

现代浏览器架构
在开始介绍渲染流水线之前,我们需要先介绍一下 Chromium 的浏览器架构与 Chromium 的进程模型作为前置知识。
两个公式
公式 1: 浏览器 = 浏览器内核 + 服务
- Safari = WebKit + 其他组件、库、服务
- Chrome = Chromium + Google 服务集成
- Microsoft Edge (Chromium) = Chromium + Microsoft 服务集成
- Yandex Browser = Chromium + Yandex 服务集成
- 360 安全浏览器 = Trident + Chromium + 360 服务集成
- Chromium = Blink + V8 + 其他组件、库、服务
公式 2:内核 = 渲染引擎 + JavaScript 引擎 + 其他
| Browser | Rendering Engine | JavaScript Engine |
|---|---|---|
| Internet Export | Trident (MSHTML) | JScript/Chakra |
| Microsoft Edge | EdgeHTML → Blink | Chakra → V8 |
| Firefox | Gecko | SpiderMonkey |
| Safari | KHTML → WebKit | JavaScriptCore |
| Chrome | WebKit → Blink | V8 |
| Opera | Presto → WebKit → Blink | Carakan → V8 |
这里我们可以发现除了 Firefox 和已经死去的 IE,市面上大部分浏览器都朝着 Blink + V8 或是 WebKit + JavaScriptCore 的路线进行演变。
渲染引擎
负责解析 HTML, CSS, JavaScript,渲染页面。
以 Firexfox 举例,有以下工作组:
- Document parser (handles HTML and XML)
- Layout engine with content model
- Style system (handles CSS, etc.)
- JavaScript runtime (SpiderMonkey)
- Image library
- Networking library (Necko)
- Platform-specific graphics rendering and widget sets for Win32, X, and Mac
- User preferences library
- Mozilla Plug-in API (NPAPI) to support the Navigator plug-in interface
- Open Java Interface (OJI), with Sun Java 1.2 JVM
- RDF back end
- Font library
- Security library (NSS)
接下来,我们看看 WebKit 的发展历程。
Apple 2001 年基于 KHTML 开发了 WebKit 作为 Safari 的内核,之后 Google 在 2008 年时基于 WebKit 自研 Chromium,那时候的 Chrome 渲染引擎采用的也是 Webkit。2010 年时,Apple 升级重构了 WebKit,其就是如今 WKWebView 与 Safari 的渲染引擎 WebKit2。2013 年时,Google 基于 WebKit 开发了自己的渲染引擎—— Blink,其作为如今 Chromium 的渲染引擎。因为开源协议的关系,我们如今看 Blink 源码依然能看到很多 Apple 和 WebKit 的影子。
WebKit 的演变路线大致历程如下图所示:
通过 Web Platform Tests 的测试报告可见 Chromium 渲染引擎的兼容性也是极好的:
JavaScript 引擎
JavaScript 引擎在浏览器中通常作为渲染引擎内置的一个模块,但同时它的独立性非常好,也可以作为独立的引擎移植到其他地方使用。
这里列举几个业内有名的 JavaScript 引擎:
- SpiderMonkey: Mozilla 的 JavaScript 引擎,使用 C/C++ 编写,作为 Firefox 的 JavaScript 引擎。
- Rhino: Mozilla 的开源 JavaScript 引擎,使用 Java 编写。
- Nashorn: Oracle Java Development Kit (JDK) 8 开始内置的 JavaScript 引擎,使用 Java 编写。
- JavaScriptCore: WebKit 内置的 JavaScript 引擎,其作为系统提供给开发者使用,iOS 移动端应用可以直接零增量引入 JavaScriptCore(但这种场景下无法开启 JIT)。
- ChakraCore: Microsoft 的开源 JavaScript 引擎,而如今已全面使用 Chromium 作为 Edge,因此除了 Edge iOS 移动端以外(Chromium iOS 端使用 JavaScriptCore 作为 JavaScript 引擎),其他端的 Edge 使用的都是 V8 引擎。
- V8: Google 的开源 JavaScript 引擎,使用 C++ 编写,作为 Chromium(或者更进一步可以说 Blink)的内置 JavaScript 引擎,同时也是 Android 系统 WebView 的内置引擎(因为 Android WebView 也是 Chromium 嘛,笑)。性能优异,开启 JIT 之后的性能吊打一众引擎。此外,ES 语法兼容性表现也比较优秀(可见后文表格)。
- JerryScript: Samsung 开源的 JavaScript 引擎,被 IoT.js 使用。
- Hermes: Facebook 的开源 JavaScript 引擎,为 React Native 等 Hybrid UI 系统打造的引擎。支持直接加载字节码,从而使得 JS 加载时间缩短,让 TTI 得到优化。此外引擎还对字节码做过优化,且支持增量加载,对中低端机更友好。但是其设计为胶水语言解释器而存在,故不支持 JIT。(移动端 JS 引擎会限制 JIT 的使用,因为开 JIT 之后预热时间会变得很长,从而影响页面首屏时间;此外也会增加包体积和内存占用。)
- QuickJS: 由 FFmpeg 作者 Fabrice Bellard 开发,体积极小(210 KB),且兼容性良好。直接生成字节码,且支持引入 C 原生模块,性能优异。在单核机器上有着 300 μs 极低的启动时间,内存占用也极低,使用引用计数,内存管理优秀。QuickJS 非常适用于 Hybrid 架构、游戏脚本系统或其他嵌入式系统。
各引擎性能表现如下图所示:
ECMAScript 标准支持情况:
Chromium 进程模型
Chromium 有 5 类进程:
- Browser Process:1 个
- Utility Process:1 个
- Viz Process:1 个
- Plugin Process:多个
- Render Process:多个
抛开 Chrome 扩展的 Plugin Process,和渲染强相关的有 Browser Process、Render Process、Viz Process。接下来,我们重点看看这 3 类进程。
Render Process
- 数量:多个
- 职责:负责单个 Tab 内单个站点(注意跨站点 iframe 的情况)的渲染、动画、滚动、Input 事件等。
- 线程:
- Main thread x 1
- Compositor thread x 1
- Raster thread x 1
- worker thread x N
Render Process 负责的区域是 WebContent:
Main thread
职责:
- 执行 JavaScript
- Event Loop
- Document 生命周期
- Hit-testing
- 事件调度
- HTML、CSS 等数据格式的解析
Compositor Thread
职责:
- Input Handler & Hit Tester
- Web Content 中的滚动与动画
- 计算 Web Content 的最优分层
- 协调图片解码、绘制、光栅化任务(helpers)
