day05
scrapy框架介绍
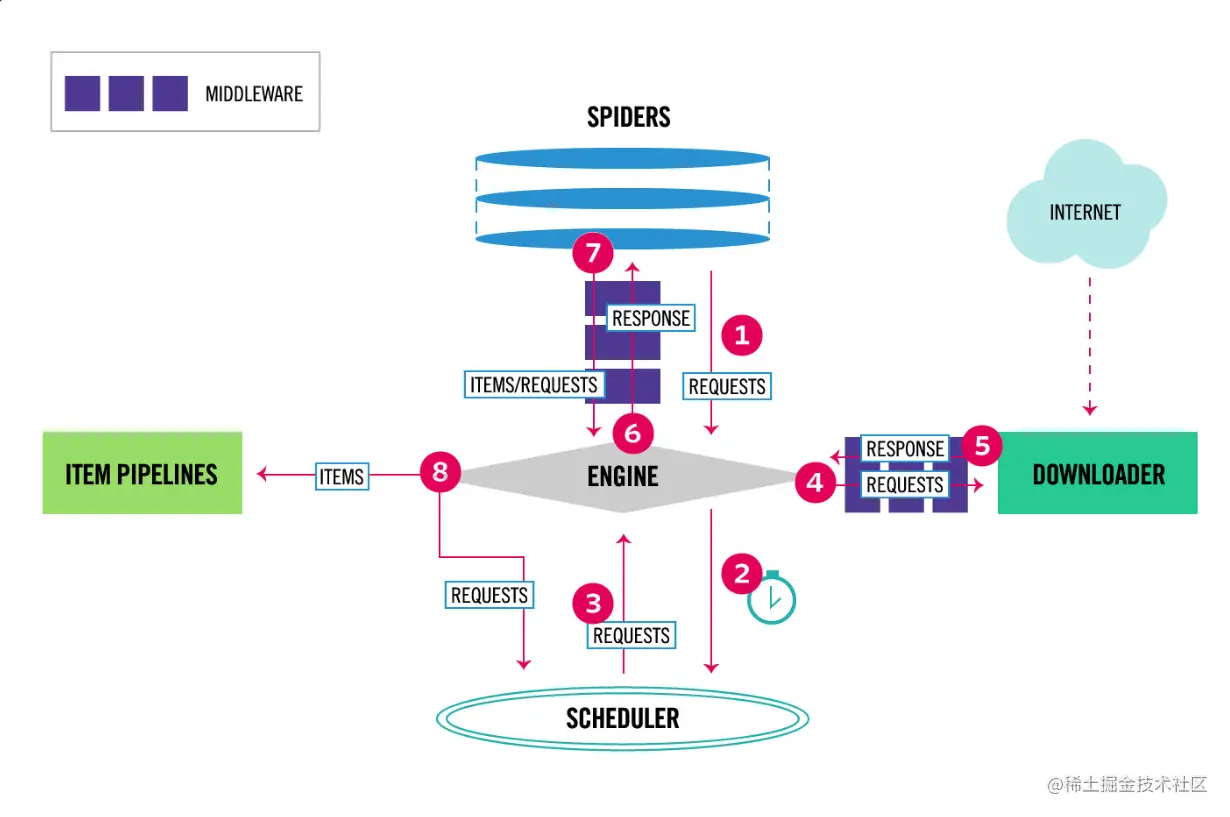
引擎负责控制系统所有组件之间的数据流,并在某些动作发生时触发事件。有关详细信息,请参见上面的数据流部分。
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL的优先级队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址
用于下载网页内容, 并将网页内容返回给EGINE,下载器是建立在twisted这个高效的异步模型上的
SPIDERS是开发人员自定义的类,用来解析responses,并且提取items,或者发送新的请求
在items被提取后负责处理它们,主要包括清理、验证、持久化(比如存到数据库)等操作
位于Scrapy引擎和下载器之间,主要用来处理从EGINE传到DOWLOADER的请求request,已经从DOWNLOADER传到EGINE的响应response,你可用该中间件做以下几件事:设置请求头,设置cookie,使用代理,集成selenium
位于EGINE和SPIDERS之间,主要工作是处理SPIDERS的输入(即responses)和输出(即requests)
scrapy解析数据
1 response对象有css方法和xpath方法
-css中写css选择器
-xpath中写xpath选择
2 重点1:
-xpath取文本内容
'.//a[contains(@class,"link-title")]/text()'
-xpath取属性
'.//a[contains(@class,"link-title")]/@href'
-css取文本
'a.link-title::text'
-css取属性
'img.image-scale::attr(src)'
3 重点2:
.extract_first() 取一个
.extract() 取所有
class CnblogsSpider(scrapy.Spider):
name = 'cnblogs'
allowed_domains = ['www.cnblogs.com']
start_urls = ['http://www.cnblogs.com/']
def parse(self, response):
article_list = response.xpath('//article[contains(@class,"post-item")]')
for article in article_list:
title_name = article.xpath('./section/div/a/text()').extract_first()
author_img = article.xpath('./section/div/p//img/@src').extract_first()
desc_list = article.xpath('./section/div/p/text()').extract()
desc = desc_list[0].replace('\n', '').replace(' ', '')
if not desc:
desc = desc_list[1].replace('\n', '').replace(' ', '')
author_name = article.xpath('./section/footer/a/span/text()').extract_first()
article_date = article.xpath('./section/footer/span/span/text()').extract_first()
print('''
文章标题:%s
作者头像:%s
摘要:%s
作者名字:%s
发布日期:%s
''' % (title_name,author_img,desc,author_name,article_date))
settings基础配置
ROBOTSTXT_OBEY = False
LOG_LEVEL='ERROR'
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36'
BOT_NAME = 'myfirstscrapy'
SPIDER_MODULES = ['myfirstscrapy.spiders']
NEWSPIDER_MODULE = 'myfirstscrapy.spiders'
增加爬取效率配置
默认scrapy开启的并发线程为32个,可以适当进行增加。在settings配置文件中修改
CONCURRENT_REQUESTS = 100
值为100,并发设置成了为100。
在运行scrapy时,会有大量日志信息的输出,为了减少CPU的使用率。可以设置log输出信息为INFO或者ERROR即可。在配置文件中编写:
LOG_LEVEL = 'INFO'
如果不是真的需要cookie,则在scrapy爬取数据时可以禁止cookie从而减少CPU的使用率,提升爬取效率。在配置文件中编写:
COOKIES_ENABLED = False
对失败的HTTP进行重新请求(重试)会减慢爬取速度,因此可以禁止重试。在配置文件中编写:
RETRY_ENABLED = False
如果对一个非常慢的链接进行爬取,减少下载超时可以能让卡住的链接快速被放弃,从而提升效率。在配置文件中进行编写:
DOWNLOAD_TIMEOUT = 10 超时时间为10s
持久化方案
将数据保存起来--->持久化
-第一种:了解
-解析函数中parse,要return [{},{},{}]
-scrapy crawl cnblogs -o 文件名(json,pickle,csv结尾)
-方案二:使用pipline 常用的,管道形式,可以同时存到多个位置的
-1 在items.py中写一个类[相当于写django的表模型],继承scrapy.Item
-2 在类中写属性,写字段,所有字段都是scrapy.Field类型
title = scrapy.Field()
-3 在爬虫中导入类,实例化得到对象,把要保存的数据放到对象中
item['title'] = title 【不要使用. 放】
解析类中 yield item
