

背景
sealfs 的作者拿过很多编程比赛的世界冠军或者非常好的名次:
- 2019.12 SSCAIT(国际星际争霸 AI 算法开发大赛)
- **在“排位赛”中世界综合排名第 3 位,以 84%的胜率在“近 50 场胜率排行榜”中最高排名第二位。
- 2022.01 RLChina 智能体挑战赛 队长 冠军
- 2018.08 天池阿里巴巴全球调度算法大赛 冠军 总名次 1/2116
- 2017.05 2017 华为软件精英挑战赛 全球总决赛二等奖,名次 2/10000+ 队长
- 2022.03 AI 球球大作战:Go-Bigger 多智能体决策智能挑战赛 总名次 10/1434 队长
- 2020.08 天池首届云原生编程挑战赛 赛道二内部赛道第一名,总名次 7/4031 队长
现在是 sealos 的合伙人,sealfs 也是为 sealos 而生的,准备做一个高性能分布式文件存储,如果整个 sealos 是云操作系统,那 sealfs 就是这个操作系统的磁盘。
sealfs 还有个伟大目标,就是在一年内拿下 io500 的榜首!希望能成功。
sealfs设计文档
丝滑,高性能的分布式文件存储
为什么要为云原生构建新的分布式文件存储
使用本地存储
- 单点故障
云原生应用使用本地持久化存储带来的最大问题是单点故障,由于数据位于某个特定的节点,节点宕机会导致数据不可用,受绑定的应用无法重启,也难以迁移到其他节点。此外单节点磁盘故障甚至会出现数据丢失的问题。
目前对于一些数据可靠性要求高的应用,都在应用层实现了分布式架构,本质上是将复杂性交给了应用,对于复杂的应用而言,成本过高。 - 存储规划与扩容
应用本地存储意味着需要对每个节点进行容量规划,在节点故障时还需要对原本的分布式架构进行额外的迁移配置,带来了巨大的工作量和出错概率。
另一方面,原本的容量不足时,进行节点扩容也是本地存储无法解决的难题。 - 性能效率低下 由于磁盘设备IO,本地存储的性能是存在瓶颈的,多应用共享磁盘时尤其明显。
使用现有分布式存储
-
性能 尽管理论上分布式存储的数据性能随着节点增多可以不受限制,但实际上还是受到几方面的影响。一是集群一致性带来的瓶颈,使用raft等协议的分布式方案存在的问题;二是数据调用流程延长带来的内存拷贝成本,采用fuse的众多文件系统带来的问题;三是元数据请求的瓶颈,典型的是GFS,大规模集群下目录遍历的成本非常高。
-
配置 配置复杂,特别的节点扩容,许多限制要求十分苛刻。典型为GFS扩容极其复杂。cephfs的稳定性较差。
-
价格 高性能的商业分布式存储价格昂贵,开源产品又大多无法相提并论。
适用场景
性能极致方案×可靠数据体验
- 高性能的网络数据访问
- 无分布式元数据的方案
- intercept
- 完整posix请求(link、rename、delete的高效实现)
- 丝滑
- 数据可靠性
- 数据服务高可用性
- 存储节点可扩展
用户接口与系统调用流程
对象存储、文件存储、块存储接口
目前对于存储服务所提供的接口主要有三种,对象存储、文件存储和块存储。
日常使用遇到的大多数是文件存储,应用程序大多也是以文件为单位进行文件操作,请求交给文件系统。而块存储则位于文件系统之下,与存储设备直接对接,其访问目标是存储设备的一段区间,文件存储的请求在处理之后被转换为块存储。
二者在posix都提供了完整的接口标准。在linux中系统中,这两种类型的存储也被纳入了内核中,由内核来处理程序的系统调用。
对象存储则是一类第三方的存储接口,提供单个文件的读写,典型的标准有aws-s3等。这类接口与linux系统无关,访问则需要单独的客户端。
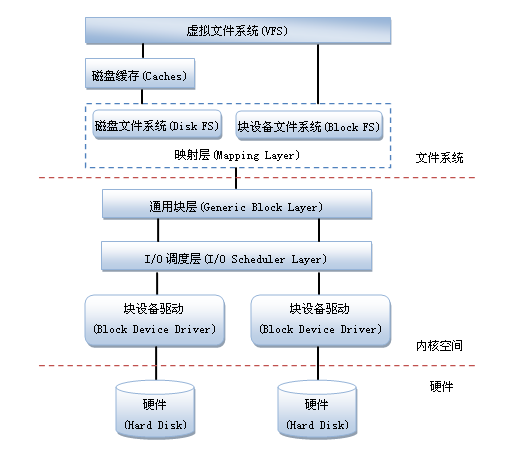
- 本地文件(块)存储调用流程 本地文件存储的一次调用流程包括:
- 用户态请求
- VFS
- 内核文件系统
- 块设备驱动
