

文本处理是大量应用程序和服务的核心,在.NET中,这意味着大量的System.String 。String 的创建是如此的基本,以至于自.NET框架1.0发布以来,就有无数的创建方法存在,而且之后还有更多的方法加入到这个行列。无论是通过String's constructors,还是StringBuilder ,还是ToString overrides,还是String ,如Join 、Concat 、Create 、Replace ,创建字符串的API无处不在。然而,在.NET中创建字符串的最强大的API之一是String.Format 。
String.Format 方法有许多重载,所有这些方法的共同点是能够提供一个 "复合格式字符串 "和相关参数。该格式字符串包含文字和占位符的混合物,有时被称为 "格式项 "或 "洞",然后由格式化操作用所提供的参数来填充。例如,string.Format("Hello, {0}! How are you on this fine {1}?", name, DateTime.Now.DayOfWeek) ,给定一个名称为"Stephen" ,并在星期四调用,将输出一个字符串"Hello, Stephen! How are you on this fine Thursday?" 。还有一些其他的功能,比如提供一个格式指定符的能力,例如:string.Format("{0} in hex is 0x{0:X}", 12345) 将产生一个字符串"12345 in hex is 0x3039" 。
这些功能都使String.Format 成为一个工作主力,为相当大比例的字符串创建提供动力。事实上,它是如此的重要和有用,C#语言的语法在C# 6中被加入,以使其更加可用。这种 "字符串插值 "功能使开发者能够在字符串之前放置一个$ ;然后,与其单独指定格式项的参数,不如将这些参数直接嵌入到插值的字符串中。例如,我先前的 "Hello "例子现在可以写成$"Hello, {name}! How are you on this fine {DateTime.Now.DayOfWeek}?" ,这将产生完全相同的字符串,但通过一个更方便的语法。
C#编译器可以自由地生成它认为最适合插值字符串的任何代码,只要它最终产生相同的结果,而且今天它有多种机制可以使用,这取决于情况。例如,如果你写道:
const string Greeting = "Hello";
const string Name = "Stephen";
string result = $"{Greeting}, {Name}!";
C#编译器可以看到插值字符串的所有部分都是字符串字面,它可以将其排放到IL中,就好像它被写成了一个字符串字面“
string result = "Hello, Stephen!";
或者,举例来说,如果你写:
public static string Greet(string greeting, string name) => $"{greeting}, {name}!";
C#编译器可以看到所有的格式项都是字符串,所以它可以生成一个对String.Concat 的调用”
public static string Greet(string greeting, string name) => string.Concat(greeting, ", ", name);
然而,在一般情况下,C#编译器会发出一个对String.Format 的调用。例如,如果你要写:
public static string DescribeAsHex(int value) => $"{value} in hex is 0x{value:X}";
C#编译器将发出与我们前面看到的string.Format 调用类似的代码:
public static string DescribeAsHex(int value) => string.Format("{0} in hex is 0x{1:X}", value, value);
常量字符串和String.Concat 的例子代表了编译器所希望的良好输出。然而,当涉及到所有最终需要String.Format 的情况时,就隐含了一些限制,特别是围绕性能,但也有功能:
- 每次调用
String.Format,它都需要解析复合格式字符串,以找到文本的所有字面部分、所有格式项以及它们的指定器和排列方式;有点讽刺的是,在字符串插值的情况下,C#编译器已经做了这样的解析,以便解析插值字符串并生成String.Format,但每次调用时都要在运行时再次进行。 - 这些API都接受类型为
System.Object的参数,这意味着任何值类型最终都会被装箱,以便作为参数传入。 - 有一些
String.Format的重载,最多接受三个单独的参数,但对于需要超过三个参数的情况,有一个接受params Object[]的总括性重载。这意味着任何超过三个参数的数量都会分配一个数组。 - 为了提取要插入孔中的字符串表示,需要使用对象参数的
ToString方法,这不仅涉及到虚拟(Object.ToString)或接口(IFormattable.ToString)调度,还需要分配一个临时字符串。 - 这些机制都有一个共同的功能限制,那就是你只能使用可以作为
System.Object的东西作为格式项。这就禁止了使用ref struct,比如Span<char>和ReadOnlySpan<char>。越来越多的人使用这些类型作为提高性能的方法,它们能够以非分配的方式表示文本片段,不管是作为一个较大的字符串的切片跨度,还是作为格式化到堆栈分配的空间或可重复使用的缓冲区的文本,所以很遗憾它们不能被用于这些较大的字符串构造操作中。 - 除了创建
System.String实例外,C#语言和编译器还支持针对System.FormattableString,它实际上是复合格式字符串和Object[]参数数组的一个元组,这些参数数组将被传递给String.Format。这使得字符串插值语法可以用于创建除System.String以外的东西,因为代码可以接受该FormattableString及其数据并对其进行特殊处理;例如,FormattableString.Invariant方法接受一个FormattableString,并将数据与CultureInfo.InvariantCulture一起传递给String.Format,以便使用不变文化而不是当前文化执行格式化。虽然在功能上是有用的,但这增加了更多的费用,因为所有这些对象在做任何事情之前都需要被创建(除了分配,FormattableString也增加了自己的费用,比如额外的虚拟方法调用)。
所有这些问题以及更多的问题都被C# 10和.NET 6中的插值字符串处理程序所解决了!