-4 修改配置文件,指定pipline,数字表示优先级,越小越大
ITEM_PIPELINES = {
'crawl_cnblogs.pipelines.CrawlCnblogsPipeline': 300,
}
-5 写一个pipline:CrawlCnblogsPipeline
-open_spider:数据初始化,打开文件,打开数据库链接
-process_item:真正存储的地方
-一定不要忘了return item,交给后续的pipline继续使用
-close_spider:销毁资源,关闭文件,关闭数据库链接
cnblogs.py
import scrapy
from myfirstscrapy.items import CnblogsItem
class CnblogsSpider(scrapy.Spider):
name = 'cnblogs'
allowed_domains = ['www.cnblogs.com']
start_urls = ['https://www.cnblogs.com/']
def parse(self, response):
article_list = response.css('article.post-item')
for article in article_list:
item = CnblogsItem()
title_name = article.css('section>div>a::text').extract_first()
article_url = article.css('section>div>a::attr(href)').extract_first()
author_img = article.css('section>div>p>a>img::attr(src)').extract_first()
desc_list = article.css('section>div>p::text').extract()
description = desc_list[0].replace('\n', '').replace(' ', '')
if not description:
description = desc_list[1].replace('\n', '').replace(' ', '')
author_name = article.css('section>footer>a>span::text').extract_first()
article_time = article.css('section>footer>span>span::text').extract_first()
item['title_name'] = title_name
item['article_url'] = article_url
item['author_img'] = author_img
item['description'] = description
item['author_name'] = author_name
item['article_time'] = article_time
yield item
pass
pipelines.py
import pymysql
from itemadapter import ItemAdapter
class CnblogsFilesPipeline:
def open_spider(self, spider):
print('爬虫起了')
self.f = open('cnblogs.txt', 'at', encoding='utf-8')
def process_item(self, item, spider):
self.f.write('''
文章标题:%s
文章链接:%s
作者头像:%s
摘要:%s
作者名字:%s
发布日期:%s
\n
''' % (
item['title_name'], item['article_url'], item['author_img'], item['description'], item['author_name'],
item['article_time']))
return item
def close_spider(self, spider):
print('爬虫关闭')
self.f.close()
class CnblogsMysqlPipeline:
def open_spider(self, spider):
self.conn = pymysql.connect(
user='root',
password='',
host='127.0.0.1',
database='cnblogs',
port=3306
)
self.cursor = self.conn.cursor()
def process_item(self, item, spider):
self.cursor.execute(
'insert into article(title_name,article_url,author_img,description,author_name,article_time,article_content)values(%s,%s,%s,%s,%s,%s,%s)',
args=[item['title_name'], item['article_url'], item['author_img'], item['description'], item['author_name'],
item['article_time'], '', ])
self.conn.commit()
def close_spider(self, spider):
self.cursor.close()
self.conn.close()
print('爬虫关闭')
items.py
import scrapy
class MyfirstscrapyItem(scrapy.Item):
pass
class CnblogsItem(scrapy.Item):
title_name = scrapy.Field()
article_url = scrapy.Field()
author_img = scrapy.Field()
description = scrapy.Field()
