

GPU是大多数用户执行深度学习和机器学习任务的首选硬件。"GPU通过并行执行计算来加速机器学习操作。许多操作,特别是那些可表示为矩阵乘法的操作,一开箱就能看到良好的加速。通过调整操作参数以有效利用GPU资源,甚至可以实现更好的性能。"(1)
在实践中,即使在GPU上进行深度学习计算,计算成本也很高。此外,这些机器很容易超载,引发内存不足的错误,因为机器解决指定任务的能力范围很容易被超出。幸运的是,GPU带有内置和外部监控工具。通过使用这些工具来跟踪耗电量、利用率和使用的内存百分比等信息,用户可以在事情发生时更好地了解哪里出了问题。
GPU的瓶颈和阻碍因素
在CPU中进行预处理
在许多深度学习框架和实现中,在切换到GPU进行高阶处理之前,通常使用CPU对数据进行转换。这种预处理可能需要65%的历时,正如最近的研究中所详述的那样。像图像或文本数据的转换工作会产生瓶颈,阻碍性能。在GPU上运行这些相同的过程可以为训练时间增加改变项目的效率。
什么原因导致内存不足(OOM)错误?
内存不足意味着GPU已经用完了它可以分配给指定任务的资源。这种错误经常发生在特别大的数据类型上,如高分辨率的图像,或当批处理量过大,或当多个进程同时运行时。它是一个可以被访问的GPU RAM数量的函数。
针对OOM的建议解决方案
- 使用一个较小的批处理规模。由于迭代是完成一个纪元所需的批次数量,降低输入的批次大小将减少GPU在迭代期间需要在内存中保存的进程的数据量。这是最常见的解决OOM错误的方法
- 你是在处理图像数据并对数据进行变换吗?考虑使用像Kornia这样的库来使用你的GPU内存执行变换。
- 考虑你的数据是如何被加载的。考虑使用一个DataLoader对象,而不是一次性加载数据以节省工作内存。它通过结合一个数据集和一个采样器来提供对给定数据集的可迭代。
用于监控性能的命令行工具
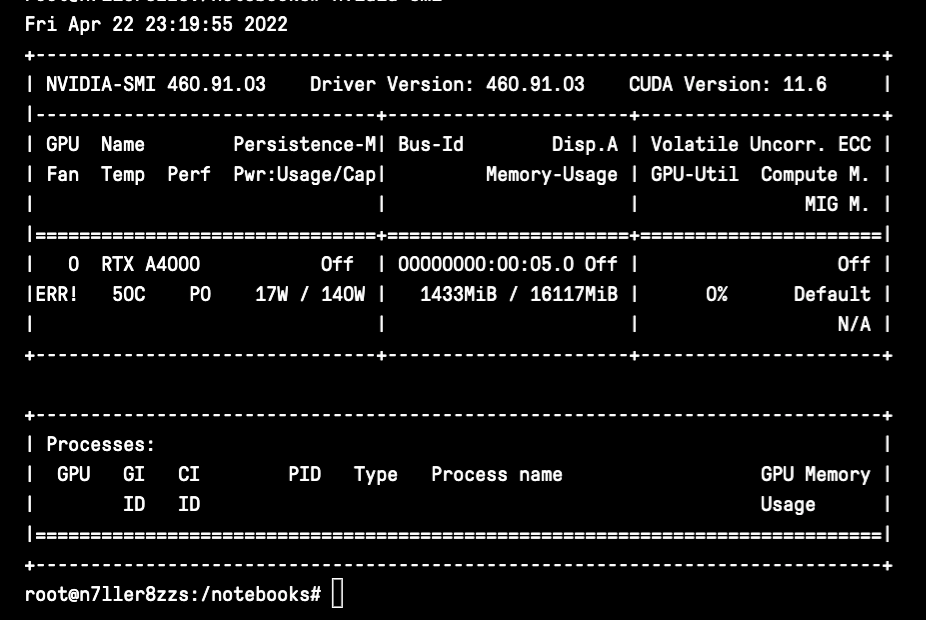
nvidia-smi windows
nvidia-smi
