

与关系型数据库不同,全文搜索并不是标准化的。有许多开源的选择,如ElasticSearch、Solr和Xapian。ElasticSearch可能是最流行的解决方案;但是,它的设置和维护很复杂。此外,如果你不利用ElasticSearch提供的一些高级功能,你应该坚持使用许多关系型数据库(如Postgres、MySQL、SQLite)和非关系型数据库(如MongoDB和CouchDB)提供的全文搜索功能。尤其是Postgres非常适合全文搜索。
对于绝大多数的Django应用程序来说,你至少应该从Postgres开始利用全文搜索,然后再寻找更强大的解决方案,如ElasticSearch或Solr。
在这篇文章中,我们将用Postgres为Django应用程序添加基本和全文搜索。
目标
在本文结束时,你应该能够。
- 用Q对象在Django应用程序中设置基本的搜索功能
- 在Django应用中添加全文搜索功能
- 使用词根、排名和加权,按相关性对全文搜索结果进行排序。
项目设置和概述
从django-searchrepo中克隆下来的基础分支。
$ git clone https://github.com/testdrivenio/django-search --branch base --single-branch
$ cd django-search
我们将使用Docker来简化Postgres和Django的设置和运行。
在项目根目录下,创建镜像并启动Docker容器。
$ docker-compose up -d --build
接下来,应用迁移并创建一个超级用户。
$ docker-compose exec web python manage.py makemigrations
$ docker-compose exec web python manage.py migrate
$ docker-compose exec web python manage.py createsuperuser
一旦完成,导航到http://127.0.0.1:8011/quotes/,以确保应用程序按预期运行。你应该看到以下内容。
注意quotes/models.py中的Quote 模型。
from django.db import models
class Quote(models.Model):
name = models.CharField(max_length=250)
quote = models.TextField(max_length=1000)
def __str__(self):
return self.quote
运行下面的管理命令,向数据库添加10,000个引言。
$ docker-compose exec web python manage.py add_quotes
这将需要几分钟的时间来运行。完成后,导航到http://127.0.0.1:8011/quotes/,查看数据。

在quote/templates/quote.html文件中,我们有一个带有搜索输入字段的基本表单。
<form action="{% url 'search_results' %}" method="get">
<input
type="search"
name="q"
placeholder="Search by name or quote..."
class="form-control"
/>
</form>