author_name = scrapy.Field()
article_time = scrapy.Field()
article_content = scrapy.Field()
全栈爬取cnblogs文章
1 继续爬取下一页:解析出下一页的地址,包装成request对象
2 继续爬取详情页:解析出详情页地址,包装成request对象
request和response对象传递参数
yield Request(url=url, callback=self.detail_parse,meta={'item':item})
yield item
解析下一页并基础爬取
import scrapy
from bs4 import BeautifulSoup
from myfirstscrapy.items import CnblogsItem
from scrapy import Request
class CnblogsSpider(scrapy.Spider):
name = 'cnblogs'
allowed_domains = ['www.cnblogs.com']
start_urls = ['http://www.cnblogs.com/']
def parse(self, response):
article_list = response.xpath('//article[contains(@class,"post-item")]')
for article in article_list:
item = CnblogsItem()
title_name = article.xpath('./section/div/a/text()').extract_first()
author_img = article.xpath('./section/div/p//img/@src').extract_first()
desc_list = article.xpath('./section/div/p/text()').extract()
desc = desc_list[0].replace('\n', '').replace(' ', '')
if not desc:
desc = desc_list[1].replace('\n', '').replace(' ', '')
author_name = article.xpath('./section/footer/a/span/text()').extract_first()
article_date = article.xpath('./section/footer/span/span/text()').extract_first()
url = article.xpath('./section/div/a/@href').extract_first()
item['title_name'] = title_name
item['author_img'] = author_img
item['desc'] = desc
item['author_name'] = author_name
item['article_date'] = article_date
item['url'] = url
yield Request(url=url, callback=self.detail_parse,meta={'item':item})
next_url = 'https://www.cnblogs.com' + response.css('div.pager>a:last-child::attr(href)').extract_first()
print(next_url)
yield Request(url=next_url, callback=self.parse)
def detail_parse(self, response):
item=response.meta.get('item')
article_content=response.css('div.post').extract_first()
item['article_content']=str(article_content)
yield item
爬虫和下载中间件
MyfirstscrapySpiderMiddleware
def process_spider_input(self, response, spider):
def process_spider_output(self, response, result, spider):
def process_spider_exception(self, response, exception, spider):
def process_start_requests(self, start_requests, spider):
def spider_opened(self, spider):
MyfirstscrapyDownloaderMiddleware
def process_request(self, request, spider):
def process_response(self, request, response, spider):
def process_exception(self, request, exception, spider):
def spider_opened(self, spider):
-返回值:
- return None: 继续执行下面的中间件的process_request
- return a Response object: 不进入下载中间件了,直接返回给引擎,引擎把它通过6给爬虫
- return a Request object:不进入中间件了,直接返回给引擎,引擎把它放到调度器中
- raise IgnoreRequest: process_exception() 抛异常,会执行process_exception
-返回值:
- return a Response object:正常,会进入到引擎,引擎把它给爬虫
- return a Request object: 会进入到引擎,引擎把它放到调度器中,等待下次爬取
- raise IgnoreRequest 会执行process_exception


