

在这篇文章中,我们将学习如何用不同的方法监测SQL Server阻塞问题。
在SQL Server中是如何发生阻塞的?
在关系型数据库中,许多用户事务被并发处理。在这种情况下,不同的事务同时访问同一个表的记录是一种不可避免的情况。SQL Server使用锁机制来保护数据的完整性,因为一个资源可以被不同的事务同时修改。锁机制并不是一个问题,它是一种提供数据完整性的方法。然而,当一个资源被锁定,其他进程开始长时间等待该资源时,锁可能会导致问题的出现。
数据库引擎决定在执行语句时应该访问哪些资源。在这个决定之后,锁管理器进入游戏,根据正在执行的操作类型和将被影响的数据量,决定适当的锁类型和锁的粒度(行、页和表)。根据执行的语句和隔离级别,SQL Server锁管理器可以为资源选择不同类型的锁。阻塞是一种等待状态,当一个资源或一组资源被一个进程获得了锁,然后另一个进程想锁定相同的资源时,这种状态就开始了。在这种情况下,第二个进程开始等待,直到释放锁定的对象。假设在默认隔离级别下,用户Alfa更新了Adventureworks数据库中SalesPerson 表中的一些行。User-Alfa的更新语句获得了对变化资源的独占锁。
BEGIN TRAN
UPDATE Sales.SalesPerson SET ModifiedDate =GETDATE()
WHERE BusinessEntityID BETWEEN 274 AND 280
WAITFOR DELAY '00:00:40'
ROLLBACK TRAN
在执行这个查询后,我们可以在以下查询的帮助下检查Adventureworks数据库中的锁定资源。这个查询包括sys.dm_tran_locks动态管理视图,这个视图返回SQL Server中当前活动的锁管理器资源信息。
SELECT *
FROM sys.dm_tran_locks
WHERE resource_database_id = (SELECT db.database_id
FROM sys.databases AS db
WHERE name = 'Adventureworks2017');

在默认的隔离模式下(read committed),读操作获得了资源的共享(S)锁。现在,User-Beta想要读取整个表,所以读取操作也需要读取更新的行,但是这些行已经被User-Alfa锁定。在这种情况下,User-Beta必须等待40秒来释放User-Alfa的资源,因为独占锁和共享锁类型发生冲突。
SELECT *
FROM Sales.SalesPerson;
在这个简单的例子之后,让我们看看有助于监控SQL Server阻塞问题的不同方法。
使用SQL Server锁等待类型来监控SQL Server阻塞问题
等待类型是SQL Server的主要性能指标之一,对确定性能问题的原因很有帮助。
以LCK*为前缀的等待类型表示SQL Server中的阻塞问题。锁的等待类型可以根据隔离级别或锁定的资源来改变。例如,如果我们在可序列化的隔离级别中执行我们的样本查询,等待类型表示LCK_M_RX_S等待类型。首先,我们将执行更新查询。
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
BEGIN TRANSACTION;
UPDATE Sales.SalesPerson
SET ModifiedDate = GETDATE()
WHERE BusinessEntityID BETWEEN 274 AND 280;
WAITFOR DELAY '00:00:40';
ROLLBACK TRAN;
作为第二步,我们将在一个单独的查询窗口中执行选择查询。
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
BEGIN TRAN;
SELECT *
FROM Sales.SalesPerson;
COMMIT TRAN;
我们将使用sp_whoisactive来监视活动事务的细节。
EXECUTE sp_whoIsActive @get_locks = 1

