

用跨模态嵌入发现系统性错误
在这篇博文中,我们介绍了Domino,一种发现机器学习模型的系统性错误的新方法。我们还讨论了一个定量评估Domino等方法的框架。
在验证数据的连贯切片上,达到高总体精度的机器学习模型往往会出现系统性错误。
什么是片断?切片是一组具有共同特征的数据样本。举例来说,在大型图像数据集中,老式汽车的照片构成一个切片(即切片中的所有图像都有一个共同的主题)。片断这个词有很多同义词,你可能更熟悉(例如,子组、子种群、分层)。这些术语在很大程度上是可以互换的,但我们将在这篇文章中坚持使用 "切片"。如果一个模型在某个片区的数据样本上的表现明显差于其整体表现,我们就说该模型在该片区表现不佳。
寻找表现不佳的片断是模型评估的一个关键部分,但常常被忽视。当从业人员意识到他们的模型在哪些片断上表现不佳时,他们可以围绕模型部署做出更明智的决定。这在像医学这样的安全关键环境中尤为重要:一个在年轻病人身上表现不佳的诊断模型很可能不应该被部署到儿科医院。分片意识也可以帮助从业者调试和改进模型:在识别出表现不佳的片断后,我们可以通过更新训练数据集或使用稳健的优化技术来提高模型的稳健性*(例如* Sohoni等人,2020; Sagawa等人,2020)。
部署在关键数据片上表现不佳的模型可能会产生重大的安全或公平的后果。例如,为检测胸部 X 光片中的肺塌陷而训练的模型已被证明可以根据胸腔引流管的存在进行预测,而胸腔引流管是治疗期间通常使用的设备*(Oakden-Rayner,2019)*。因此,这些模型往往不能检测到没有胸腔引流管的图像中的肺塌陷,这是一个关键的数据片,错误的负面预测可能会危及生命。