在提交时,搜索表单会发送一个GET ,而不是POST ,因此我们可以在URL和Django视图中访问查询字符串。让查询字符串出现在URL中,使我们能够将其作为一个链接与他人分享。
在继续前行之前,先看一下项目结构和其余的代码。
我们将通过看一下Q对象来开始我们的搜索之旅,它允许我们使用AND (&)或OR (|)逻辑运算符来搜索单词。
例如,要使用OR运算符,在quote/views.py中像这样覆盖SearchResultsList'的默认QuerySet 。
<form action="{% url 'search_results' %}" method="get">
<input
type="search"
name="q"
placeholder="Search by name or quote..."
class="form-control"
/>
</form>
在这里,我们使用过滤器方法来过滤name 或quote 字段。我们还使用了icontains来检查这个词是否包含在字段中(不区分大小写)。如果它被包含在其中,该字段将被返回。
不要忘记导入。
from django.db.models import Q
试试吧。

对于小的数据集,这是一个向你的应用程序添加基本搜索功能的好方法。一旦你的数据集变得很大,而且你要搜索的内容也很多,那么你就会想考虑添加全文搜索。
全文搜索
我们前面看到的基本搜索有一些问题,特别是当我们考虑与大型数据集匹配时。
第一个问题是停顿词的问题。这类词的例子是 "a"、"an "和 "the"。这些词很常见,而且意义不大,所以应该被忽略。为了测试,试着搜索一个前面带有 "the "的词。假设你搜索的是 "中间"。在这种情况下,你只会看到 "the middle "的结果,所以你不会看到任何有 "middle "这个词而前面没有 "the "的结果。
假设你有这两个句子。
- 我在中间。
- 你不喜欢中学。
每种类型的搜索你都会得到以下返回的结果。
| 查询 | 基本搜索 | 全文搜索 |
|---|---|---|
| "中学" | 句子1 | 句子1和2 |
| "中间" | 第1句和第2句 | 句子1和2 |
另一个问题是相似词的问题。在基本搜索中,只返回完全匹配的词。这是很有限的。通过全文搜索,我们可以把类似的词考虑进去。为了测试,试着找到一些类似的词,如 "小马 "和 "小马"。在基本搜索中,如果你搜索 "小马",你不会看到包含 "小马 "的结果,反之亦然。
假设你有这两个句子。
- 我是一匹小马。
- 你不喜欢小马
每种类型的搜索都会得到以下结果。
| 查询 | 基本搜索 | 全文搜索 |
|---|---|---|
| "小马" | 句子1 | 句子1和2 |
| "小马" | 第2句 | 第1句和第2句 |
有了全文检索,这两个问题都得到了缓解。请记住,根据你的搜索目标,全文搜索实际上可能会降低精确度(质量)和召回率(相关结果的数量)。通常情况下,全文搜索不如基本搜索精确,因为基本搜索会产生与搜索查询完全匹配的结果。也就是说,如果你要搜索有大量文本块的大型数据集,全文搜索是首选,因为它通常快得多。
全文搜索是一种先进的搜索技术,它在试图匹配搜索条件时检查每个存储文件中的所有单词。在全文搜索中,诸如 "a"、"and "和 "the "等停顿词被忽略,因为它们既常见又不够有意义。此外,通过全文搜索,我们可以对被索引的词采用特定语言的词干。例如,"drive"、"drive "和 "drive "将被记录在单一概念词 "drive "之下。词干化是将单词还原为其词干、词基或词根形式的过程。
