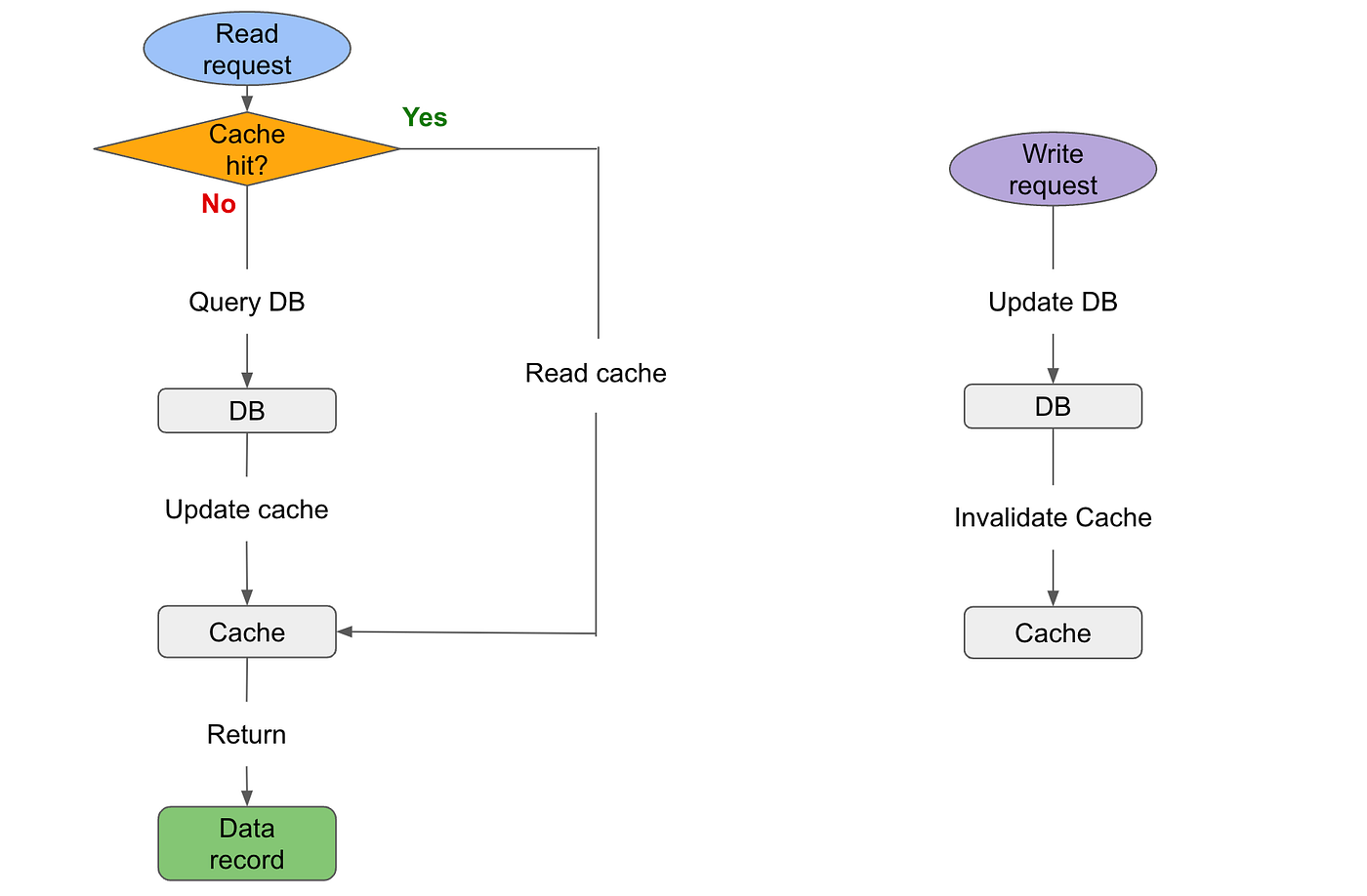
To ensure eventual consistency in cache-aside systems:
- Read request: the client first sends a request to the cache. If it is cache hit, meaning that the cache contains the requested data records, then the data in the cache will be returned. If it is cache miss, client then sends the request to DB. Once DB returns the requested data, client will update the cache as well.