serializable是最严格的SQL隔离级别,因为这个隔离级别可以防止脏读、不可重复的读和幻象读。下表给出了锁等待类型的简短描述。
等待类型 | 描述 |
LCK_M_IX | 意图排他性 |
LCK_M_IU | 意图-更新 |
意思是说 | 意图分享 |
独家 | 独家 |
独家 | 更新-内部-独占 |
独家 | 更新型 |
独家 | 分享-内部-专属 |
独家分享 | 共享的更新意图 |
LCK_M_SCH_S | 模式的稳定性 |
LCK_M_SCH_M | 模式修改 |
架构修改 | 分享 |
LCK_M_RI_X | 范围-插入-排除 |
LCK_M_RI_U | 范围-插入-更新 |
列表 | 范围内插入-共享 |
LCK_M_RI_NL | 范围输入-NULL |
LCK_M_RX_X | 范围-排他性-排他性 |
独家更新 | 范围-排他性-更新 |
独家更新 | 范围排他性-共享 |
LCK_M_RS_U | 范围共享-更新 |
LCK_M_RS_S | 范围共享-共享 |
LCK_M_BU | 批量更新 |
因此,锁等待类型指导确定SQL Server阻塞问题,但并不直接指向历史上有问题的查询。
使用system_health扩展事件来监控SQL Server的阻塞问题
system_health是SQL Server的默认扩展事件会话。它是在数据库引擎启动时自动启动的。system_health 捕获任何在阻塞状态下等待超过30秒的会话。我们可以在以下查询的帮助下,报告超过30秒的阻塞查询。这个查询找到了system_health文件的存储位置,然后只解析这个XML数据的锁等待类型。
SELECT s.name, CAST(t.target_data AS XML).value( '(EventFileTarget/File/@name)[1]', 'VARCHAR(MAX)' ) AS fileName
INTO #EX_FilePath
FROM sys.dm_xe_sessions AS s
INNER JOIN
sys.dm_xe_session_targets AS t
ON s.address = t.event_session_address
WHERE t.target_name = 'event_file';
DECLARE @EventFileTarget AS NVARCHAR(500);
SELECT @EventFileTarget = fileName
FROM #EX_FilePath
WHERE name = 'system_health';
SELECT *
FROM(SELECT n.value( '(@name)[1]', 'varchar(50)' ) AS event_name,
n.value( '(@package)[1]', 'varchar(50)' ) AS package_name,
n.value( '(@timestamp)[1]', 'datetime2' ) AS [utc_timestamp],
n.value( '(data[@name="wait_type"]/text)[1]', 'nvarchar(max)' ) AS wait_type,
n.value( '(action[@name="session_id"]/value)[1]', 'bigint' ) AS session_id,
n.value( '(data[@name="duration"]/value)[1]', 'bigint' ) / 1000 AS duration_ms,
n.value( '(action[@name="sql_text"]/value)[1]', 'nvarchar(max)' ) AS sql_text
FROM
(
SELECT CAST(event_data AS XML) AS event_data
FROM sys.fn_xe_file_target_read_file( @EventFileTarget, NULL, NULL, NULL )
) AS ed
CROSS APPLY
ed.event_data.nodes( 'event' ) AS q(n)) AS TMP_TBL
WHERE event_name = 'wait_info'
AND wait_type LIKE 'LCK%'
ORDER BY utc_timestamp DESC;

这个选项的好处是可以看到有问题的查询和锁等待类型,而不需要额外的努力。尽管如此,system_health的缺点是,它只能捕捉到超过30秒的阻塞问题。
使用所有阻塞交易报告来监控SQL Server的阻塞问题
我们可以在SQL Server Management Studio(SSMS)中找到各种标准报告,帮助获得数据库引擎性能指标的细节。所有阻塞交易报告提供了当前阻塞和被阻塞交易的细节。为了找到这个报告,我们需要右键点击任何一个数据库,然后进行导航,如下图所示。
报告>常规报告> 所有阻断交易

这个报告显示了阻塞和被阻塞的会话,这个细节提供了一个优势,可以找出SQL Server阻塞链问题的头部阻塞者。在阻塞链中,一个查询锁定了一个资源,然后多个查询由于第一个查询锁定的资源而开始互相等待。因此,我们需要找出阻塞链问题中的头部阻塞者查询。这个报告可以帮助解决哪个查询是阻塞链的根本原因。