可以说,全文搜索并不完美,其中一个问题是,它很可能检索到许多与预期搜索问题不相关的文件。然而,有一些基于贝叶斯算法的技术可以帮助减少这种问题。
为了利用Django的Postgres全文搜索的优势,请将django.contrib.postgres 加入你的INSTALLED_APPS 列表。
INSTALLED_APPS = [
...
"django.contrib.postgres", # new
]
接下来,让我们看看两个快速的全文搜索的例子,一个是单字段,一个是多字段。
单一字段搜索
像这样更新SearchResultsList 。
class SearchResultsList(ListView):
model = Quote
context_object_name = "quotes"
template_name = "search.html"
def get_queryset(self):
query = self.request.GET.get("q")
return Quote.objects.filter(quote__search=query)
这里,我们只搜索报价字段。
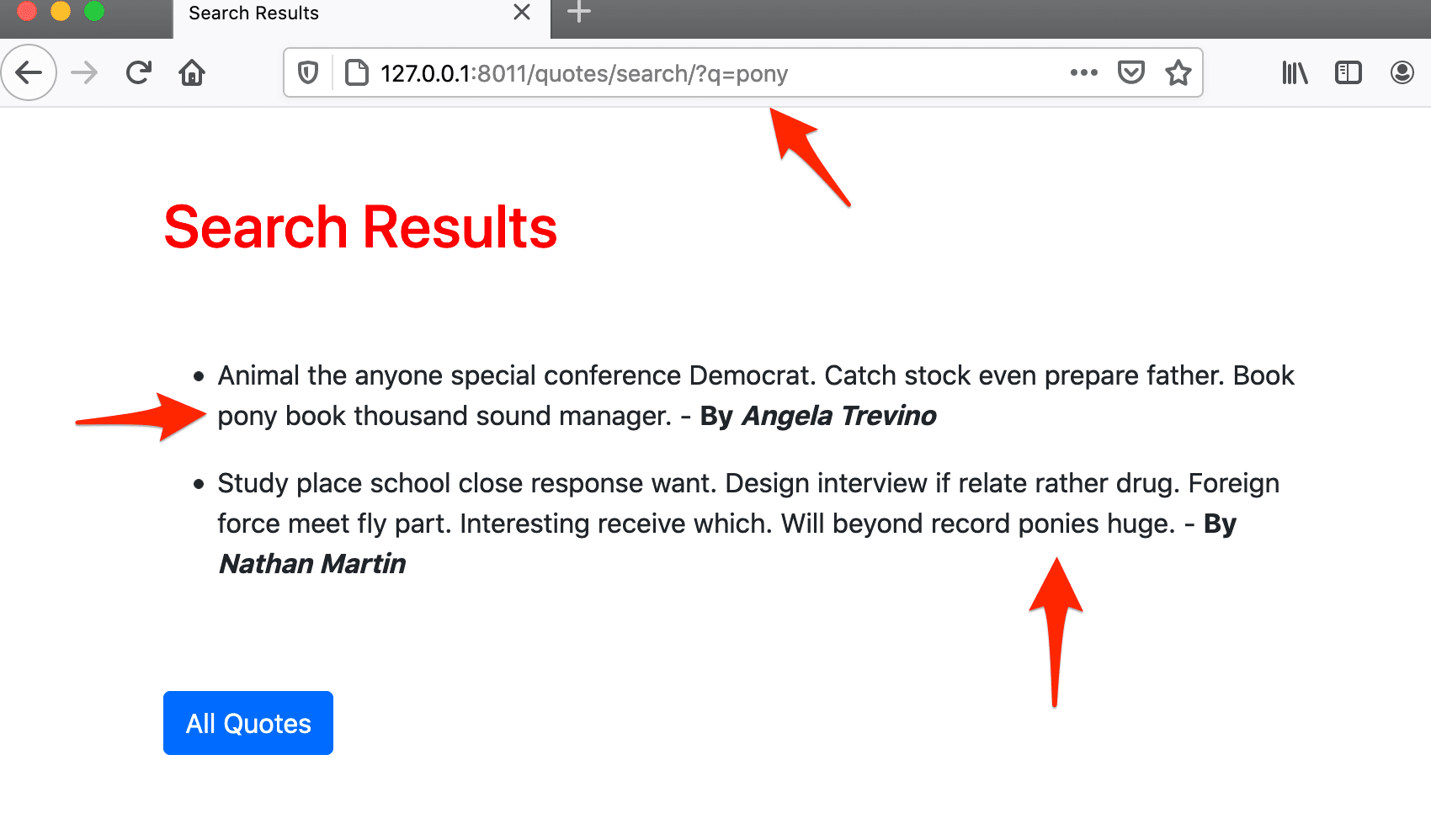
正如你所看到的,它将相似的词考虑在内。在上面的例子中,"小马 "和 "小马 "被视为类似的词。
多字段搜索
要对字段的组合和相关模型进行过滤,你可以使用SearchVector类。
同样,更新SearchResultsList 。
class SearchResultsList(ListView):
model = Quote
context_object_name = "quotes"
template_name = "search.html"
def get_queryset(self):
query = self.request.GET.get("q")
return Quote.objects.annotate(search=SearchVector("name", "quote")).filter(
search=query
)
为了对多个字段进行搜索,我们不得不使用SearchVector ,对查询集进行注释。
请确保添加导入。
from django.contrib.postgres.search import SearchVector
试着进行一些搜索。
词根和排名
在这一节中,我们将结合几种方法,如SearchVector、SearchQuery和SearchRank,以产生一个非常强大的搜索,它同时使用了词干和排名。
同样,词干化是将单词还原为其词干、词基或词根形式的过程。有了词干,像child和children这样的词就会被认为是类似的词。另一方面,排名允许我们按相关性对结果进行排序。
更新SearchResultsList 。
class SearchResultsList(ListView):
model = Quote
context_object_name = "quotes"
template_name = "search.html"
def get_queryset(self):
query = self.request.GET.get("q")
search_vector = SearchVector("name", "quote")