- Write request: client directly writes to the DB, then invalidates (deletes) the data record in the cache if it also contains the key.
1. Why delete the cache record, rather than update it while handling write request?
The logic to handle read request should be straightforward. For write request, why invalidate the cache entry, rather than update it? While updating the cache after write may make more sense at the first glance, it may lead to some other problems.
Performance penalty
In many cases, a data object requested at the API layer is computed from records in multiple DB tables that are correlated by foreign key references. Join multiple tables on the request handling critical path can be slow, so usually we pre-compute the joined data records and store them in the cache. When such a request hits the cache, a simple KV lookup can fulfill the request, no expensive table join is needed. Under this scenario, if we choose to update the cache when only one DB table is changed, it will lead to unnecessary reads to other DB tables, and expensive join operation across these tables.
Further, for systems with high write QPS, if we update the cache eagerly in every write, it is possible that no read traffic ever hits the updated record in the cache before it is updated again by another write. In such cases, the first cache update is useless since it never served any read requests, but consumes machine resources.
Commonly used practice is to “lazily” update the cache. In other words, only when a read request encounters a cache miss, then we update the cache. i.e. only when the work is needed, then we actually get it done. In a write request, we only invalidates the cache record by deleting it. Deletion is also “idempotent”, meaning that we can safely retry the cache invalidation should any error happens during write.
Data staleness
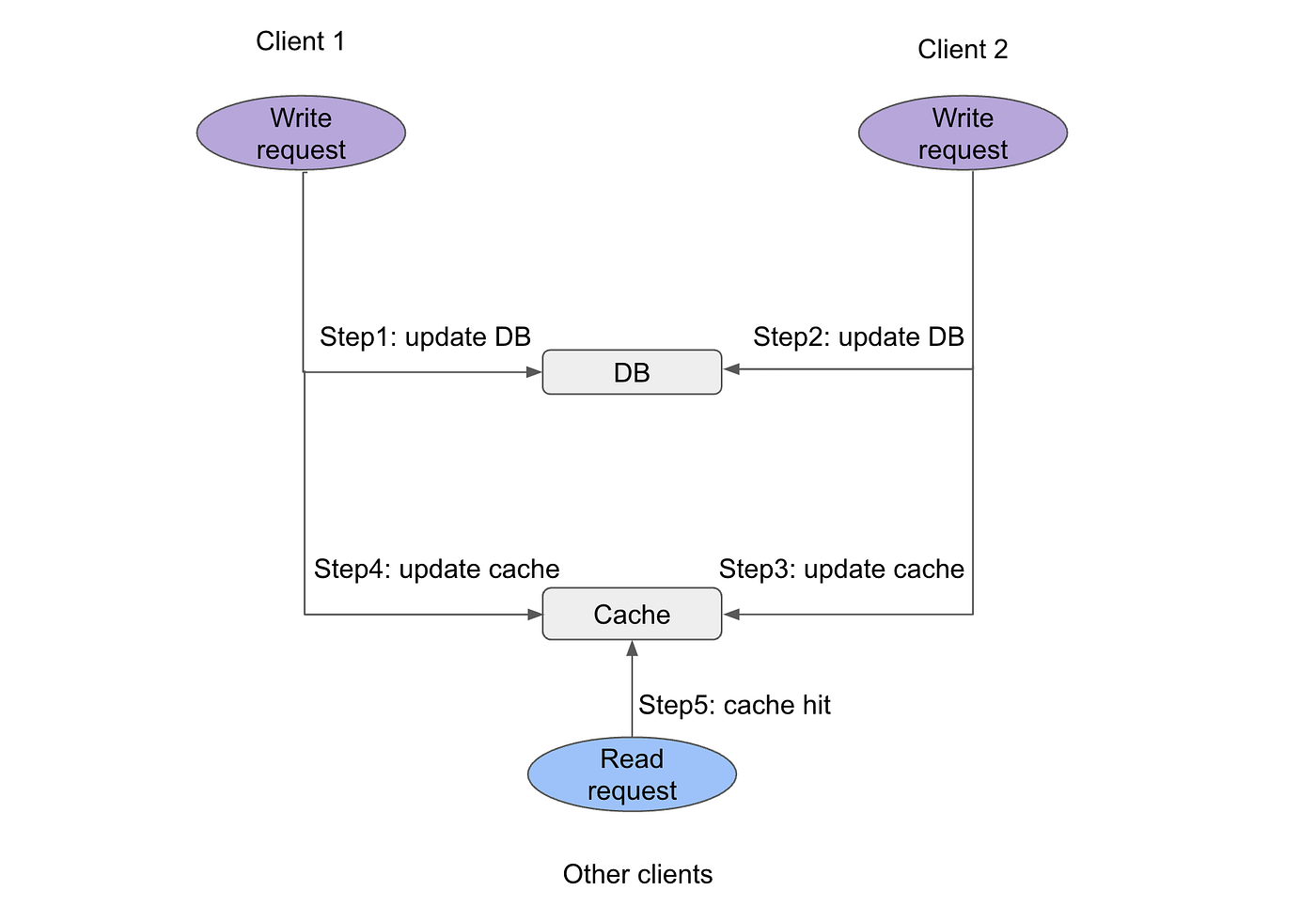
Update the cache during handling write request can also lead to data staleness issue in the cache (known as stale read), especially when the system has high write concurrency. For example, the diagram below shows a system handling two write requests. At step 1, the write request from client 1 updated the DB, then at step 2, another write request from client 2 updated the same data record in DB to a newer value. Due to network glitch, it is possible that client 2 updates the cache first, then client 1 updates the cache (step 3 happens before step 4). In this case, the DB stores newer value from client 2, while the cache stores the stale value from client 1. When a read request from other clients hits the cache, the stale value is returned to the client (step 5).
2. Why update the DB first, rather than invalidate the cache first?