其中,Compositor thread helpers 的数目取决于 CPU 核心数。
Browser Process
- 数量:1 个
- 职责:负责 Browser UI (不包含 WebContent 的 UI)的全部能力,包括渲染、动画、路由、Input 事件等。
- 线程:
- Render & Compositing Thread
- Render & Compositing Thread Helpers
Viz Process
- 数量:1 个
- 职责:接受 Render Process 和 Browser Process 产生的 viz::CompositorFrame,并将其合成 (Aggregate),最后使用 GPU 将合成结果上屏 (Display)。
- 线程:
- GPU main thread
- Display Compositor Thread
Chromium 的进程模式
- Process-per-site-instance:老版本的默认策略,如果从一个页面打开了另一个新页面,而新页面和当前页面属于同一站点(根域名与协议相同)的话,那么这两个页面会共用一个 Render Process。
- Process-per-site
- Process-per-tab:如今版本的默认策略,每个 Tab 起一个 Render Process。但注意站点内部的跨站 iframe 也会启动一个新的 Render Process。可看下文 Example。
- Single Process:单进程模式,启动参数可控,用于 Debug。
示例:
假设现在有 3 个 Tab,分别打开了 foo.com,bar.com,baz.com 三个站点,其中 bar.com、baz.com 不涉及 iframe;但 foo.com 涉及,它的代码如下所示:
<html>
<iframe id=one src="foo.com/other-url"></iframe>
<iframe id=two src="bar.com"></iframe>
</html>
那么按照 Process-per-tab 模式,最终的进程模型如下图所示:
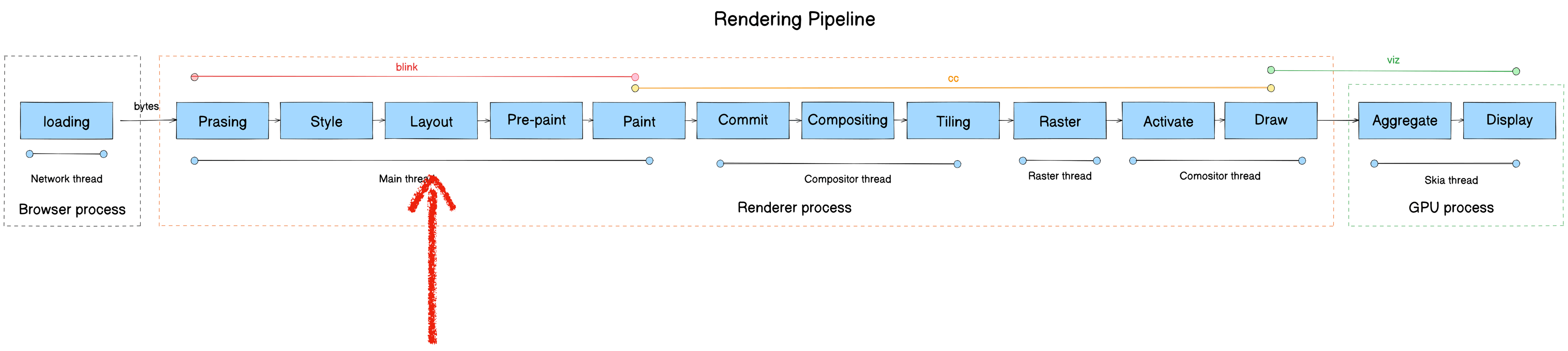
Chromium 渲染流水线
至今前置知识已介绍完毕,开启本文的核心部分 —— Chromium Rendering Pipeline。
所谓渲染流水线,就是从接受网络的字节码开始,一步步处理这些字节码把它们转变成屏幕上像素的过程。经过梳理之后,包括以下 13 个流程:
- Prasing
- Style
- Layout
- Pre-paint
- Paint
- Commit
- Compositing
- Tiling
- Raster
- Activate
- Draw
- Aggregate
- Display
整理了一下各自流程所在的模块与进程线程,绘制的最终流水线如下图所示:
下文,我们一步步来看。
注:本文属于 Overview,所以力求简洁、不贴源码,但是会把设计到源码的部分打上源码链接,读者们可以自己索引阅读。同时,有些环节我撰写了更详细的流程分析文章,会贴在对应章节的开头处,感兴趣的读者可以点进去详细阅读。
Prasing
本节推荐阅读该系列的文章《Chromium Rendering Pipeline - Prasing》以深入了解 Parsing。
- 模块:blink
- 进程:Render Process
- 线程:Main thread
- 职责:解析 Browser Process 网络线程传过来的 bytes,经过解析处理,生成 DOM Tree
- 输入:bytes
- 输出:DOM Tree
这个环节设计的数据流为:bytes → characters → token → nodes → object model (DOM Tree)
我们把数据流的每次扭转进行梳理,得到以下 5 个环节:
- Loading:Blink 从网络线程接收 bytes
- Conversion: HTMLParser 将 bytes 转为 characters
- Tokenizing: 将 characters 转为 W3C 标准的 token
- Lexing: 通过词法分析将 token 转为 Element 对象
- DOM construction: 使用构建好的 Element 对象构建 DOM Tree
Loading
职责:Blink 从网络线程接收 bytes。
流程:
- Browser process 下载网页内容
- 传给 Render Process 的 Content 模块
- blink::DocumentLoader
- blink::HTMLDocumentParser
Conversion
职责:将 bytes 解析为 characters。
核心堆栈:
#0 0x00000002d2380488 in blink::HTMLDocumentParser::Append(WTF::String const&) at /Users/airing/Files/code/chromium/src/third_party/blink/renderer/core/html/parser/html_document_parser.cc:1037
#1 0x00000002cfec278c in blink::DecodedDataDocumentParser::UpdateDocument(WTF::String&) at /Users/airing/Files/code/chromium/src/third_party/blink/renderer/core/dom/decoded_data_document_parser.cc:98
#2 0x00000002cfec268c in blink::DecodedDataDocumentParser::AppendBytes(char const*, unsigned long) at /Users/airing/Files/code/chromium/src/third_party/blink/renderer/core/dom/decoded_data_document_parser.cc:71
#3 0x00000002d2382778 in blink::HTMLDocumentParser::AppendBytes(char const*, unsigned long) at /Users/airing/Files/code/chromium/src/third_party/blink/renderer/core/html/parser/html_document_parser.cc:1351
Tokenizing
职责:将 characters 解析为 token。
核心函数:
需要注意的是,这一步中如果解析到 link、script、img 标签时会继续发起网络请求;同时解析到 script 时,需要先执行完解析到的 JavaScript,才会继续往后解析 HTML。因为 JavaScript 可能会改变 DOM 树的结构(如 document.write() 等),所以需要先等待它执行完。
Lexing
职责:将 token 解析为 Element。
核心函数:
注意这一步在处理的过程中,就会使用栈结构存储 Node (HTML Tag),以便后续构造 DOM Tree —— 例如对于 HTMLToken::StartTag 类型的 Token,就会调用 ProcessStartTag 执行一个压栈操作,而对于HTMLToken::EndTag 类型的 Token,就会调用 ProcessEndTag 执行一个出栈操作。
如针对如下所示的 DOM Tree:
<div>
<p>
<div></div>
</p>
<span></span>
</div>
各 Node 压榨与出栈流程如下:
DOM construction
职责:将 Element 实例化为 DOM Tree。
最终 DOM Tree 的数据结构可以断点从 blink::TreeScope 中预览:
我们可以使用 DevTools 查看页面的 Parsing 流程:
但是这个火焰图看不到 C++ 侧的栈调用情况。如果想深入查看内核侧的堆栈情况, 可以使用 Perfetto 进行页面录制与分析,它不仅能看到 C++ 侧的堆栈情况,还能分析每个调用所属的线程,以及跨进程通信时也会连线标出发出通信与接收到通信的函数调用。
分析完 Paring 之后,我们可以完善一下我们的流程图:
Style
- 模块:blink
