U-Net出自 U-Net: Convolutional Networks for Biomedical Image Segmentation
这个网络和别的自编码(autoe第二步是就是ncoder)模型一样,在中间有一个bottleneck,以确保网络只学习最重要的信息。和他之前的模型的一个区别是它引入了编码器和解码器之间的残差连接,大大改善了梯度流。
看下图,看这个形状你们应该就知道它为什么叫U-Net了。
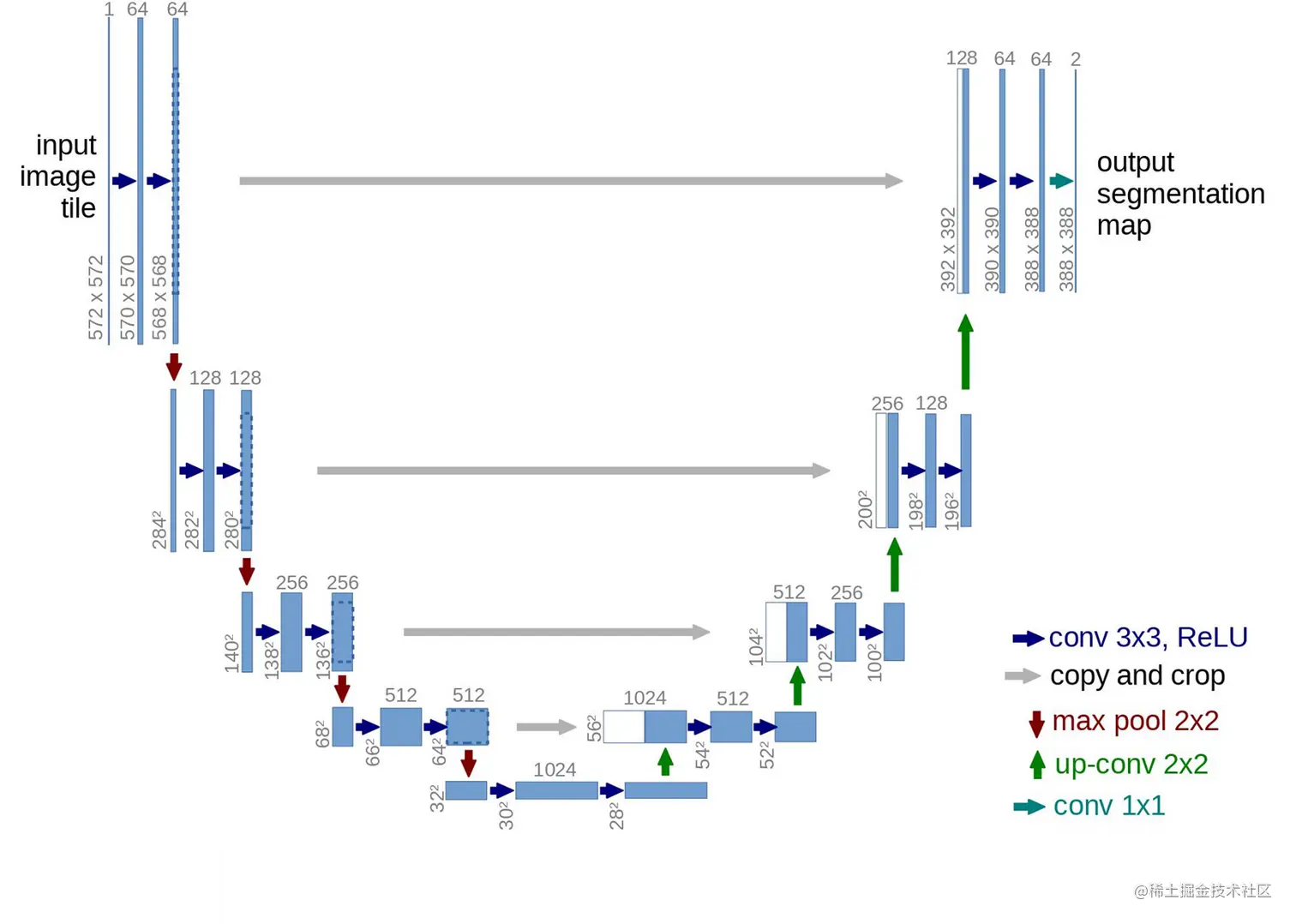
可以看出,U-Net模型首先对输入进行downsamples即在空间分辨率上使输入变小,进行特征提取,然后再进行updownsamples,用于精确定位,文中使用的是bilinear双线性插值。
该网络由收缩路径(contracting path)和扩张路径(expanding path)组成。我们可以将两部分认为是encoder-decoder结构。
接下来介绍一下图像的处理过程。
看一下右下角的图例:
-
蓝色箭头代表3*3的卷积+ReLU
-
灰色箭头代表复制裁剪
-
红色箭头是池化
-
绿色箭头是upsampling上采样
-
青色箭头是坐了个1*1的卷积
-
而图中的蓝色框框就是feature map了。
第一步接收到图像之后是将图像从1通道转化成64通道,顺便做了一个卷积,用的是3x3 的卷积核,padding 为 0 ,striding 为 1,所以每次计算之后图像H、W两个维度都会减2。

