

测试你的网站的所有组件,看它们是否按预期工作,这是至关重要的。Playwright的端到端测试功能可以帮助你轻松实现这一目标。然而,如果你能熟练使用Python,你可以将其与Playwright测试框架配对,在你的网站上运行Python端到端测试。
Playwright测试框架比大多数替代品,包括Cypress 和TestCafe等,更加直接和轻便。为了给它加分,它还提供API测试。因此,它是端到端测试的绝佳选择。
在这个 Playwright Python 教程中,你将学习如何将 Python 的简单性和 Playwright 的实用性结合起来进行端到端测试。但让我们先了解端到端测试,以及为什么要用Playwright来执行测试。
什么是端到端测试?
端到端测试是一种验证应用程序的整个使用流程的方法,以确保它的每一部分都按预期工作。它涉及到对每个细节的关注,并扩大测试范围,以发现和修复错误。它的最终目标是帮助你建立一个没有错误的网站。
因此,它是测试复杂网站的一种方法。一般来说,它包括拿起你的网站的用户故事,在不同的集成环境中模拟你的用户行为。
在端到端测试中,你要考虑操作系统和浏览器的可变性,以及其他许多决定一个应用程序可行性的因素。因此,它涉及到进行一个至关重要的包容性测试--从后端(API测试)到前端。
考虑到这一点,自动化的端到端测试可以降低测试成本,提高应用程序的完整性,并帮助你的产品更快地出货。
什么是Playwright?
Playwright,由微软在2020年发布,是一个开源的、跨平台的自动化测试框架。它支持许多浏览器,包括Chromium、Firefox和Microsoft Edge,以及基于WebKit的应用程序。所以它为测试网络和移动应用提供了一个方便的工具包。
它还适用于大多数现代编程语言。截至目前,它支持JavaScript、Python、TypeScript、.NET和Java。这个Playright Python教程将研究如何使用Python用Playright进行端到端的测试。
为什么使用Playright进行Python端到端测试?
Playwright框架有许多事件触发器,让你像真正的用户一样与网站的不同客户端功能进行交互。而且它在同步和异步请求方面都发挥得很好。因此,你可以选择按顺序运行你的测试,或者利用Python的asyncio 包的力量,使用async/await并发地运行测试步骤。后者对于与异步运行任务的网站进行交互很方便。
它的API测试能力也可以帮助你验证应用程序端点上的请求和响应。
根据指定的测试浏览器,Playwright还将每个测试隔离到每个浏览器。因此,Playwright中的每个测试案例都是一个浏览器上下文,它定义了一个快速生成的浏览器实例,以减少开销。
考虑到Playwright的多功能性和Python的简单性和接受性,结合两者来编写你的测试脚本,可以简化自动化测试。此外,2021年Stackoverflow开发者调查将Python放在最常用编程语言中的第三位。
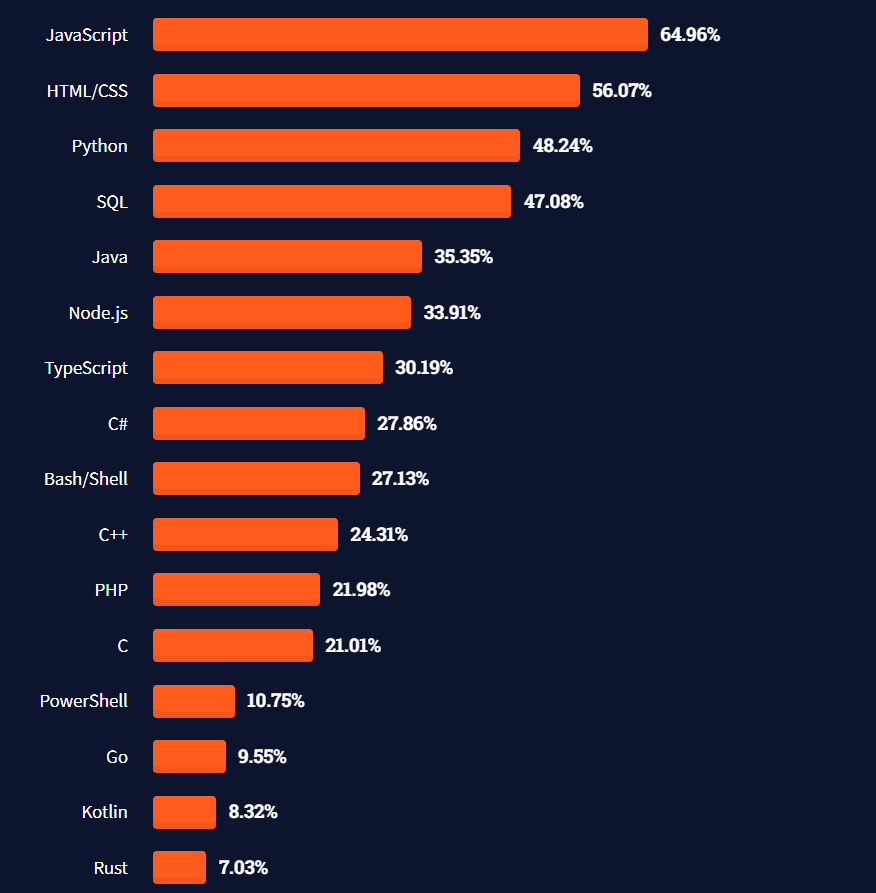
Playwright框架很受欢迎,在GitHub上有超过2000个分叉和超过41800个星。更重要的是?它在Stack Overflow上也有足够的提及率,有一个良好的社区。因此,你可以随时得到帮助,解决你的测试中的错误。
与Selenium不同的是,在Selenium中,你可能需要定义自定义的超时间隔,以防止在元素无法加载时出现错误的失败,而Playwright有一个自动等待功能,在执行测试案例的进一步步骤前,会暂时暂停DOM元素的加载。这个等待时间默认为30秒后超时,但你可以使用Playwright内置的**wait_for_timeout()**函数扩展这个时间。因此,使用Playwright,你会有一个较低的错误失败概率。
Playwright还提供了一个检查器工具,你可以用它来在你写测试时轻松地生成选择器。这有助于减少甚至消除手动检查浏览器的需要。
它的代码生成器以播放和记录的方式工作。你可以用它来旋转你的应用程序的用户界面,并在你与DOM交互时自动生成任何语言的测试脚本。尽管如果你不熟悉编码,这可能很方便,但它的可定制性较差。它不适合复杂的网站(如电子商务、银行、金融技术等),因为生成的代码往往是冗长而复杂的。
这些特点,加上其直观的选择器和定位器类,使Playwright成为一个优秀的端到端测试框架。
截至撰写本篇Playwright Python教程时,Playwright的GitHub趋势。
- 明星:41.8k
- 使用的人。14.1k
- 叉子: 2k
- 关注者。360
- 贡献者。274
- 发布。79
在我们深入学习这个Playright Python教程之前,让我们看看如何为Python端到端测试安装Playright并设置测试项目。
在线运行自动的 Playwright Python 测试。现在就试试LambdaTest!
如何为Python端到端测试设置Playwright?
