

1.模型结构
YOLOv5 (v6.0/6.1) consists of:
Backbone: New CSP-Darknet53
Neck: SPPF, New CSP-PAN
Head: YOLOv3 Head
模型结构 (yolov5l.yaml):
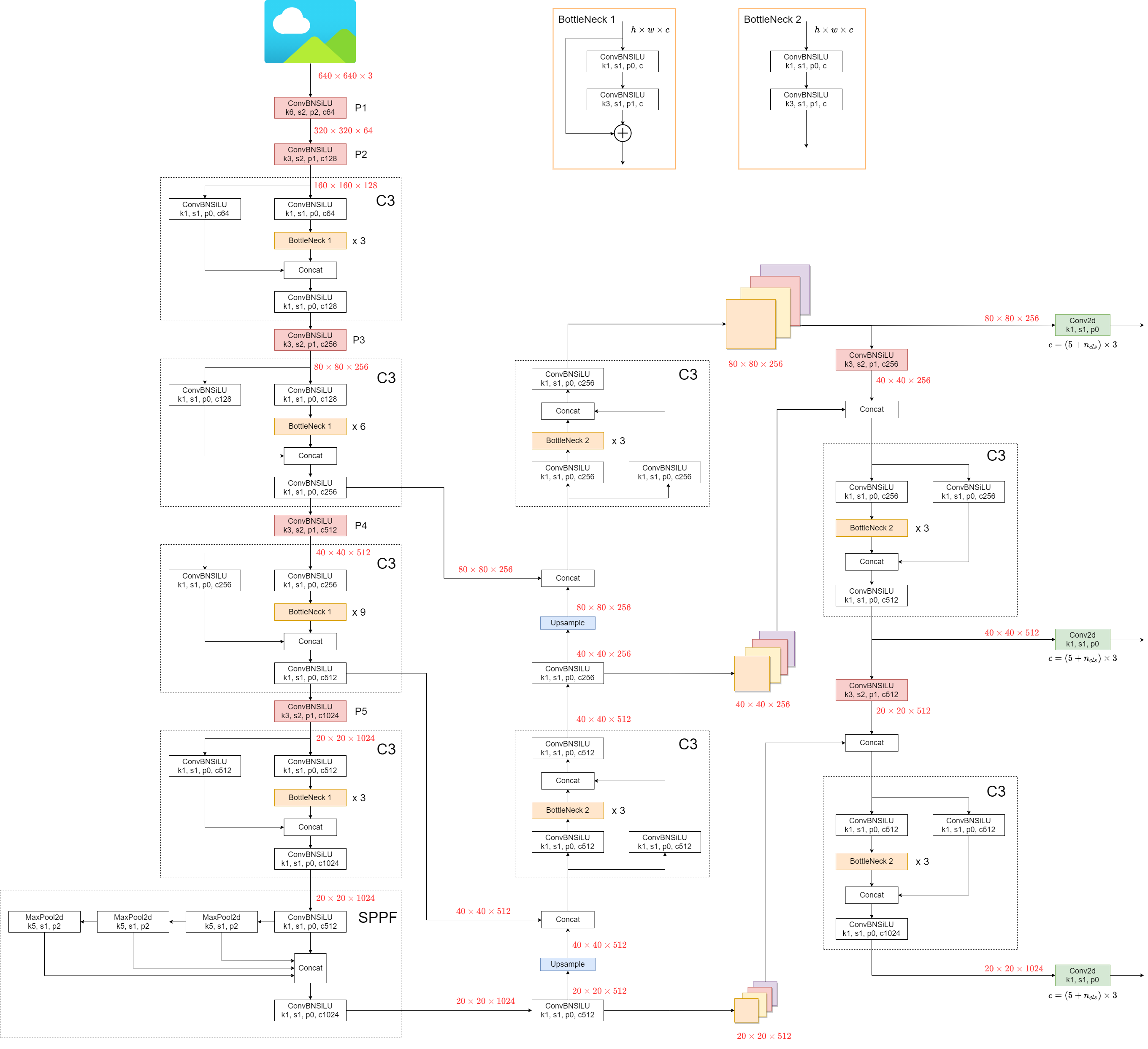
相比以前的版本有一些小的改变:
- 替换 Focus 结构通过 6x6 Conv2d (更多的细节详见,github.com/ultralytics…)
- 替换 SPP 结构通过 SPPF (速度优化了两倍,具体如下)
- 测试代码:
import time
import torch
import torch.nn as nn
class SPP(nn.Module):
def __init__(self):
super().__init__()
self.maxpool1 = nn.MaxPool2d(5, 1, padding=2)
self.maxpool2 = nn.MaxPool2d(9, 1, padding=4)
self.maxpool3 = nn.MaxPool2d(13, 1, padding=6)
def forward(self, x):
o1 = self.maxpool1(x)
o2 = self.maxpool2(x)
o3 = self.maxpool3(x)
return torch.cat([x, o1, o2, o3], dim=1)
class SPPF(nn.Module):
def __init__(self):
super().__init__()
self.maxpool = nn.MaxPool2d(5, 1, padding=2)
def forward(self, x):
o1 = self.maxpool(x)
o2 = self.maxpool(o1)
o3 = self.maxpool(o2)
return torch.cat([x, o1, o2, o3], dim=1)
def main():
input_tensor = torch.rand(8, 32, 16, 16)
spp = SPP()
sppf = SPPF()
output1 = spp(input_tensor)
output2 = sppf(input_tensor)
print(torch.equal(output1, output2))
t_start = time.time()
for _ in range(100):
spp(input_tensor)
print(f"spp time: {time.time() - t_start}")
t_start = time.time()
for _ in range(100):
sppf(input_tensor)
print(f"sppf time: {time.time() - t_start}")
if __name__ == '__main__':
main()
- result:
True
spp time: 0.5373051166534424
sppf time: 0.20780706405639648
2.数据增强
参数解析:
具体在 data/hyps/*.yaml配置文件中。 这里以hyp.scratch-low.yaml文件进行解析:
表2.1:数据增强参数表
| 参数名 | 配置 | 解析 |
|---|---|---|
| hsv_h: | 0.015 | # image HSV-Hue augmentation (fraction) 色调 |
| hsv_s: | 0.7 | # image HSV-Saturation augmentation (fraction) 饱和度 |
| hsv_v: | 0.4 | # image HSV-Value augmentation (fraction) 曝光度 |
| degrees: | 0.0 | # image rotation (+/- deg) 旋转 |
| translate: | 0.1 | # image translation (+/- fraction) 平移 |
| scale: | 0.9 | # image scale (+/- gain) 缩放 |
| shear: | 0.0 | # image shear (+/- deg) 错切(非垂直投影) |
| perspective: | 0.0 | # image perspective (+/- fraction), range 0-0.001 透视变换 |
| flipud: | 0.0 | # image flip up-down (probability) 上下翻转 |
| fliplr: | 0.5 | # image flip left-right (probability)左右翻转 |
| mosaic: | 1.0 | # image mosaic (probability) 图拼接 |
| mixup: | 0.1 | # image mixup (probability) 图像融合 |
| copy_paste: | 0.0 | # segment copy-paste (probability) 分割填补 |
-
Mosaic

