自编码器
自编码器,可以进行无监督的特征学习,可以将高维数据压缩并重构。
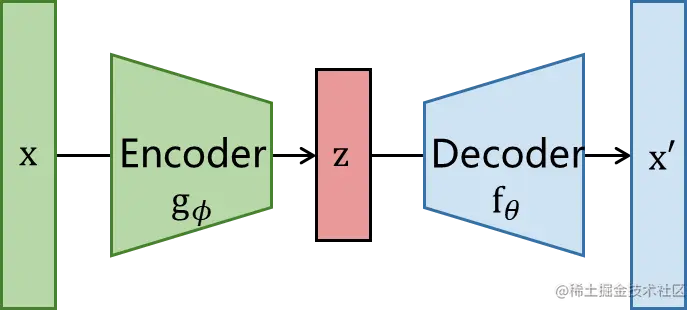
Autoencoder可以使用无标签数据训练,将数据压缩到潜变量空间上。但是仅有一个编码器和输入数据我们无法训练获得z,因此我们加一个解码器重构数据为x^,保证x和x^越接近越好,就可以证明z中保留了x的特征。这样Autoencoder就实现了编码器解码器的联合训练。
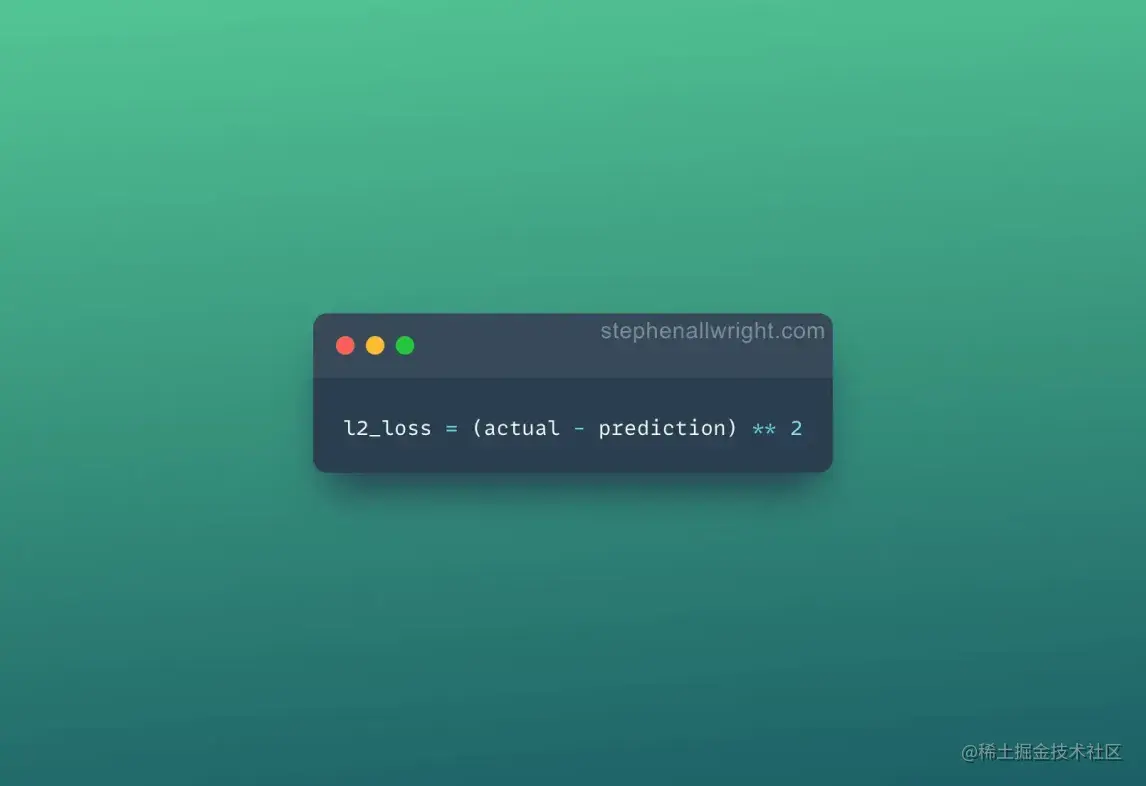
输入样本x通过编码器获得低维特征z,最后通过解码器重构输入数据获得x^,loss直接最小化∣∣x−x^∣∣2即可实现无监督训练。
 .
.