如果请求是块设备请求,则直接交给内核的块设备驱动(中间省略了两步,不影响)。可以看出无论哪种请求,都只进行一次内核用户态切换。
网络文件(块)存储调用流程
fuse
网络文件存储有许多不同的实现方式,最容易实现且易于使用的fuse。
在fuse中,通过网络进行文件存储的一次调用流程包括:
- 用户态请求
- VFS(切换)
- FUSE内核模块
- 用户态client(切换)
- 用户态server
- vfs(切换)
- 内核文件系统
- 块设备驱动
过程中总共涉及3次用户内核态切换,调用返回后则为6次,成本大大增加。
内核文件系统
为了减少调用次数,另一种实现方案则是直接在内核态实现文件系统,网络请求则在内核态实现。
- 用户态请求
- VFS(切换)
- 内核态client
- 用户态server
- vfs(切换)
- 内核文件系统
- 块设备驱动
这种方案可以将切换次数减少至2次,但缺点也显而易见:
- 内核编程的调试复杂
- 需要为客户端安装额外内核模块
系统调用劫持
此外还有一种方案。在上一节的图中,可以看到,用户请求并不是直接交给linux内核的,而是经过了glibc(或其他libc库)来提交系统调用,这意味着可以在libc层替换系统调用的地址,实现系统调用劫持。
- 用户态请求
- 系统调用劫持client
- 用户态server
- vfs(切换)
- 内核文件系统
- 块设备驱动 这种情况下,用户内核态切换次数仅为一次,网络交互也完全实现在用户态,无论是切换的代价还是编程成本都可以降到最低。
遗憾的是,并不是所有的应用程序都是通过libc进行系统调用的,例如golang的二进制程序,其不使用任何动态链接。
对象存储调用流程
由于对象存储无关系统调用,而是由第三方定义标准,所以无关任何用户内核态切换,没有这一层面上的限制。
这也是为什么开源的对象存储产品如此之多,且性能良好的部分原因了。
结论
fuse作为实现成本最低的一种方式,是实现sealfs的最好选择,但需要注意fuse存在的一些问题,主要需要解决:
- 双缓存
- inode转换
- 其他fuse下冗余的机制
开发内核文件系统不是个好的选择,用户应用所在的节点安装内核补丁可能存在风险与限制。
系统调用劫持的实现难度不高,性能更好,可以作为特殊需求场景的可选支持项。
网络架构

客户端
使用libfuse构建客户端,用于挂载一个目录,并处理所有该目录下的请求。 一个文件请求会被客户端使用在线算法映射到一个服务器,通过socket链接进行传输。
服务器
一个服务器用于组织一部分文件内容,接收任意位置的客户端对于位于该目标服务器的所有文件请求。一个节点上可以存在多个服务器,所有服务器间组织管理的文件内容不存在重合。
数据流连接
一个数据流连接用于保持活跃的服务器连接。一个客户端与一个服务器间仅存在一个(或可配置的有限多个)数据流连接,用于处理客户端所有位于该服务节点的文件请求。
可能的实现方式是直接使用RPC框架,或基于socket或其他网络协议,亦或是各类RDMA。目前直接使用socket实现,有些复杂,具体流程在请求流程中描述并实现。
请求流程
- client接收请求,创建处理线程。创建处理线程的工作是由libfuse实现的,sealfs实现的函数可以认为已经是独立线程。
- 计算文件所在的服务器,内容在元数据管理中,本节不细述。
- 向server发送文件请求,hold线程。发送请求的过程要考虑多个请求并行处理的情况。为每个请求建立一个socket是最简单的实现,但创建连接的延迟过高,网络连接数也可能会过多。保持多个长连接保证了创建连接的延迟问题,但在大并发的情况下,依旧无法解决网络连接数量过多,同时代码的实现也稍显复杂。所以采用了一个长连接共享多个文件请求的方式。一个线程发送请求需要包含该请求的id与数据长度,同时需要实现一个额外的线程安全的队列用于保存发送请求后的线程的锁。