字符串更快
编译器中的 "降低 "是一个过程,编译器通过这个过程有效地用更简单的结构或性能更好的结构重写一些更高级或更复杂的结构。例如,当你在一个数组上foreach :
int[] array = ...;
foreach (int i in array)
{
Use(i);
}
而不是将其作为使用数组的枚举器来表达:
int[] array = ...;
using (IEnumerator<int> e = array.GetEnumerator())
{
while (e.MoveNext())
{
Use(e.Current);
}
}
编译器将其作为你使用数组的索引器,从0到其长度进行迭代:
int[] array = ...;
for (int i = 0; i < array.Length; i++)
{
Use(array[i]);
}
因为这将导致最小和最快的代码。
C# 10通过允许内插字符串不仅可以 "降低到 "一个常量字符串、一个String.Concat 调用或一个String.Format 调用,而且现在还可以 "降低到 "一系列附加到构建器的概念,类似于今天你可能使用一个StringBuilder 来进行一系列Append 调用,最后提取构建的字符串。这些构建器被称为 "插值字符串处理程序",而.NET 6包括以下System.Runtime.CompilerServices 处理程序类型,供编译器直接使用:
namespace System.Runtime.CompilerServices
{
[InterpolatedStringHandler]
public ref struct DefaultInterpolatedStringHandler
{
public DefaultInterpolatedStringHandler(int literalLength, int formattedCount);
public DefaultInterpolatedStringHandler(int literalLength, int formattedCount, System.IFormatProvider? provider);
public DefaultInterpolatedStringHandler(int literalLength, int formattedCount, System.IFormatProvider? provider, System.Span<char> initialBuffer);
public void AppendLiteral(string value);
public void AppendFormatted<T>(T value);
public void AppendFormatted<T>(T value, string? format);
public void AppendFormatted<T>(T value, int alignment);
public void AppendFormatted<T>(T value, int alignment, string? format);
public void AppendFormatted(ReadOnlySpan<char> value);
public void AppendFormatted(ReadOnlySpan<char> value, int alignment = 0, string? format = null);
public void AppendFormatted(string? value);
public void AppendFormatted(string? value, int alignment = 0, string? format = null);
public void AppendFormatted(object? value, int alignment = 0, string? format = null);
public string ToStringAndClear();
}
}
作为一个最终如何使用的例子,请考虑这个方法。
public static string FormatVersion(int major, int minor, int build, int revision) =>
$"{major}.{minor}.{build}.{revision}";
在C# 10之前,这将产生相当于以下的代码。
public static string FormatVersion(int major, int minor, int build, int revision)
{
var array = new object[4];
array[0] = major;
array[1] = minor;
array[2] = build;
array[3] = revision;
return string.Format("{0}.{1}.{2}.{3}", array);
}
我们可以通过在分配分析器下观察这个问题来直观地看到上述的一些成本。这里我将使用Visual Studio中性能分析器中的.NET对象分配跟踪工具。对这个程序进行剖析:
for (int i = 0; i < 100_000; i++)
{
FormatVersion(1, 2, 3, 4);
}
public static string FormatVersion(int major, int minor, int build, int revision) =>
$"{major}.{minor}.{build}.{revision}";
yields:
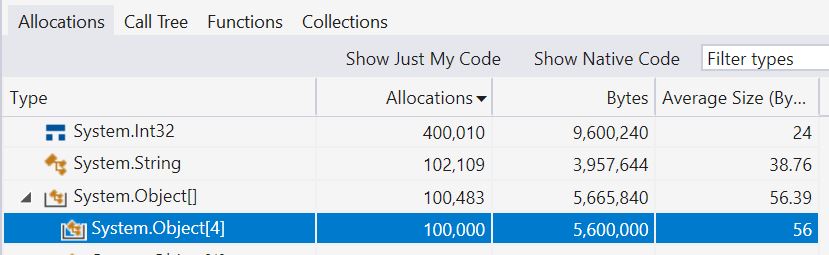
突出表明,我们正在对所有四个整数进行装箱,并分配一个对象[]数组来存储它们,此外还有我们期望在这里看到的结果字符串。
现在,在C# 10针对.NET 6的情况下,编译器反而产生了与此相当的代码:
public static string FormatVersion(int major, int minor, int build, int revision)
{
var handler = new DefaultInterpolatedStringHandler(literalLength: 3, formattedCount: 4);
handler.AppendFormatted(major);
