参考网址
blog.csdn.net/a7303349/ar…
1/什么是shap value
shap value(shap值)衡量特征的边际贡献度,是当前模型解释的最佳方法之一,
对于模型进行可视化的全局解释、局部解释,可以在一定程度上满足业务对于模型解释性的要求。
全局解释,特征对于整体模型的影响,可以作为特征重要性帮助筛选变量;
局部解释,对单个样本的预测结果进行解释,可以直观地让我们看到单个样本预测结果的主要影响因素-特征有哪些、以及相应的影响程度,这样在风控业务中对于模型预测风险偏高的样本、我们可以给出模型认为他风险偏高的原因。
2/shap的本质原理
有甲、乙、丙三个工人,单人工作时、多人协同工作时每天的罐子产量如下:
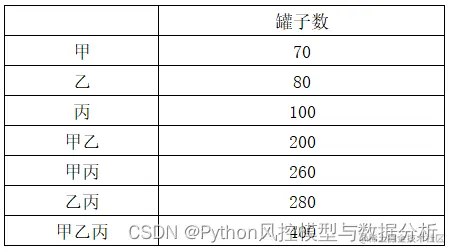
按照产量计算每个人的边际贡献度:

得到每人的平均贡献度:

3/代码应用(以xgboost模型为例子)
<1>导入包,及训练模型
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings('ignore')
from sklearn.model_selection import train_test_split
from sklearn.metrics import roc_curve,roc_auc_score
import xgboost as xgb
import matplotlib.pyplot as plt
train = df_train.head(10000)
test = df_train.tail(5000)
dtrain = xgb.DMatrix(train[col_list], label = train['isDefault'])
dtest = xgb.DMatrix(test[col_list], label = test['isDefault'])
params={
'booster': 'gbtree',
'objective': 'binary:logistic',
'eval_metric': [ 'logloss','auc'],
'gamma':10,
'max_depth': 3}
xgb_model = xgb.train(params=params,
dtrain=dtrain,
verbose_eval=True,
evals=[(dtrain, "train"), (dtest, "valid")],
early_stopping_rounds=10,
num_boost_round = 30
)
<2>Shap包导入及shap_value计算
import shap
shap.initjs()
explainer = shap.Explainer(xgb_model)
shap_values = explainer.shap_values(train[col_list])
shap_values2 = explainer(train[col_list])
shap_values2
4/局部可解释性
对单个样本的预测结果解释,通过shap值展示出各特征值对当前预测结果的贡献度,
可以使用shap值top变量给出该条样本最终被拒绝的原因
<1>力图
shap.plots.force(shap_values[0])
此处第一条样本的实际预测结果为0.3338,在力图及下面瀑布图中显示的结果-0.69与预测概率为logit的关系,两者保持单调;图中红色条框为正向影响、蓝色条框为负向的变量,下方均为相应变量以及变量值,其中interestRate的正向贡献度最大。