然而,在实践中,一些表现不佳的片断是很难发现的。这些 "隐藏 "的数据片中的例子是由一个没有在元数据中注释的概念或从非结构化输入(如图像、视频、时间序列数据)中容易提取的概念联系起来的。回到我们前面的例子,许多胸部X射线数据集没有提供元数据,表明哪些病人的图像显示了胸管,这使得我们很难评估该片的性能。这就提出了以下问题。我们如何能自动识别我们的模型在哪些数据片上表现不佳?
在这篇博文中,我们讨论了我们最近对这个问题的探索。我们介绍了Domino,一种识别和描述表现不佳的片断的新方法。我们还讨论了一个评估框架,用于在不同的切片类型、任务和数据集上对我们的方法进行严格的评估。
什么是分片发现?
分片发现是挖掘非结构化输入数据*(如*图像、视频、音频)的任务,以寻找模型表现不佳的、有语义的子组。我们把挖掘输入数据中具有语义的片断的自动化技术称为**片断发现方法(SDM)。**给定一个标记的验证数据集和一个训练有素的分类器,SDM计算出一组切片函数,将数据集划分为若干片断。这个过程如下图所示:
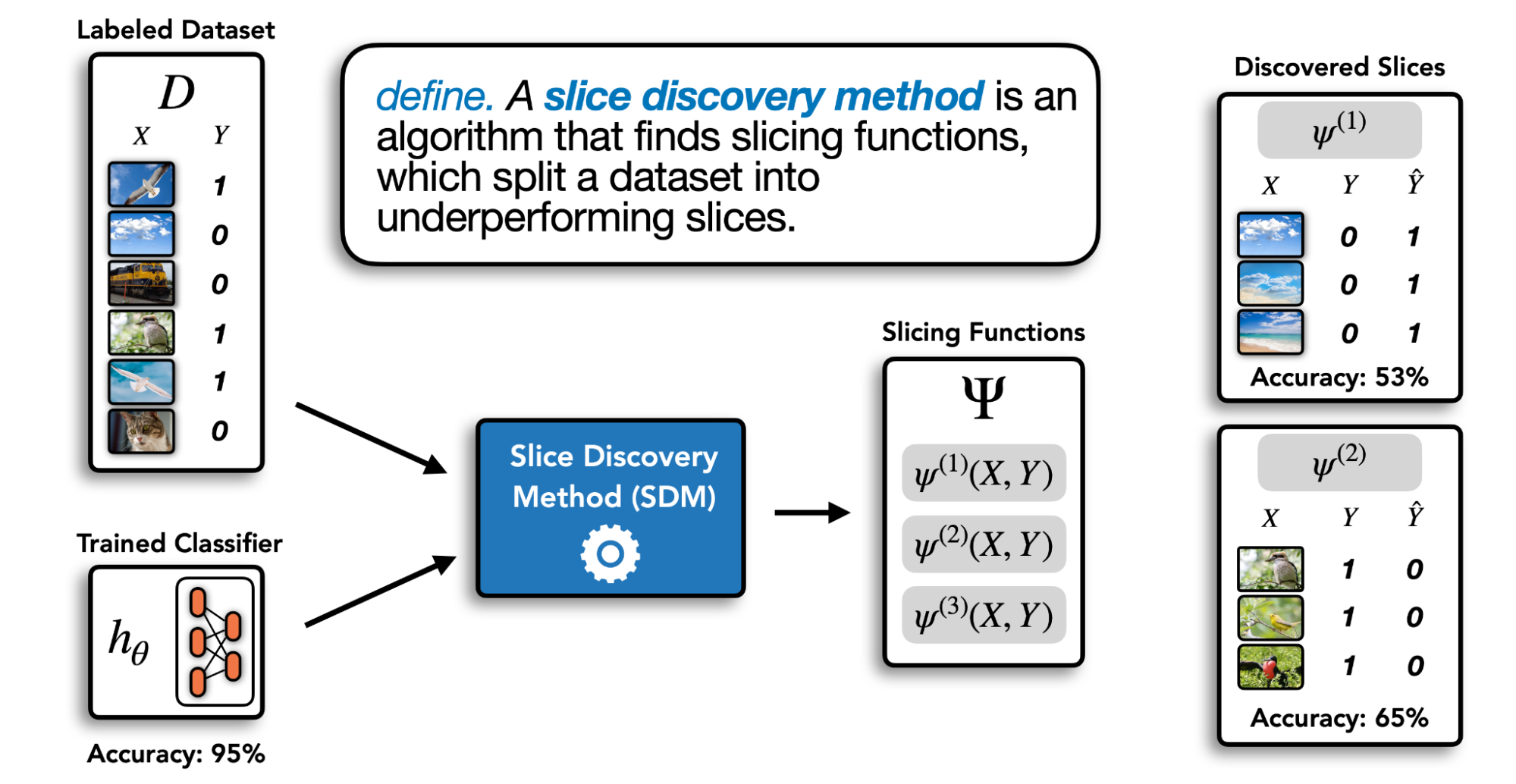
为了在不同的环境中广泛使用,一个理想的SDM应该满足以下要求:
- 识别的片断应该包含模型表现不佳或错误率高的例子。
- 识别的片断应该包含连贯的例子,或者与人类可理解的概念紧密结合。
这第二个要求特别难以实现:现有的评估表明,发现的片断往往与领域专家可以理解的概念不一致。此外,即使切片与概念完全一致,人类也很难识别其共同点。
多米诺:跨模式嵌入的切片发现
在我们的工作中,我们介绍了Domino,一种旨在识别连贯的、表现不佳的数据片*(即*模型出错的类似验证数据点群)的片发现方法。它利用了最近开发的一类强大的跨模式表征学习方法,该方法通过将图像和文本嵌入同一潜在空间来产生有语义的表征。我们证明,使用跨模态表征既能提高切片的连贯性,又能使Domino为识别的切片生成自然语言描述!