- server处理文件请求,并将请求结果返回给client。处理过程中始终保持了请求的id。
- client接收数据,激活请求线程并处理返回值。一个(或有限多个)独立的线程用于接收请求结果,其中包含了请求的id,需要在队列中查询请求id所对应的线程锁,写入结果并释放该线程锁,激活原请求线程并将结果返回给应用。
上述流程可以横向扩展,一个client可以存在多个长连接,用于解决一个线程处理socket请求带来的cpu瓶颈。
内存拷贝
采用了多个请求共享同一线程的方式,socket发送请求时,由于数据不定长,需要提前发送一个长度变量,才能避免粘包。这里有两种不同的方案:
一种是使用多个socket实现连接池,每次发送一个请求使用一个socket,该方案不存在数据包连续性的问题,可以多次发送。
另一种是用同一个socket,但是要保证数据连续性,需要进行字符串拼接,涉及内存拷贝,开销会变大,那为了避免这个问题,每次发送数据需要给线程加锁,这个是第一个阶段的实现方案。
元数据管理
- 无分布式元数据
在大数据环境下,元数据的体量也非常大,元数据的存取性能是整个分布式文件系统性能的关键。常见的元数据管理可以分为集中式和分布式元数据管理架构。集中式元数据管理架构采用单一的元数据服务器,实现简单.但是存在单点故障等问题。分布式元数据管理架构则将元数据分散在多个结点上.进而解决了元数据服务器的性能瓶颈等问题.并提高了元数据管理架构的可扩展性,但实现较为复杂,并引入了元数据一致性的问题。另外,还有一种无元数据服务器的分布式架构,通过在线算法组织数据,不需要专用的元数据服务器。但是该架构对数据一致性的保障很困难.实现较为复杂。文件目录遍历操作效率低下,并且缺乏文件系统全局监控管理功能。
为了效率采用无元数据的分布式架构,一种简单的实现是使用文件名进行hash,获取对应的服务器id,将所有该文件相关的数据与元数据全部放在该服务器上。其可扩展性也较好,一方面可以实现基于一致性hash的节点扩缩容,另一方面也可以实现基于offset的文件分段,平衡存储空间。这个方法参考GFS、gekkofs。
存在的问题在于两点,一是文件目录的遍历问题,由于元数据分散,需要多次请求各个服务器来获取元数据目录信息。二是目录存储空间的容量难以监控。可能的解决方案是延迟更新所有父目录的元数据,但实际情况可能还有许多复杂问题,例如删除某目录的请求仍需要遍历所有数据。这些问题是GFS等存储方案还未能解决的,解决这些问题会十分有趣,也会使sealfs变得独特。
-
本地元数据管理
每个节点由一个leveldb本地数据库负责存储元数据,以kv的形式保存可以被哈希到该节点的文件名:文件元数据。请求到达时先向数据库查询元数据,再存取对应位置的文件内容。 -
集群元数据管理
对于整个集群来说,除了文件元数据,还需要存储服务器信息,保存有几个节点。由于更新和读取的频率不高(仅在扩缩容时会变更),直接使用raft维护即可。
一些其他的扩展
-
数据可靠性与高可用
一个文件被hash到一个节点上,那么多hash几次就可以分布到多个节点上实现replica。 -
数据扩缩容
基于一致性hash实现扩缩容,具体细节暂时先不讲。需要明确的是添加或删除节点后集群会进行rebalance,这是一致性hash本身需要做的,无需额外设计。rebalance期间会导致集群性能下降,且可能耗费较长时间,但对于可以持续提供服务。在rebalance期间需要做的工作如下:
| 开始扩容 | 迁移数据 | 扩容完成 |
|---|---|---|
| 更新集群元数据 | client进行二次请求,确认迁移后数据和迁移前数据一致性,并将数据写于新节点;同时迁移任务进行数据迁移和同步 | 确认集群元数据 |
-
租户管理
对于不同的client申请挂载的磁盘,进行容量限制隔离 -
内存缓存
在server端实现文件的内存缓存,避免存储瓶颈。但同时要求不能有集群级别的断电。可选实现。