Earlier we mentioned that in handling write request, we should update the DB first, then invalidate the cache. Why not do it in the reverse order? In a single thread situation, i.e. no concurrency, it is plausible to first invalidate the cache then update the DB. Should the cache invalidation succeeded but DB update failed, the system is still in a consistent state — a future read request can always read DB and put the newest value back to cache.
Again, problems occur under high write concurrency. Let’s take a look at the example shown below. At step 1, the write request from client 1 invalidates the cache. Then client 2 sends a read request, since it is cache miss, the request will hit DB. However, considering that usually write operation is slower than read, it is possible that client 2 first updates the cache (step 3), then client 1’s write request updates the DB (step 4). In this case, the DB stores newer value from client 1, while the cache stores old value read-and-updated by client 2. Similarly, cache lags behind the DB, and other clients only gets the stale value in read requests (step 5).

Further, cache invalidation means cache miss for subsequent reads. In extreme cases, DB may be overwhelmed by read requests after cache miss.
3. Let’s say we choose to invalidate cache first, then update DB. How to design for eventual consistency in this case?
“Delayed-delete” strategy is sometimes used to tackle the above-mentioned data staleness issue. In other words, besides the initial cache invalidation before DB update, another delete request is sent to cache to invalidate the data record again after DB update plus a certain time interval. This delayed delete should happen after any concurrent read request which may update the cache with stale value. From practical experience, the delay interval should be slightly higher than read request latency, and the delay can be implemented by sleep or delay queue. However, there are always situations causing the read requests to take longer than usual to complete. It will be difficult to match the delay interval precisely with the read latency.

4. Let’s say we follow the guideline to update DB first, then invalidate cache. Could data inconsistency still happen?
The short answer is yes. Let’s take a look at the following concurrency situation:
Client 1 sends a read request and get cache miss, and proceeds to query the DB, along with updating the cache entry afterwards. In the mean time, client 2 sends a write request to DB to change the same record client 1 is intended to read, and then proceeds to invalidate the cache entry. Let’s say for some reason, client 2’s cache invalidation happens before client 1'’s cache update (step 3 happens before step 4). In this case, client 1 writes the stale value back to cache, while the DB has the newer value from client 2. Other clients will experience stale read.