-
Copy paste

-
Random affine(Rotation, Scale, Translation and Shear)

-
MixUp

-
Albumentations
-
Augment HSV(Hue, Saturation, Value)

-
Random horizontal flip

3.训练策略
- Warmup and Cosine LR scheduler(多卡训练)
- AutoAnchor(对于训练一般的数据集)
- Warmup and Cosine LR scheduler(热身和CosineLRScheduler调度器)
- EMA(Exponential Moving Average) (指数移动平均)
- Mixed precision (混合精度)
- Evolve hyper-parameters(超参数进化)
4.其他
4.1 计算Losses
主要包含三个部分:
- Classes loss(BCE loss)
- Objectness loss(BCE loss)
- Location loss(CIoU loss)
4.2 Losses损失
三个预测层(P3、P4、P5)的目标损失被不同地加权。平衡重分别为[4.0,1.0,0.4]。
4.3 消除坐标影响
在YOLOv2和YOLOv3中,用于计算预测目标信息的公式为:

在YOLOv5中,用于计算预测目标信息的公式为:
比较缩放前后的中心点偏移。中心点偏移范围从(0,1)调整到(-0.5,1.5)。
因此,偏移可以很容易地得到0或1。

比较调整前后的高度和宽度比例( 相对于锚框(anchor) )。原始的yolo/darknet 计算方程有一个严重的缺陷。宽度和高度完全是无界的,因为它们只是out=exp(in),这是危险的,因为它可能导致失控的梯度、不稳定性、NaN损失,最终导致训练的完全损失。参考这个 issue

4.4 建立 Targets
- 匹配正样本:

- 将成功匹配的锚框(anchor)分配给对应的单元格。

- 因为中心点偏移范围从(0,1)调整到(-0.5,1.5)。GT框可以分配给更多锚框(anchor)。

个人水平有限,翻译有问题,欢迎评论区留言。
