持续创作,加速成长!这是我参与「掘金日新计划 · 10 月更文挑战」的第6天,点击查看活动详情
在第一篇打分系统漫谈1 - 时间衰减我们聊了两种相对简单的打分算法Hacker News和Reddit Hot Formula,也提出了几个这两种算法可能存在的问题,这一篇我们就其中的一两个问题进一步讨论:
- 如何综合浏览量和点赞量对文章进行打分[期望效用函数->点赞率]
- 如何解决浏览量较小时,点赞率不置信的问题[wald Interval -> wilson]
Reddit Hot Formula? 期望效用函数!
让我们从上一篇我们提到的Reddit Hot Formula来说起,抛开文章质量的惩罚项,只考虑点赞拍砖的低配版打分公式是
score=sign(U−D)∗log10∣U−D∣+seconds/4500
Evan从经济学期望效用这个新颖的角度试图对上述公式进行复现,几个基本假设包括:
- 用户刷新界面的行为∼Poisson(λ)
- 每次刷新看到新/老文章的概率是q/(1−q), 喜欢/不喜欢的概率是p/(1−p)
- 老文章效用为0,喜欢的新文章效用为1, 不喜欢的新文章效用为-1
上述概率p,q可以用已有数据进行估计:
-
在没有任何和文章相关的信息时,喜欢不喜欢的概率是一样的p=21, 当我们获得一篇文章的点赞量和拍砖数时我们可以用点赞率对概率进行更新得到p=U+D+2U+1
-
概率q是一篇t时刻前发布的文章没有被作者读过的概率,换言之就是用户在t时间内没有刷新界面的概率q=p(Nλ=0)=p(x>t)=exp(−λt)
综上我们可以得到对数效用的表达式:
Utility=p∗q−(1−p)∗q=exp(−λt)∗(U+D+2U+1−U+D+2D+1)=exp(−λt)∗(U+D+2U−D)log(Utility)=log(U−D)−log(U+D+2)−λt
和上述Reddit Hot Formula对比我们会发现当U>D的时候,两个表达式是基本一致的,最大的不同是Reddit没有期望效用的第二个对数项log(U+D+2)。换言之Reddit只考虑点赞量而没有考虑点赞量对应的基数,这个基数可以是点赞+拍砖或者是用户的浏览量。
我们举个例子你就会明白这种打分可能存在的问题,我们拿Stack overflow来举个例子,下图的两个问题获得了差不多的投票57 vs. 53,但是会发现第一个问题比第二个问题多一倍的浏览量4k vs. 2K, 所以从投票率来看反而是第二个问题的投票率更高。
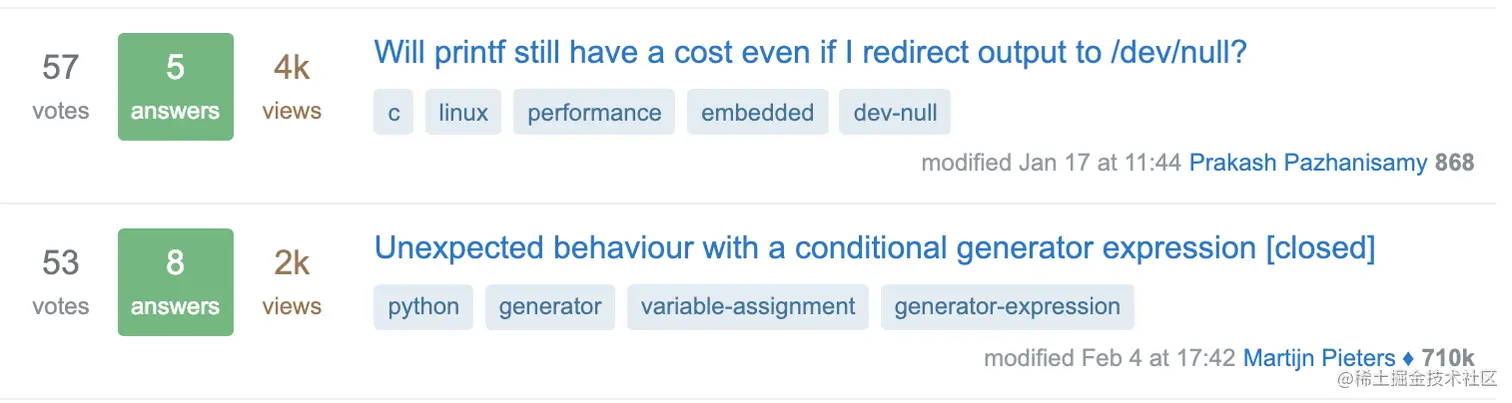
点估计?区间估计!