handler.AppendLiteral(".");
handler.AppendFormatted(minor);
handler.AppendLiteral(".");
handler.AppendFormatted(build);
handler.AppendLiteral(".");
handler.AppendFormatted(revision);
return handler.ToStringAndClear();
}
现在在分析器中,我们只看到:

并取消了装箱和数组分配。
这里发生了什么?编译器:
- 构建一个
DefaultInterpolatedStringHandler,传入两个值:插值字符串的字面部分的字符数,以及字符串中的孔数。处理程序可以利用这些信息做各种事情,比如猜测整个格式化操作需要多少空间,并从ArrayPool<char>.Shared,租一个足够大的初始缓冲区来容纳。 - 发出一系列的调用来追加插值字符串的部分,为字符串的常量部分调用
AppendLiteral,为格式化项目调用AppendFormatted的一个重载。 - 发出对处理程序的
ToStringAndClear方法的调用,以提取构建的字符串(并将任何ArrayPool<char>.Shared资源返回到池中)。
如果我们回顾一下我们先前对string.Format 的关注清单,我们可以看到这里是如何解决各种关注的:
- 在运行时没有更多的复合格式字符串需要解析:编译器在编译时已经解析了字符串,并生成了适当的调用序列来建立结果。
- 处理程序暴露了一个通用的
AppendFormatted<T>方法,所以值类型将不再被框住,以便被附加。这也有连带的好处;例如,如果T是一个值类型,AppendFormatted<T>里面的代码将专门用于那个特定的值类型,这意味着由该方法执行的任何接口检查或虚拟/接口调度可以被去虚拟化,甚至可能被内联。(多年来,我们考虑过添加通用的String.Format重载,例如Format<T1, T2>(string format, T1 arg, T2 arg),以帮助避免装箱,但这样的方法也会导致代码膨胀,因为每一个带有一组独特的通用值类型参数的调用站点都会导致一个通用的特殊化被创建。虽然我们将来仍可能选择这样做,但这种方法限制了这种臃肿,因为每个T只需要一个AppendFormatted<T>,而不是在那个特定的调用站点传递的所有T1、T2、T3等的组合)。 - 我们现在对每个洞进行一次
AppendFormatted调用,所以在我们必须使用和分配一个数组来传入几个以上的参数时,不再有人为的悬崖。 - 编译器将绑定到任何接受与被格式化的数据类型兼容的
AppendFormatted方法,所以通过暴露AppendFormatted(ReadOnlySpan<char>),现在可以在插值字符串的孔中使用跨度的字符。
以前在格式化项目上调用object.ToString 或IFormattable.ToString 可能导致的中间字符串分配怎么办?.NET 6现在暴露了一个新的接口,ISpanFormattable (这个接口以前是内部的),它在核心库的许多类型上实现:
public interface ISpanFormattable : IFormattable
{
bool TryFormat(Span<char> destination, out int charsWritten, ReadOnlySpan<char> format, IFormatProvider? provider);
}
在DefaultInterpolatedStringHandler 上的通用AppendFormatted<T> 重载会检查T 是否实现了这个接口,如果它实现了,它就会使用它来进行格式化,而不是进入一个临时System.String ,而是直接进入支持处理程序的缓冲区。在值型Ts上,由于后端编译器进行的通用专业化,在编译汇编代码时也可以对这个接口进行检查,所以对于这种类型没有接口调度。
我们可以通过运行一个简单的基准测试来看看这对性能的影响的例子:
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using System.Runtime.CompilerServices;
[MemoryDiagnoser]
public class Program
{
static void Main(string[] args) => BenchmarkSwitcher.FromAssemblies(new[] { typeof(Program).Assembly }).Run(args);
private int major = 6, minor = 0, build = 100, revision = 7;
[Benchmark(Baseline = true)]
public string Old()
{
var array = new object[4];
array[0] = major;
array[1] = minor;
array[2] = build;
array[3] = revision;
return string.Format("{0}.{1}.{2}.{3}", array);
}
[Benchmark]
public string New()
{
var builder = new DefaultInterpolatedStringHandler(3, 4);
builder.AppendFormatted(major);
builder.AppendLiteral(".");
builder.AppendFormatted(minor);
builder.AppendLiteral(".");
builder.AppendFormatted(build);
builder.AppendLiteral(".");
builder.AppendFormatted(revision);
return builder.ToStringAndClear();
}
}
在我的机器上,这会产生:
| 方法 | 平均值 | 比率 | 分配 |
|---|---|---|---|
| Old | 111.70 ns | 1.00 | 192 B |
| New | 66.75 ns | 0.60 | 40 B |
表明简单的重新编译就能产生40%的吞吐量,并将内存分配减少近5倍。但是,我们可以做得更好...