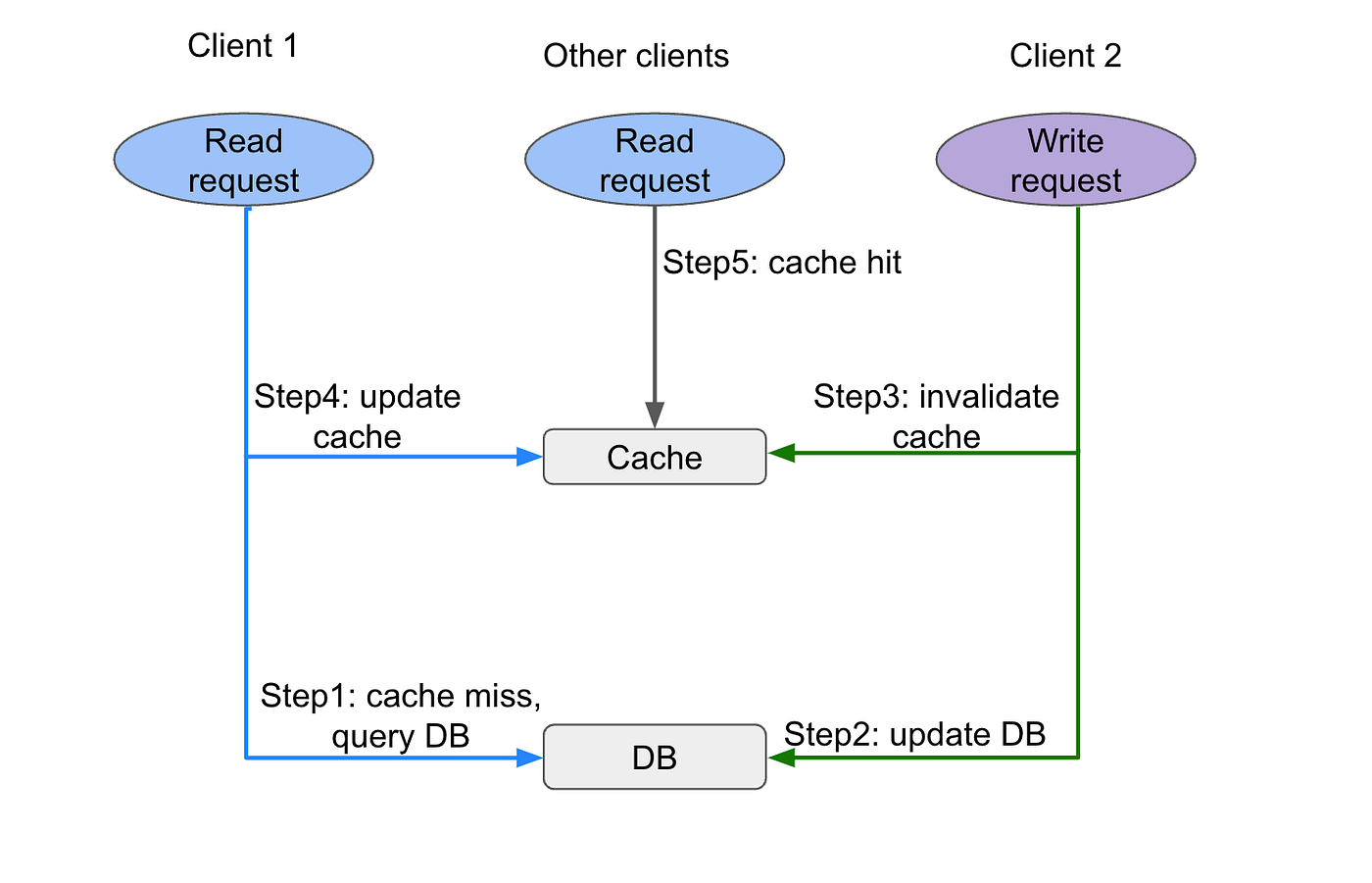
In reality, this concurrency situation happens very rarely. It requires cache miss and concurrent read & write on the same key, plus read request’s DB query happens before write request’s DB update, plus write request’s cache invalidation happens before read request’s cache backfill. The probability for all these preconditions to happen all at once is extremely small.
In addition, let’s say the system has very high read QPS. Since write request actually involves two steps: update DB, then invalidate cache, it is possible that some read requests hit the cache after a write request update the DB, but before it has time to invalidate the cache. All the read requests happens in between will read stale value.