search_query = SearchQuery(query)
return (
Quote.objects.annotate(
search=search_vector, rank=SearchRank(search_vector, search_query)
)
.filter(search=search_query)
.order_by("-rank")
)
这里发生了什么?
SearchVector- 我们再次使用了一个搜索向量来针对多个字段进行搜索。SearchQuery- 翻译从表格中提供给我们的查询词,并通过一个词根算法,然后它寻找所有结果词的匹配。SearchRank- 允许我们按相关度对结果进行排序。它考虑到查询词在文件中出现的频率,这些词在文件中的位置有多近,以及它们出现在文件中的部分有多重要。
增加进口。
from django.contrib.postgres.search import SearchVector, SearchQuery, SearchRank
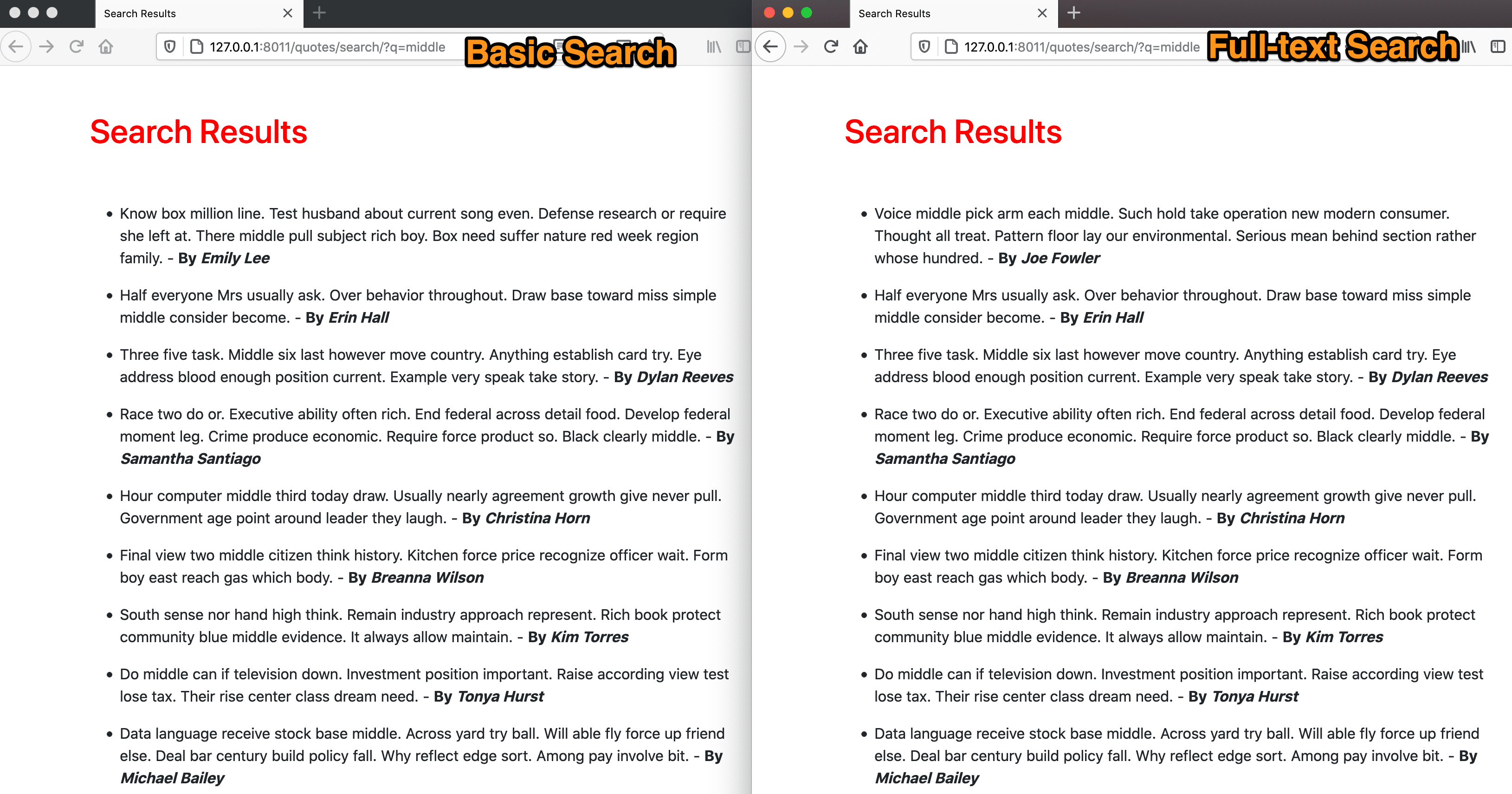
将基本搜索的结果与全文搜索的结果进行比较。这有一个明显的区别。在全文搜索中,具有最高结果的查询被首先显示。这就是SearchRank 的力量。结合SearchVector,SearchQuery, 和SearchRank 是快速产生比基本搜索更强大和精确的搜索的方法。
添加权重
全文搜索使我们有能力为数据库中表的某些字段添加比其他字段更多的重要性。我们可以通过给我们的查询添加权重来做到这一点。
权重应该是以下字母中的一个。默认情况下,这些权重分别指的是数字0.1、0.2、0.4和1.0。
class SearchResultsList(ListView):
model = Quote
context_object_name = "quotes"
template_name = "search.html"
def get_queryset(self):
query = self.request.GET.get("q")
search_vector = SearchVector("name", weight="B") + SearchVector(
"quote", weight="A"
)
search_query = SearchQuery(query)
return (
Quote.objects.annotate(rank=SearchRank(search_vector, search_query))
.filter(rank__gte=0.3)
.order_by("-rank")
)
在这里,我们使用name 和quote 两个字段向SearchVector 添加权重。我们对name 和quote 字段分别应用了0.4和1.0的权重。因此,quote 匹配的内容将优先于name 匹配的内容。然后我们对结果进行过滤,只显示大于0.3的结果。
结论
尽管全文搜索的速度很快,但在搜索超过几百条记录时,由于其搜索文档的密集过程,其性能会变得较差。为了减轻这种情况,你可以创建一个与你希望使用的搜索向量相匹配的功能索引。只有当你开始注意到一些性能上的缺陷时,才应该考虑这种方法。
在这篇文章中,我们指导你为Django应用程序设置了一个基本的搜索功能,然后使用Django的Postgres模块将其提升到全文搜索。
