

Python多处理和并行编程指南
加快计算速度是每个人都想实现的目标。如果你有一个脚本,它的运行速度可以比目前的运行时间快十倍呢?在这篇文章中,我们将了解Python多处理和一个叫做multiprocessing 的库。我们将讨论什么是多处理,它的优点,以及如何通过使用并行编程提高你的 Python 程序的运行时间。
好的,那么我们开始吧
并行性的介绍
在我们深入研究Python代码之前,我们必须先谈谈并行计算,这是计算机科学中的一个重要概念。
通常,当你运行一个Python脚本时,你的代码在某一时刻成为一个进程,这个进程在CPU的一个核心上运行。但是现代计算机有不止一个核心,那么如果你可以使用更多的核心进行计算呢?事实证明,你的计算会更快。
现在让我们把这作为一个普遍的原则,但在本文的后面,我们会看到这并不是普遍的事实。
在不涉及太多细节的情况下,并行性背后的想法是以这样一种方式编写你的代码,使其能够使用CPU的多个核心。
为了方便起见,让我们看一个例子。
并行和串行计算
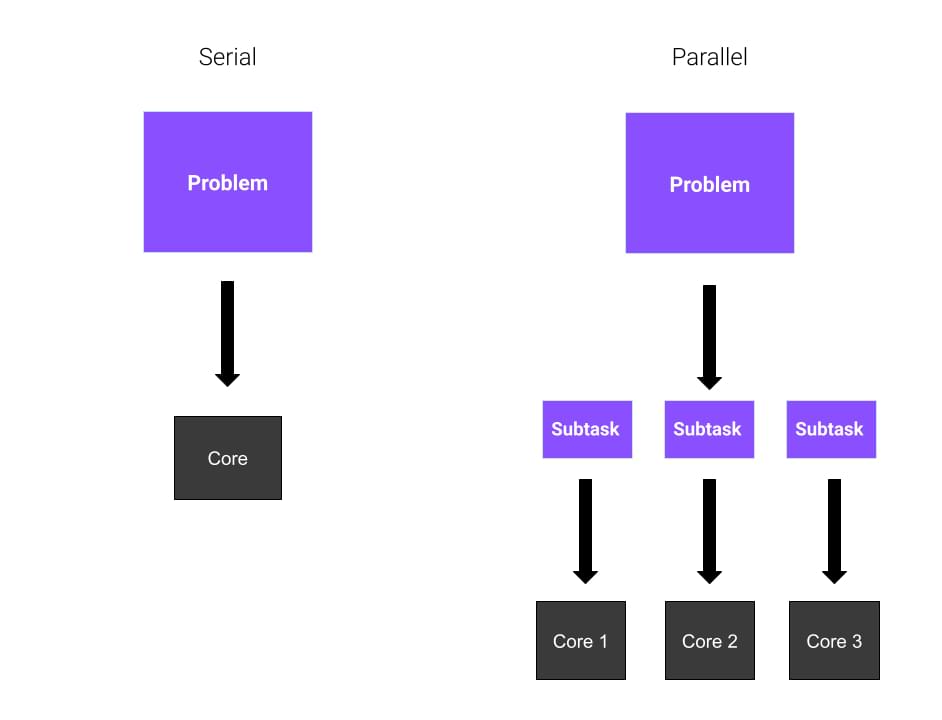
想象一下,你有一个巨大的问题要解决,而你是一个人。你需要计算八个不同数字的平方根。你会怎么做呢?嗯,你没有太多的选择。你从第一个数字开始,并计算出结果。然后,你再继续计算其他的。
如果你有三个擅长数学的朋友愿意帮助你呢?他们每个人都会计算两个数字的平方根,而你的工作会更容易,因为工作量在你的朋友之间平均分配。这意味着你的问题会得到更快的解决。
好了,都清楚了吗?在这些例子中,每个朋友代表CPU的一个核心。在第一个例子中,整个任务是由你按顺序解决的。这被称为串行计算。在第二个例子中,由于你总共使用了四个核心,所以你使用的是并行计算。并行计算涉及到并行进程的使用,或在一个处理器的多个核心之间划分的进程。
并行编程的模型
我们已经确定了什么是并行编程,但我们如何使用它?好吧,我们之前说过,并行计算涉及在处理器的多个核心之间执行多个任务,也就是说,这些任务是同时执行的。在接近并行化之前,有几个问题是你应该考虑的。例如,是否有其他优化措施可以加快我们的计算速度?
现在,让我们想当然地认为并行化是最适合你的解决方案。在并行计算中主要有三种模式:
- 完美并行:任务可以独立运行,它们不需要相互沟通。
- 共享内存并行:程(或线程)需要通信,所以它们共享一个全局地址空间。
- 消息传递:进程在需要时需要共享消息。
在这篇文章中,我们将说明第一个模型,这也是最简单的。
Python多进程。Python中基于进程的并行性
在Python中实现并行的一种方法是使用多进程模块。multiprocessing 模块允许你创建多个进程,每个进程都有自己的 Python 解释器。出于这个原因,Python 多进程完成了基于进程的并行。
你可能听说过其他的库,比如threading ,它也是 Python 内置的,但它们之间有关键的区别。multiprocessing 模块创建新的进程,而threading 创建新的线程。
在下一节中,我们将看一下使用多进程的好处。
使用多进程的好处
以下是多进程的一些好处:
- 在处理CPU高度密集的任务时,可以更好地使用CPU
- 与线程相比,对子程序的控制更多
- 易于编码
第一个优点是与性能有关。由于多进程会产生新的进程,你可以通过在其他核心之间分配任务,更好地利用CPU的计算能力。现在大多数处理器都是多核处理器,如果你优化你的代码,就可以通过并行解决计算问题来节省时间。
第二个优势是看多处理的另一种方式,即多线程。不过线程不是进程,这有其后果。如果你创建了一个线程,杀死它甚至中断它都是很危险的,就像你对一个正常进程所做的那样。由于多进程和多线程之间的比较不在本文的范围内,我鼓励你进一步阅读这方面的内容。
多进程的第三个优点是,鉴于你要处理的任务适合于并行编程,它的实现相当容易。
开始使用 Python 多处理
我们终于准备好写一些Python代码了!