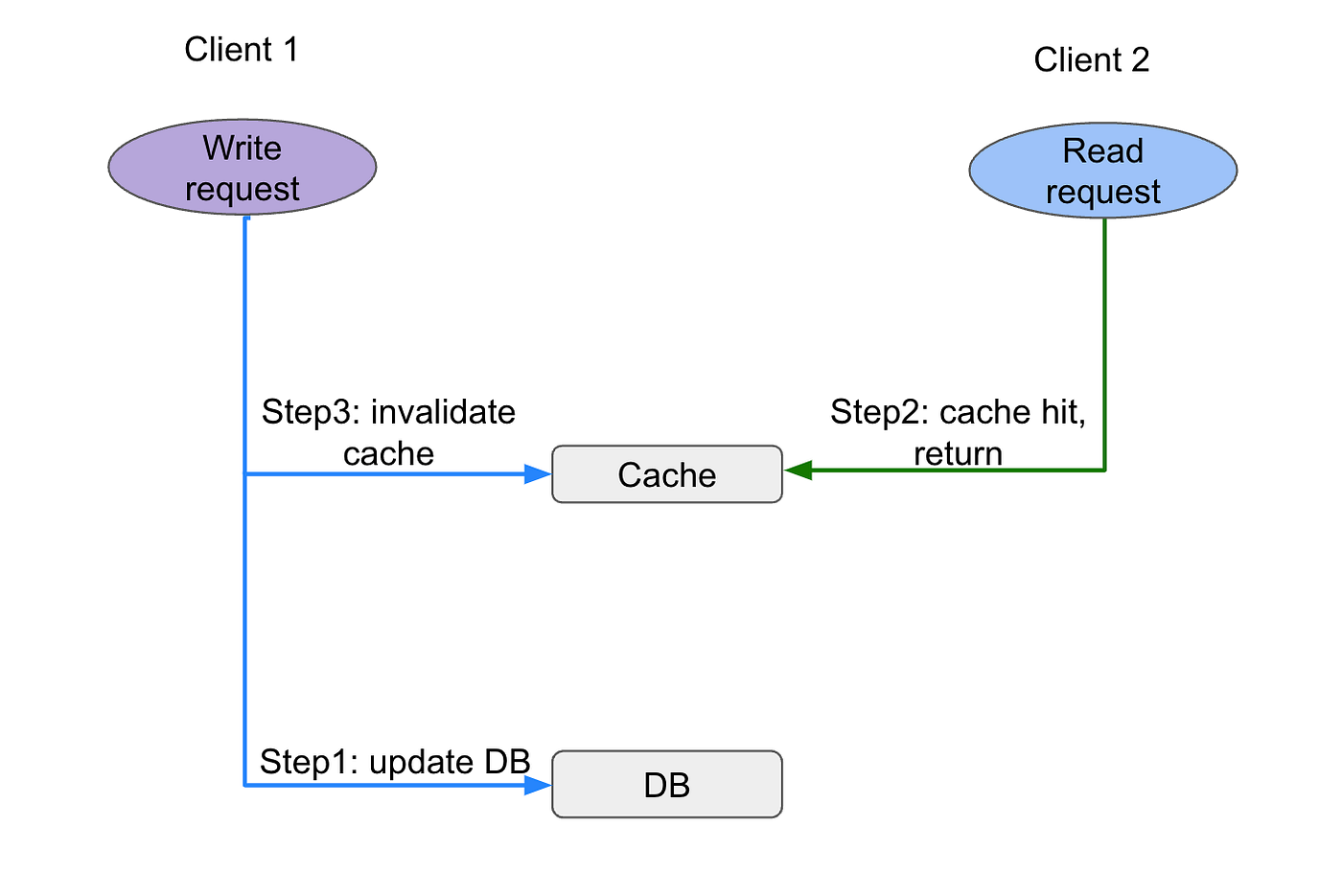
In such case, the next read (after cache invalidation) will hit DB and then backfill the cache with correct new value. While sufficient for most business cases, it may cause problems for business cases with strict consistency requirements. We can add locks to make the write request atomic, so that read requests are not served “in-between” write operation, rather, all shall wait for the lock release which happens after cache invalidation. The tradeoff is that the read throughput the system can handle will be lower due to overhead for acquiring & releasing lock.