数学公式好好写一下AE的目标函数:
LAE(θ,ϕ)=n1i=1∑n∣∣xi−fθ(gϕ(xi))∣∣2
这里就是用了个MSE loss。
一个训练好的AE:
- 编码器:特征提取
将数据x输编码器,提取特征,得到bottleneck层的潜变量表示z
- 解码器:生成器
使用潜变量z,重建数据。
学习完成之后,解码器就可以做图片生成器。在低维空间上非编码处进行解码可以生成新的不同于输入的样本。
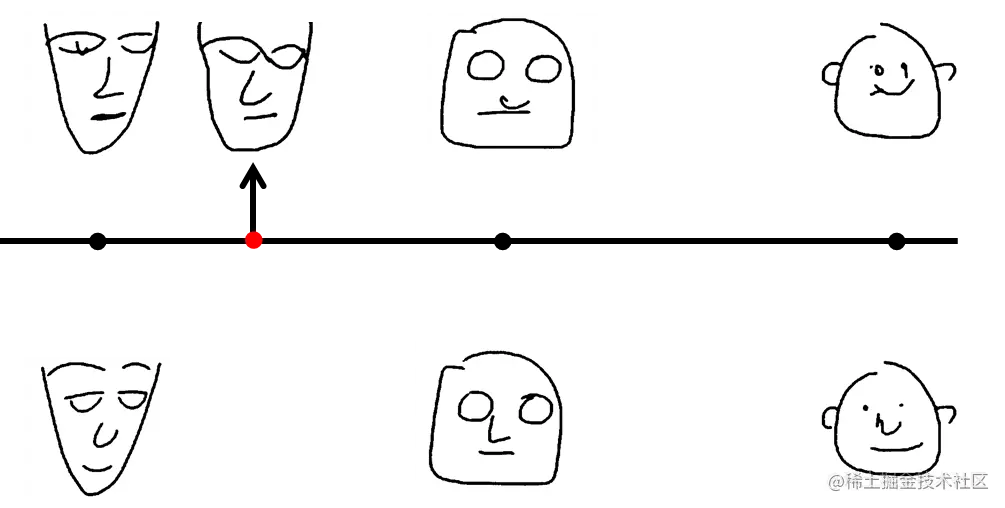
比如上图,中间这条线假设是我们学习到的码空间,下边的三个人脸是输入数据,上边的三个人脸是对应的重建输出。现在我们采样橙色那个点,你可能会想,它应该可以生成介于尖脸和方脸之间的一种脸型。但是实际上AE是做不到这一点的。
问题在于因为神经网络只是稀疏地记录下来你的输入样本和生成图像的一一对应关系,所以,如果介于某两个特征之间的某个点,编码器并没有学习到码空间里。因此无法实现码空间随机采样即可生成对应的图片,随机采样的点在解码时一定不会生成我们所希望特征的图像。
码空间的泛化能力基本为零,所以AE模型训练出来的解码器存在缺陷。
所以你采样红色的点的时候,解码器会说:啊?编码器没告诉过我啊。 所以是AE生成不出你期望的东西的。那怎么办呢?我们可以使用VAE。
VAE
为什么VAE可以做到?
原来的AE是将输入映射到固定向量,现在VAE的要求是将其映射到分布中,也就是给原来的固定点引入噪音,你要在这个噪声的范围的都能重建回这个图像。将原来的一个点变成了一个范围。
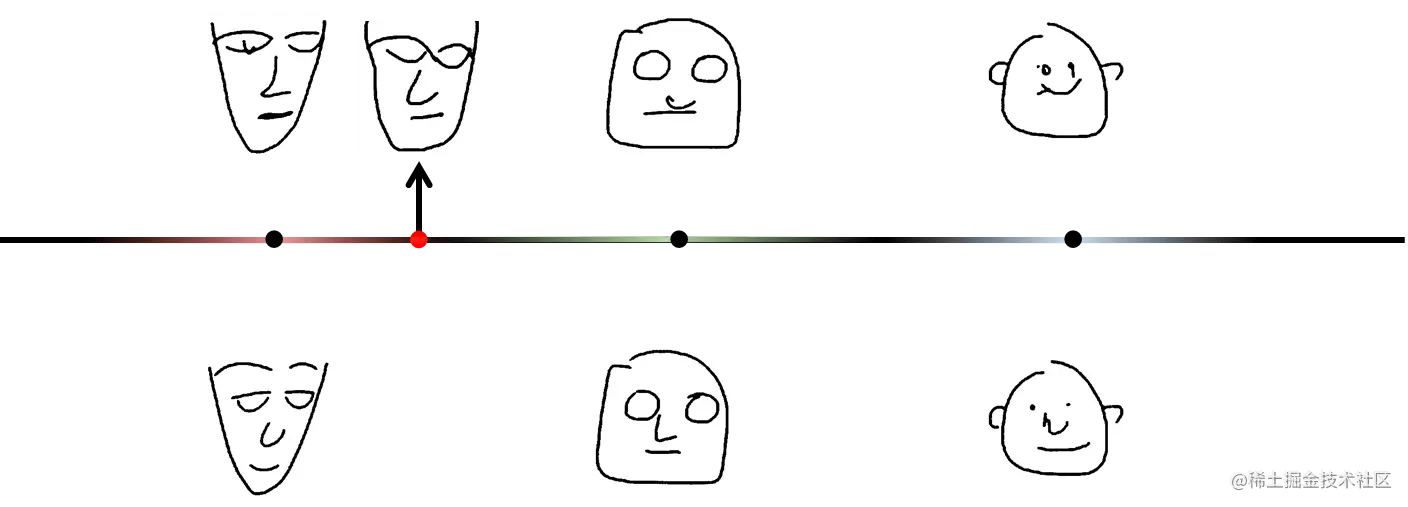
那当我们取某一个点的时候,它同时被不同的区间覆盖到,所以当它要生成一个东西的时候会产生介于二者之间的结果,使用VAE我们就可以获得在尖脸和方脸之间的结果了。
VAE的结构
我们看一下作者画的图:
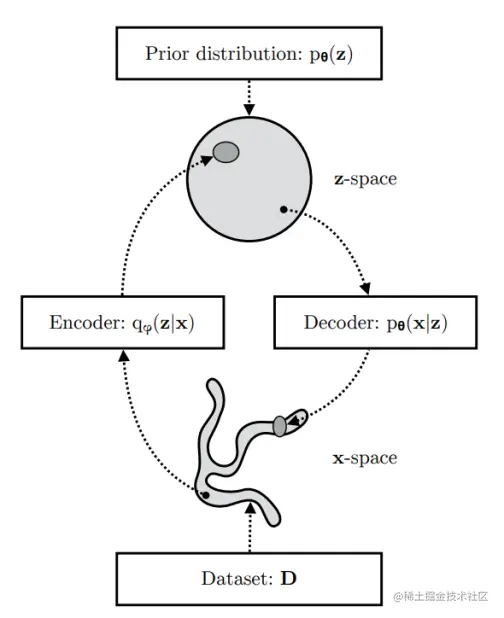 我们有一个数据集D,它的分布是未知的。也就是图中的xspace。通过VAE的编码器之后将其压缩到潜变量空间zspace上了。VAE的解码器要使用能从zspace上采样点,生成x′,要让x′尽力和x相似。如果成功的话,那x′的空间应该和和x差不多。