我们将从一个非常基本的例子开始,我们将用它来说明Python多处理的核心内容。在这个例子中,我们将有两个进程:
parent进程。只有一个父进程,它可以有多个子进程。child进程。这是由父进程催生的。每个子进程也可以有新的子进程。
我们要用child 进程来执行某个函数。这样,parent 就可以继续执行了。
一个简单的Python多进程例子
下面是我们将用于这个例子的代码:
from multiprocessing import Process
def bubble_sort(array):
check = True
while check == True:
check = False
for i in range(0, len(array)-1):
if array[i] > array[i+1]:
check = True
temp = array[i]
array[i] = array[i+1]
array[i+1] = temp
print("Array sorted: ", array)
if __name__ == '__main__':
p = Process(target=bubble_sort, args=([1,9,4,5,2,6,8,4],))
p.start()
p.join()
在这个片段中,我们定义了一个叫做bubble_sort(array) 的函数。这个函数是泡沫排序算法的一个非常幼稚的实现。如果你不知道它是什么,不要担心,因为这并不重要。关键是要知道它是一个做一些工作的函数。
进程类
从multiprocessing ,我们导入类Process 。这个类代表了一个将在独立进程中运行的活动。事实上,你可以看到我们已经传递了一些参数:
target=bubble_sort, 意味着我们的新进程将运行bubble_sort函数args=([1,9,4,52,6,8,4],),这是作为参数传递给目标函数的数组。
一旦我们创建了一个Process类的实例,我们只需要启动该进程。这可以通过编写p.start() 。在这一点上,进程已经开始了。
在我们退出之前,我们需要等待子进程完成其计算。join() 方法会等待进程的终止。
在这个例子中,我们只创建了一个子进程。正如你可能猜到的,我们可以通过在Process 类中创建更多的实例来创建更多的子进程。
池子类
如果我们需要创建多个进程来处理更多的CPU密集型任务怎么办?我们是否总是需要启动并明确地等待终止?这里的解决方案是使用Pool 类。
Pool 类允许你创建一个工作进程池,在下面的例子中,我们将看看如何能使用它。这就是我们的新例子:
from multiprocessing import Pool
import time
import math
N = 5000000
def cube(x):
return math.sqrt(x)
if __name__ == "__main__":
with Pool() as pool:
result = pool.map(cube, range(10,N))
print("Program finished!")
在这个代码片断中,我们有一个cube(x) 函数,它简单地接收一个整数并返回其平方根。很简单,对吗?
然后,我们创建一个Pool 类的实例,没有指定任何属性。池类默认为每个CPU核创建一个进程。接下来,我们运行带有一些参数的map 方法。
map 方法将cube 函数应用于我们提供的可迭代的每个元素--在本例中,它是一个从10 到N 的每个数字的列表。
这样做的巨大好处是,列表上的计算是平行进行的
充分利用 Python 的多处理功能
创建多个进程并进行并行计算并不一定比串行计算更有效率。对于低CPU密集型的任务,串行计算要比并行计算快。出于这个原因,了解什么时候应该使用多进程很重要--这取决于你要执行的任务。
为了让你相信这一点,让我们看一个简单的例子:
from multiprocessing import Pool
import time
import math
N = 5000000
def cube(x):
return math.sqrt(x)
if __name__ == "__main__":
# first way, using multiprocessing
start_time = time.perf_counter()
with Pool() as pool:
result = pool.map(cube, range(10,N))
finish_time = time.perf_counter()
print("Program finished in {} seconds - using multiprocessing".format(finish_time-start_time))
print("---")
# second way, serial computation
start_time = time.perf_counter()
result = []
for x in range(10,N):
result.append(cube(x))
finish_time = time.perf_counter()
print("Program finished in {} seconds".format(finish_time-start_time))
这个片段是基于前面的例子。我们要解决的是同一个问题,即计算N 数字的平方根,但有两种方法。第一种涉及到Python多进程的使用,而第二种则不涉及。我们使用time 库中的perf_counter() 方法来衡量时间性能。
在我的笔记本电脑上,我得到这样的结果:
> python code.py
Program finished in 1.6385094 seconds - using multiprocessing
---
Program finished in 2.7373942999999996 seconds
正如你所看到的,有超过一秒钟的差异。所以在这种情况下,多处理的效果更好。
让我们改变代码中的一些东西,比如N 的值。让我们把它降低到N=10000 ,看看会发生什么。
这就是我现在得到的结果:
> python code.py
Program finished in 0.3756742 seconds - using multiprocessing
---
Program finished in 0.005098400000000003 seconds
发生了什么?现在看来,多处理是一个不好的选择。为什么呢?
与所解决的任务相比,在各进程之间分割计算所带来的开销太大。你可以看到在时间性能方面有多大的差别。
总结
在这篇文章中,我们谈到了通过使用Python多处理来优化Python代码的性能。
首先,我们简要介绍了什么是并行计算以及使用它的主要模式。然后,我们开始讨论多处理和它的优势。最后,我们看到并行计算并不总是最好的选择,应该使用multiprocessing 模块来并行处理CPU绑定的任务。像往常一样,这是一个考虑你所面临的具体问题并评估不同解决方案的利弊的问题。
我希望你在学习Python多处理时能像我一样有所收获。