C#编译器不仅仅知道如何在降低插值字符串的过程中隐含地使用DefaultInterpolatedStringHandler 。它还知道如何将一个插值字符串 "目标类型"(意思是根据被分配的东西来选择做什么)到一个 "插值字符串处理程序",一个实现编译器所知道的特定模式的类型,DefaultInterpolatedStringHandler ,实现该模式。这意味着一个方法可以有一个DefaultInterpolatedStringHandler 参数,当一个插值字符串作为该参数的参数被传递时,编译器将产生相同的构造和追加调用,在将处理程序传递给方法之前,创建和填充该处理程序。除此之外,如果提供了适当的构造函数,该方法可以使用[InterpolatedStringHandlerArgument(...)] 属性来让编译器将其他参数传入处理程序的构造函数。如前所述,DefaultInterpolatedStringHandler 实际上在我们的例子中已经使用的构造函数之外还暴露了两个额外的构造函数,一个还接受一个用于控制如何完成格式化的IFormatProvider? ,另一个则进一步接受一个可以被格式化操作用作划痕空间的Span<char> (这个划痕空间通常是堆栈分配的或者来自一些容易访问的可重用数组缓冲区),而不是总是要求处理程序从ArrayPool 。这意味着我们可以写一个这样的助手方法:
public static string Create(
IFormatProvider? provider,
Span<char> initialBuffer,
[InterpolatedStringHandlerArgument("provider", "initialBuffer")] ref DefaultInterpolatedStringHandler handler) =>
handler.ToStringAndClear();
这个方法和它没有太多的实现可能看起来有点奇怪......那是因为大部分涉及的工作实际上是在调用站点发生的。当你写的时候:
public static string FormatVersion(int major, int minor, int build, int revision) =>
Create(null, stackalloc char[64], $"{major}.{minor}.{build}.{revision}");
时,编译器会将其降低到相当于:
public static string FormatVersion(int major, int minor, int build, int revision)
{
Span<char> span = stackalloc char[64];
var handler = new DefaultInterpolatedStringHandler(3, 4, null, span);
handler.AppendFormatted(major);
handler.AppendLiteral(".");
handler.AppendFormatted(minor);
handler.AppendLiteral(".");
handler.AppendFormatted(build);
handler.AppendLiteral(".");
handler.AppendFormatted(revision);
return Create(null, span, ref handler);
}
现在我们可以从堆栈分配的缓冲区空间开始,而且在这个例子中,永远不需要从ArrayPool ,我们得到这样的数字:
| 方法 | 平均值 | 比率 | 分配 |
|---|---|---|---|
| Old | 109.93 ns | 1.00 | 192 B |
| New | 69.95 ns | 0.64 | 40 B |
| NewStack | 48.57 ns | 0.44 | 40 B |
当然,我们并不鼓励大家自己编写这样一个Create 方法。在.NET 6中,该方法实际上已经在System.String :
public sealed class String
{
public static string Create(
IFormatProvider? provider,
[InterpolatedStringHandlerArgument("provider")] ref DefaultInterpolatedStringHandler handler);
public static string Create(
IFormatProvider? provider,
Span<char> initialBuffer,
[InterpolatedStringHandlerArgument("provider", "initialBuffer")] ref DefaultInterpolatedStringHandler handler);
}
所以我们可以不需要任何自定义的帮助器来编写我们的例子:
public static string FormatVersion(int major, int minor, int build, int revision) =>
string.Create(null, stackalloc char[64], $"{major}.{minor}.{build}.{revision}");
IFormatProvider? 的参数呢?DefaultInterpolatedStringHandler 能够将该参数贯穿到AppendFormatted 的调用中,这意味着这些string.Create 的重载提供了一个直接的(而且性能更好的)替代FormattableString.Invariant 。比方说,我们想在我们的格式化例子中使用不变文化。以前我们可以写。
public static string FormatVersion(int major, int minor, int build, int revision) =>
FormattableString.Invariant($"{major}.{minor}.{build}.{revision}");
而现在我们可以这样写:
public static string FormatVersion(int major, int minor, int build, int revision) =>
string.Create(CultureInfo.InvariantCulture, $"{major}.{minor}.{build}.{revision}");
或者如果我们想同时使用一些初始缓冲区空间:
public static string FormatVersion(int major, int minor, int build, int revision) =>
string.Create(CultureInfo.InvariantCulture, stackalloc char[64], $"{major}.{minor}.{build}.{revision}");
这里的性能差异就更加明显了:
| 方法 | 平均值 | 比率 | 已分配的 |
|---|---|---|---|
| 旧的 | 124.94 ns | 1.00 | 224 B |
| 新的 | 48.19 ns | 0.39 | 40 B |
