


Pyspark lit()简介
Pyspark的lit()函数用于将新的列添加到已经创建的数据框中;我们通过分配一个常数或字面值来创建一个新的列。lit函数将返回类型作为一个列。我们可以通过导入SQL函数来导入PySpark lit的函数。假设我们需要在数据框中添加一个新的列,那么lit函数就很有用。
什么是PySpark lit()?
在python中,PySpark模块提供了类似于使用数据框架的处理方式。一个lit函数被用来创建新的列,在PySpark的数据框架中为该列添加常量值。它有助于连接RDDs,这是用py4j的库实现的。Pyspark只不过是一个库,它是通过对大量非结构化和结构化数据的分析而开发的。要在python中使用lit函数,我们需要python版本为3.0,apache spark版本为3.1.1或更高。
在哪里使用PySpark lit()函数?
我们可以在需要在创建的数据框架中添加列的地方使用lit函数。下面的语法显示了我们可以在哪里使用lit函数,如下所示。
语法。
lit(val) .alias(name_of_column)
在上面的例子中,列名是我们要添加到数据集中的列的名称。Value只不过是我们要添加到新列中的常量值。我们使用lit函数来添加新的列到数据集。
下面的例子显示了我们使用lit函数的情况,如下所示。
在下面的例子中,我们导入了 pyspark, spark session, col, 和 lit 模块。我们定义了用于创建数据框架的py变量。在创建了数据框架之后,我们在数据框架中添加了列名emp_code列。
代码。
import pyspark
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, lit
py = SparkSession.builder.appName('pyspark lit function').getOrCreate()
emp = [{'emp_id' : '11', 'emp_name' : 'ABC', 'emp_age' : 32},
{'emp_id' : '13', 'emp_name' : 'PQR', 'emp_age' : 36},
{'emp_id' : '15', 'emp_name' : 'XYZ', 'emp_age' : 41}]
pyspark = py.createDataFrame(emp)
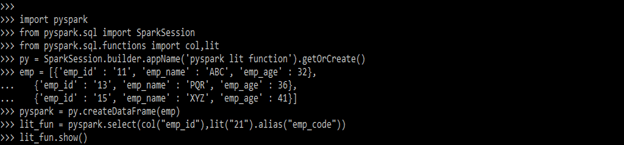
lit_fun = pyspark.select(col("emp_id"),lit("21").alias("emp_code"))
lit_fun.show()
在下面的例子中,我们正在向emp数据集添加两列。我们正在向emp数据集添加emp_code和emp_addr列,如下所示。
代码。
import pyspark
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, lit
py = SparkSession.builder.appName('pyspark lit function').getOrCreate()
emp = [{'emp_id' : '11', 'emp_name' : 'ABC', 'emp_age' : 32},
{'emp_id' : '13', 'emp_name' : 'PQR', 'emp_age' : 36},
{'emp_id' : '15', 'emp_name' : 'XYZ', 'emp_age' : 41}]
pyspark = py.createDataFrame(emp)
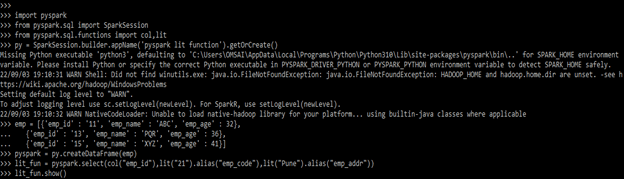
lit_fun = pyspark.select(col("emp_id"),lit("21").alias("emp_code"),lit("Pune").alias("emp_addr"))
lit_fun.show()
如何使用PySpark lit()?
基本上,我们正在使用lit函数向数据集中添加一个带有常量值的新列。下面的步骤显示了我们如何使用lit函数,如下所示。
为了使用PySpark的lit函数,我们需要在系统中安装PySpark。
- 在第一步,我们要在系统中安装PySpark模块。我们通过使用pip命令来安装这个模块,如下所示。
pip install pyspark

- 安装完模块后,在这一步中,我们通过使用python命令登录到python中,如下所示。
python

- 登录python后,在这一步,我们导入col、lit、PySpark和SparkSession模块。我们是通过使用import关键字来导入所有模块的。
import pyspark
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, lit

