携手创作,共同成长!这是我参与「掘金日新计划 · 8 月更文挑战」的第26天,点击查看活动详情
Transformer
论文:Attention Is All You Need
总体架构
Transformer 模型就像论文标题一样,只需要用到 Attention 机制,完全不需要 CNN,RNN 等模型,就可以解决很多问题。
Transformer模型总体的样子如下图所示:
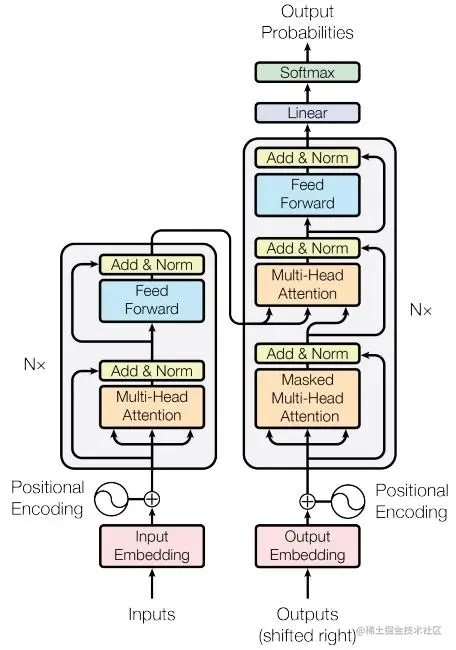
从整体讲本质上是一个Encoder-Decoder的结构,左边是 Encoder部分,右边是 Decoder 部分。
Encoder部分:单词的 Embedding 信息加上位置编码(Positional Encoding),进入多个结构中,该结构分为两部分,第一个部分是 多头的自注意力机制,第二个部分是 Feed Forward,是一个全连接层,每个部分都借用了残差的思想,并且后面加上了 Normalization 层。
Decoder层:第一次输入是上一次的产生的 Embedding,加上位置编码,进入多个模块结构中,该结构分为三个部分:第一和第二部分是一个 Attention 层,第三层是一个全连接层,每个部分都是用了残差思想加上Normalization 层。
输出:经过全连接层,通过 softmax 进行预测。
Encoder 模块
位置编码
在输入信息中不仅仅是单词的 Embedding,还需要 Positional Encoding。为什么要加上 Positional Encoding 信息?因为我们想要网络知道单词所在的句子的位置,网络的注意力不仅仅是句子中不同单词,还需要知道单词的距离。因为模型没有用到 RNN 和 CNN,为了让模型能利用序列的顺序,必须输入序列中词的位置。
论文给出的编码公式如下:
PE(pos,2i)PE(pos ,2i+1)=sin(100002i/dmodel pos)=cos(100002i/dmodel pos)
pos:单词位置, i:单词维度。
优点:
- 任意位置 PEPOS+K 都可以被 PEPOS 所表示。因为使用的是三角函数,三角函数相关公式:
cos(α+β)=cos(α)cos(β)−sin(α)sin(β)sin(α+β)=sin(α)cos(β)+cos(α)sin(β)
- 可以使模型外推到比训练过程中遇到的序列更长的序列长度。
self-Attention 机制
可以参考 自注意力机制,不会花很多文字讲了。
整体的过程如下:
- 将输入信息转化成三个不同的向量,分别是:qi,ki,vi。
- 根据公式开始计算αi,j=dqi⋅kj 。
- 该结果经过 softmax 函数。
- 根据bi=∑jαˉi,jvj 计算语义编码,输入下一个部分中。
整体过程可以利用一个函数进行总结:
Attention(Q,K,V)=softmax(dkQKT)V
为什么要除以 d ?
为了防止发生梯度爆炸,维数过高时QKT的值过大。至于带上一个根号,是根据经验而来,可能是希望值适当增加。
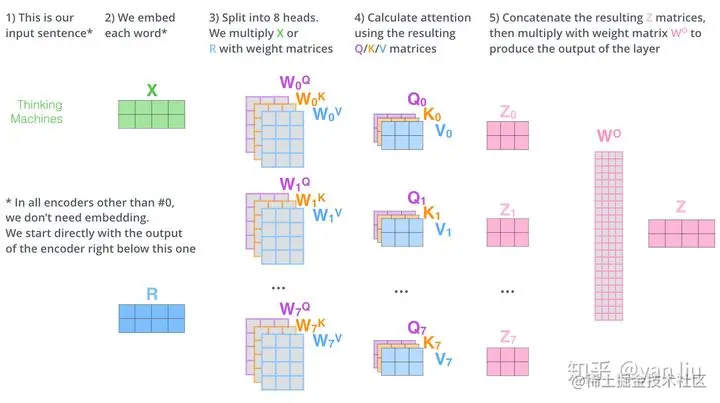
其实模型使用的是 Multi-Head Attention。当模型拥有多套 qi,ki,vi 值时候,可以从多个角度去理解输入信息,具有多个角度的特征。
输入一个单词会有多个版本的语义编码,多个语义编码拼接成一个大的特征矩阵,经过一个全连接层得到对应的语义编码 zi。
整个过程如下图:
参考
luweikxy.gitbook.io/machine-lea…
zhuanlan.zhihu.com/p/48508221