你必须安装和设置你的计算机,才能开始使用Playwright Python进行自动化测试。然而,这个 Playwright Python 教程假定你的机器运行在 Python 3 上。
第一步:安装Python的最新版本。
去Python官方网站下载并在你的机器上安装最新版本的Python。
Windows操作系统默认不带有Python,所以你必须明确地安装它。然而,确保在安装过程中允许安装程序将Python添加到你的系统变量路径中。否则,你将不得不在以后手动完成。
要在 Windows 操作系统上安装 Python。
- 打开安装文件。
- 点击安装窗口右下方的Add Python to Path复选框。然后点击立即安装。
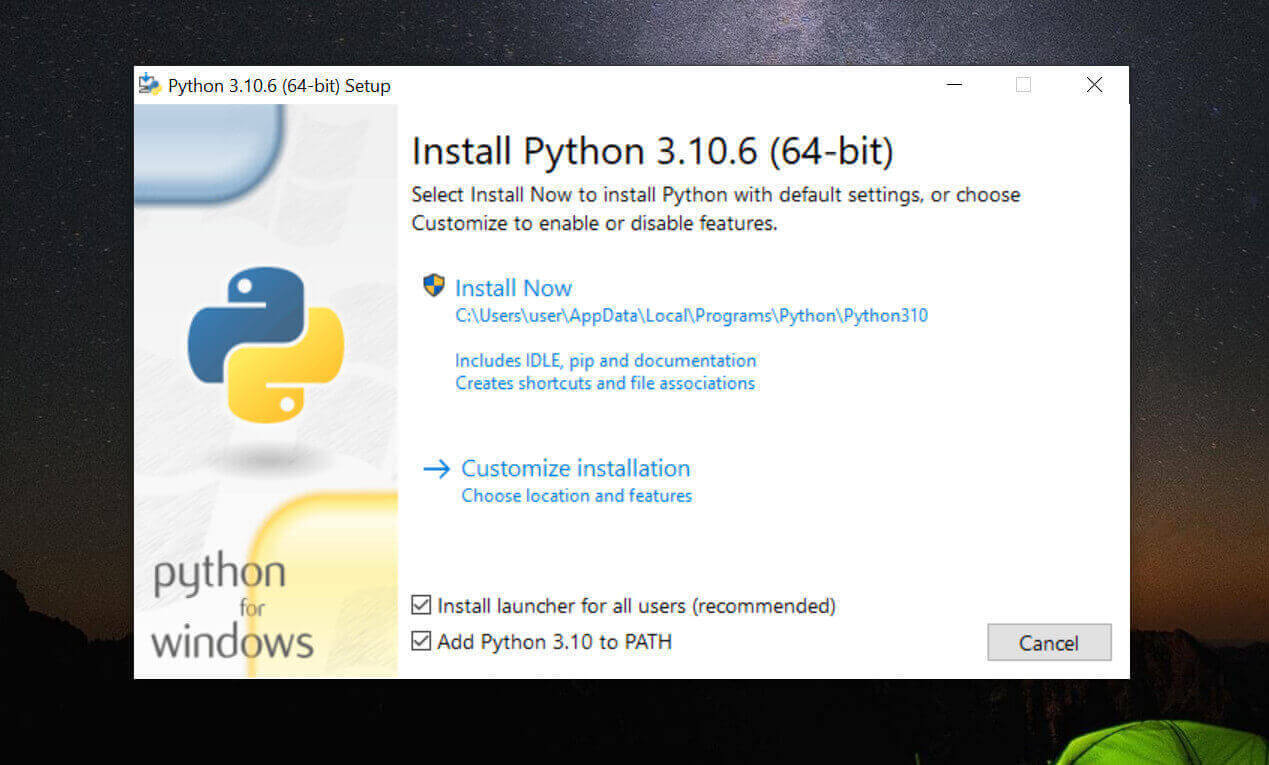
- 安装会初始化并在下面的菜单中开始。
虽然大多数Linux发行版可能默认预装了Python,但你可能仍然要升级到一个较新的版本,因为系统版本可能已经过时,无法运行Playwright。然而,Playwright可以在Python 3.7或更高版本上运行。
要在Linux上从头安装Python。
sudo apt-get install python 3
步骤 2.安装 Playwright 和它的 WebKit。
你可以使用pip 来安装 Playwright。
pip install playwright
如果你是在Linux或Mac上,你可以用pip3 代替,它可以在这些平台上与Python 3一起工作。
pip3 install playwright
上述任何一个命令都可以运行Playwright的安装程序。
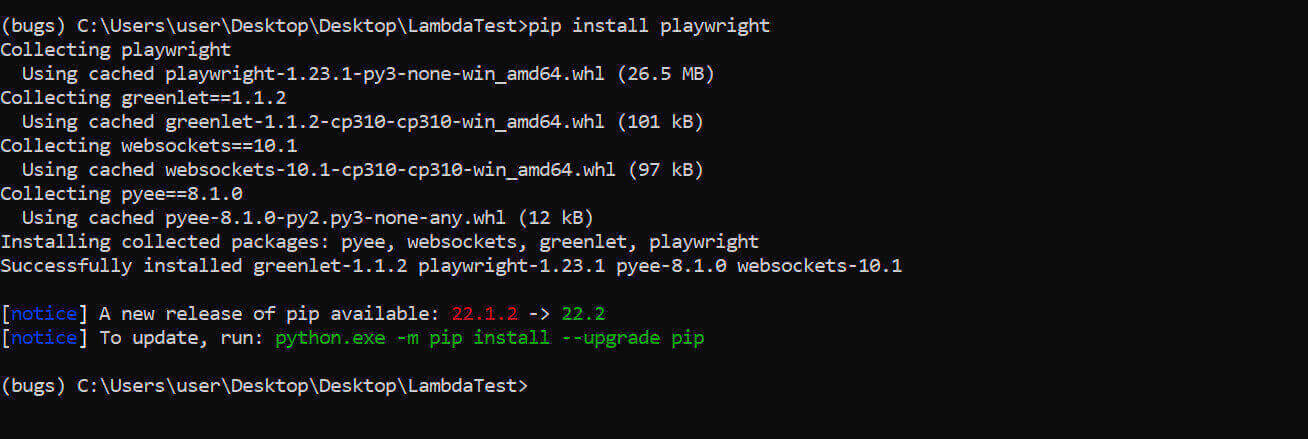
而如果你使用conda 来管理依赖关系。
conda install playwright
根据你选择的Python依赖性安装程序,上述命令会将Playwright框架安装到你的机器或Python虚拟环境中(如果你使用一个)。
并安装 Playwright WebKit。
playwright install
上面的命令安装了 Playwright 的内置 WebKit。你将用它来调出不同网络浏览器的测试场景。
第3步。创建项目文件夹。
Playwright Python教程的下一步是为你的自动测试创建一个项目文件夹。你可以从命令行或你的图形用户界面上创建一个。
在这个 Playwright Python 教程中,我们将使用 Windows 平台上的 Visual Studio Code。但是你可以使用任何最适合你的IDE。
要在 Windows 上创建一个文件夹,并用 VS Code 打开它。
- 打开你电脑上的任何文件夹,右键单击一个空白处。进入 "新建">"文件夹"。
- 命名你的文件夹;这可以是一个描述性的名字(例如playwright_test_folder)。
- 现在,打开VS Code到你的项目文件夹。打开VS代码并点击打开文件夹。转到你先前创建的文件夹,并选择它来打开VS Code到该目录。
现在你已经看到了如何建立一个开发环境,用Playwright在Python中测试你的应用程序--让我们深入到编码方面。但在此之前,记得我们在这个Playwright Python教程中提到过,Playwright有一个代码生成器。
你会在本教程的下一节看到这个代码生成器是如何工作的,因为它告诉你在编写测试时如何选择网站上的元素。
在50多种浏览器和操作系统组合上即时运行你的Playwright测试脚本。现在就试试LambdaTest吧!
Playwright代码生成器是如何工作的?
正如本 Playwright Python 教程的前面部分所提到的,Playwright 代码生成器使得扫描DOM变得很容易,而无需进入浏览器的检查标签。虽然它限制了浏览器选择的灵活性,而且不像写自定义测试那么干净,但对于无代码爱好者来说,它也是一种很好的方式,可以在与UI交互的同时自动生成测试脚本。
代码生成器以两种方式工作。你可以用它来挑选出你的网站的选择器。或者你可以用它的记录和播放功能生成整个测试案例脚本。
打开你的终端到你的项目根目录,使用下面的命令为你的应用程序启动一个选择器生成器。在我的例子中,我将使用LambdaTest电子商务游乐场,所以记得用你的网站的URL替换它。
playWright codegen https://ecommerce-playground.lambdatest.io/
当你在网页上的元素上悬停时,上面的命令会生成相应的选择器。
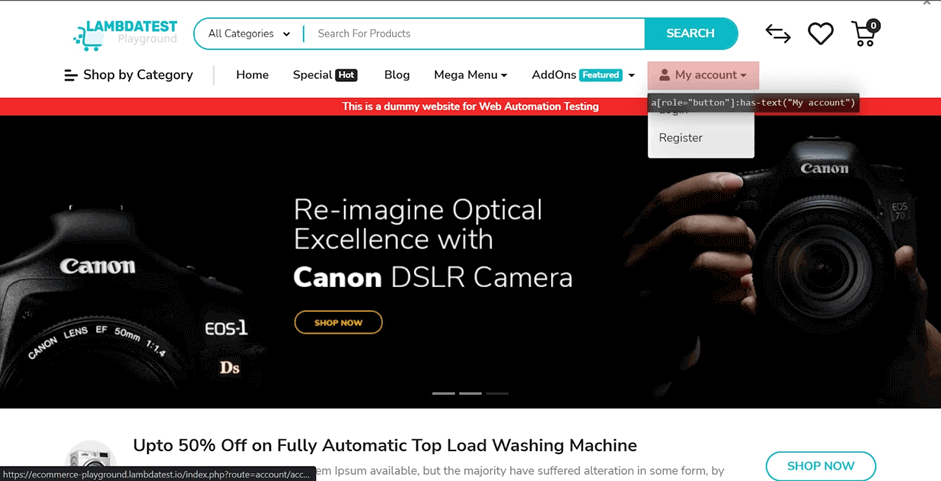
仔细观察上面的图片。你会看到,该页面上的 "我的账户"下拉菜单生成了一个选择器。这有助于确定Playwright定位器在测试期间如何找到元素或功能。
要从你与目标网站的互动中生成一个测试脚本到Python文件,在你的终端粘贴以下命令,用你的应用程序的URL替换ecommerce-playground.lambdatest.io/。
playwright codegen --target python -o example2.py https://ecommerce-playground.lambdatest.io/
上面的命令会出现一个像第一个一样的浏览器。但这一次,它告诉 Playwright 在你与指定网站互动时,将测试代码写入目标文件**(example2.py)**。你不需要明确地创建目标文件。Playwright会自动这样做。
现在打开你的文本编辑器到你的项目文件夹。你应该看到生成的Python脚本**(在我的例子中是example2.py**)。
下面是该网站和与之交互生成的代码。
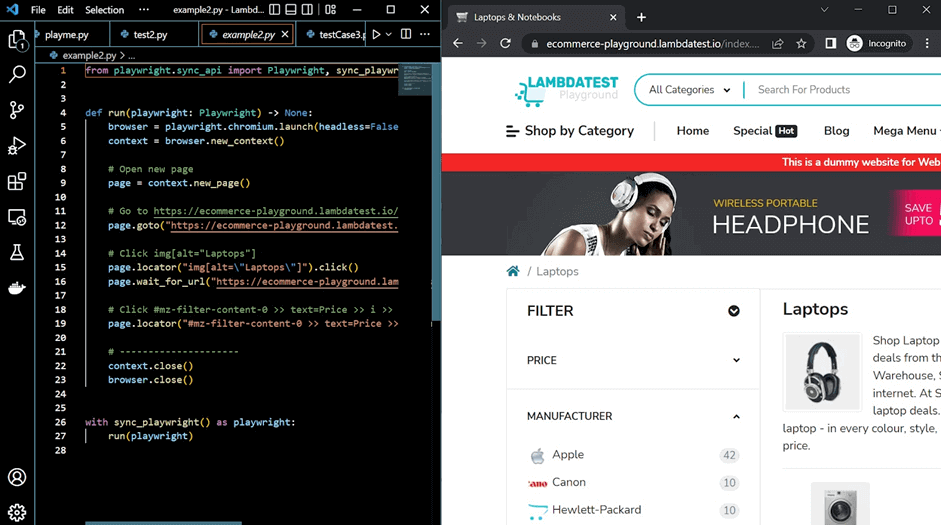
如果你把生成的Python脚本和网站并排放在一起,如上图所示,你会看到当你与你的应用程序互动时,Python脚本中的代码会动态变化。
Playwright代码生成器的优点。
- 它能自动生成代码,如果你需要进一步扩展用例,这可以是一个好的起点。
- 便于在自定义自动测试中挑选测试选择器。
- 你可以为任何Playwright支持的编程语言生成代码。
Playwright代码生成器的缺点。
- 生成的代码不具有可扩展性和可维护性。
- 它不适合测试复杂的网站。
- 没有办法执行并行测试,因为它只生成一个代码文件。
- 生成的代码很难阅读和调试。
- 它没有提供连接到云网的空间。
- 当你生成更多的测试时,代码库变得更加混乱。
- 测试案例是重复的。
Playwright定位器和选择器
与大多数测试框架一样,定位器和选择器是Playwright的一些核心功能。
像Selenium定位器一样,你使用Playwright选择器来指定一个元素在DOM中的位置。定位器是一个类,它将 Playwright 指向指定的 DOM 元素,这样它就可以对它们执行事件。
定位器暂缓事件的发生并触发自动等待,它不断重试,但如果找不到元素,30秒后就会失败。Playwright中的定位器和选择器携手工作。
例如,下面的定位器对所选元素执行了一个点击事件。
page.locator('input[name="Search"]').click()