我们有一个数据集D,它的分布是未知的。也就是图中的xspace。通过VAE的编码器之后将其压缩到潜变量空间zspace上了。VAE的解码器要使用能从zspace上采样点,生成x′,要让x′尽力和x相似。如果成功的话,那x′的空间应该和和x差不多。
解码器
解码器的作用是从zspace上采样点,然后重建xspace:
- 首先,从先验分布 pθ(z) 中采样一个 zi。
- 然后从条件分布 pθ(x∣z=zi) 中生成一个值 xi。
最优参数 θ∗ 是最大化生成真实数据样本概率的参数,也就是计算pθ(x)的极大似然:
θ∗=argmaxθ∏i=1npθ(xi)
通常我们使用对数概率将右侧的乘积转换为求和:
θ∗=argmaxθ∑i=1nlogpθ(xi)
编码器
我们看一下pθ(xi)是怎么出来的:
pθ(xi)=∫pθ(xi∣z)p(z)dz
我们可以发现这样计算 pθ(xi) 并不容易,因为不可能检查所有的 z 值。
为了缩小值空间, 我们现在这样考虑:无法计算所有的z,那我们只计算给定对应的x的时候能出现什么样的z,然后再看z能否重建回x不就行了。
那如何获得后验pθ(z∣x),这就引入网络的编码器了。
我们引入一个新的近似函数 qϕ(z∣x),用于估计给定输入 x 时可能的编码,也就是用qϕ(z∣x)去近似真实后验pθ(z∣x)。
现在,结构看起来很像一个自编码器:
条件概率 pθ(x∣z) 定义了一个生成模型,类似于上面介绍的AE解码器 fθ(x∣z),pθ(x∣z) 也被称为概率解码器。
近似函数 qϕ(z∣x) 是概率编码器,扮演了AE中 gϕ(z∣x) 相似的角色。
到这里就回到了本节开头作者画的那张图了。
目标函数
估计的后验 qϕ(z∣x) 应该非常接近真实的后验 pθ(z∣x)。我们可以使用 KL散度来量化这两个分布之间的距离。
现在我们来将这个KL散度展开计算:
DKL(qϕ(z∣x)∥pθ(z∣x))=∫qϕ(z∣x)logpθ(z∣x)qϕ(z∣x)dz=∫qϕ(z∣x)logpθ(z,x)qϕ(z∣x)pθ(x)dz=∫qϕ(z∣x)(logpθ(x)+logpθ(z,x)qϕ(z∣x))dz=logpθ(x)+∫qϕ(z∣x)logpθ(z,x)qϕ(z∣x)dz=logpθ(x)+∫qϕ(z∣x)logpθ(x∣z)pθ(z)qϕ(z