当然,可以传入的不仅仅是CultureInfo.InvariantCulture 。DefaultInterpolatedStringHandler 在提供的IFormatProvider 上支持与String.Format 相同的接口,所以甚至可以使用提供了ICustomFormatter 的实现。假设我想改变我的例子,用十六进制而不是十进制来打印所有的整数值。我们可以使用格式指定器来实现这个目的,比如说:
public static string FormatVersion(int major, int minor, int build, int revision) =>
$"{major:X}.{minor:X}.{build:X}.{revision:X}";
现在提供了格式指定符,编译器寻找的不是一个只接受Int32 值的AppendFormatted 方法,而是寻找一个既能接受要格式化的Int32 值,又能接受字符串格式指定符的方法。这样的重载确实存在于DefaultInterpolatedStringHandler ,所以我们最终生成了这个代码:
public static string FormatVersion(int major, int minor, int build, int revision)
{
var handler = new DefaultInterpolatedStringHandler(3, 4);
handler.AppendFormatted(major, "X");
handler.AppendLiteral(".");
handler.AppendFormatted(minor, "X");
handler.AppendLiteral(".");
handler.AppendFormatted(build, "X");
handler.AppendLiteral(".");
handler.AppendFormatted(revision, "X");
return handler.ToStringAndClear();
}
我们再次看到,编译器不仅在前面处理了将复合格式字符串解析为一系列单独的Append 调用,而且还解析出了格式指定符,作为参数传递给AppendFormatted 。但是,如果只是为了好玩,我们想以二进制而不是十六进制的方式输出组件呢?没有任何格式指定器可以产生Int32 的二进制表示。这是否意味着我们不能再使用插值的字符串语法?不是的。我们可以写一个小小的ICustomFormatter 实现:
private sealed class ExampleCustomFormatter : IFormatProvider, ICustomFormatter
{
public object? GetFormat(Type? formatType) => formatType == typeof(ICustomFormatter) ? this : null;
public string Format(string? format, object? arg, IFormatProvider? formatProvider) =>
format == "B" && arg is int i ? Convert.ToString(i, 2) :
arg is IFormattable formattable ? formattable.ToString(format, formatProvider) :
arg?.ToString() ??
string.Empty;
}
并将其传递给String.Create:
public static string FormatVersion(int major, int minor, int build, int revision) =>
string.Create(new ExampleCustomFormatter(), $"{major:B}.{minor:B}.{build:B}.{revision:B}");
关于重载的说明
需要注意的一个有趣的事情是AppendFormatted 处理程序上暴露的重载。前四个都是通用的,可以满足绝大多数开发者可以传递格式项的输入:
public void AppendFormatted<T>(T value);
public void AppendFormatted<T>(T value, string? format);
public void AppendFormatted<T>(T value, int alignment);
public void AppendFormatted<T>(T value, int alignment, string? format);
例如,给定一个int value ,这些重载可以使格式项变成这样:
$"{value}" // formats value with its default formatting
$"{value:X2}" // formats value as a two-digit hexademical value
$"{value,-3}" // formats value consuming a minimum of three characters, left-aligned
$"{value,8:C}" // formats value as currency consuming a minimum of eight characters, right-aligned
如果我们把对齐方式和格式参数作为可选项,我们可以只用最长的重载来启用所有这些项目;编译器使用正常的重载解析来确定要绑定到哪个AppendFormatted ,因此如果我们只有AppendFormatted<T>(T value, int alignment, string? format) ,就可以正常工作。然而,有两个原因我们没有这样做。首先,可选参数最终会将默认值作为参数带入IL,这使得调用站点变得更大,考虑到插值字符串的使用频率,我们希望尽可能减少调用站点的代码大小。其次,在某些情况下有代码质量上的好处,当这些方法的实现可以假定format 和alignment 的默认值时,所产生的代码可以更加精简。因此,对于代表插值字符串中使用的参数的大多数情况的通用重载,我们增加了所有四个组合。
当然也有一些东西今天不能被表示为泛型,最突出的是ref structs 。鉴于Span<char> 和ReadOnlySpan<char> 的重要性(前者可隐含地转换为后者),处理程序也暴露了这些重载:
public void AppendFormatted(ReadOnlySpan<char> value);
public void AppendFormatted(ReadOnlySpan<char> value, int alignment = 0, string? format = null);
给定一个ReadOnlySpan<char> span = "hi there".Slice(0, 2); ,这些重载可以启用像这样的格式项:
$"{span}" // outputs the contents of the span
$"{span,4}" // outputs the contents of the span consuming a minimum of four characters, right-aligned
后者可以由一个只接受对齐方式的AppendFormatted 方法来启用,但传递对齐方式是相对不常见的,所以我们决定只有一个可以同时接受对齐方式和格式的重载。带跨度的format ,但没有这个重载可能会导致编译器在某些情况下发出错误,所以为了一致性,它是可用的。
这使我们想到:
public void AppendFormatted(object? value, int alignment = 0, string? format = null);
既然我们有一个泛型,为什么还要有一个基于object 的重载?事实证明,在某些情况下,编译器无法确定用于泛型的最佳类型,因此,如果只提供泛型,就会导致绑定失败。如果你试图写一个这样的方法,你就可以看到这一点:
public static T M<T>(bool b) => b ? 1 : null; // error
这将无法编译,因为编译器目前无法确定一个用来表示该三元组结果的类型。然而,如果我们把它写成:
public static object M(bool b) => b ? 1 : null; // ok
就可以成功编译,因为1和null都可以转换为object 的目标类型。因此,我们为object 公开了一个AppendFormatted 的重载,以处理这些无法确定泛型类型的角落情况。但是,这些情况非常罕见,所以我们只添加了一个最长的重载,有可选的参数,作为后备。
有趣的是,如果你试图传递一个带有对齐方式和格式的字符串,这就会产生一个问题。在这一点上,编译器必须在T 、object 和ReadOnlySpan<char> 之间做出选择,而且string 可以隐含地转换为object (它来自于object )和ReadOnlySpan<char> (定义了一个隐含的转换操作),这就使问题变得模糊不清。为了解决这种模糊性,我们增加了string 的重载,该重载可以选择对齐方式和格式。我们还添加了只接受string 的重载,这是因为字符串作为格式项是非常普遍的,而且我们可以提供一个专门针对字符串的优化实现:
public void AppendFormatted(string? value);
public void AppendFormatted(string? value, int alignment = 0, string? format = null);
插值到Span中
到目前为止,我们已经看到了在C#中用字符串插值创建字符串是如何变得更快、更节省内存的,我们也看到了我们如何通过String.Create ,对字符串插值进行一些控制。我们还没有看到的是,新的C#字符串插值支持远远超出了创建新字符串实例的范围。相反,它现在提供了对使用字符串插值语法来格式化成任意目标的一般支持。
近年来,.NET中更有趣、更有影响的进展之一是跨度的扩散。当涉及到文本时,ReadOnlySpan<char> 和Span<char> 使得文本处理的性能得到了显著的改善。而格式化是其中的一个关键部分......例如,.NET中的许多类型现在都有TryFormat ,用于将基于char的表示方法输出到目标缓冲区,而不是使用ToString ,将其等效为一个新的字符串实例。现在,ISpanFormattable 接口及其TryFormat 方法是公开的,这将变得更加普遍。
所以,假设我正在实现我自己的类型,Point ,并且我想实现ISpanFormattable :
public readonly struct Point : ISpanFormattable
{
public readonly int X, Y;
public static bool TryFormat(Span<char> destination, out int charsWritten, ReadOnlySpan<char> format, IFormatProvider? provider)
{
...
}
}
我如何实现那个TryFormat 方法呢?我可以通过格式化每个组件来实现,边做边切跨度,一般来说,我可以手动完成所有的工作,比如说:
public bool TryFormat(Span<char> destination, out int charsWritten, ReadOnlySpan<char> format, IFormatProvider? provider)
{
charsWritten = 0;
int tmpCharsWritten;
if (!X.TryFormat(destination, out tmpCharsWritten, format, provider))
{
return false;
}
destination = destination.Slice(tmpCharsWritten);
if (destination.Length < 2)
{
return false;
}
", ".AsSpan().CopyTo(destination);
tmpCharsWritten += 2;
destination = destination.Slice(2);
if (!Y.TryFormat(destination, out int tmp, format, provider))
{
return false;
}
charsWritten = tmp + tmpCharsWritten;
return true;
}
这很好,尽管这是个不小的代码量。可惜的是,我不能用简单的字符串插值语法来表达我的意图,让编译器为我生成逻辑上等价的代码,例如:
public bool TryFormat(Span<char> destination, out int charsWritten, ReadOnlySpan<char> format, IFormatProvider? provider) =>
destination.TryWrite(provider, $"{X}, {Y}", out charsWritten);
事实上,你可以。在C# 10和.NET 6中,由于编译器对自定义插值字符串处理程序的支持,上述内容将 "恰到好处"。
.NET 6包含以下关于MemoryExtensions 类的新扩展方法:
public static bool TryWrite(
this System.Span<char> destination,
[InterpolatedStringHandlerArgument("destination")] ref TryWriteInterpolatedStringHandler handler,
out int charsWritten);
public static bool TryWrite(
this System.Span<char> destination,
IFormatProvider? provider,
[InterpolatedStringHandlerArgument("destination", "provider")] ref TryWriteInterpolatedStringHandler handler,
out int charsWritten);
这些方法的结构现在看起来应该很熟悉,以一个 "处理程序 "作为参数,该参数被赋予了一个[InterpolatedStringHandlerArgument] 属性,指的是签名中的其他参数。这个TryWriteInterpolatedStringHandler 是一种类型,旨在满足编译器对插值字符串处理程序的要求,特别是:
- 它需要以
[InterpolatedStringHandler]为属性。 - 它需要有一个构造函数,接受两个参数,一个是
int literalLength,一个是int formattedCount。如果处理程序参数有一个InterpolatedStringHandlerArgument的属性,那么构造函数也需要为该属性中的每个命名的参数提供一个参数,类型要适当,顺序要正确。构造函数也可以选择有一个out bool作为它的最后一个参数(稍后再谈)。 - 它需要有一个