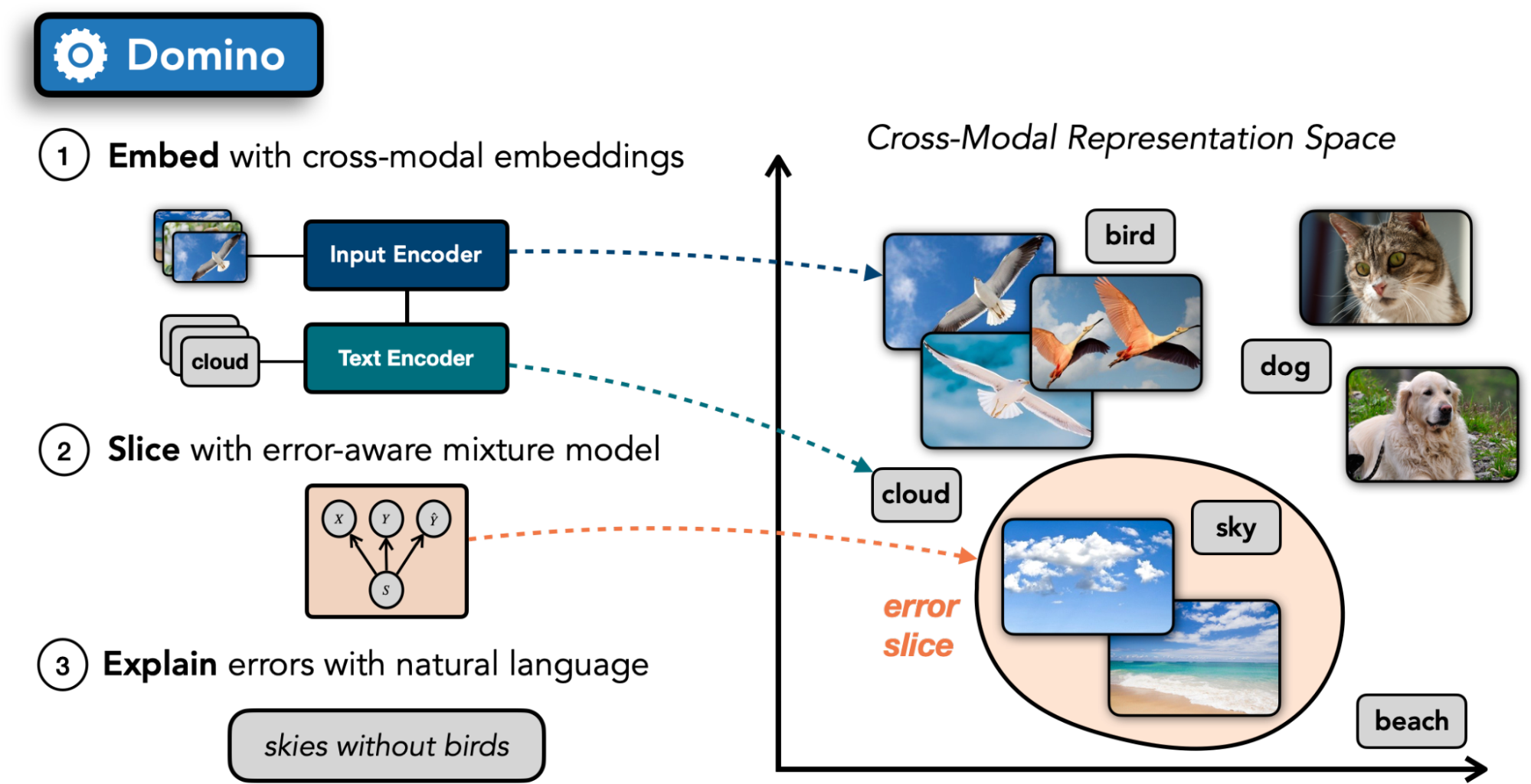 Domino遵循上图所示的三步程序:
Domino遵循上图所示的三步程序:
- 嵌入:Domino使用跨模式编码器在一个共享的嵌入空间中对验证图像和文本进行编码。在许多领域,这样的编码器是公开可用的*(例如*,自然图像的 CLIP,自然视频的VideoCLIP,医学图像的ConVIRT,以及氨基酸序列的CLASP)。
- 切片:使用一个错误感知的混合模型,Domino识别出嵌入空间中错误高度集中的区域。
- 描述:最后,为了帮助从业者了解每个切片中的例子的共性,Domino生成了切片的自然语言描述。为此,它利用步骤1中计算的跨模式嵌入,浮现出嵌入空间中最接近切片的文本。
我们现在用Domino来审核一个流行的现成分类器:一个 在ImageNet上预训练的ResNet18。具体来说,我们审视该模型检测汽车的能力,探索是否有任何有趣的切片,该模型在这些切片上表现不佳。在下图中,我们展示了Domino发现的几个片断。灰色方框显示了Domino产生的两个片断的自然语言描述,X行显示了分配给该图片的地面真实标签,行显示了ResNet18预测的 "汽车 "类的概率。请注意,虽然我们这里只包括六张图片,但完整的切片包括几十张图片:

从这些片断中,我们可以假设,该模型在识别从内部拍摄的汽车照片和赛车照片时很吃力*。*这两个片断都描述了目标类的罕见子类。根据模型的预期使用情况,我们可能想增加更多的训练实例来提高这些片断的性能。例如,Waymo(一家自动驾驶汽车公司)可能不太关心模型是否错过了汽车内饰的照片,但ESPN(一家拥有一级方程式电视转播权的广播公司)会非常关心模型是否无法识别赛车显然,对从业人员来说,发现的切片映射到连贯的概念上是很重要的。
评估片断发现方法
在设计Domino的过程中,我们受到了最近提出的一些真正令人兴奋的切片发现方法的启发。这些方法包括The Spotlight(D'Eon等人,2022),GEORGE(Sohoni等人,2020),以及MultiAccuracy Boost(Kim等人,2018)。这些方法都有(1)嵌入步骤和(2)切片步骤,像Domino一样,但使用不同的嵌入和切片算法。在我们的实验中,我们沿着这两条轴线评估SDM,消减了嵌入和切片算法的选择。值得注意的是,这些方法不包括(3)描述步骤,通常需要用户手动检查例子并识别共同属性。
由于缺乏简单的定量方法,像Domino这样的SDM传统上都是定性评估。通常,在这些评估中,SDM被应用于一些不同的模型,并对识别的切片进行可视化。然后,从业人员可以检查这些切片并判断这些切片是否 "有意义"。然而,这些定性的评价是主观的,并没有超过几个设置的规模。此外,它们不能告诉我们SDM是否遗漏了一个重要的、连贯的片断。