- 进程:Render Process
- 线程:Main thread
- 职责:Style Engine 遍历 DOM,通过匹配 CSSOM 进行样式分析 (resolution) 和样式重算 (recalc) 构建出 Render Tree
- 输入:DOM Tree
- 输出:Render Tree
RenderTree 由 RenderObject 构成,每个 RenderObject 对应一个 DOM 节点上,它会在 DOM 附加 ComputedStyle (计算样式)信息。
ComputedStyle 可以通过 DevTools 直接查看,CSS 调试时经常使用。
核心函数:Document::UpdateStyleAndLayout (可以先不看 Layout 的部分)
该函数的的逻辑如下图所示,这个生成 ComputedStyle 的环节我们称之为 style recalc(样式计算):
完整的 Style 的流程如下图所示:
我们可以拆成 3 个环节:
- CSS 加载
- CSS 解析
- CSS 计算
CSS 加载
核心堆栈的打印:
[DocumentLoader.cpp(558)] “<!DOCType html>\n<html>\n<head>\n<link rel=\”stylesheet\” href=\”demo.css\”> \n</head>\n<body>\n<div class=\”text\”>\n <p>hello, world</p>\n</div>\n</body>\n</html>\n”
[HTMLDocumentParser.cpp(765)] “tagName: html |type: DOCTYPE|attr: |text: “
[HTMLDocumentParser.cpp(765)] “tagName: |type: Character |attr: |text: \n”
[HTMLDocumentParser.cpp(765)] “tagName: html |type: startTag |attr: |text: “
…
[HTMLDocumentParser.cpp(765)] “tagName: html |type: EndTag |attr: |text: “
[HTMLDocumentParser.cpp(765)] “tagName: |type: EndOfFile|attr: |text: “
[Document.cpp(1231)] readystatechange to Interactive
[CSSParserImpl.cpp(217)] recieved and parsing stylesheet: “.text{\n font-size: 20px;\n}\n.text p{\n color: #505050;\n}\n”
需要注意的是 DOM 构建之后不会立刻渲染 HTML 页面,而是要等待 CSS 处理完毕。因为 CSS 加载完之后才会进行后续的 style recalc 等流程,如果没有 CSS 只渲染无样式的 DOM 是无意义的。
The browser blocks rendering until it has both the DOM and the CSSOM. ——Render blocking CSS
CSS 解析
CSS 解析涉及的数据流为:bytes → characters → tokens → StyleRule → RuleMap,bytes 的处理前文已经说过,不再赘述,我们重点看后续的流程。
首先是:characters → tokens。
css 涉及到的 token 有下图这些:
需要注意的是 FunctionToken 会有额外的计算。例如,Blink 底层使用 RGBA32 来存储 Color (CSSColor::Create)。根据我微基准测试的结果,Hex 转换为 RGBA32 比 rgb() 的效率快 15% 左右。
第二步是:tokens → StyleRule。
StyleRules = selectors(选择器) + properties(属性集)。
值得注意的的是 CSS 选择器解析是从右向左的
例如对于这个 CSS:
.text .hello{
color: rgb(200, 200, 200);
width: calc(100% - 20px);
}
#world{
margin: 20px;
}
解析结果如下所示:
selector text = “.text .hello”
value = “hello” matchType = “Class” relation = “Descendant”
tag history selector text = “.text”
value = “text” matchType = “Class” relation = “SubSelector”
selector text = “#world”
value = “world” matchType = “Id” relation = “SubSelector”
这里额外说一下 Blink 的默认样式,Blink 有一套应用默认样式的规则:加载顺序为 html.css (默认样式)→ quirk.css (怪异样式)→ android/linux/mac.css(各操作系统样式) → other.css(业务样式)。
更多内置 CSS 加载顺序可参考 blink_resources.grd 配置。
最后是:StyleRule → RuleMap。
所有的 StyleRule 会根据选择器类型存储在不同的 Map 中,这样做的目的是为了在比较的时候能够很快地取出匹配第一个选择器的所有 rule,然后每条 rule 再检查它的下一个 selector 是否匹配当前元素。
- RuleMap id_rules_: id 选择器的 RuleMap
- RuleMap class_rules_: 类选择器的 RuleMap
- RuleMap attr_rules_: 属性选择器的 RuleMap
- RuleMap tag_rules_: tag 选择器的 RuleMap
- RuleMap ua_shadow_pseudo_element_rules_: 伪类选择器的 RuleMap
CSS 计算
- 产物:ComputedStyle
为什么要计算 CSS Style?因为可能会有多个选择器的样式命中了 DOM 节点,还需要继承父元素的属性以及 UA 提供的属性。
步骤:
- 找到命中的选择器
- 设置样式
指的注意的是最后应用样式的优先级顺序:
- Cascade layers 顺序
- 选择器优先级顺序
- proximity 排序
- 声明位置顺序
我们都知道应用样式的优先级顺序是选择器优先级相加,但这只是里面的第二级优先级。如果前三个优先级完全相同的情况下,最后应用的样式会取决于样式的声明时机 —— 声明靠后的优先级越大。
如图:
这里的 h1 的 class,无论写成 main-heading 2 main-heading 还是调转顺序,标题都是蓝色的,因为 .main-heading2 的声明靠后,因此优先级更高。
Layout
- 模块:blink
- 进程:Render Process
- 线程:Main thread
- 职责:处理 Element 的几何属性,即位置与尺寸
- 输入:Render Tree
- 输出:Layout Tree
Layout Object 记录了 Render Object 的几何属性。
一个 LayoutObject 附加了一个 LayoutRect 属性,包括:
- x
- y
- width
- height
但需要注意的是,LayoutObject 与 DOM Node 并非 1:1 的关系,理由如下图所示:
Layout 流程的核心函数:Document::UpdateStyleAndLayout ,经过这一步之后 DOM tree 会变成 Layout Tree,如下图代码:
<div style="max-width: 100px">
<div style="float: left; padding: 1ex">F</div>
<br>The <b>quick brown</b> fox
<div style="margin: -60px 0 0 80px">jumps</div>
</div>
每一个 LayoutObject 节点都记录了位置和尺寸信息:
我们知道避免 Layout (reflow),可以提高页面的性能。那么如何减少重排呢?主旨是合并多个 reflow,最后再反馈到 render tree 中。具体有以下措施:
- 直接更改 classname 而非 style → 避免 CSSOM 重新生成与合成
- 让频繁 reflow 的 Element “离线”
- 替代会触发 reflow 的属性
- 将 reflow 的影响范围控制在单独的图层内
其中,会首次/二次触发 Layout(reflow),Paint(repaint),Compositor 的属性可以参考 CSS Triggers:
可以发现每个浏览器内核对于属性的处理是不一样的,如果需要优化性能,就可以对照查看这张表格,看看有没有 css 属性是可以优化的。
Pre-paint
- 模块:blink
- 进程:Render Process
- 线程:Main thread
- 职责:生成 Property trees,供 Compositor thrread 使用,避免某些资源重复 Raster
- 输入:Layout Tree
- 输出:Property Tree
基于属性树,Chromium 可以单独操作某个节点的变换、裁剪、特效、滚动,不至于影响它的子节点。
核心函数:
新版本 Chromium 改成了 CAP(composite after paint)模式
Property trees 包括以下四棵树:
Paint
- 模块:blink
- 进程:Render Process
- 线程:Main thread
- 职责:Blink 对接 cc 的绘制接口进行 Paint,生成 cc 模块的数据源 cc::Layer
- 输入:Layout Object
- 输出:PaintLayer (cc::Layer)
注意:cc = content collator (内容编排器),而不是 Chromium Compositor。
核心函数:
Paint 阶段将 Layout Tree 中的 Layout Object 转换成绘制指令,并把这些操作封装在 cc::DisplayItemList 中,之后将其注入进 cc::PictureLayer 中。
生成 display item list 的流程也是一个栈结构的遍历:
再举一个例子,针对以下 HTML:
<style> #p {
position: absolute; padding: 2px;
width: 50px; height: 20px;
left: 25px; top: 25px;
border: 4px solid purple;
background-color: lightgrey;
} </style>
<div id=p> pixels </div>
对应生成的 display items 如下图所示:
最后再介绍一下 cc::Layer,它运行在主线程,且一个 Render Process 内有且只有一棵 cc::Layer 树。
一个 cc::Layer 表示一个矩形区域内的 UI,以下子类代表不同类型的 UI 数据:
- cc::PictureLayer:用于实现自绘型的 UI 组件,它允许外部通过实现 cc::ContentLayerClient 接口提供一个 cc::DisplayItemList 对象,它表示一个绘制操作的列表,记录了一系列的绘制操作。它经过 cc 的流水线之后转换为一个或多个 viz::TileDrawQuad 存储在 viz::CompositorFrame 中。
- cc::TextureLayer:对应 viz 中的 viz::TextureDrawQuad,所有想要使用自己的逻辑进行 Raster 的 UI 组件都可以使用这种 Layer,比如 Flash 插件,WebGL等。
- cc::UIResourceLayer/cc::NinePatchLayer:类似 TextureLayer,用于软件渲染。
- cc::SurfaceLayer/cc::VideoLayer(废弃):对应 viz 中的 viz::SurfaceDrawQuad,用于嵌入其他的 CompositorFrame。Blink 中的 iframe 和视频播放器可以使用这种 Layer 实现。
- cc::SolidColorLayer:用于显示纯色的 UI 组件。
Commit
- 模块:cc
- 进程:Render Process
- 线程:Compositor thread
- 职责:将 Paint 阶段的产物数据 (cc::Layer) 提交给 Compositor 线程
- 输入:cc::Layer (main thread)
- 输出:LayerImpl (compositor thread)
核心函数:PushPropertiesTo
核心逻辑是将 LayerTreeHost 的数据 commit 到 LayerTreeHostImpl,我们在接收到 Commit 消息的地方进行断点,堆栈如下所示:
libcc.so!cc::PictureLayer::PushPropertiesTo(cc::PictureLayer * this, cc::PictureLayerImpl * base_layer)
libcc.so!cc::PushLayerPropertiesInternal<std::__Cr::__wrap_iter<cc::Layer**> >(std::__Cr::__wrap_iter<cc::Layer**> source_layers_begin, std::__Cr::__wrap_iter<cc::Layer**> source_layers_end, cc::LayerTreeHost * host_tree, cc::LayerTreeImpl * target_impl_tree)
libcc.so!cc::TreeSynchronizer::PushLayerProperties(cc::LayerTreeHost * host_tree, cc::LayerTreeImpl * impl_tree)
libcc.so!cc::LayerTreeHost::FinishCommitOnImplThread(cc::LayerTreeHost * this, cc::LayerTreeHostImpl * host_impl)
libcc.so!cc::SingleThreadProxy::DoCommit(cc::SingleThreadProxy * this)libcc.so!cc::SingleThreadProxy::ScheduledActionCommit(cc::SingleThreadProxy * this)libcc.so!cc::Scheduler::ProcessScheduledActions(cc::Scheduler * this)
libcc.so!cc::Scheduler::NotifyReadyToCommit(cc::Scheduler * this, std::__Cr::unique_ptr<cc::BeginMainFrameMetrics, std::__Cr::default_delete<cc::BeginMainFrameMetrics> > details)
libcc.so!cc::SingleThreadProxy::DoPainting
libcc.so!cc::SingleThreadProxy::BeginMainFrame(cc::SingleThreadProxy * this, const viz::BeginFrameArgs & begin_frame_args)
Compositing
- 模块:cc
- 进程:Render Process
- 线程:Compositor thread
- 职责:将整个页面按照一定规则,分成多个独立的图层,便于隔离更新
- 输入:PaintLayer(cc::Layer)
- 输出:GraphicsLayer
核心函数:
为什么需要 Compositor 线程?那我们假设下如果没有这个步骤,Paint 之后直接光栅化上屏又会怎样:
如果直接走光栅化上屏,如果 Raster 所需要的数据源因为各种原因,在垂直同步信号来临时没有准备就绪,那么就会导致丢帧,发生 “Janky”。
当然,为了避免 Janky,Chromium 也在每个阶段也做了很常规的优化——缓存。如下图所示,在 Style、Layout、Paint、Raster 阶段都做了对应了缓存策略,以避免不必要的渲染,从而减少 Janky 发生的可能性:
但即便做了如此多的缓存优化,一个简单的滚动会导致所有的像素重新 Paint + Raster!