AppendLiteral(string)方法,并且需要有一个AppendFormatted方法,支持插值字符串中传递的每个格式项类型。这些方法可以是void-returning或可选的bool-returning(同样,一会儿会有更多的内容)。
因此,这个TryWriteInterpolatedStringHandler 类型最终有一个非常类似于DefaultInterpolatedStringHandler 的形状:
[InterpolatedStringHandler]
public ref struct TryWriteInterpolatedStringHandler
{
public TryWriteInterpolatedStringHandler(int literalLength, int formattedCount, Span<char> destination, out bool shouldAppend);
public TryWriteInterpolatedStringHandler(int literalLength, int formattedCount, Span<char> destination, IFormatProvider? provider, out bool shouldAppend);
public bool AppendLiteral(string value);
public bool AppendFormatted<T>(T value);
public bool AppendFormatted<T>(T value, string? format);
public bool AppendFormatted<T>(T value, int alignment);
public bool AppendFormatted<T>(T value, int alignment, string? format);
public bool AppendFormatted(ReadOnlySpan<char> value);
public bool AppendFormatted(ReadOnlySpan<char> value, int alignment = 0, string? format = null);
public bool AppendFormatted(object? value, int alignment = 0, string? format = null);
public bool AppendFormatted(string? value);
public bool AppendFormatted(string? value, int alignment = 0, string? format = null);
}
有了这个类型,一个像前面所示的调用:
public bool TryFormat(Span<char> destination, out int charsWritten, ReadOnlySpan<char> format, IFormatProvider? provider) =>
destination.TryWrite(provider, $"{X}, {Y}", out charsWritten);
的调用最终会被降低为下面这样的代码:
public bool TryFormat(Span<char> destination, out int charsWritten, ReadOnlySpan<char> format, IFormatProvider? provider)
{
var handler = new TryWriteInterpolatedStringHandler(2, 2, destination, provider, out bool shouldAppend);
_ = shouldAppend &&
handler.AppendFormatted(X) &&
handler.AppendLiteral(", ") &&
handler.AppendFormatted(Y);
return destination.TryWrite(provider, ref handler, out charsWritten);
}
这里有一些非常有趣的事情发生。首先,我们看到TryWriteInterpolatedStringHandler's constructor中的out bool 。编译器正在使用这个bool 来决定是否进行任何后续的Append 调用:如果bool 是假的,它就短路,不调用任何一个。这在这种情况下是很有价值的,因为构造函数被传递给它要写入的literalLength 和destination span。如果构造函数看到字面长度大于目标跨度的长度,它就知道插值不可能成功(不像DefaultInterpolatedStringHandler ,它可以增长到任意的长度,TryWriteInterpolatedStringHandler 被赋予用户提供的跨度,它必须包含所有写入的数据),所以为什么要费心做更多的工作?当然,有可能字面上的内容适合,但字面上的内容加上格式化的项目则不适合。所以这里的每个Append 方法也会返回一个bool ,表示追加操作是否成功,如果不成功(因为没有更多的空间),编译器又能把所有的后续操作短路了。同样重要的是,这种短路不只是避免了后续Append 方法所做的任何工作,它甚至还避免了对洞的内容进行评估。想象一下,如果这些例子中的X 和Y 是昂贵的方法调用;这种条件性评估意味着我们可以避免我们知道不会有用的工作。在这篇文章的后面,我们将看到它的好处在哪里真正得到了体现。
一旦所有的格式化工作完成(或未完成),处理程序将被传递给开发者的代码实际调用的原始方法。该方法的实现负责任何最终的工作,在这种情况下,从处理程序中提取多少个字符被写入,以及操作是否成功,并将其返回给调用者。
插值到StringBuilders中
StringBuilder 长期以来一直是开发者创建 的主要方式之一,有许多方法暴露出来,用于突变实例,直到数据最终被复制到一个不可变的 。这些方法包括几个 的重载,例如:String String AppendFormat
public StringBuilder AppendFormat(string format, params object?[] args);
其工作方式与string.Format 相同,只是将数据写入StringBuilder 而不是创建一个新的字符串。让我们考虑一下前面的FormatVersion 例子的一个变体,这次修改为追加到构建器中。
public static void AppendVersion(StringBuilder builder, int major, int minor, int build, int revision) =>
builder.AppendFormat("{0}.{1}.{2}.{3}", major, minor, build, revision);
这当然是可行的,但它与我们最初对string.Format 的关注完全相同,所以关注这些中间成本的人(特别是如果他们正在汇集和重复使用StringBuilder 实例)可能会选择手工写出来。
public static void AppendVersion(StringBuilder builder, int major, int minor, int build, int revision)