这样看似乎我们应该使用点赞(投票)率而非简单的点赞量来对文章进行打分,但是点赞率真的永远可信么? 我们再看一个例子


单从投票率来看,第一个问题投票率高达50%但是浏览量只有2 ,而第二个问题投票率较低但是浏览量很高。如果但从投票率来看,似乎第一个问题排名更高,但是直觉告诉我们第二个问题应该排名更靠前。这就涉及统计学中点估计的置信度问题。
让我们来把用户点赞这个行为抽象一下,我们假设每一个用户要么点赞要么拍砖,每一个用户之间的行为之间独立,所以每个用户∼Bernoulli(p), 其中p是点赞的概率。当样本量足够大的时候,根据大数定律用户点赞的频率会趋于点赞率x→∞limP(∣nnx−p∣<ϵ)=1
但是当用户量不够,样本比较小的时候,计算的点赞率会和总体概率会存在较大的偏差。一种解决方法就是使用区间估计而非点估计,我们给出点赞率估计的下边界而非点赞率的估计值。
最常用的二项分布的区间估计由近似正态分布给出。根据大数定律,参数为n,p的二项分布在n→∞的时候 p(1−p)/np^−p∼N(0,1)。根据正态分布的置信区间我们会得到二项分布的近似区间估计如下
p(∣p(1−p)/np^−p∣<zα/2)=1−αwhere置信度是0.95,α=0.05p^是根据每个用户点赞行为给出的点赞率的估计n是样本量,可以是用户点赞+拍砖的总和,或者是用户浏览量p是总体的点赞率是我们希望得到的估计
Wald Interval 对上述近似区间用样本估计p^替代总体p,给出了最常用的二项分布置信区间:
p−,p+=p^±zα/2p^(1−p^)/n
wald置信区间适用大多数情况,但是在下面三个情况下会存在问题:
- 样本不够,n太小时,p^和总体的p相比会偏差较大
- p→0 or p→1会导致方差趋于0,使得置信区间显著偏窄
- p=0,1 置信区间长度为0
而在估计文章点赞率这个场景下我们不可避免的会碰到上述3个情况,在这种情况我们往往会使用更加复杂的置信区间算法。来来来下面让我们说说其中一种高配版的置信区间- Wilson Interval
Wilson Score
Wilson对Walt置信区间做了修正, Wilson置信区间的上下界如下:
p−,p+=1+nzα/22p^+2nzα/22±zα/21+nzα/22np^(1−p^)+4n2zα/22
看着老复杂了,让我们来拆解一下你就会发现原理蛮好理解的。先说说对总体均值的估计,wilson对p^进行了如下调整:
p^→p~=1+nzα/22p^+2nzα/22
当样本量足够大Wilson和Walt对总体均值的估计会趋于一致。当样本量很小的时候, 不同于walt,wilson给样本估计加了一个21的贝叶斯前置概率(点赞和拍砖的概率各是50%),然后不断用新增样本来对这个前置概率进行调整。从而避免样本较小的时候样本估计过度偏离总体的问题。
whenn→∞limp~→p^whenn→0limp~→21
方差部分也做了相同的处理, 当样本足够大的时候wilson和walt对总体方差的估计会趋于一致,但是当样本小的时候和上述样本均值的处理方法一样,会趋于贝叶斯前置概率对应的方差p^→21⇒p^(1−p^)→41
np^(1−p^)→1+nzα/22np^(1−p^)+4n2zα/22
下面两张图片很直观的给出了不同样本数量(n=10 vs.100)下,样本均值的估计所对应的置信区间的长度(方差估计)。当样本大的时候Wilson和Wald几乎一样,当样本小的时候,随着p趋于0 or 1,Wilson置信区间会显著宽于Walt区间。
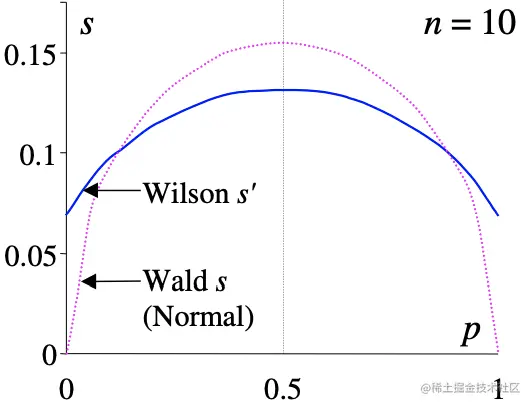
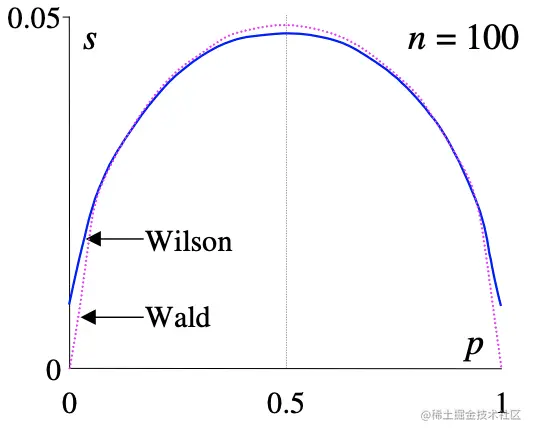
而Wilson打分就是取Wilson置信区间的下界:
score=1+nzα/22p^+2nzα/22−zα/21+nzα/22np^(1−p^)+4n2zα/22
Wilson打分方式有几个很好的特性:
- 点赞率(p)一样,浏览量(n)越高得分越高
- 点赞率趋于0时, score = 0
- 点赞率趋于1时, score = 1+zα/22/n1, 浏览量越高,得分越接近1,反之浏览量越小,得分越低,这样会对小样本点赞率高的问题进行调整
- 置信度越高,zα/2越大,点赞率越不重要,而样本量n越重要
在下一篇文章我们继续聊聊另一种更灵活的处理小样本打分的方法- 贝叶斯更新
Reference
- www.ucl.ac.uk/english-usa…
- www.ruanyifeng.com/blog/2012/0…
- www.evanmiller.org/how-not-to-…
- 二项分布参数的区间估计,朱永生《粒子物理数据分析基础与前沿》研讨会