而 Compositing 阶段经过分层之后的产物 GraphicsLayer,可以让 Chromium 在渲染时只需要操作必要的图层,其他图层只需要参与合成就行了,以此提高渲染效率:
如下图所示:
wobble 类有个 transform 动画,那么这整个 div 节点就是一个独立的 GraphicsLayer,动画只需要渲染这部分 layer 即可。
我们也可以通过 DevTools 的图层工具查看所有的 Layers,它会告诉我们这个图层产生的原因是什么、内存占用多少,至今为止绘制了多少次,以便我们进行内存与渲染效率的优化。
这也解答了为什么 CSS 动画性能表现优秀?因为有 Compositor 线程的参与,它基于 Property Trees 合成的图层,单独在 Compositor 线程处理 CSS 动画。此外,我们也可以使用 will-change 去提前告知 Compositor 线程,以优化图层合并。但这个方案也不是万能的,每个 Layer 都会消耗一定的内存。
Compositor Thread 还具备处理输入事件的能力,如下图所示,它会监听从 Browser Process 过来的各种事件:
但需要注意的是如果在 JavaScript 注册了事件监听,它会把输入事件转发给 main thread 进行处理。
Tiling
- 模块:cc
- 进程:Render Process
- 线程:Compositor thread
- 职责:将一个 cc::PictureLayerImpl 根据不同的 scale 级别,不同的大小拆分为多个 cc::TileTask 任务给到 Raster 线程处理。
- 输入:LayerImpl (compositor thread)
- 输出:cc::TileTask (raster thread)
图块(Tiling)是 Raster 的基本工作单位,这个阶段中 Layer (LayerImpl) 会拆成一个个 Tiling。在 Commit 完成之后会根据需要创建 Tiles 任务 cc::RasterTaskImpl,这些任务被 Post 到 Raster 线程中执行。
核心函数:PrepareTiles
这个环节主要是提交 cc::TileTask 任务给到 raster thread 做分块渲染 (Tile Rendering),所谓分块渲染就是把网页的缓存分为一格一格的小块,通常为 256x256 或者 512x512,然后分块进行渲染。
分块渲染的必要性提现在以下两个方面:
- GPU 合成通常是使用 OpenGL ES 贴图实现的,这时候的缓存实际就是纹理(GL Texture),很多 GPU 对纹理的大小是有限制的。GPU 无法支持任意大小的缓存。
- 分块缓存,方便浏览器使用统一的缓冲池来管理缓存。缓冲池的小块缓存由所有 WebView 共用,打开网页的时候向缓冲池申请小块缓存,关闭网页是这些缓存被回收。
如果说前一个环境的分层是宏观上提升了渲染效率,那么分块就是微观上提升了渲染效率。
Chromium 对分块渲染的策略还有以下优化点:
- 优先绘制靠近视口的图块:Raster 会根据 Tiling 与可见视口的距离安排优先顺序进行 Raster,离得近的会被优先 Raster,离得远的会降级 Raster 的优先级。
- 在首次合成图块的时候,降低分辨率,以减少纹理合成和上传的耗时。
在提交 TileTask 的位置我们断点,可以看到该环节的完整堆栈:
libcc.so!cc::SingleThreadTaskGraphRunner::ScheduleTasks(cc::TestTaskGraphRunner * this, cc::NamespaceToken token, cc::TaskGraph * graph)
libcc.so!cc::TileTaskManagerImpl::ScheduleTasks(cc::TileTaskManagerImpl * this, cc::TaskGraph * graph)
libcc.so!cc::TileManager::ScheduleTasks(cc::TileManager * this, cc::TileManager::PrioritizedWorkToSchedule work_to_schedule)
libcc.so!cc::TileManager::PrepareTiles(cc::TileManager * this, const cc::GlobalStateThatImpactsTilePriority & state)
libcc.so!cc::LayerTreeHostImpl::PrepareTiles(cc::LayerTreeHostImpl * this)
libcc.so!cc::LayerTreeHostImpl::NotifyPendingTreeFullyPainted(cc::LayerTreeHostImpl * this)libcc.so!cc::LayerTreeHostImpl::UpdateSyncTreeAfterCommitOrImplSideInvalidation(cc::LayerTreeHostImpl * this)
libcc.so!cc::LayerTreeHostImpl::CommitComplete(cc::LayerTreeHostImpl * this)
libcc.so!cc::SingleThreadProxy::DoCommit(cc::SingleThreadProxy * this)libcc.so!cc::SingleThreadProxy::ScheduledActionCommit(cc::SingleThreadProxy * this)
libcc.so!cc::Scheduler::ProcessScheduledActions(cc::Scheduler * this)
libcc.so!cc::Scheduler::NotifyReadyToCommit(cc::Scheduler * this, std::__Cr::unique_ptr<cc::BeginMainFrameMetrics, std::__Cr::default_delete<cc::BeginMainFrameMetrics> > details)
libcc.so!cc::SingleThreadProxy::DoPainting(cc::SingleThreadProxy * this)
libcc.so!cc::SingleThreadProxy::BeginMainFrame(cc::SingleThreadProxy *this, const viz::BeginFrameArgs & begin_frame_args)
Raster
- 模块:cc
- 进程:Render Process
- 线程:Raster thread
- 职责:Raster 阶段会执行每一个 TileTask,最终产生一个资源,记录在产生一个资源,该资源被记录在了 LayerImpl (cc::PictureLayerImpl) 。它会将 DisplayItemList 中的绘制操作 Playback 到 viz 的 CompositorFrame 中。