{
builder.Append(major);
builder.Append('.');
builder.Append(minor);
builder.Append('.');
builder.Append(build);
builder.Append('.');
builder.Append(revision);
}
你可以看到这是怎么回事。.NET 6现在在StringBuilder 上提供了额外的重载。
public StringBuilder Append([InterpolatedStringHandlerArgument("")] ref AppendInterpolatedStringHandler handler);
public StringBuilder Append(IFormatProvider? provider, [InterpolatedStringHandlerArgument("", "provider")] ref AppendInterpolatedStringHandler handler);
public StringBuilder AppendLine([InterpolatedStringHandlerArgument("")] ref AppendInterpolatedStringHandler handler);
public StringBuilder AppendLine(System.IFormatProvider? provider, [InterpolatedStringHandlerArgument("", "provider")] ref AppendInterpolatedStringHandler handler)
有了这些重载,我们就可以重写我们的AppendVersion 例子,用插值字符串的简单性,但又有个别追加调用的一般效率。
public static void AppendVersion(StringBuilder builder, int major, int minor, int build, int revision) =>
builder.Append($"{major}.{minor}.{build}.{revision}");
正如我们所看到的,这最终会被编译器翻译成单独的追加调用,每个追加调用都会直接追加到由处理程序包裹的StringBuilder 。
public static void AppendVersion(StringBuilder builder, int major, int minor, int build, int revision)
{
var handler = new AppendInterpolatedStringHandler(3, 4, builder);
handler.AppendFormatted(major);
handler.AppendLiteral(".");
handler.AppendFormatted(minor);
handler.AppendLiteral(".");
handler.AppendFormatted(build);
handler.AppendLiteral(".");
handler.AppendFormatted(revision);
handler.Append(ref handler);
}
这些新的StringBuilder 重载有一个额外的好处,那就是它们确实是现有的Append 和AppendLine 方法的重载。当把一个非恒定的插值字符串传递给一个有多个重载的方法时,一个是接受字符串的方法,一个是接受有效的插值字符串处理程序的方法,编译器会优先选择有处理程序的重载。这意味着,在重新编译时,任何现有的对StringBuilder.Append 或StringBuilder.AppendLine 的调用,目前正在传递一个插值字符串,现在将简单地得到改善,将所有单独的组件直接追加到构建器中,而不是首先创建一个临时字符串,然后再追加到构建器中。
没有开销的Debug.Assert
开发人员有时在使用Debug.Assert 时面临的一个难题是希望在断言消息中提供大量有用的细节,同时也认识到这些细节实际上是不必要的;毕竟,Debug.Assert 的目的是在不应该发生的事情实际上已经发生时通知你。字符串插值使得在这样的消息中添加大量的细节变得容易。
Debug.Assert(validCertificate, $"Certificate: {GetCertificateDetails(cert)}");
但这也意味着它使人们很容易支付很多不必要的费用,而这些费用是不应该被要求的。虽然这 "只是 "用于调试,但这可能会对例如测试的性能产生深远的影响,这种开销会有意义地减损开发人员的生产力,增加持续集成所花费的时间和资源,等等。如果我们既能拥有这种漂亮的语法,又能在预期的100%不需要它们的情况下避免支付任何这些费用,那不是很好吗?
当然,答案是我们现在可以。还记得我们在前面的跨度例子中看到的执行的条件性吗?处理程序能够传递出一个bool 的值来告诉编译器是否要短路?我们利用Assert (以及WriteIf 和WriteLineIf )在Debug 上的新重载,例如:
[Conditional("DEBUG")]
public static void Assert(
[DoesNotReturnIf(false)] bool condition,
[InterpolatedStringHandlerArgument("condition")] AssertInterpolatedStringHandler message);
根据我之前的评论,当调用Debug.Assert ,并带有一个插值的字符串参数时,编译器现在会更喜欢这个新的重载,而不是采用String 。对于像图中所示的调用(Debug.Assert(validCertificate, $"Certificate: {GetCertificateDetails(cert)}") ),编译器将产生如下代码。
var handler = new AssertInterpolatedStringHandler(13, 1, validCertificate, out bool shouldAppend);
if (shouldAppend)
{
handler.AppendLiteral("Certificate: ");
handler.AppendFormatted(GetCertificateDetails(cert));
}
Debug.Assert(validCertificate, handler);
因此,如果处理程序的构造函数将shouldAppend 设置为false ,那么GetCertificateDetails(cert) 的计算和字符串的创建就根本不会发生,如果传入的条件布尔validCertificate 是true ,它就会这样做。这样,我们就避免了为断言做任何昂贵的工作,除非它即将失败。非常酷。
同样的技术对于其他的API来说可能是非常有价值的,比如那些涉及到日志的API,在那里你可能只想计算要记录的信息,如果日志当前被启用并且被设置为足够高的日志级别,以保证这个特定的调用生效。
下一步是什么?
这项支持从.NET 6预览版开始提供,我们希望得到您的反馈,特别是您希望看到对自定义处理程序的支持的其他地方。最有可能的候选者包括那些数据注定不是字符串的地方,或者对条件执行的支持自然适合于目标方法的地方。