上例中的选择器是**'input[name="search"]',而page.locator()函数指向所选元素,对其执行JavaScript事件(本例中是点击**事件)。然而,在这种情况下,页面是一个浏览器上下文实例。
!['input[name="search"]'](https://www.lambdatest.com/blog/wp-content/uploads/2022/09/image1-6-1-1-1.jpg)
用 Playwright 实现 Python 端到端测试
在你开始测试之前,你可能想检查一下网站元素,为你的测试挑选选择器。把你的光标放在一个网站元素上**> 右键单击它,然后转到检查** (用于Chrome或你选择的任何其他网站浏览器)。
**提示:**你可以使用Playwright代码生成器来生成选择器。只需使用playwright codegen Website_URL 命令启动它。将鼠标悬停在元素上,在你的测试代码中重新使用生成的选择器。
如前所述,Codegen在生成选择器方面非常有用,因为选择器是任何自动化测试代码的一个组成部分。
我们将使用Playwright Python串联和并行地运行测试。而我们的测试场景将考虑一个实际的用户故事来展示我们的端到端测试。通过阅读这个 Playwright Python 教程来了解更多关于并行测试的知识。
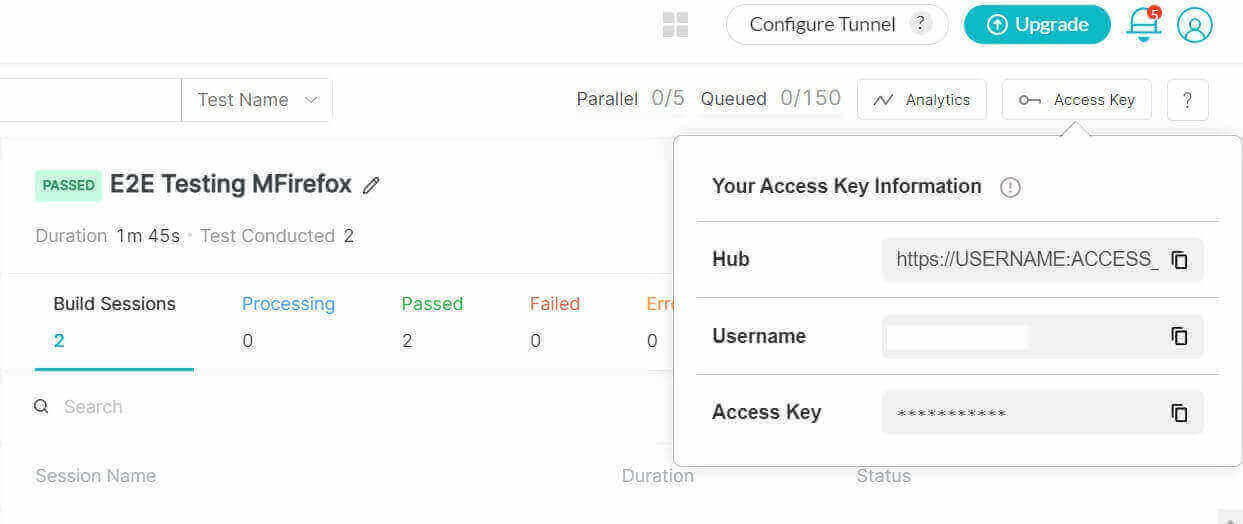
我们将在LambdaTest云网格上运行我们的测试。因此,你需要从LambdaTest Build Dashboard上点击右上角的Access Key标签来获取你的用户名和密匙。
通过使用LambdaTest这样的云测试平台,你可以通过使用由50多个浏览器和Chrome、Chromium、Microsoft Edge、Mozilla Firefox甚至Webkit等浏览器版本组成的浏览器群,大大减少运行Playwright Python测试的时间。
你也可以订阅LambdaTest YouTube频道,随时了解围绕自动化浏览器测试、Cypress E2E测试、移动应用测试等的最新教程。
这些测试都是使用LambdaTest电子商务游乐场进行演示的。这个Playwright Python教程的用例如下。
测试场景 - 1 (新用户注册)
- 用户启动LambdaTest电子商务游乐场的注册页面。
- 填写注册表。
- 用户提交注册表。
- 第一次进入他们的仪表板。
测试场景 - 2(登录和购买物品)
- 用户用注册账户再次登录。
- 搜索一个产品。
- 用户选择步骤中搜索到的产品。
- 将该产品添加到购物车中。
- 用户退房。
- 执行注销。
Playwright Python测试结构。
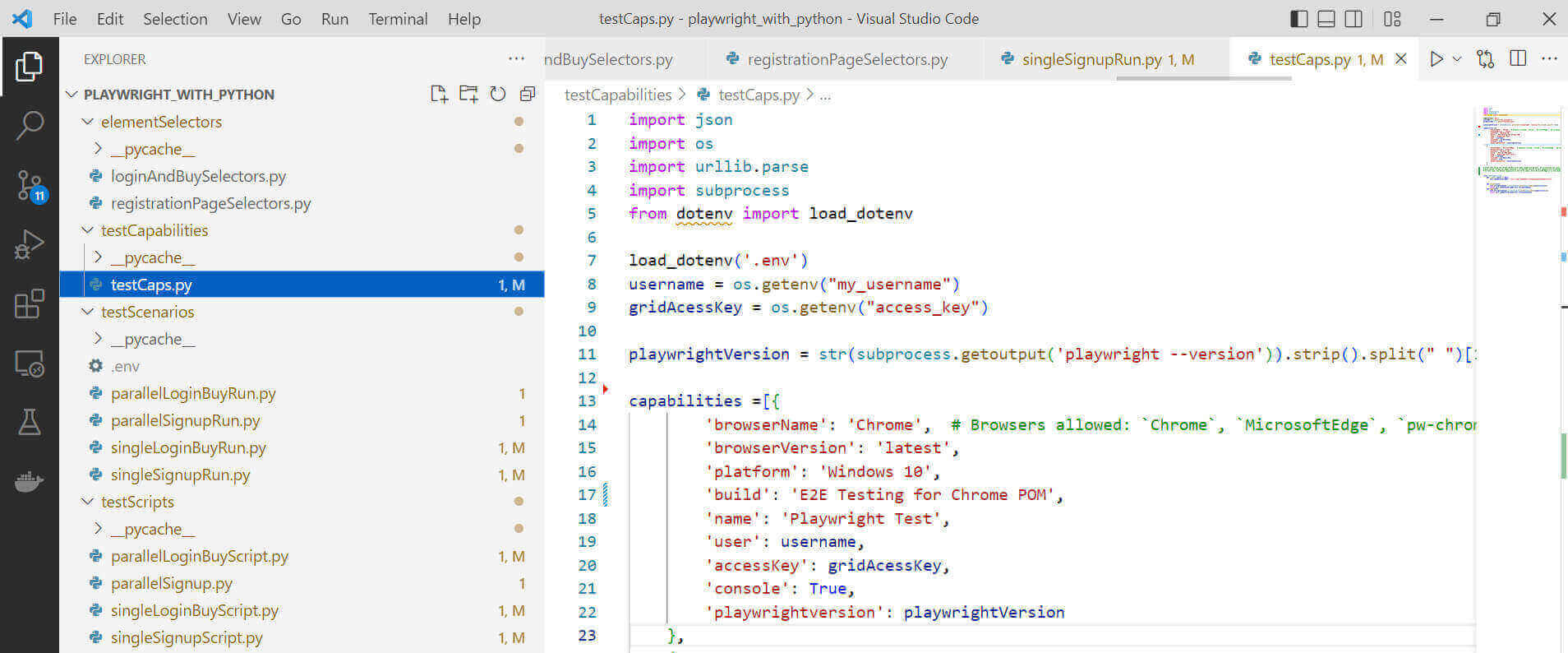
我们将采用页面对象模型(POM)设计模式来构造测试项目。因此,我们的代码结构,在这种情况下,将关注点分离成不同的文件,放在不同的文件夹中,以实现模块化。这有助于我们以后扩展我们的代码并摆脱复杂的问题。
源代码的可维护性和可扩展性是页面对象模型设计模式的一些最大优点。
例如,你可能想把并行的测试用例和单一的测试用例沿线分开。
下面是Playwright Python的测试结构。
Playwright Python结构演练。
elementSelectors文件夹包含所有测试方案的选择器。运行所有测试套件所需的所有能力都在testCapabilities目录中。这个文件夹只有一个文件,它定义了所有测试案例共享的能力。
我们还将所有的测试动作(事件处理程序)放在testScripts 文件夹内。这个文件夹中的每个文件都持有处理事件方法的类。最后,testScenarios 目录包含每个测试用例的测试运行器。要运行任何测试,你只需要运行这里的每个文件。
因此,我们必须将**.env文件放在这个testScenarios** 文件夹中,因为所有导入的模块在运行测试时都会从其中提取已声明的环境变量。记住,.env文件保存了所有的秘密参数,包括你的云网密钥和用户名。
下面是这个 Playwright Python 教程中使用的项目目录的 VS Code 截图。
现在,我们开始为整个测试套件设置测试能力。
测试能力的实现。
文件名 - testCapabilities / testCaps.py
Playwright Python代码演练。
testCaps.py文件包含运行我们所有测试用例所需的能力模块,包括单一和并行测试。因此,在运行Playwright Python测试时,你不必为后续的测试案例改变它--除非你想在数组中添加更多的能力,这涉及到方法的扩展。
你首先要导入所有必要的包来运行这个 Playwright Python 模块。
import json
import os
import urllib.parse
import subprocess
from dotenv import load_dotenv
接下来,使用dotenv包从环境变量中加载你的云网格访问密钥和用户名,因为你将在能力中提供它们。
load_dotenv('.env')
username = os.getenv("my_username")
gridAcessKey = os.getenv("access_key")
你还会在测试能力里面以字符串的形式提供Playwright版本。在这种情况下,我们使用subprocess模块提取这个值。然后我们用 Python 内置的strip 和split 函数来清理它。
playwrightVersion = str(subprocess.getoutput('playwright --version')).strip().split(" ")[1]
每个能力都是一个字典,指定测试的设置。数组中有两个能力--在这种情况下(Chrome 和 Microsoft Edge)。因此,我们可以使用一个数组索引在不同的方法中单独调用它们。这使得使用Playwright Python进行跨浏览器测试的规模很容易扩大--甚至是并行的。
capabilities =[{
'browserName': 'Chrome', # Browsers allowed: `Chrome`, `MicrosoftEdge`, `pw-chromium`, `pw-firefox` and `pw-webkit`
'browserVersion': 'latest',
'platform': 'Windows 10',
'build': 'E2E for Chrome POM',
'name': 'Playwright Test',
'user': username,
'accessKey': gridAcessKey,
'console': True,
'playwrightversion': playwrightVersion
},
{
'browserName': 'MicrosoftEdge', # Browsers allowed: `Chrome`, `MicrosoftEdge`, `pw-chromium`, `pw-firefox` and `pw-webkit`
'browserVersion': 'latest',
'platform': 'Windows 10',