理想情况下,我们想估计SDM的失败率:它未能识别模型表现不佳的连贯片断的频率。估计这个失败率是非常具有挑战性的,因为我们通常不知道模型表现不佳的全部片断。我们怎么可能知道SDM是否遗漏了什么?
为了解决这个问题,我们训练了1235个深度分类器,这些分类器被特别限制在预先定义的片断上表现不佳。我们在三个领域做到了这一点:自然图像、医学图像和医学时间序列。我们的方法包括:(1)获得一个带有一些注释片断的数据集*(例如一个带有有趣的注释属性的数据集,如CelebA或MIMIC-CXR),以及(2)操纵该数据集,使得在其上训练的模型很可能在一个或多个注释片断上表现不佳(例如,*通过对数据集进行子采样,在标签和元数据字段之间引起虚假的相关性)。
使用这个评估框架,我们能够对Domino进行定量评估。我们发现,在我们的框架中,Domino准确地识别了1,235个切片中的36%。此外,在35%的情况下,生成的切片的自然语言描述与切片的名称完全一致。
我们还能够比较SDM,并进行消融研究,评估特定的SDM设计选择。从这些实验中得出了两个关键的发现:
- 跨模态嵌入提高了SDM的性能:我们发现,表示法的选择很重要--非常重要!基于跨模态嵌入的切片发现方法比基于单一模态的方法在精度上至少要高出9个百分点,即10分。如果与使用训练过的模型的激活值相比,差距增长到15个百分点。鉴于分类器的激活是现有SDMs中一个流行的嵌入选择,这一发现特别令人感兴趣。
- 对预测和类标签进行建模能够实现准确的切片发现:仅仅有好的嵌入是不够的--从嵌入空间中实际提取表现不佳的片断的算法选择也很重要。我们发现,一个对嵌入、标签和预测进行联合建模的简单混合模型能够比下一个最佳切片算法提高105%。我们假设,这是因为该算法在将类标签和模型的预测作为独立变量建模方面是独一无二的,这导致切片在其错误类型(假阳性与假阴性)方面是 "纯粹的"。
然而,还有很长的路要走:切片发现是一项具有挑战性的任务,*Domino,*我们实验中表现最好的方法,仍然无法恢复60%以上的连贯切片。我们看到未来的工作有许多令人兴奋的途径,可以开始缩小这一差距:
-
我们猜测,为切片发现提供动力的嵌入的改进将由大型跨模式数据集驱动,因此数据集的策划和管理方面的工作可以帮助推动这一进程。
-
在这篇博文中,我们将切片发现描述为一个完全自动化的过程,而在未来,我们预计有效的切片发现系统将是高度互动的:从业者将能够快速探索切片并提供反馈。 Forager,一个用于快速数据探索的系统,是朝着这个方向迈出的令人兴奋的一步。
我们非常高兴能继续研究这个重要的问题,并与其他人合作,寻求开发更可靠的切片发现方法。为了促进这个过程,我们正在发布984个模型和它们相关的切片,作为dcbench的一部分,这是一套以数据为中心的基准测试。这将使其他人能够复制我们的结果,并开发新的切片发现方法。此外,我们还发布了domino,一个包含流行切片发现方法实现的Python包。如果你已经开发了一个新的切片发现方法,并希望我们将其添加到库中,请联系我们!
