本文已参与「新人创作礼」活动,一起开启掘金创作之路。
前言
CenterNet是2019年发表的一篇文章《Objects as Points》中提出的一个经典的目标检测算法,该算法采用Anchor-Free的方式实现目标检测及其他一些扩展任务,非常值得研究。
主要思想
CenterNet将目标检测当做一个标准的关键点估计问题,将目标表示为一个在其bounding box中心位置的单独点,其他的一些属性比如目标尺寸、维度、朝向和姿态等则直接从这个中心点位置的图像特征中进行回归。该模型将图像输入到一个全卷积网络中用来生成热力图,热力图的峰值位置即为目标的中心,每个峰值位置的图像特征用来预测目标bounding box的宽度和高度。该模型训练过程采用标准的监督学习方法,推理过程则是简单的网络前向传播而不需要在后处理中做非极大值抑制处理。
这篇文章提出的是一个通用的目标检测方法,只需要在中心点的预测中添加一些额外的内容就可以非常简单地扩展到其他任务中去,比如3D目标检测和人体姿态估计。对于3D目标检测任务,是通过回归目标的绝对深度、3D bounding box维度和目标的朝向来实现的;而对于人体姿态估计任务,则是将2D关节位置视为距中心点的偏移量,并且在中心点位置直接回归得到它们。

原理
输入一张宽高分别为W和H的3通道图像I∈ℜW×H×3,CenterNet模型会输出关键点的热点图Y^∈[0,1]RW×RH×C,其中R表示热点图相对于输入图像的下采样因子,论文里默认为4;C表示关键点类别的数量,如果是用COCO数据集训练的2D目标检测任务那么C=80,如果是人体姿态估计任务那么C=17。在热点图中,Y^x,y,c=1 表示在(x,y)坐标位置检测到一个类别为c的关键点;反之,如果Y^x,y,c=0 表示在该位置不存在类别为c的关键点。
作者采用ResNet、DLA、Hourglass等几种不同的编码-解码结构的全卷积神经网络从图像I中预测关键点Y^,训练方式沿用CornerNet``的方法。对于ground truth中每个类别为c的关键点p∈ℜ2,需要在下采样R倍后的热点图上计算一个等效的关键点p~=⌊Rp⌋:通过一个高斯核函数Yxyc=exp(−2δp2(x−px~)2+(y−py~)2),把ground truth中所有的关键点映射到热点图Y∈[0,1]RW×RH×C中,其中δp是一个与目标尺寸有关的标准差。如果某个类别的两个高斯分布区域存在重叠,那么就直接取元素值最大的就可以。
对于一个类别为ck的目标k,我们通常会用一个坐标为(x1(k),y1(k),x2(k),y2(k))的bounding box来表示它在图像中的位置,那么它的中心点坐标为pk=(2x1(k)+x2(k),2y1(k)+y2(k))。通过前面的知识我们知道,CenterNet模型就是通过关键点估计的方式来预测所有目标的中心点,但是只有一个中心点还不足以表达一个bounding box,还需要预测出它的尺寸sk=(x2(k)−x1(k),y2(k)−y1(k)),所以CenterNet用了一个分支S^∈ℜRW×RH×2来预测目标的宽度和高度。为了减少因为下采样带来的中心点坐标精度误差,作者还添加了一个中心点坐标偏置预测分支O^∈ℜRW×RH×2来进行补偿。