- 输入:cc::TileTask
- 输出:LayerImpl (cc::PictureLayerImpl)
推荐阅读:cc/raster/
这些颜色值位图存储与 OpenGL 引用会在 GPU 的内存中(GPU 也可以进行栅格化,即硬件加速。)
除此之外,Raster 还包括的图片解码的能力:
Raster 的核心类 cc::RasterBufferProvider 有以下几个关键子类:
- cc::GpuRasterBufferProvider:使用 GPU 进行 Raster,Raster 的结果直接存储在 SharedImage 中。
- cc::OneCopyRasterBufferProvider:使用 Skia 进行 Raster,结果先保存到 GpuMemoryBuffer 中,然后再将 GpuMemoryBuffer 中的数据通过 CopySubTexture 拷贝到资源的 SharedImage 中。
- cc::ZeroCopyRasterBufferProvider:使用 Skia 进行 Raster,结果保存到 GpuMemoryBuffer 中,然后使用 GpuMemoryBuffer 直接创建 SharedImage。
- cc::BitmapRasterBufferProvider:使用 Skia 进行 Raster,结果保存到共享内存中。
GPU Shared Image
所谓 SharedImage 机制本质上抽象了 GPU 的数据存储能力,即允许应用直接把数据存储到 GPU 内存中,以及直接从 GPU 中读取数据,并且允许跨过 shared group 边界。在早期的 Chromium 中使用的的是 Mailbox 机制,如今的模块基本都重构为 GPU Shared Image 了。
GPU Shared Image 包括 Client 端和 Service 端,其中 Client 端可以为 Browser / Render / GPU 进程等,Client 端可以有多个;而 Service 端则只能用一个,运行在 GPU 进程。架构图如下所示:
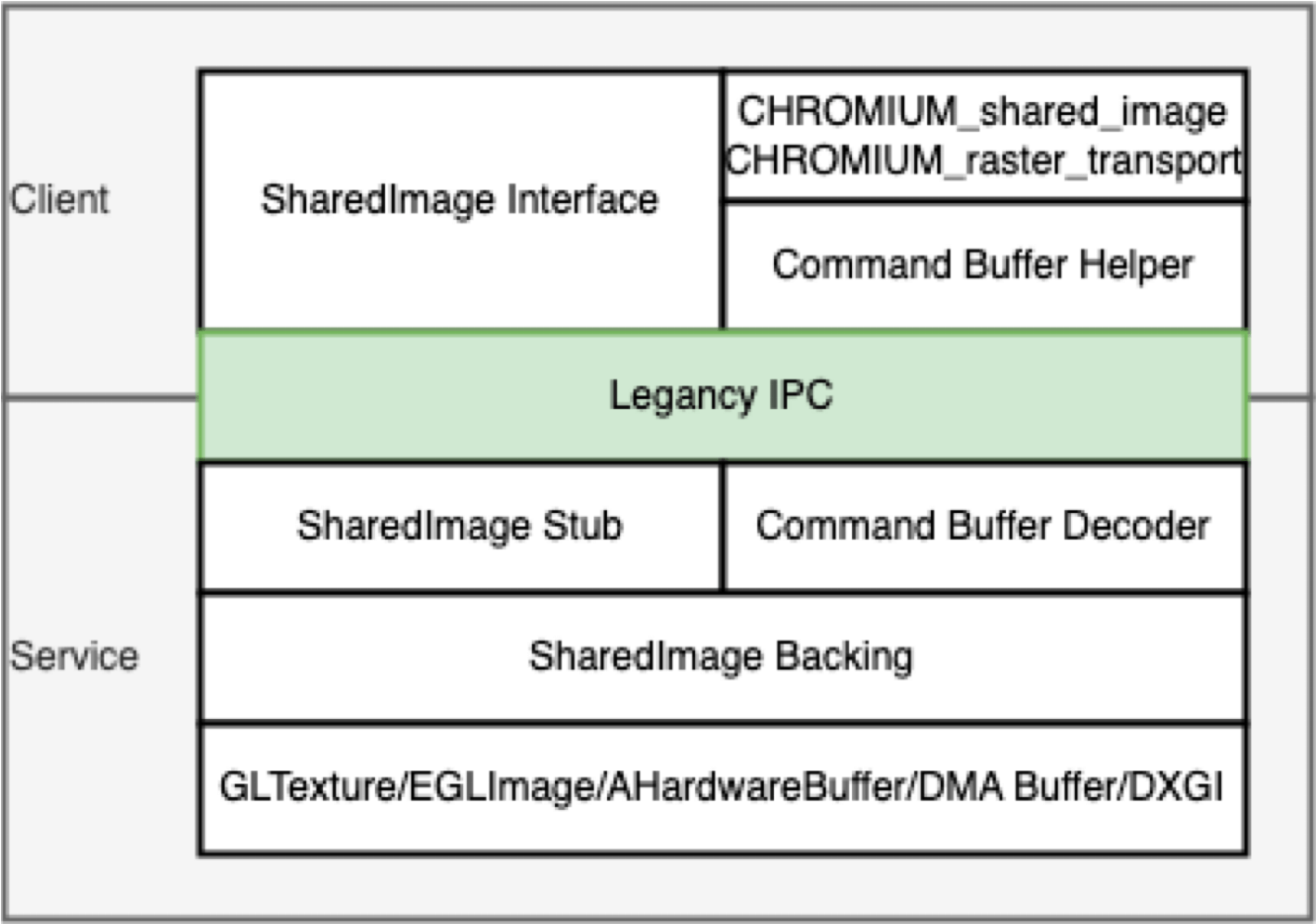
Chromium 中使用 SharedImage 机制的一些场景:
- CC 模块:先将画面 Raster 到 SharedImage,然后再发送给 Viz 进行合成。
- OffscreenCanvas:先将 Canvas 的内容 Raster 到 SharedImage,然后再发送给 Viz 进行合成。
- 图片处理/渲染:一个线程将图片解码到 GPU 中,另一个线程使用 GPU 来修改或者渲染图片。
- 视频播放:一个线程将视频解码到 GPU 中,另一个线程来渲染。
光栅化策略
根据 Compositor 和 Raster 这两个阶段是同步进行(注意同步不一定要求在同一个线程)还是异步进行,分为同步光栅化和异步光栅化,而异步光栅化都是分块进行的,因此也叫异步分块光栅化。
同步光栅化,如 Android、iOS、Flutter 都使用的同步光栅化机制,同时它们也支持图层分屏额外的像素缓冲区来进行间接光栅化。
同步光栅化的渲染管线很简单,如下图所示:
异步光栅化则是目前浏览器与 WebView 采用的策略,除却一些特殊的图层外(如 Canvas、Video),图层会进行分块光栅化,每个光栅化任务执行对应图层的对应分块区域内的绘图指令,结果写入该分块的像素缓冲区;此外光栅化和合成不在同一个线程执行,并且不是同步的,如果合成过程中某个分块没有完成光栅化,那它就会保留空白或者绘制一个棋盘格的图形。
两种光栅化策略各有优劣,大致如下表所示:
| 同步光栅化 | 异步光栅化 | |
|---|---|---|
| 内存占用 | 极好 | 极差 |
| 首屏性能 | 好 | 一般 |
| 动态变化的内容渲染效率 | 高 | 低 |
| 图层动画 | 一般 | 惯性动画绝对优势 |
| 光栅化性能 | 低端机略弱 | 好 |
内存占用上,同步光栅化具有绝对的优势,而异步光栅化则很吃内存,基本上可以说浏览器内核的性能大部分是靠内存换出来的。
首屏性能上,同步光栅化的流水线由于更精炼,没有复杂的调度任务,会更早实现上屏。但这个提升实际上也很有限,在首屏性能上,同步光栅化通常比起异步光栅化理论上可以提前一两帧完成,可能就 20 毫秒。(当然,这里异步光栅化的资源也是本地加载的。)
对于动态变化的内容,如果页面的内容在不断发生变化,这意味这异步光栅化的中间缓存大部分是失效的,需要重新光栅化。而由于同步光栅化流水更精炼,这部分重渲染效率也更高一些。
对于图层动画,是异步光栅化绝对的优势了,前文也说了属性树与 Compositing,它可以控制重新渲染的图层范围,效率是很高的。虽然异步光栅化需要额外的分块耗时,但是这个开销不高,也就 2 ms 左右。如果页面动画特别复杂,那么异步光栅化的优势就能体现出来。对于惯性滚动,异步光栅化会提前对 Viewport 外的区域进行预光栅化以优化体验。但是同步光栅化也各显神通,如在编码时,iOS、Android、Flutter 都会非常强调 Cell 层面的重用机制,以此来优化滚动效果。
最后是光栅化的性能上,同步光栅化对性能要求更高,因为需要大量的 CPU 计算,在低端机上容易出现持续掉帧。但是随着手机 CPU 性能越好,同步光栅化策略的优势就越明显,因为对比异步光栅化有着绝对的内存优势,且对于惯性动画也可以通过重用机制来解决,总体优势还是比较明显的。
除此之外,异步光栅化也有一些无法规避的问题如快速滚动时页面白屏、滚动过程中 DOM 更新不同步等问题。
Activate
- 模块:cc
- 进程:Render Process
- 线程:Compositor thread
- 职责:实现一个缓冲机制,确保 Draw 阶段操作前 Raster 的数据已准备好。具体而言将 Layer Tree 分成 Pending Tree 与 Active Tree,从 Pending Tree 拷贝 Layer 到 Activate Tree 的过程就是 Activate。
核心函数:LayerTreeHostImpl::ActivateSyncTree
Compositor thread 有三棵 cc::LayerImpl 树:
- Pending tree: 负责接收 commit,然后将 LayerImpl 进行 Raster
- Active tree: 会从这里取出栅格化好的 LayerImpl 进行 Draw 操作
- Recycle tree:为避免频繁创建 LayerImpl 对象,Pending tree 后续不会被销毁,而是退化成 Recycle tree。
// Tree currently being drawn.
std::unique_ptr<LayerTreeImpl> active_tree_;
// In impl-side painting mode, tree with possibly incomplete rasterized
// content. May be promoted to active by ActivateSyncTree().