'build': 'E2E for POM Egde',
'name': 'Playwright Test Case 2',
'user': username,
'accessKey': gridAcessKey,
'console': True,
'playwrightversion': playwrightVersion
}
]
testCapabilities 类持有Chrome和Microsoft Edge的能力方法。首先,你用云网格的URL初始化这个类。
class testCapabilities:
def __init__(self) -> None:
self.lambdatestGridURL = 'wss://cdp.lambdatest.com/playwright?capabilities='
如上所述,Playwright的LamdaTest网格URL是self.lambdatestGridURL。
然后你使用其索引位置提取每个浏览器方法**(Chrome和Edge**)的能力。然后将每个方法与从**__init__**函数中继承的网格 URL 连接起来。
Chrome 方法的能力字典位于索引0(数组中的第一项)。
self.stringifiedCaps = urllib.parse.quote(json.dumps(capabilities[0]))
return self.lambdatestGridURL+self.stringifiedCaps
**Edge()**方法得到数组中的第二个字典。
self.stringifiedCaps1 = urllib.parse.quote(json.dumps(capabilities[1]))
return self.lambdatestGridURL+self.stringifiedCaps1
因此,这种设计有助于你根据不同的能力单独或并行地运行你的测试。
注册测试场景的实现。
FileName - elementSelectors/registrationPageSelectors.py
FileName - testScripts / singleSignupScript.py
FileName - *testScenario / singleSignupRun.*py
Playwright Python代码演练。
FileName - elementSelectors / registrationPageSelectors.py。
我们把所有的网络元素选择器,包括测试网站的URL,插入到registrationPageSelectors.py文件里面的一个字典里。
例如,电子邮件字段选择器在字典中采取这种格式。
'E-Mail': 'input[placeholder="E-Mail Address"]'
整个元素选择器的字典看起来是这样的。
webElements = {
'webpage': "https://ecommerce-playground.lambdatest.io/index.php?route=account/register",
'First_Name': 'input[placeholder="First Name"]',
'Last_Name': 'input[placeholder="Last Name"]',
'E-Mail': 'input[placeholder="E-Mail"]',
'Telephone': 'input[placeholder="Telephone"]',
'Password': 'input[placeholder="Password"]',
'Confirm_Password': 'input[placeholder="Password Confirm"]',
'Subscribe': 'label:has-text("No")',
'Privacy_Policy': 'label:has-text("I have read and agree to the Privacy Policy")',
'Submit': 'input[value="Continue"]',
'Continue': "text=Continue"
}
接下来是把这些变成启动elementSelector类的属性,通过调用每个元素的键来实现。
class elementSelector:
def __init__(self) -> None:
self.webpage = webElements["webpage"]
self.firstname = webElements["First_Name"]
self.lastname = webElements["Last_Name"]
self.email = webElements["E-Mail"]
self.telephone = webElements["Telephone"]
self.password = webElements["Password"]
self.confirmpassword = webElements["Confirm_Password"]
self.subscribe = webElements["Subscribe"]
self.privacypolicy = webElements["Privacy_Policy"]
self.submit = webElements["Submit"]
self.todashboard = webElements["Continue"]
然后我们把它们声明为elementSelector类的方法,像这样。
def webPage(self):
return self.webpage
def firstName(self):
return self.firstname
def lastName(self):
return self.lastname
def eMail(self):
return self.email
def Telephone(self):
return self.telephone
def Password(self):
return self.password
def confirmPassword(self):
return self.confirmpassword
def Subscribe(self):
return self.subscribe
def privacyPolicy(self):
return self.privacypolicy
def Submit(self):
return self.submit
def goToDashboard(self):
return self.todashboard
文件名 - testScripts / singleSignupScript.py。
singleSignupScript.py文件包含测试事件的方法。我们首先导入内置模块。
from playwright.sync_api import sync_playwright
import sys
sys 包连接了不同文件夹中的Python文件,使导入的自定义模块可见。
sys.path.append(sys.path[0] + "/..")