<2> 瀑布图
shapley_value(train[col_list].head(1),model,max_display=10)
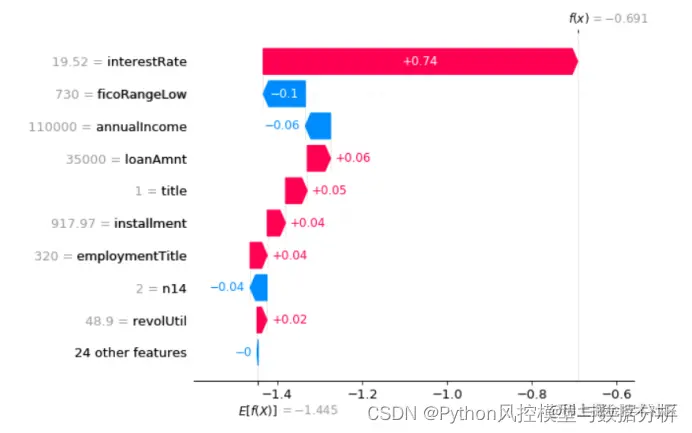
瀑布图中给出了基准线E[f(x)] = -1.445,对应的预测概率计算方式为取反logit:p=1-1/(math.exp(-1.445)+1)=0.19为平均预测概率,此处interestRate贡献度为0.74。
瀑布图更加直观地展示出模型对于单个样本预测结果的解释,该样本的预测结果0.3338,结合下图的散点图(interestRate与y标签保持正向相关性)可以给出解释:由于该样本的interestRate值偏高,导致预测概率偏高。
<3>散点图-依赖图
shap.plots.scatter(shap_values2[:,"interestRate"])
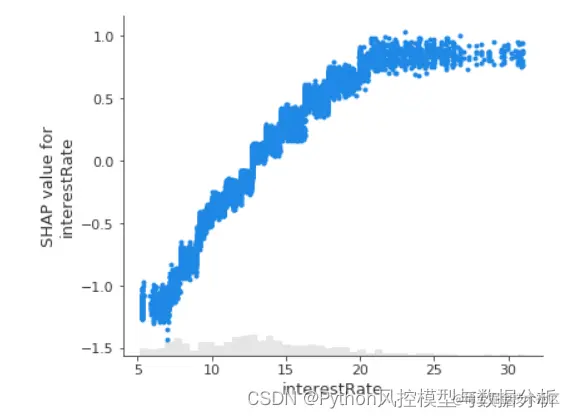
散点图可以大致看到interestRate特征与shap值是正相关关系,即其他特征稳定的条件下,interestRate特征值越大、shap值越大、对应的最终预测概率越高。
shap.dependence_plot('interestRate', shap_values2.values, train[col_list])
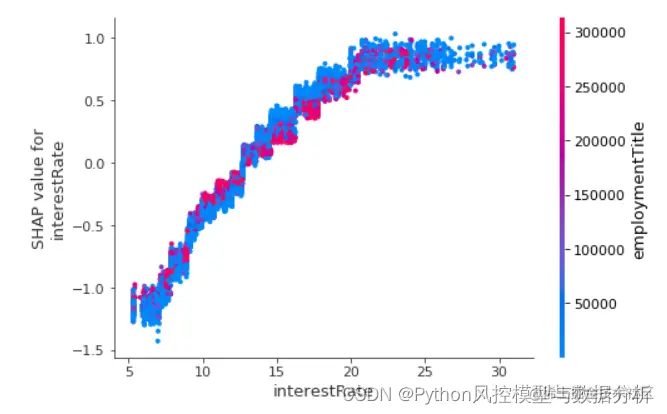
5/全局可解释性
<1>蜂窝图
shap.plots.beeswarm(shap_values2)
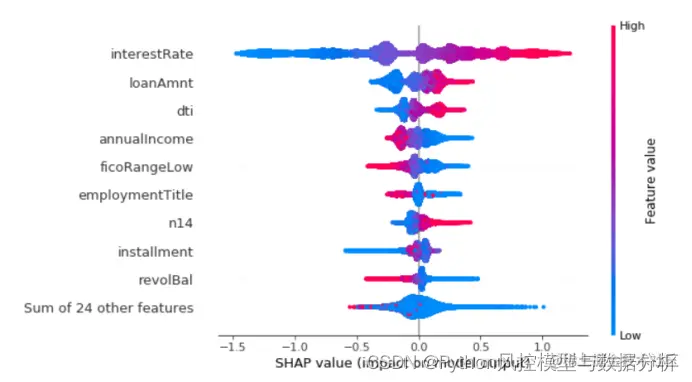
为了了解哪些特征对模型最重要,我们可以绘制每个样本的每个特征的 SHAP 值。
蜂窝图按照所有样本的 SHAP 值之和对特征进行降序排序(即特征重要性降序排序),并使用 SHAP 值显示每个特征对模型输出结果的影响分布。颜色代表特征值(红色代表特征值高,蓝色代表特征值低)。
此处,红色方向在右边代表特征对模型预测结果的影响为正向的,反之为逆向的。
<2>平均shap值的条形图
shap.plots.bar(shap_values2)
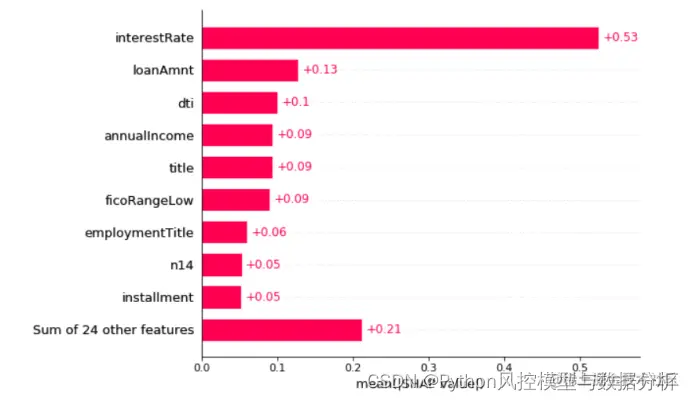
此处取每个特征 SHAP 值的平均绝对值来获得标准条形图,效果类似于feature_importance的条形图,可以通过设置参数来显示多个特征shap值,其他特征的总shap值会放在最后一条。