使用阻塞进程阈值选项来监控SQL Server的阻塞问题
我们可以使用阻塞进程阈值选项来报告阻塞查询等待时间超过指定值的情况。默认情况下,这个选项是禁用的,要启用这个选项,我们需要使用sp_configure系统过程。微软建议将这个值设置为至少5秒。在下面这个查询的帮助下,我们可以启用这个选项并将其设置为10秒。
EXEC sp_configure 'show advanced options', 1;
GO
RECONFIGURE;
GO
EXEC sp_configure 'blocked process threshold', 10;
GO
RECONFIGURE;
GO
EXEC sp_configure 'blocked process threshold'

在启用阻塞进程阈值选项后,我们需要创建一个扩展的事件会话来报告阻塞的进程。要做到这一点,我们需要使用blocked_process_session事件。首先,我们右击位于管理节点下的会话文件夹,然后点击新建会话向导。
在 "设置会话属性 "窗口,我们将给我们的会话起一个名字,然后点击 "下一步"。
我们选择 "不使用模板 "选项,跳过选择模板屏幕。
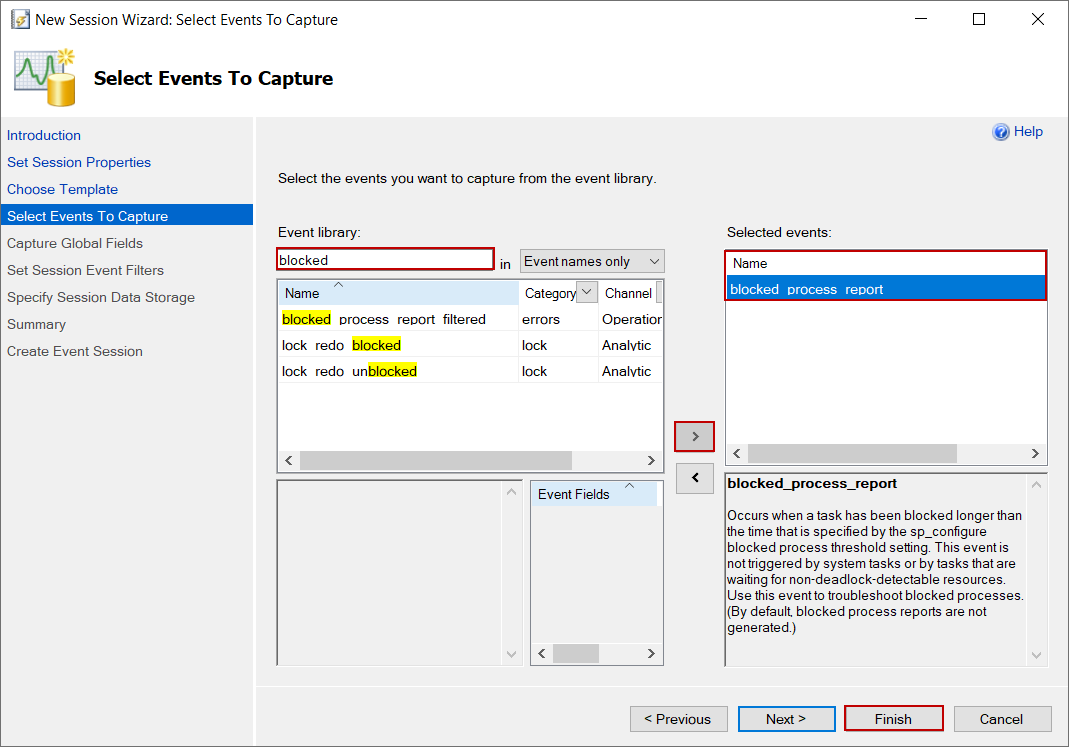
我们过滤blocked_process_report事件,并将其添加到选定的事件中。为了快速创建扩展事件会话,我们将点击完成按钮。当我们模拟一个阻塞的过程时,我们可以在观察实时数据屏幕上看到一个捕获的事件。
在扩展事件的最后一个屏幕上,我们点击立即开始事件会话,并在屏幕上观察捕获的实时数据。这样,会话立即开始,观察实时数据屏幕就会出现。
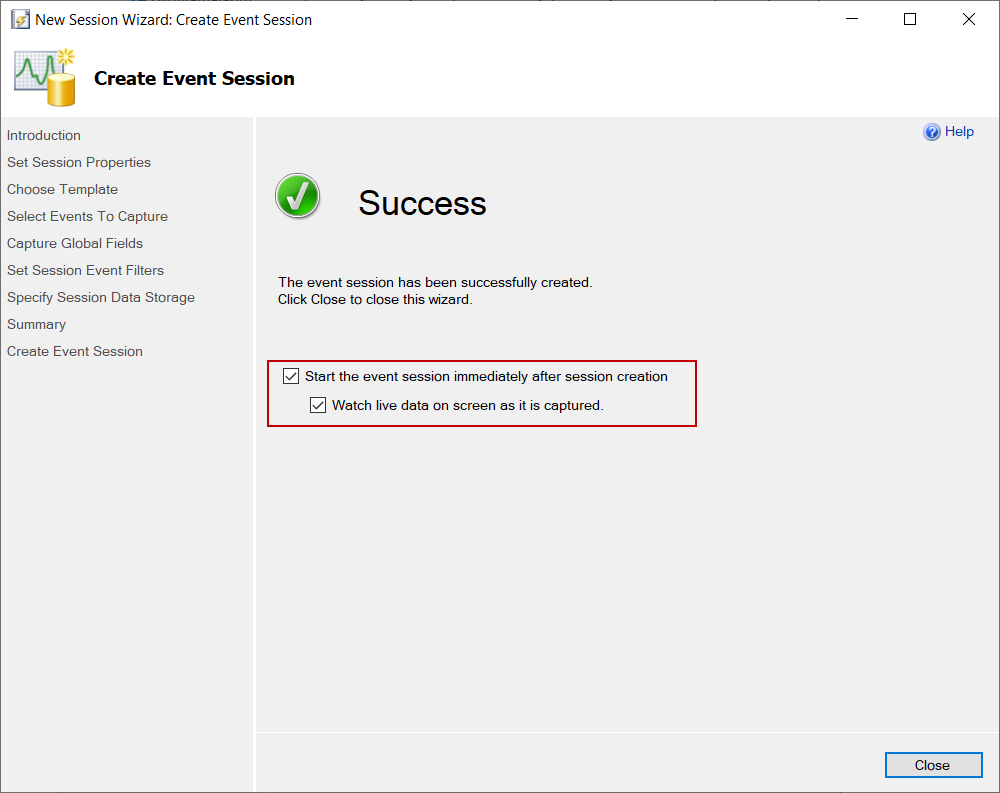
被阻断的进程将被这个会话捕获,但它们的等待时间必须超过被阻断进程的阈值。
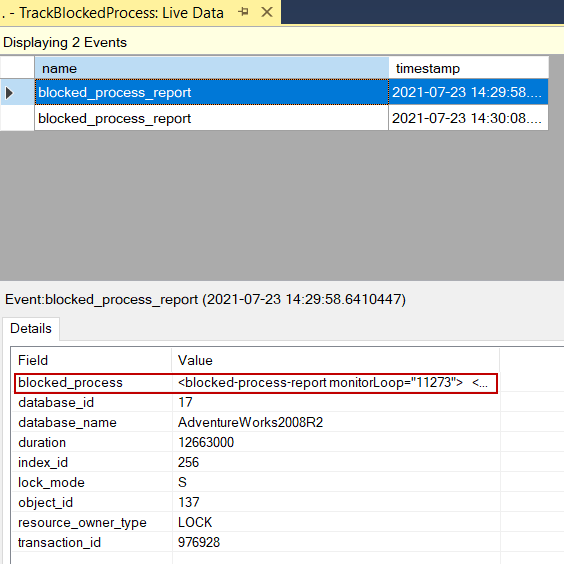
blocked_process字段显示一个XML报告。这个报告包括关于阻塞和被阻塞进程的所有细节。

总结
在这篇文章中,我们已经学会了一些不同的方法来监控SQL Server的阻塞问题。有时候,阻塞问题会让数据库管理员感到厌烦,因此监控这种类型的问题将有助于发现有问题的查询。