std::unique_ptr<LayerTreeImpl> pending_tree_;
// In impl-side painting mode, inert tree with layers that can be recycled
// by the next sync from the main thread.
std::unique_ptr<LayerTreeImpl> recycle_tree_;
Commit 阶段提交的目标其实就是 Pending 树,Raster 的结果也被存储在了 Pending 树中。通过 Active 可以实现一边从最新的提交中光栅化图块,一边上屏绘制之前的提交。
Draw
该阶段也可以叫做 Submit,本文中统一术语就叫 Draw。
- 模块:cc
- 进程:Render Process
- 线程:Compositor thread
- 职责:将 Raster 后图块 (Tiling) 生成为 draw quads 的过程。
- 输入:cc::LayerImpl (Tiling)
- 输出:viz::DrawQuad
Draw 阶段并不执行真正的绘制,而是遍历 Active Tree 中的 cc::LayerImpl 对象,并调用它的 cc::LayerImpl::AppendQuads 方法创建合适的 viz::DrawQuad 放入 CompositorFrame 的 RenderPass 中。
核心函数:
Viz
这里先介绍一下 Chromium 上屏的重要模块 —— viz。
viz = visuals
在 Chromium 中 viz 的核心逻辑运行在 Viz Process 中,负责接收其他进程产生的 viz::CompositorFrame(简称 CF),然后把这些 CF 进行合成,并将合成的结果最终渲染在窗口上。
viz 模块的核心类如下图所示:
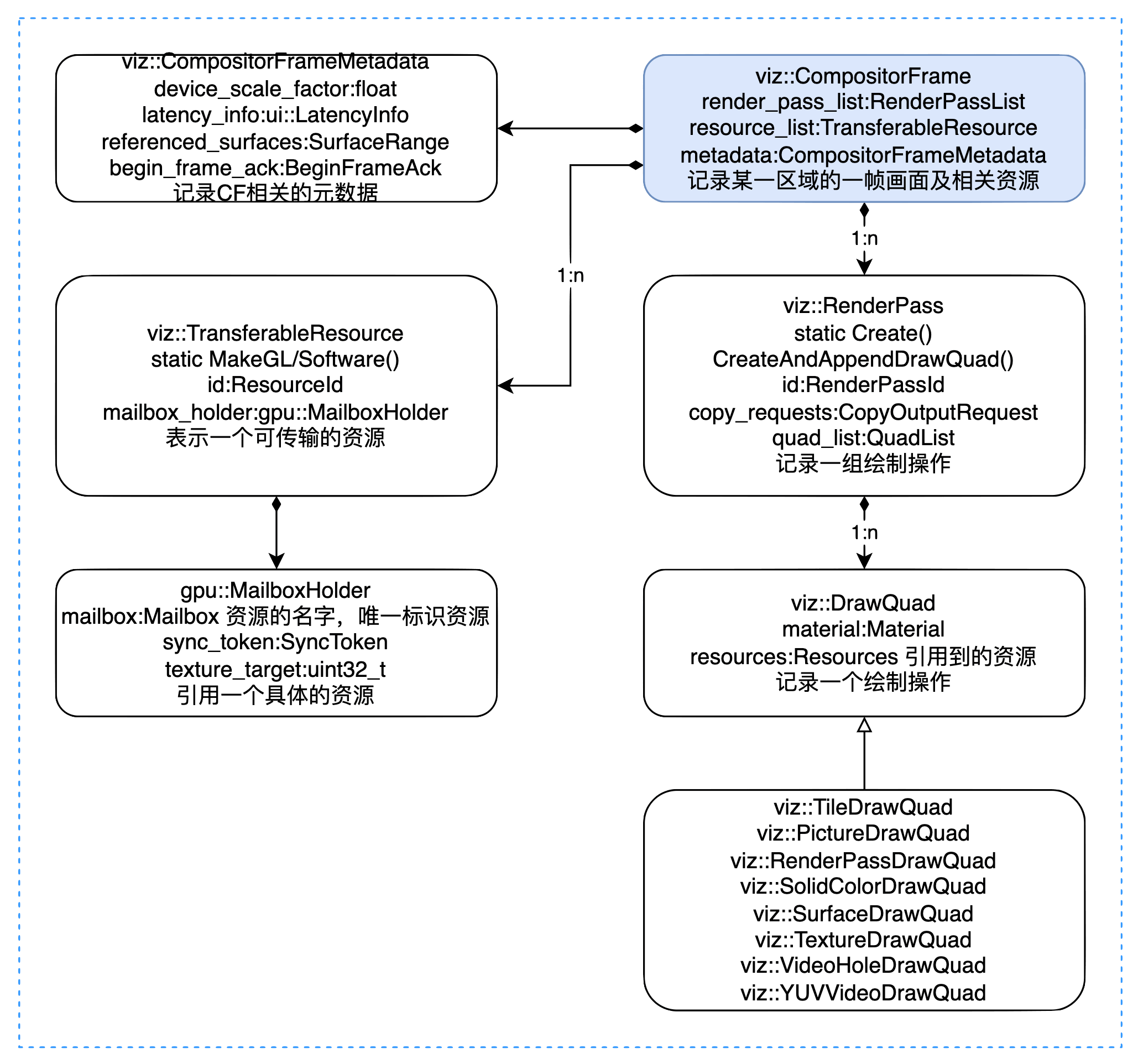
一个 CF 对象表示一个矩形显示区域中的一帧画面, viz::CompositorFrame 内部存储了以下几类数据:
- 元数据:CompositorFrameMetadata
- 引用到的资源:TransferableResource
- 绘制操作:RenderPass/DrawQuad
元数据 viz::CompositorFrameMetadata 记录了 CF 相关的元数据,比如画面的缩放级别,滚动区域,引用到的 Surface 等:
- device_scale_factor:float
- latency_info:ui::LatencyInfo
- referenced_surfaces:SurfaceRange
- begin_frame_ack:BeginFrameAck
引用到的资源 viz::TransferableResource 记录了该 CF 引用到的资源,所谓的资源可以理解为一张图片。资源有两种存在形式:
- 存储在内存中的 Software 资源
- 存储在 GPU 中的 Texture
如果没有开启硬件加速渲染,则只能使用 Software 资源;而如果开启了硬件加速,则只能使用硬件加速的资源。
CF 的绘制操作 viz::RenderPass 由一系列相关的 viz::DrawQuad 构成。可以对一个 RenderPass 单独应用特效,变换,mipmap,缓存,截图等。DrawQuad 有很多种类型:
- viz::TextureDrawQuad:内部引用一个资源。
- viz::TileDrawQuad:表示一个 Tile 块,和 TextureDrawQuad 类似,内部也引用一个资源,DisplayItemList 会被 cc Raster 为 TileDrawQuad;
- viz::PictureDrawQuad:内部直接存放 DisplayItemList,但是目前只能用于 Android WebView;
- viz::SolidColorDrawQuad:表示一个颜色块;
- viz::RenderPassDrawQuad:内部引用另外一个 RenderPass 的 Id;
- viz::SurfaceDrawQuad:内部保存一个 viz::SurfaceId,该 Surface 的内容由其他 CompositorFrameSinkClient 创建,用于 viz 的嵌套,比如 OOPIF, OffscreenCanvas 等;
介绍完了 Viz 模块的基础知识,接下来让我们的流水线进入到 Viz Process 中。
Aggregate
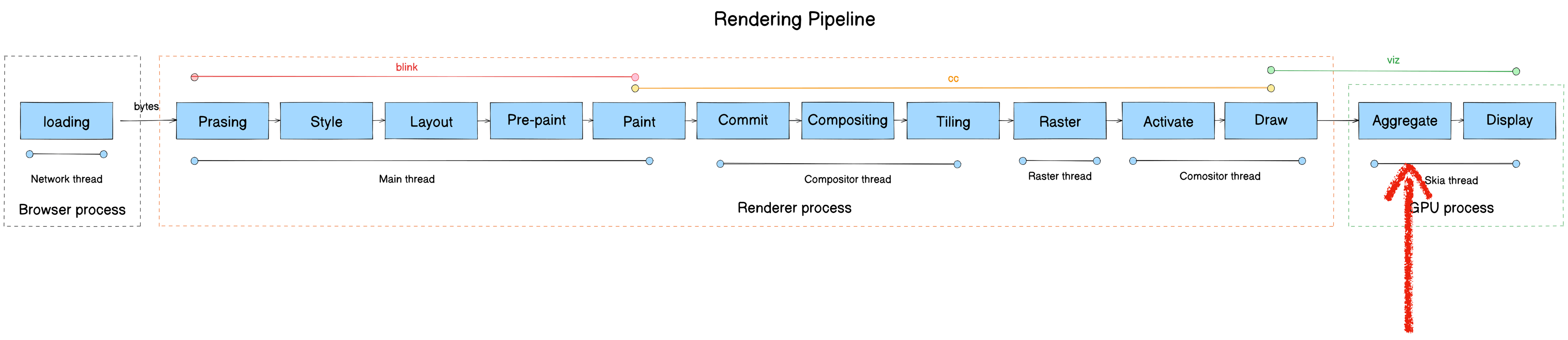
- 模块:Viz
- 进程:Viz Process
- 线程:Display Compositor thread
- 职责:Surface aggregation,接受多个进程传递过来的 CF 并进行合成。
核心类:SurfaceAggregator。
Display compositor(viz process compositor thread)会接受多个进程传递过来的 CF ,并调用SurfaceAggregator 中的函数进行合成。
Display
- 模块:Viz
- 进程:Viz Process
- 线程:GPU main thread
- 职责:生成了 CF 以后,viz 会调用 GL 指令把 draw quads 最终输出到屏幕上。
- 输入:合成之后的 viz::CompositorFrame (需要其中的 DrawQuad)
- 输出:绘制 pixels
先介绍一下 Viz 的渲染目标,viz::DirectRenderer 和 viz::OutputSurface 用于管理渲染目标,根据它们不同子类的组合,存在三种不同的渲染方案:
- 软件渲染: viz::SoftwareRenderer + viz::SoftwareOutputSurface + viz::SoftwareOutputDevice
- Skia 渲染: viz::SkiaRenderer + viz::SkiaOutputSurface(Impl) + viz::SkiaOutputDevice
- OpenGL 渲染: viz::GLRenderer + viz::GLOutputSurface
首先是软件渲染,SoftwareRenderer 用于纯软件渲染,当关闭硬件加速的时候使用该种渲染方式。
第二个是 Skia 渲染, SkiaOutputSurface 对渲染目标的控制是通过 SkiaOutputDevice 实现的,后者有很多子类,其中 SkiaOutputDeviceOffscreen 用于实现离屏渲染,SkiaOutputDeviceGL 用于 GL 渲染。
SkiaRenderer 将 DrawQuad 绘制到由 SkiaOutputSurfaceImpl 提供的 canvas 上,但是该 canvas 并不会进行真正的绘制动作,而是通过 skia 的 ddl(SkDeferredDisplayListRecorder) 机制把这些绘制操作记录下来,等到所有的 RenderPass 绘制完成,这些被记录下来的绘制操作会被通过 SkiaOutputSurfaceImpl::SubmitPaint 发送到 SkiaOutputSurfaceImplOnGpu 中进行真实的绘制。
Skia 渲染具有最大的灵活性,同时支持 GL 渲染,Vulkan 渲染,离屏渲染等。
核心函数与相关类梳理如下:
- viz::SkiaRenderer
- viz::SkiaOutputSurface
- viz::SkiaOutputDevice
- SkiaOutputSurfaceImplOnGpu
- SkSurface::draw
最后是 OpenGL 渲染,来自 viz compositor 线程的 GL 调用(帧数据)被 command buffer 代理,从 Compositor thread 写入到 main thread 的 back buffer 中。
注:GLRenderer 已经被标记为 deprecated, 未来会被 SkiaRenderer 取代。
它使用基于 CommandBuffer 的 GL Context 来渲染 DrawQuad 到 GLOutputSurface 上,GLOutputSurface 使用窗口句柄创建 Native GL Context。GL 调用发生在 Compositor thread 中,通过 InProcessCommandBuffer 这些 GL 调用最终在 CrGpuMain 线程中执行。
关于 CommandBuffer 相关内容可以参考 GPU Command Buffer。
最后进行 GL 指令调用,不同的操作系统/显卡驱动提供的类库不同,
需要注意的,图形绘制引擎一般会使用双缓冲(Double Buffering)技术,先将图片绘制到一个缓冲区,再一次性传递给屏幕进行显示,这样可以防止屏幕抖动,优化渲染性能。
同样的这里上屏也分为 Front Buffer(前台缓冲区)与 Back Buffer(后台缓冲区),屏幕负责从 Front Buffer 读帧数据输出展示。viz 调用 Display::DrawAndSwap 来交换 Front Buffer 与 Back Buffer 的指针,在垂直同步信号来临时,显卡驱动类库执行对应的绘制指令,最后用户就能在屏幕上看到 pixels 了。
以上便是 Chromium 的整个渲染流水线,本文是渲染流水线的 Overview,若对该话题感兴趣,可期待该系列的后续文章,或阅读本文列出的核心源码与扩展阅读,来进一步了解更多相关知识。
扩展阅读
- Chromium Rendering Pipeline - Introduce
- Chromium Rendering Pipeline - Parsing
- Chromium Rendering Pipeline - Style
- Mojo docs (go/mojo-docs) - Mojo
- Multi-process Architecture - The Chromium Projects
- Inside look at modern web browser (part 3)
- How cc Works
- Viz Services Directory Structure
- components/viz - chromium/src - Git at Google
- Shared images and synchronization
- Overview of the RenderingNG architecture - Chrome Developers
- RenderingNG - Chrome Developers
- Key data structures and their roles in RenderingNG - Chrome Developers
- Life of a pixel - Google Docs
- RenderingNG deep-dive: LayoutNG - Chrome Developers
- RenderingNG deep-dive: BlinkNG - Chrome Developers
- Get the Code: Checkout, Build, & Run Chromium - The Chromium Project
- Web Platform Tests
- Chromium Code Search
- CSS Triggers
- ECMAScript Language Specification
- WHATWG HTML Living Standard