目录路径("/...")是一个文件级声明,表明导入的模块离根文件夹有两步之遥。所以在你的情况下,它可能会改变,这取决于你的项目结构。
在这之后,我们从各自的模块中导入并实例化elementSelector和testCapability类。
from elementSelectors.registrationPageSelectors import elementSelector
from testCapabilities.testCaps import testCapabilities
select = elementSelector()
capability = testCapabilities()
因此,比如说,从testCapability类中调用Chrome方法。
capability.Chrome()
而要获得一个方法,例如从elementSelector类中获得webPage。
select.webPage()
为了启动Register 类,它继承了Playwright包中的方法。
def __init__(self, playwright) -> None:
然而,为了启动Register 类,我们连接到Chrome方法(它定义了网格URL和JSON化的能力)。self.page属性是一个包含定位器动作的浏览器上下文的实例。
self.browser = playwright.chromium.connect(capability.Chrome())
page = self.browser.new_page()
self.page = page
launchWeb 方法通过调用网站URL与elementSelector 类的select.webPage()实例,使用页面实例goto 方法打开网站。
def launchWeb(self):
self.page.goto(select.webPage())
title = self.page.title()
print(title)
该类中的每个其他属性也同样得到了相应的方法。为了便于阅读,每个字段元素都接受一个数据 关键字。
例如,填入名字。
def fillFirstName(self, data):
self.page.locator(select.firstName()).fill(data)
接受点击事件的元素并不接受任何数据。例如,要点击订阅按钮。
def subscribe(self):
self.page.locator(select.Subscribe()).click()
脚本顶部的set_test_status 函数在LambdaTest网格用户界面上返回测试状态。因此,一旦测试通过,它就会返回通过,但对于失败的测试,你会得到一个失败 的消息。
def set_test_status(page, status, remark):
page.evaluate("_ => {}",
"lambdatest_action: {\"action\": \"setTestStatus\", \"arguments\": {\"status\":\"" + status + "\", \"remark\": \"" + remark + "\"}}")
这后来成为注册类方法的一部分。
def getSuccessStatus(self):
return set_test_status(self.page, "passed", "Success")
def getFailedStatus(self):
return set_test_status(self.page, "failed", "Test failed")
FileName - testScenario / singleSignupRun.py。
singleSignupRun.py文件也以模块导入开始。但值得注意的是,我们从singleSignupScript 模块中导入了Register 类。然后我们使用 Playwright 的 sync 类创建了一个事件循环,并将其作为playwright 传递。
with sync_playwright() as playwright:
记得Register 类在前面继承了Playwright的方法。为了实现这一点,我们将playwright 变量作为Register 类的一个实例传递。而且它现在也带有继承的Playwright同步类。
playwright = Register(playwright)
因此,事件循环按照这个顺序执行注册测试步骤。
步骤1:使用启动方法启动测试网站。
playwright.launchWeb()
第2步:填写注册表。所以对于表单字段,你必须调用并填写它们,因为它们接受一个位置数据参数。
playwright.fillFirstName("Idowu")
playwright.fillLastName("Omisola")
playwright.fillEmail("anEmailgmai@gmail.com")
playwright.fillPhone("08122334433")
playwright.fillPassword("mypassword")
playwright.confirmPassword("mypassword")
playwright.subscribe()
playwright.acceptPolicy()
第3步:提交注册表。
playwright.submit()
第4步:第一次访问你的仪表板。
playwright.continueToDashboard()
如果try块中的代码执行成功,getSuccessStatus()方法会在网格上返回一个通过的信息。
playwright.getSuccessStatus()
否则,它将运行getfailedStatus()方法并在网格上返回一个失败的 消息。
except Exception as err:
playwright.getFailedStatus()
最后,我们在try-except块外关闭浏览器,以防止出现无休止的循环,在执行过程中抛出一个错误。
playwright.closeBrowser()
Playwright Python执行。
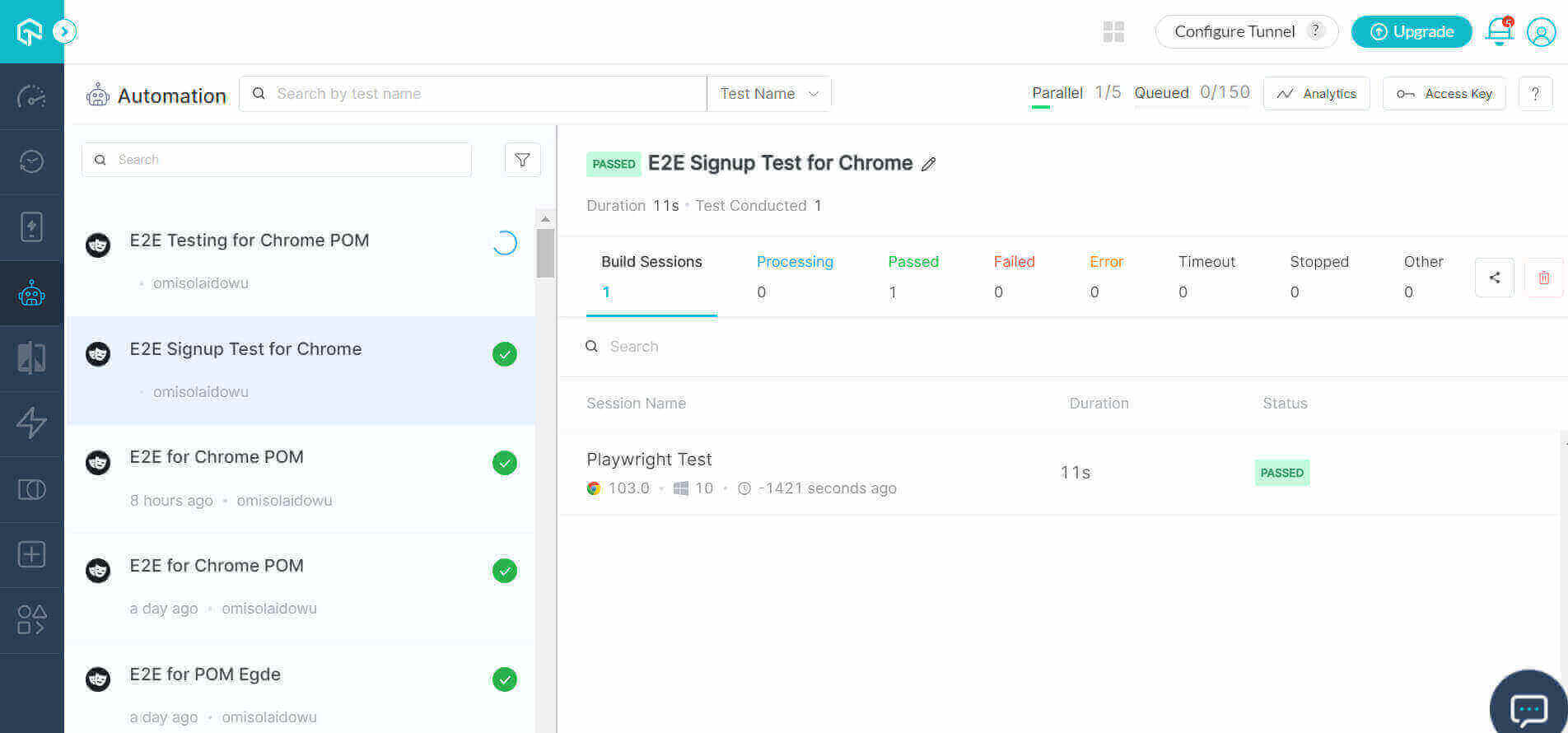
运行测试运行器文件**(singleSignupRun.py**)。
python singleSignupRun.py
该测试在LambdaTest网格上成功执行,如下图所示。
登录和产品购买测试案例执行。
登录测试用例的元素选择器在loginAndBuySelectors.py文件内。
FileName - elementSelectors/loginAndBuySelectors.py
FileName - testScripts / singleLoginButScript.py:
FileName - testScenarios / singleLoginBuyRun.py。
Playwright Python Code Walkthrough:
FileName - elementSelectors / loginAndBuySelectors.py:
和注册测试案例一样,我们把所有的登录页面元素选择器和网站的URL放在一个字典**(webElements**)中。
webElements = {
'webpage': "https://ecommerce-playground.lambdatest.io/index.php?route=account/login",
'E-Mail': 'input[placeholder="E-Mail Address"]',
'Password': 'input[placeholder="Password"]',
'Login': 'input:has-text("Login")',
'Search': 'input[name="search"] >> nth = 0',
'searchbutton': 'div[class="search-button"]:has-text("Search")',
'product': 'h4[class="title"]:has-text("Nikon D300") >> nth = 0',
'addcart': 'div[id="entry_216842"]:has-text("Add to Cart")',
'checkoutmodal': 'div[role="alert"]:has-text("Checkout")',
'Hoverable': 'a[role="button"]:has-text("My account")',
'Logout': 'span:has-text("Logout")'
}
搜索 和产品 元素有**>> nth = index**,因为这些DOM元素中的每一个都有一个类似选择器的第n个节点。所以第n个 参数有助于指定子元素的索引位置,从0开始。
例如,像我们上面做的那样,从一组相似的产品中选择第一个产品。
'product': 'h4[class="title"]:has-text("Nikon D300") >> nth = 0'
我们使用这些元素来启动elementSelector 类,将每个元素附加到一个属性上。
class elementSelector:
def __init__(self) -> None:
self.webpage = webElements['webpage']
self.email = webElements['E-Mail']
self.password = webElements['Password']
self.login = webElements['Login']
self.hover = webElements['Hoverable']
self.searchproduct = webElements['Search']
self.product = webElements['product']
self.addcart = webElements['addcart']
self.checkout = webElements['checkoutmodal']
self.searchbutton = webElements['searchbutton']
self.logout = webElements['Logout']
接下来,我们创建一个方法来返回每个属性。这些方法将处理测试脚本中的Playwright定位器事件。
def webPage(self):
return self.webpage
def firstName(self):
return self.firstname
def lastName(self):
return self.lastname
def eMail(self):
return self.email
def Telephone(self):
return self.telephone
def Password(self):
return self.password
def confirmPassword(self):
return self.confirmpassword
def Subscribe(self):
return self.subscribe
def privacyPolicy(self):
return self.privacypolicy
def Submit(self):
return self.submit
def goToDashboard(self):
return self.todashboard
因此,上面的块将每个属性附加到elementSelector 类方法中。我们可以在另一个文件中轻松地使用这些方法;你只需要从elementSelector 类的一个实例中调用每个方法。这就是页面对象模型(POM)的强项之一。
文件名 - testScripts / singleLoginBuyScript.py。
我们通过导入同步的 Playwright 和sys包来开始singleLoginButScript.py文件。然后我们在导入我们的自定义模块**(elementSelector 和 testCapabilities**)之前,使用 sys append 方法将 Python 指向系统路径。
from playwright.sync_api import sync_playwright
import sys
sys.path.append(sys.path[0] + "/..")