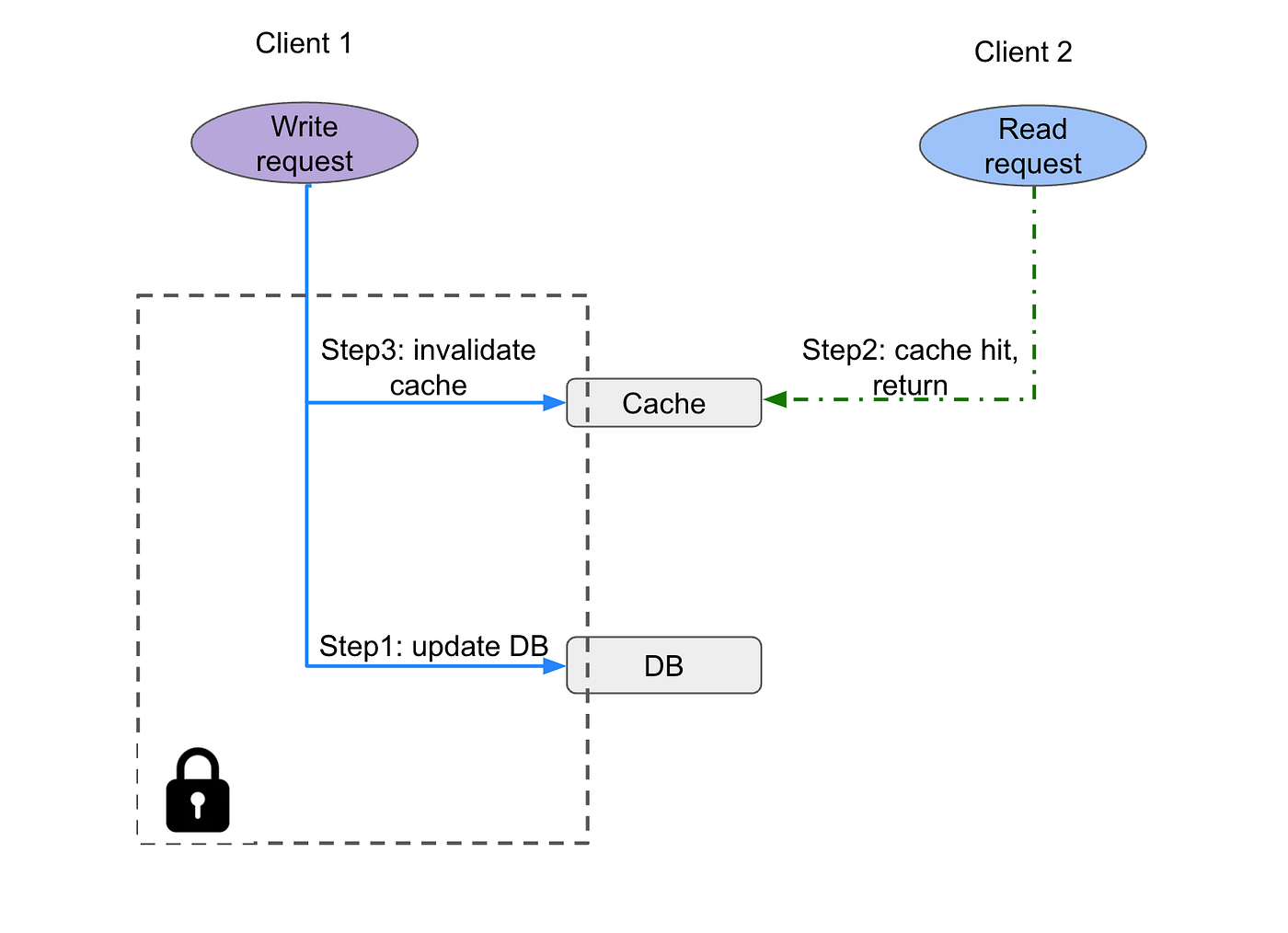
Step 2 cannot happen in-between step 1 and step 3 in this case
For more details on distributed lock, please refer to my Design distributed lock series.