第二步是进行一次 stride 为 2 的 max pooling。

之后就是一直重复直到最底下那三个,你先是得到一个32*32通道数为512的features map,然后再进行两次卷积最后得到通道数1024的28*28的features map。
看一下这一部分是怎么来的。白色部分是从左边直接裁剪出来的,用于残差连接,直接拼接到原来的维度上。右边蓝色部分就是通过一个反卷积插值扩大维度。
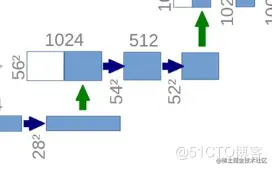
虽然我们认为U-Net属于 FCN 的一种变体,但是在这一步中体现出了FCN和U-Net很重要的一个区别。在这里处理的时候U-Net使用的是concat,将两部分拼接到一起,但是传统的FCN在这一步中是将二者相加。
至于向上的绿色箭头进行反卷积,我们可以简单地理解为使用公式进行定位,以原来features map中的点为核心将图像补全。
将一个 2x2 的矩阵通过插值的方式得到 4x4 的矩阵,那么将 2x2 的矩阵称为源矩阵,4x4 的矩阵称为目标矩阵。双线性插值中,目标点的值是由离他最近的 4 个点的值计算得到的。
计算公式如下:
X后=(X前+0.5)∗( Width 前 Width 后)−0.5Y后=(Y前+0.5)∗( Height 前 Height 后)−0.5
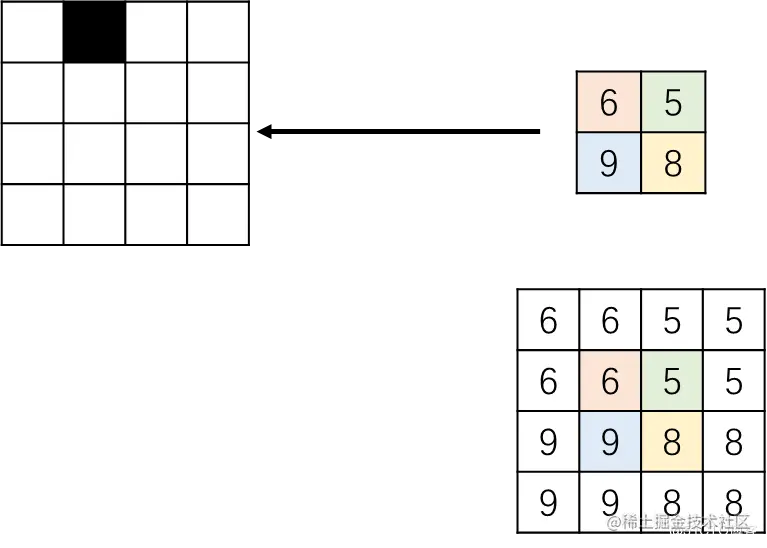
举个例子,假设我们现在要计算这个黑色格子,那根据公式:
0=(X前+0.5)∗2−0.51=(Y前+0.5)∗2−0.5
得到
X前Y前=−0.25=0.25

源矩阵长这样,肯定不能找到(−0.25,0.25)的位置,所以我们将其扩充,找到这个位置周围的四个点即可。
所以对应的四个位置是(−1,0)(−1,1)(0,0)(0,1)
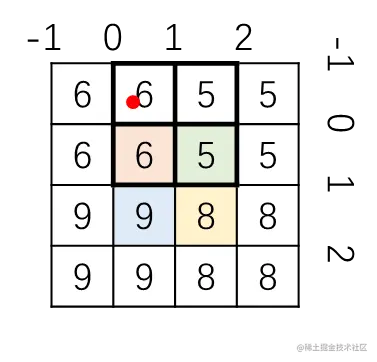
然后使用公式
f(x+u,y+v)=(1−u)(1−v)f(x,y)+(1−u)vf(x,y+1)+u(1−v)f(x+1,y)+uvf(x+1,y+1)

带入计算得到:
(1−0.75)∗(1−0.25)∗6+(1−0.75)∗0.25∗6+0.75∗(1−0.25)∗5+0.75∗0.25∗5=0.25∗0.75∗6+0.25∗0.25∗6+0.75∗0.75∗5+0.75∗0.25∗5=5.25
最终计算得到黑色格子为5.25。

其他过程以此类推。U-Net就是这样,不断使特征变短的过程叫下采样,不断恢复特征长度叫上采样,上下采样两部分共同组成一个U-Net。