from elementSelectors.loginAndBuySelectors import elementSelector
from testCapabilities.testCaps import testCapabilities
我们创建一个elementSelector和testCapabilities类的实例,以防止与类的继承发生冲突。
select = elementSelector()
capability = testCapabilities()
现在很容易通过这些类的对象实例调用每个方法。我们利用这一点在LoginAndBuy类中声明我们的方法,首先是用Chrome浏览器上下文进行初始化。然而,初始化继承了Playwright类。
class LoginAndBuy:
def __init__(self, playwright) -> None:
self.browser = playwright.chromium.connect(capability.Chrome())
page = self.browser.new_page()
self.page = page
在上面的片段中,**capacity.Chrome()从testCapabilities类中抽取了Chrome()方法。你可以通过用Edge()方法替换Chrome()**来将其改为Microsoft Edge。
self.browser = playwright.chromium.connect(capability.Edge())
其他方法属于elementSelector 类。因此,测试案例开始使用继承的浏览器上下文启动浏览器。注意它是如何从这个类中选择**webPage()**方法的。
def launchWeb(self):
self.page.goto(select.webPage())
下面的三个方法定义了登录过程。每个表单字段都接受一个数据关键字(之前注册的Email和密码)。
下面是登录的步骤。
def fillEmail(self, data):
self.page.locator(select.eMail()).fill(data)
def fillPassword(self, data):
self.page.locator(select.Password()).fill(data)
def clickLogin(self):
self.page.locator(select.loginAccount()).click()
接下来,我们搜索一个产品,找到后选择它,然后把它加入购物车并结账。
def fillSearchBox(self, data):
self.page.locator(select.searchProduct()).fill(data)
def clickSearchButton(self):
self.page.locator(select.searchButton()).click()
def clickProduct(self):
self.page.locator(select.Product()).click()
def clickAddToCart(self):
self.page.locator(select.addCart()).click()
def clickCheckOutModal(self):
self.page.locator(select.checkOut()).click()
最后的测试步骤是注销网站。**hover()**事件使注销按钮可以被访问,因为它是在一个可悬停的下拉菜单中。
def hoverMenuBox(self):
self.page.locator(select.hoverBox()).hover()
def clickLogout(self):
self.page.locator(select.logoutUser()).click()
脚本顶部的set_test_status 函数有助于将测试状态传达给云网格的用户界面。
def set_test_status(page, status, remark):
page.evaluate("_ => {}",
"lambdatest_action: {\"action\": \"setTestStatus\", \"arguments\": {\"status\":\"" + status + "\", \"remark\": \"" + remark + "\"}}")
这成为LoginAndBuy 类方法的一部分。
def getSuccessStatus(self):
set_test_status(self.page, "passed", "Success")
def getFailedStatus(self):
set_test_status(self.page, "failed", "Test failed")
最后,我们关闭浏览器上下文。
def closeBrowser(self):
self.browser.close()
FileName - testScenarios / singleLoginBuyRun.py。
singleLoginBuyRun.py文件运行登录和产品购买测试案例。首先,我们导入Playwright同步模块并使用sys包解决系统路径。
import sys
sys.path.append(sys.path[0] + "/..")
from playwright.sync_api import sync_playwright
我们还必须导入LoginAndBuy 类。
from testScripts.singleLoginBuyScript import LoginAndBuy
接下来是在Playwright事件循环中的类实例声明,接着是在选定的浏览器上启动网站。
with sync_playwright() as playwright:
try:
playwright = LoginAndBuy(playwright)
playwright.launchWeb()
以下步骤发生在事件循环中。
**步骤1:**用注册的账户再次登录。下面是事件循环中的登录步骤声明。
playwright.fillEmail("anEmailgmai@gmail.com")
playwright.fillPassword("mypassword")
playwright.clickLogin()
第2步:搜索一个产品并进入产品页面。
playwright.fillSearchBox("Nikon")
playwright.clickSearchButton()
第3步:选择你搜索到的商品,进入商品页面。
playwright.clickProduct()
第4步:将选定的产品添加到购物车中。
playwright.clickAddToCart()
第5步:用购买的产品结账。
playwright.clickCheckOutModal()
第6步:事件循环以注销步骤结束。成功状态必须在try子句中,因为只有当try块中的一系列代码起作用时,它才会运行。
playwright.hoverMenuBox()
playwright.clickLogout()
playwright.getSuccessStatus()
否则,失败状态只有在出现异常时才会运行。
except:
playwright.getFailedStatus()
最后,无论事件循环中发生什么,我们都要关闭浏览器。
playwright.closeBrowser()
在云网格上执行登录和产品购买测试。
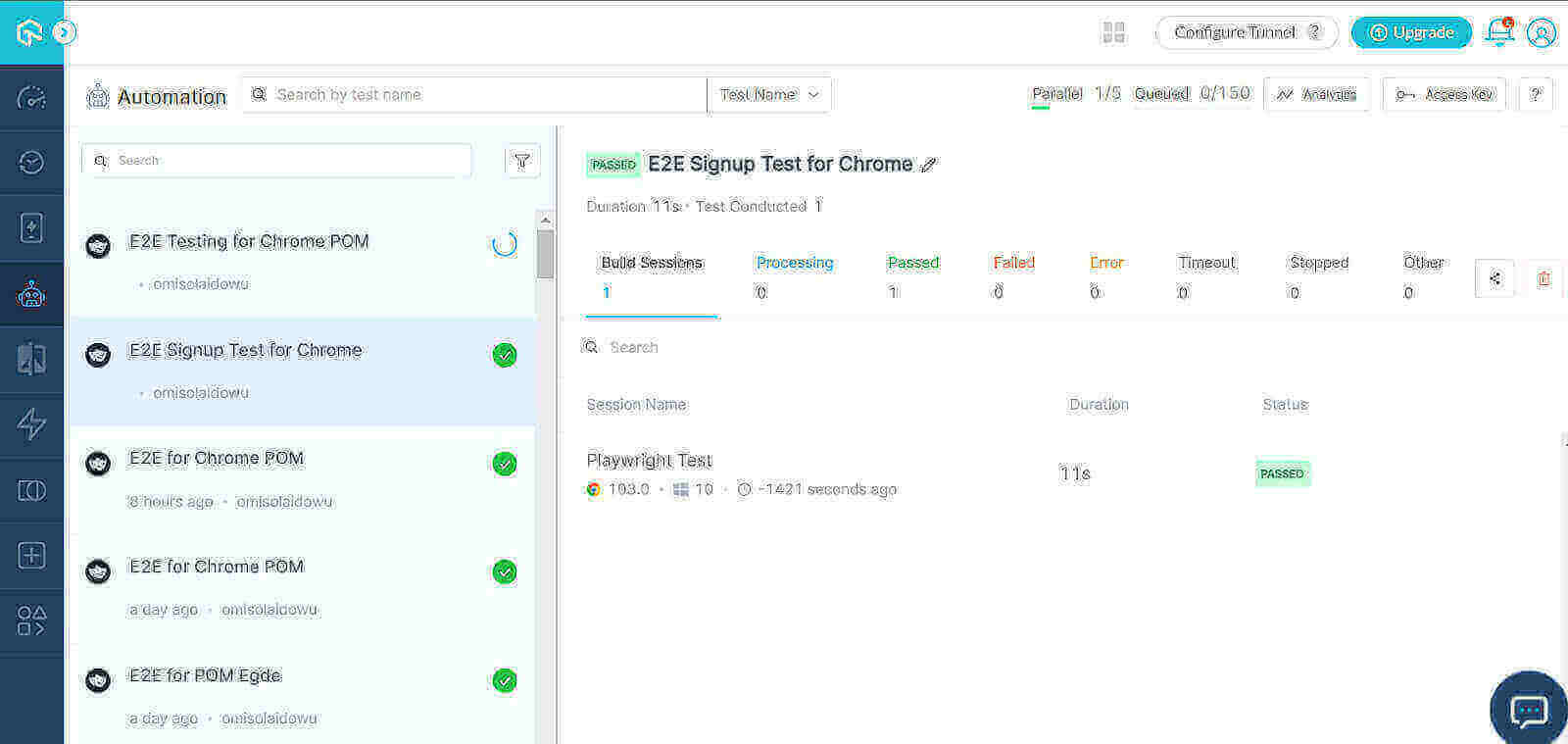
为了执行这个测试案例。
python singleLoginBuyRun.py
如图所示,该测试在云网格上成功运行。
用Playwright Python实现并行测试
一次性对多个浏览器进行跨浏览器的回归测试有助于更快地发现问题,使你能够继续进行其他工作。为了测试效率,我们将继续为并行测试保持相同的浏览器配置。
在云网格上并行运行测试案例有助于你模拟云中的服务器实例,你可以在不同的云主机上并发运行你的测试案例。这有助于检查你的应用程序是否在不同的集成环境中正常工作。
在这种情况下,并行测试的概念是通过能力阵列来迭代测试案例。因此,在本节 Playwright Python 教程中,我们将在两种浏览能力上运行注册和登录测试;Chrome 和 Microsoft Edge。
注意:整个测试套件共享testCap.py文件,我们在前面已经展示过。然而,选择器模块**(registrationPageSelectors.py和loginAndBuySelectors.py**)对于注册和登录购买的并行测试案例也保持不变。
注册并行测试实现。
FileName - testScripts/parallelSignup.py
FileName - testScenarios/parallelSignupRun.py