Lock can also be used to coordinate read requests:
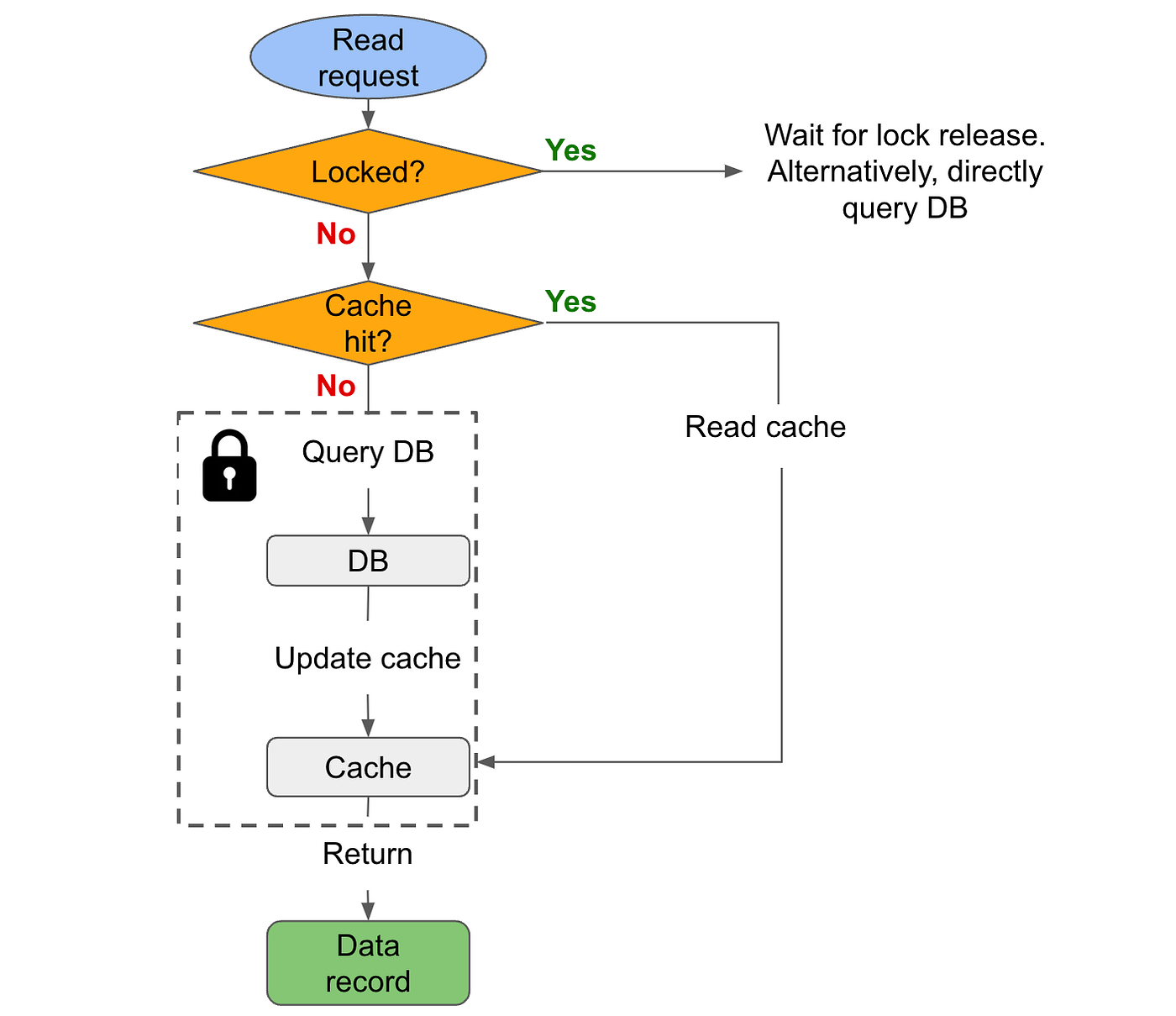
Add fallback strategies to bring system back to consistent state
Besides concurrent read & write, partial failures may also lead the system to an inconsistent (stale cache) state. For example, when the DB update succeeded but cache invalidation failed, stale read would still happen. Fallback strategies are commonly used to bring the cache system back to a consistent state in such cases. For more details, as well as other cache design architectures, please continue to read my post on
.