在推理阶段,首先从每个类别的热点图中提取峰值点,如果一个点的值大于等于它的8邻域内点的值,那么就认为这个点是一个峰值点,然后从这些候选的峰值点中选取前100个点作为检测到的中心点。对于n个检测到的中心点集合P^={(x^i,y^i)}i=1n中类别为c的中心点P^c,它的置信度为Y^xiyic,它的位置则用整型坐标值(xi,yi)来表示,以它为中心点的一个目标的bounding box可以通过下面的公式计算出来:
(x^i+δx^i−w^i/2,y^i+δy^i−h^i/2,x^i+δx^i+w^i/2,y^i+δy^i+h^i/2)
其中,(δx^i,δy^i)=O^x^i,y^i是预测的中心点偏置值,(w^i,h^i)=S^x^i,y^i是预测的宽度和高度值。需要注意的是,这里得到的bounding box的坐标只是相对于热点图尺寸的坐标,如果要得到相对于原始图像尺寸的坐标,还需要乘以前面提到的下采样系数R。最终所有的目标信息都是直接通过上述关键点估计的方式得到而不需要基于IoU的非极大值抑制(NMS)或者其他后处理操作,因为峰值关键点选取的过程就是一次充分的NMS操作,这个操作可以通过一个3×3的MaxPooling算子来实现。
损失函数
CenterNet的损失函数分为3个部分:
Ldet=Lk+λsizeLsize+λoffLoff
其中Lk,Lsize,Loff分别为中心点预测分支损失函数、尺寸预测分支损失函数和中心点偏置预测分支损失函数,设置λsize=0.1,λoff=1。
中心点预测分支损失函数
该分支损失函数采用focal loss损失函数:
Lk=N−1xyc∑{(1−Y^xyc)αlog(Y^xyc)(1−Yxyc)β(Y^xyc)αlog(1−Y^xyc)ifYxyc=1otherwise
其中,α和β是focal loss的超参数,分别设置为2和4;N是输入图像I中关键点的数量,用于将所有的positive focal loss实例标准化为1。
尺寸预测分支损失函数
该分支的损失函数采用L1损失:
Lsize=N1k=1∑N∣∣S^pk−sk∣∣
中心点偏置预测分支损失函数
该分支的损失函数同样采用L1损失:
Loff=N1p∑∣∣O^p~−(Rp−p~)∣∣
扩展任务
3D目标检测就是给每个目标去估计一个3维的bounding box,这需要3个额外的属性:深度、3D维度和朝向,这3个属性通过3个独立的分支进行预测。

人体姿态估计的目的是找出图像中每个人体实例的k个关节位置(COCO数据集k=17)。可以将姿态视为是包含k×2维属性的中心点,并且通过到中心点的偏移量对每个关键点进行参数化,另外还使用一个热点图预测分支用于对关键点进行提纯。

检测结果
以下是用官方的代码和模型跑出来的一些结果。
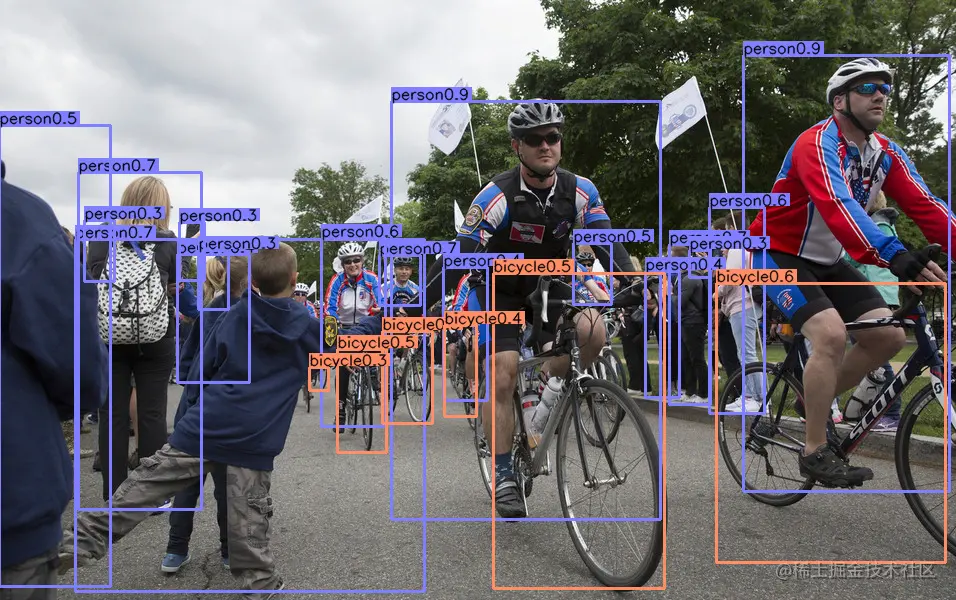
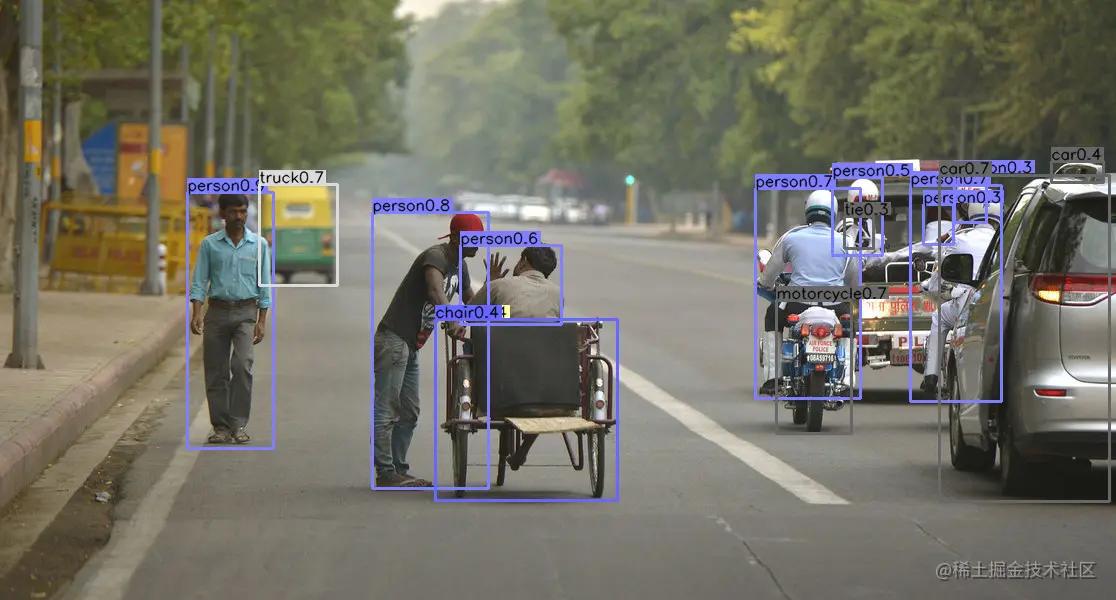
2D目标检测
用COCO数据集训练的2D目标检测的结果如下:
3D目标检测
用KITTI数据集训练的3D目标检测的结果如下:


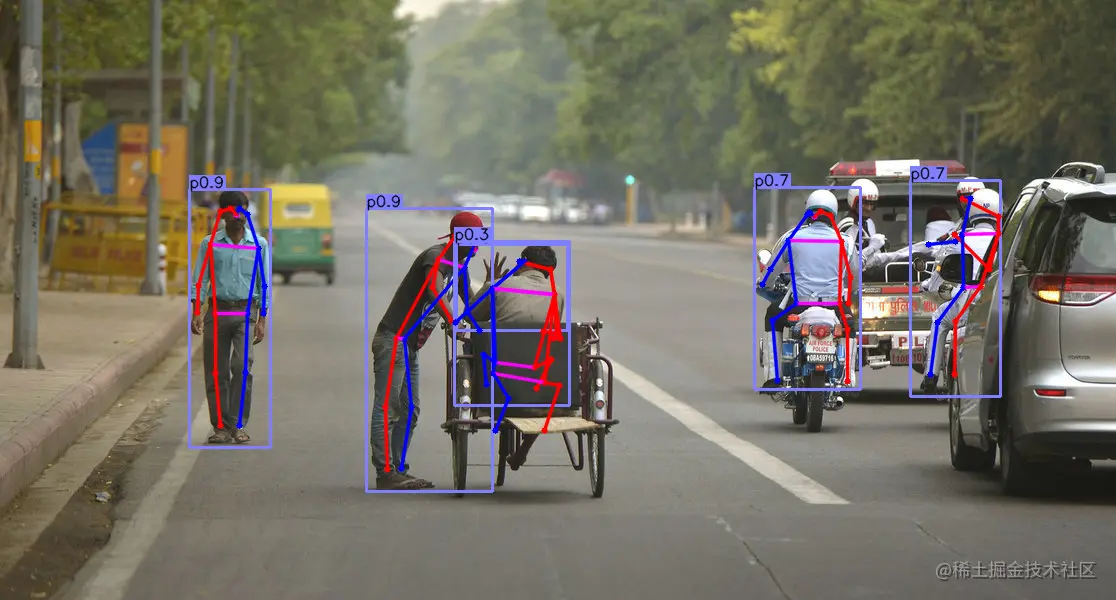
人体姿态估计
用COCO数据集训练的人体姿态估计的结果如下:

总结
读完《Objects as Points》这篇文章,我的感觉是文如其名,简单而又优雅。文中提出的目标检测算法CenterNet,模型结构简单,速度快又效果好,而且还方便扩展,确实是非常经典!