Playwright Python代码演练。
FileName - testScripts/parallelSignup.py:
我们在脚本的顶部导入测试所需的模块。
from playwright.sync_api import sync_playwright
import sys
sys模块将Python指向根目录路径。然后我们导入elementSelector和testCapabilities类。
from elementSelectors.registrationPageSelectors import elementSelector
from testCapabilities.testCaps import testCapabilities
接下来是创建对象实例。select变量是elementSelector类的实例,而capacity则是testCapabilities类的实例。
select = elementSelector()
capability = testCapabilities()
我们启动Register类,就像我们在之前的单一测试中做的那样。但是这一次,我们将能力方法**(Chrome()和Edge()**)插入到一个列表中--这样我们就可以遍历每个浏览器实例,从而启动一个跨浏览器的并行测试。
所以在**__init__**函数中值得注意的是。
self.allCaps = [capability.Edge(), capability.Chrome()]
接下来是浏览器上下文的迭代,以self.pages继承的pages列表结束。
self.browsers = [playwright.chromium.connect(i) for i in self.allCaps]
pages = [i.new_page() for i in self.browsers]
self.pages = pages
**launchWeb()**方法也是通过浏览器上下文的迭代,在每个浏览器中启动测试网站。然后我们打印出每个页面的标题。
def launchWeb(self):
for page in self.pages:
page.goto(select.webPage())
title = page.title()
print(title)
这个迭代过程对Register 类下的每个测试方法都会继续进行。
def fillFirstName(self, data):
for page in self.pages:
page.locator(select.firstName()).fill(data)
def fillLastName(self, data):
for page in self.pages:
page.locator(select.lastName()).fill(data)
def fillEmail(self, data):
for page in self.pages:
page.locator(select.eMail()).fill(data)
def fillPhone(self, data):
for page in self.pages:
page.locator(select.Telephone()).fill(data)
def fillPassword(self, data):
for page in self.pages:
page.locator(select.Password()).fill(data)
def confirmPassword(self, data):
for page in self.pages:
page.locator(select.confirmPassword()).fill(data)
def subscribe(self):
for page in self.pages:
page.locator(select.Subscribe()).click()
def acceptPolicy(self):
for page in self.pages:
page.locator(select.privacyPolicy()).click()
def submit(self):
for page in self.pages:
page.locator(select.Submit()).click()
def continueToDashboard(self):
for page in self.pages:
page.locator(select.goToDashboard()).click()
然后我们定义了状态方法,以便在网格用户界面中获得相应的信息。
def getSuccessStatus(self):
for page in self.pages:
set_test_status(page, "passed", "Success")
def getFailedStatus(self):
for page in self.pages:
set_test_status(page, "failed", "Test failed")
脚本以关闭浏览器上下文结束。
def closeBrowser(self):
for browser in self.browsers:
browser.close()
FileName - testScenarios / parallelSignupRun.py。
这里的测试运行器文件没有什么变化。我们导入所有的模块并将Python指向根目录,就像我们之前做的那样。然而,这一次,我们从parallelSignup模块中导入Register类,因为这是一个并行测试。
import sys
sys.path.append(sys.path[0] + "/..")
from testScripts.parallelSignup import Register
from playwright.sync_api import sync_playwright
在sync_playwright()事件循环下调用的方法使用Register类实例(playwright)运行并行的注册测试。
with sync_playwright() as playwright:
try:
playwright = Register(playwright)
测试步骤并没有改变。但是这一次,它们是并行运行的。
**第1步:**在考虑到的两个浏览器上下文中进入注册页面。
playwright.launchWeb()
第2步:在两个浏览器上平行地填写注册表。
playwright.fillFirstName("Idowu")
playwright.fillLastName("Omisola")
playwright.fillEmail("some7gmail@gmail.com")
playwright.fillPhone("08122334433")
playwright.fillPassword("mypassword")
playwright.confirmPassword("mypassword")
playwright.subscribe()
playwright.acceptPolicy()
第3步:在两个浏览器上提交表格。
playwright.submit()
第4步:第一次进入你的仪表板。然后用网格用户界面上的状态信息(通过或失败)来结束测试的执行。
playwright.continueToDashboard()
playwright.getSuccessStatus()
except Exception as err:
playwright.getFailedStatus()
最后,调用**closeBrowser()**方法,关闭所有浏览器实例,结束测试。
playwright.closeBrowser()
注册并行测试执行。
运行 parallelSignupRun.py 文件。
python parallelSignupRun.py
我们的平行跨浏览器测试案例在LambdaTest云网格上同时运行,如图所示。
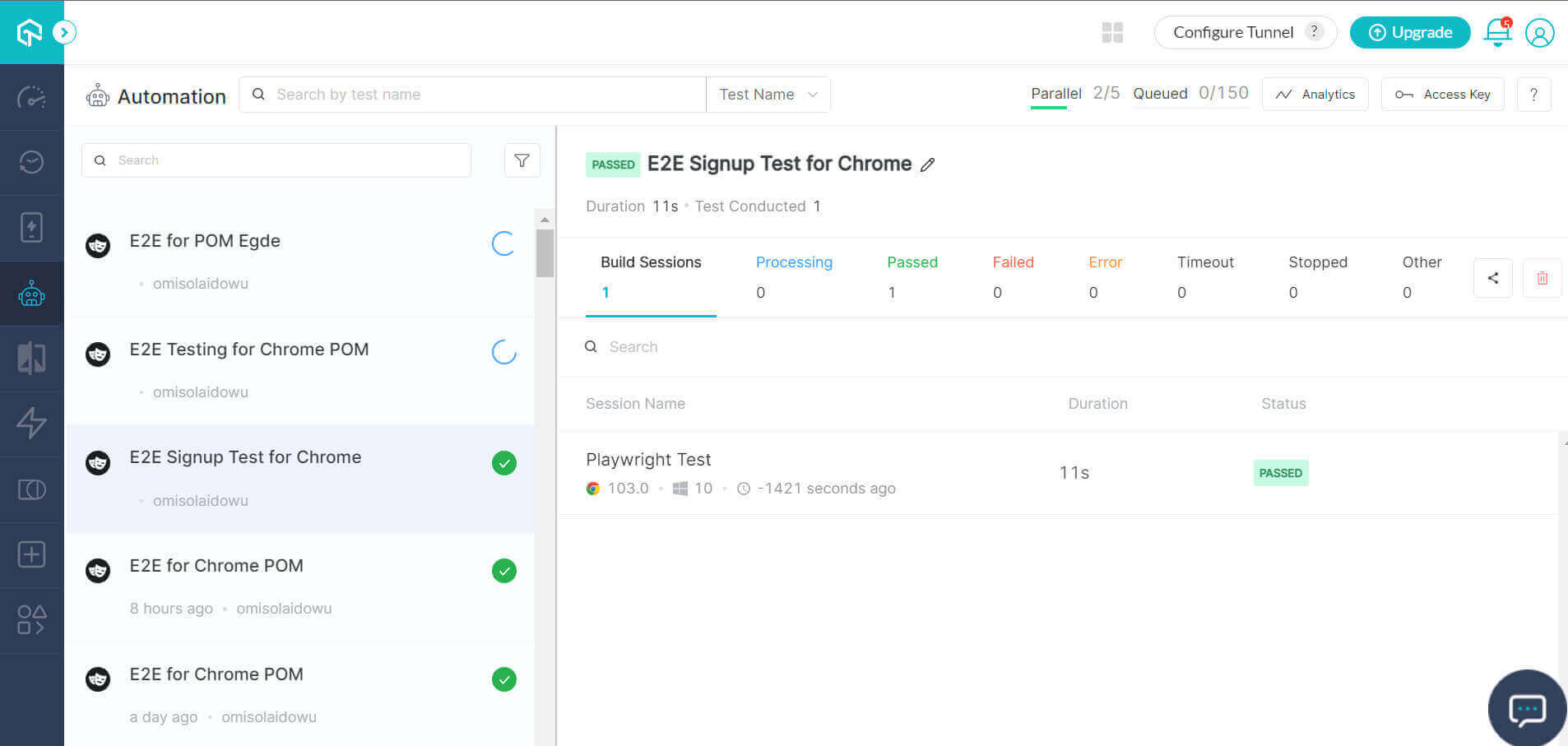
执行(登录和购买用例)。
FileName - testScripts / parallelLoginBuyScript.py
FileName - testScenarios / parallelLoginBuyRun.py。

Playwright Python代码演练。
FileName - testScripts / parallelLoginBuyScript.py:
我们首先在parallelLoginBuyScript.py文件中为测试案例导入所有必要的模块。
from playwright.sync_api import sync_playwright
import sys
sys.path.append(sys.path[0] + "/..")