nvidia-smi是Nvidia系统管理接口的缩写,它是一个建立在Nvidia管理库之上的工具,以促进Nvidia GPU的监控和使用。你可以使用nvidia-smi ,快速打印出一组关于你的GPU利用率的基本信息。第一个窗口中的数据包括GPU的等级、名称、风扇利用率(尽管这在Gradient上会出错)、温度、当前的性能状态、是否处于持续模式、你的功耗和上限以及你的GPU总利用率。第二个窗口将详细介绍某个进程的具体进程和GPU内存的使用情况,比如运行一个训练任务。
使用nvidia-smi的提示
- 使用
nvidia-smi -q -i 0 -d UTILIZATION -l 1来显示GPU或单元信息('-q'),显示单个指定GPU或单元的数据('-i',我们使用0,因为它是在单个GPU笔记本上测试的),指定利用率数据('-d'),并每秒钟重复一次。这将输出关于你的利用率、GPU利用率样本、内存利用率样本、ENC利用率样本和DEC利用率样本的信息。这些信息将每秒钟循环输出,所以你可以实时观察变化。 - 使用标志"-f "或"-filename="来记录你的命令的结果到一个特定的文件。
- 在这里可以找到完整的文档。
瞥见
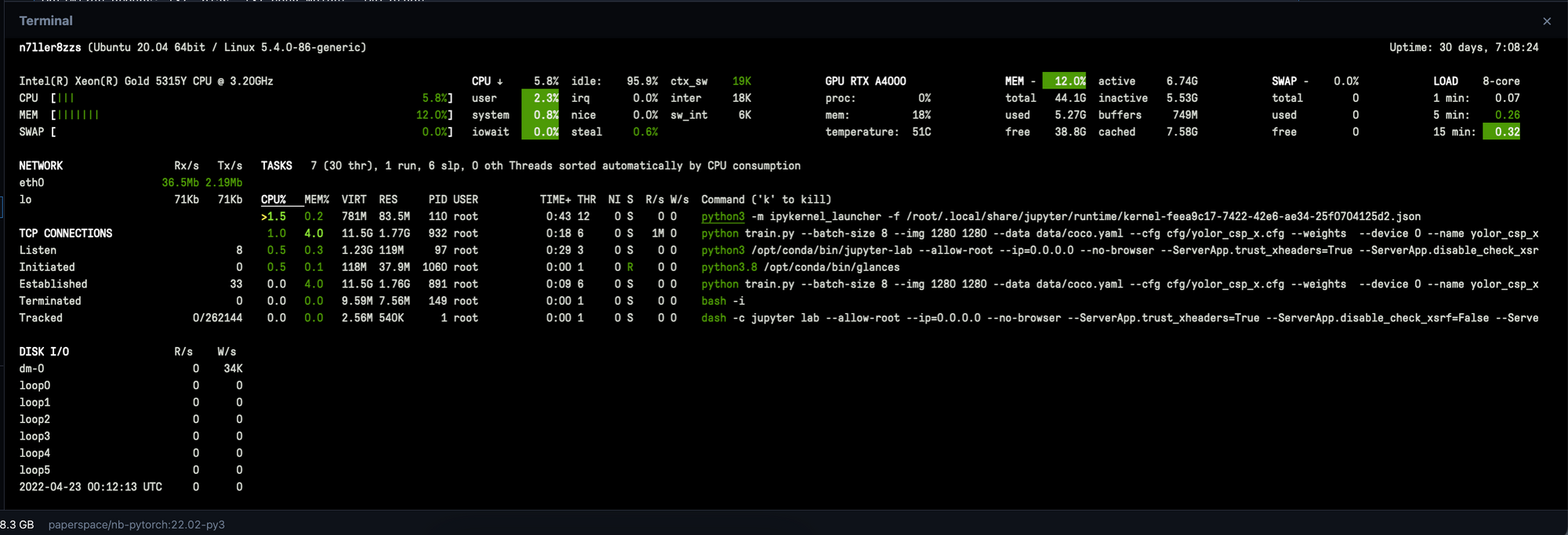
Glances是另一个监测GPU利用率的神奇库。与nvidia-smi ,在你的终端输入glances ,会打开一个仪表盘,用于实时监控你的进程。你可以使用这个功能来获得许多相同的信息,但实时更新提供了关于潜在问题可能存在的有用见解。除了实时显示你的GPU利用率的相关数据外,Glances还详细、准确,并包含CPU利用率数据。
Glances的安装非常简单。在你的终端输入以下内容。
pip install glances
然后要打开仪表板并获得对监控工具的完全访问权,只需输入。
glances
在这里阅读更多关于Glances的文档。
其他有用的命令
要警惕在Gradient Notebook上安装其他监控工具。例如,gpustat 和nvtop 与 Gradient Notebooks 不兼容。以下是一些其他的内置命令,可以帮助你监控机器上的进程。
这些命令更注重于监控CPU的利用率:
top- 打印出CPU进程和利用率指标free- 告诉你CPU正在使用多少内存vmstat- 报告进程、内存、分页、块状IO、陷阱和cpu活动的信息