- 导入模块后,在这一步,我们将创建应用程序的名称为pyspark lit函数。我们定义应用程序的变量名为py。
py = SparkSession.builder.appName('pyspark lit function').getOrCreate()

- 在这一步,我们正在创建stud数据框。我们正在创建有三行的数据,如下所示。
stud = [{'stud_id' : '41', 'stud_name' : 'AB', 'stud_age' : 12},
{'stud_id' : '43', 'stud_name' : 'PQ', 'stud_age' : 6},
{'stud_id' : '45', 'stud_name' : 'XY', 'stud_age' : 7}]

- 在这一步中,我们通过使用stud数据创建一个数据框,我们将数据框的变量定义为lit_fun。
lit_fun = py.createDataFrame(stud)

- 在这一步中,我们将通过使用lit函数在stud数据集中添加stud_addr列。在添加一个新的列时,我们也给该列一个常量值。
lit_fun1 = lit_fun.select(col("stud_id"), lit("Pune").alias("stud_addr"))
lit_fun1.show()

例子
下面是不同的例子。
例子#1
在下面的例子中,我们正在添加一个新的列名为stud_addr,如下所示。
代码。
import pyspark
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, lit
pyspark_lit = SparkSession.builder.appName (pyspark lit function').getOrCreate()
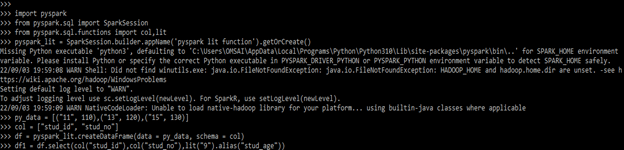
py_data = [("11", 110), ("13", 120), ("15", 130)]
col = ["stud_id", "stud_no"]
df = pyspark_lit.createDataFrame(data = py_data, schema = col)
df1 = df.select(col("stud_id"),col("stud_no"),lit("9").alias("stud_age"))
df1.show(truncate=False)
输出。
例子#2
这里我们有条件地添加一个新的列。
代码:
import pyspark
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, lit
from pyspark.sql.functions import when
pyspark_fun = SparkSession.builder.appName ('pyspark lit function').getOrCreate()
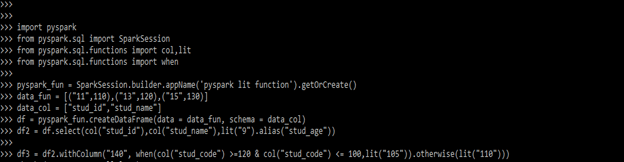
data_fun = [("11", 110), ("13", 120), ("15", 130)]
data_col = ["stud_id", "stud_code"]
df = pyspark_fun.createDataFrame (data = data_fun, schema = data_col)
df2 = df.select (col("stud_id"), col("stud_code"), lit("9").alias("stud_age"))
df3 = df2.withColumn ("140", when(col("stud_code") >= 120 & col ("stud_code") <= 100, lit("105")).otherwise (lit("110")))
df3.show(truncate=False)
输出。
主要收获
- lit函数用来向已经在pyspark中创建的数据集添加新列。
- 我们可以在数据框中添加新的列时添加一个常量值。我们还可以在使用lit函数时添加条件。
常见问题
下面是提到的常见问题。
Q1.python中的lit函数有什么用?
解答基本上,python中的lit函数是用来在已经创建的数据框中添加新的列。
Q2.在pyspark的lit函数中,我们使用了哪些模块?
答:我们使用的是col,lit,当。 在使用python中的lit函数时,我们使用了col, lit, when, spark session, 和 pyspark模块。
Q3.pyspark中的lit和typedlit函数的区别是什么?
解答l it和typedlit函数是用来在已经创建的数据框架中添加列的。这两个函数在pyspark中做的工作是一样的。
结论
lit函数用于在pyspark的数据框架中通过添加常量值来创建新的列。Pyspark的lit函数用于在已经创建的数据框架中添加新的列,我们通过指定一个常数或字面值来创建一个新的列。
推荐文章
这是一篇关于PySpark lit()的指南。在这里,我们讨论了PySpark lit()函数的介绍和如何使用,以及不同的例子。
The postPySpark lit()appeared first onEDUCBA.