from elementSelectors.loginAndBuySelectors import elementSelector
from testCapabilities.testCaps import testCapabilities
接下来是elementSelector和testCapabilities类的一个实例。
select = elementSelector()
capability = testCapabilities()
然后我们设置测试状态函数,在云网格用户界面上触发失败或成功信息。记住,我们将把它作为loginAndBuy类的一个方法来实现。
def set_test_status(page, status, remark):
page.evaluate("_ => {}",
"lambdatest_action: {\"action\": \"setTestStatus\", \"arguments\": {\"status\":\"" + status + "\", \"remark\": \"" + remark + "\"}}")
loginAndBuy继承了Playwright类的方法。正如你所看到的,__init__ 函数接受了一个额外的playwright参数。
class LoginAndBuy:
def __init__(self, playwright) -> None:
我们必须遍历浏览器功能,然后为每个浏览器实例化一个浏览器上下文。因此,self.pages属性继承了从循环中创建的页面列表。
def __init__(self, playwright) -> None:
self.allCaps = [capability.Edge(), capability.Chrome()]
self.browsers = [playwright.chromium.connect(i) for i in self.allCaps]
pages = [i.new_page() for i in self.browsers]
self.pages = pages
接下来,我们在循环中的两个浏览器上下文中启动测试网站。
def launchWeb(self):
for page in self.pages:
page.goto(select.webPage())
title = page.title()
print(title)
该类中的其他方法需要一个事件处理程序,我们将在另一个文件中的事件循环中运行该程序。
def fillEmail(self, data):
for page in self.pages:
page.locator(select.eMail()).fill(data)
def fillPassword(self, data):
for page in self.pages:
page.locator(select.Password()).fill(data)
def clickLogin(self):
for page in self.pages:
page.locator(select.loginAccount()).click()
def fillSearchBox(self, data):
for page in self.pages:
page.locator(select.searchProduct()).fill(data)
def clickSearchButton(self):
for page in self.pages:
page.locator(select.searchButton()).click()
def clickProduct(self):
for page in self.pages:
page.locator(select.Product()).click()
def clickAddToCart(self):
for page in self.pages:
page.locator(select.addCart()).click()
def clickCheckOutModal(self):
for page in self.pages:
page.locator(select.checkOut()).click()
def hoverMenuBox(self):
for page in self.pages:
page.locator(select.hoverBox()).hover()
def clickLogout(self):
for page in self.pages:
page.locator(select.logoutUser()).click()
我们还将测试状态函数声明为loginAndBuy类下的方法。
def getSuccessStatus(self):
for page in self.pages:
set_test_status(page, "passed", "Success")
def getFailed(self):
for page in self.pages:
set_test_status(page, "failed", "Test failed")
最后,我们遍历浏览器上下文,关闭已打开的实例。
def closeBrowser(self):
for browser in self.browsers:
browser.close()
FileName - testScenarios / parallelLoginBuyRun.py。
我们在并行测试运行器文件中导入了所有的基本包。然而,这次感兴趣的自定义类是loginAndBuy。
import sys
sys.path.append(sys.path[0] + "/..")
from testScripts.parallelLoginBuyScript import LoginAndBuy
from playwright.sync_api import sync_playwright
playwright_sync事件循环运行并行测试案例,从loginAndBuy类的playwright实例开始,随后在两个浏览器上下文中启动网站。
with sync_playwright() as playwright:
try:
playwright = LoginAndBuy(playwright)
playwright.launchWeb()
**第1步:**填写登录表并在并行测试中考虑的两个浏览器上下文中登录。
playwright.fillEmail("some3gmail@gmail.com")
playwright.fillPassword("mypassword")
playwright.clickLogin()
第2步:搜索一个产品,并点击搜索按钮。
playwright.fillSearchBox("Nikon")
playwright.clickSearchButton()
第**3步:**找到后点击产品页面,进入产品页面。
playwright.clickProduct()
第4步:点击 "添加到购物车"按钮,将产品添加到购物车中。
playwright.clickAddToCart()
第5步:在产品页面结账。
playwright.clickCheckOutModal()
第6步:注销网站,在LambdaTest云网格用户界面上返回成功状态。
playwright.hoverMenuBox()
playwright.clickLogout()
playwright.getSuccessStatus()
如果测试因任何原因而失败,except块内的**getFailed()**方法就会运行,并在网格UI上返回一个失败信息。
except:
playwright.getFailed()
关闭每个浏览器上下文的事件循环也很重要,以防止无休止的循环。我们在try-except块之外做这个,以避免终止冲突。
playwright.closeBrowser()
执行登录和购买并行测试。
运行parallelLoginBuyRun.py文件。
python parallelLoginBuyRun.py
下面是云网格上选定的浏览器的并行测试执行情况。
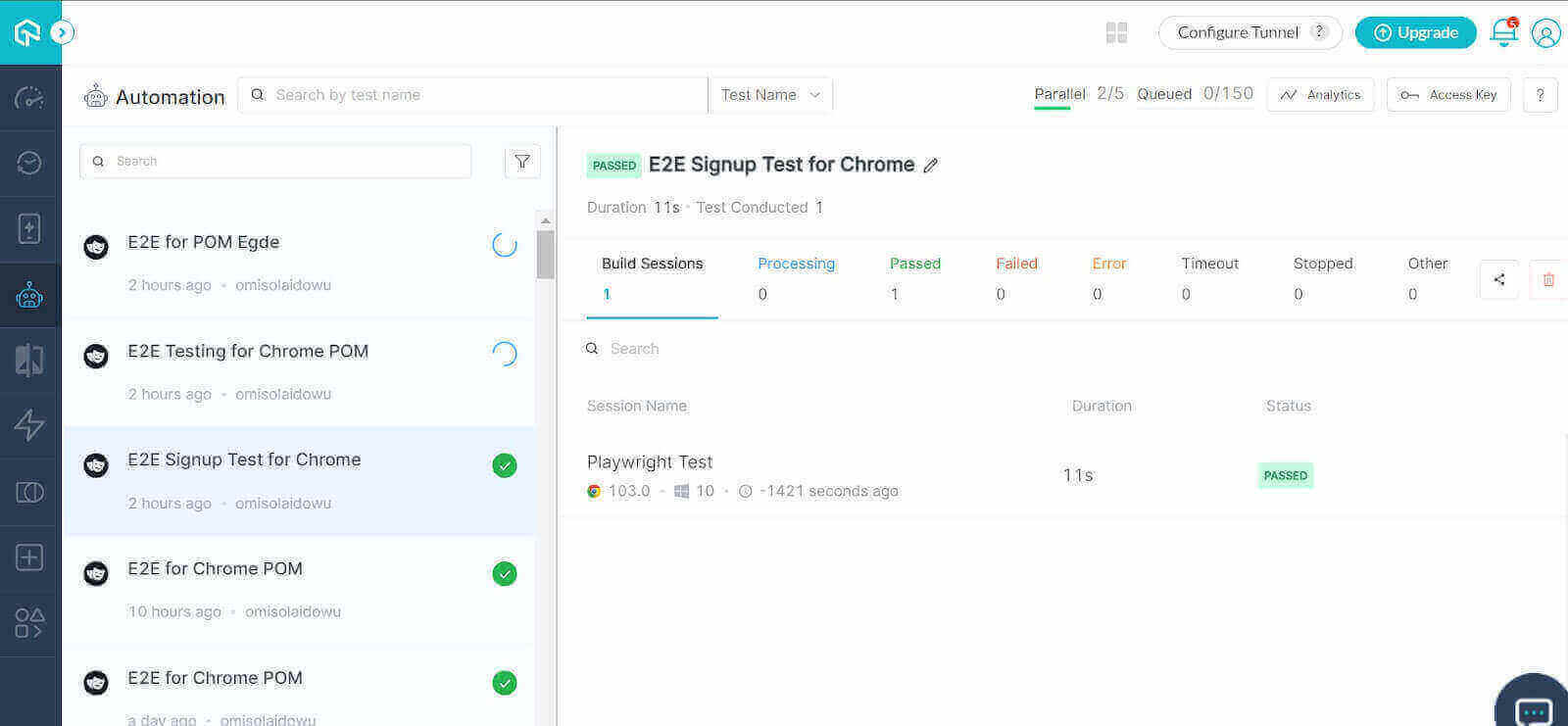
结论
Playwright测试框架为端到端测试提供了简单的方法。在这篇文章中,我们演示了使用Playwright Python进行单一和并行测试。而且,为了简单起见,我们把所有的测试用例都包裹在POM模型里面。
我们首先探索了Playwright的代码生成器的力量,以及它如何帮助我们自动创建测试用例代码和选择器。但由于该方法复杂且不可扩展,我们进一步在LambdaTest电子商务平台上对用户注册和产品购买实施了单一的自定义端到端的Playwright测试。
这促使我们对类似的测试场景进行了跨浏览器的并行测试。而且你还看到了如何创建连接你的测试和LambdaTest云网格的类方法。
常见问题解答(FAQ)
什么是端到端测试?
端到端测试是一种方法,它在从头到尾的过程中评估一个复杂产品的工作秩序。端到端方法对整个系统施加压力,确保所有组件都能在真实世界的情况下运行并发挥最佳性能。
Playwright比Selenium好吗?
Selenium是一个免费的、开源的网络应用程序测试框架,使用户能够编写针对网络应用程序的自动测试。Playwright缺乏Selenium中的一些功能,如调度自动测试,或提供支持从被测试的应用程序之外记录测试(例如,记录手动测试的回放)。