∣x)dz=logpθ(x)+Ez∼qϕ(z∣x)[logpθ(z)qϕ(z∣x)−logpθ(x∣z)]=logpθ(x)+DKL(qϕ(z∣x)∥pθ(z))−Ez∼qϕ(z∣x)logpθ(x∣z)因为p(z,x)=p(x∣z)p(z)因为∫q(z∣x)dz=1因为p(z,x)=p(x∣z)p(z)
现在得到:
DKL(qϕ(z∣x)∥pθ(z∣x))=logpθ(x)+DKL(qϕ(z∣x)∥pθ(z))−Ez∼qϕ(z∣x)logpθ(x∣z)
移项:
logpθ(x)−DKL(qϕ(z∣x)∥pθ(z∣x))=Ez∼qϕ(z∣x)logpθ(x∣z)−DKL(qϕ(z∣x)∥pθ(z))
-
先看方程右边:
Ez∼qϕ(z∣x)logpθ(x∣z)−DKL(qϕ(z∣x)∥pθ(z))
当我们尽力最大化这一项的时候,就是让第一项尽量大,让第二项尽量小,这就意味着:
-
再看方程的左边:
logpθ(x)−DKL(qϕ(z∣x)∥pθ(z∣x))
-
第一项是我们在学习真实分布时想要最大化生成真实数据的(对数)似然。
-
第二项是真实后验和近似后验分布之间的差异(这个KL散度项在这是起到正则化的作用)。
-
注意 pθ(x) 关于 qϕ 是固定的。
最大化这一项就是:
-
最大化生成真实数据的(对数)似然。
-
让真实后验和近似后验之间的差异尽量小。
上面的式子取反之后定义了我们的损失函数:
LVAE(θ,ϕ)=−logpθ(x)+DKL(qϕ(z∣x)∥pθ(z∣x))=−Ez∼qϕ(z∣x)logpθ(x∣z)+DKL(qϕ(z∣x)∥pθ(z))
θ∗,ϕ∗=argminθ,ϕLVAE
在变分贝叶斯方法中,这个损失函数被称为变分下界,或证据下界。
因为KL 散度总是非负的,因此−LVAE 是 logpθ(x) 的下界。
logpθ(x)≥−LVAE=logpθ(x)−DKL(qϕ(z∣x)∥pθ(z∣x))
因此,通过最小化损失,我们也就是在最大化生成真实数据样本概率的下界。
参数重整化
因为z∼qϕ(z∣x)这里采样z具有随机性,无法使用网络的梯度传播,因此作者使用参数重整化技巧转嫁随机性。之后网络结构如下:
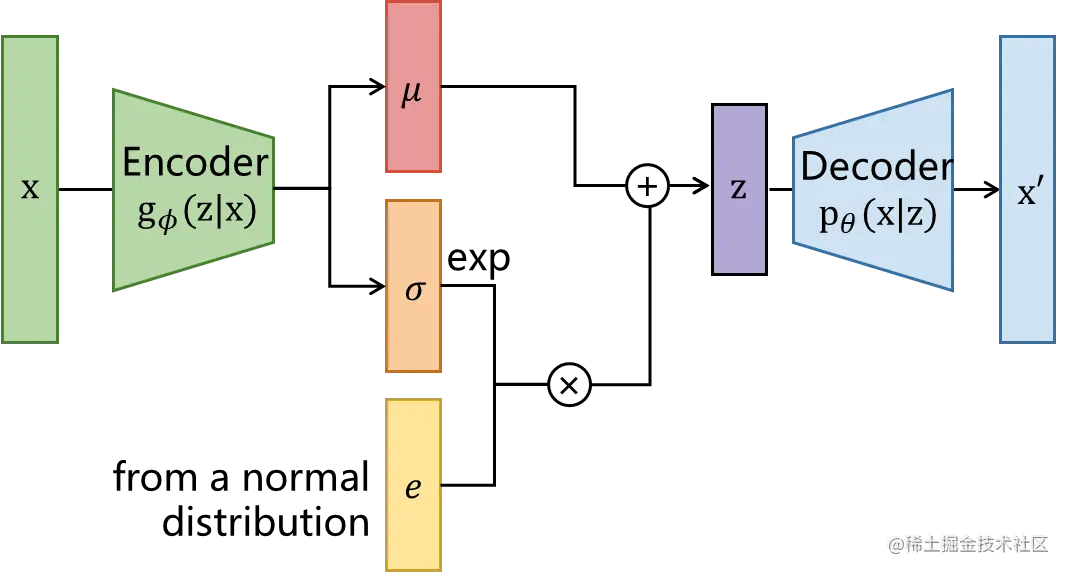
之后就可以快乐地生成人脸了!



