

本教程将告诉你如何使用Numpy meshgrid。
它将解释meshgrid函数的作用,解释语法,并向你展示清晰的例子,以帮助你发展对这一技术工作的直觉。
如果你需要特定的东西,你可以点击以下任何一个链接。
说了这么多,Numpy meshgrid的理解相当复杂,我建议你从头到尾看一遍这个教程。
Numpy Meshgrid的简单介绍
Numpy meshgrid是一个在Python中进行数字数据处理的工具。
我们使用Numpy meshgrid来创建一个X和Y值的矩形网格。
更具体地说,Meshgrid创建坐标值,使我们能够构建一个矩形的数值网格。
它以一种有点迂回的方式完成这个任务。
作为函数的输入,我们提供了带有数字值的一维数组。 这些数值将是新的 "Meshgrid "的坐标。
np.meshgrid的输出是一组包含这个新网格空间坐标的Numpy数组。
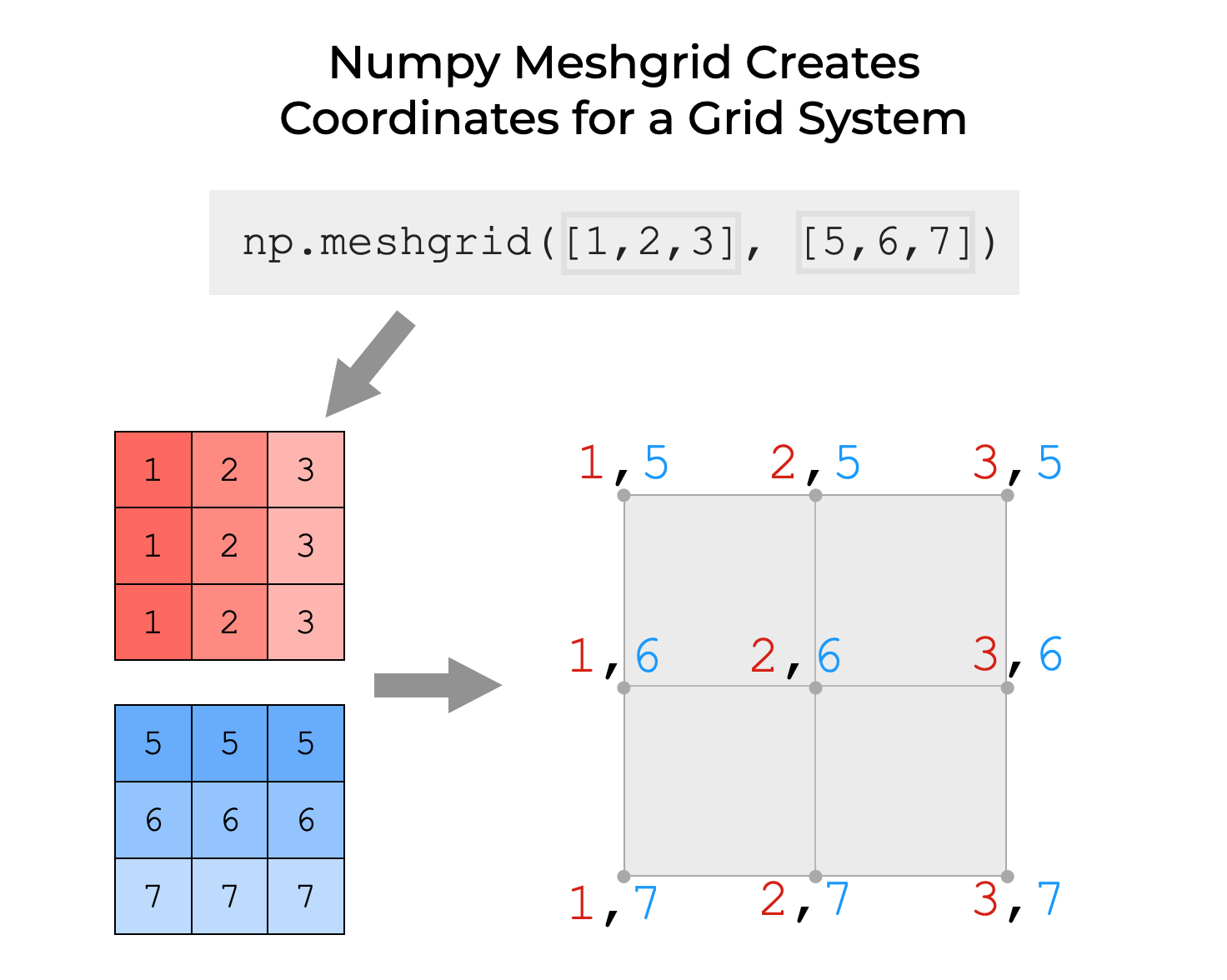
这是一个复杂的方法来创建一个网格状空间的每一个点的坐标;如果你愿意的话,就是一个 "Meshgrid"。
这个函数常常使初学者感到困惑,我认为理解它的最好方法是通过实例。 下面我将向你展示一些例子,但首先,让我们看看语法。
Numpy Meshgrid的语法
现在你已经了解了Numpy meshgrid在高层次上的作用,让我们来了解一下细节,看看它的语法。
一个简短的说明
在我继续之前,有一个简单的说明。
记住,当我们导入Numpy时,我们几乎总是用别名np ,这使得我们可以用后缀np 来调用Numpy函数。
import numpy as np
这是Python数据科学家的共同约定,接下来,我将假设你已经这样导入了Numpy。
np.meshgrid 语法
这个语法有点简单。
你以np.meshgrid() 的方式调用该函数。
在括号内,第一个参数应该是1D Numpy数组(或类似数组的对象),包含你想用作网格坐标的值。
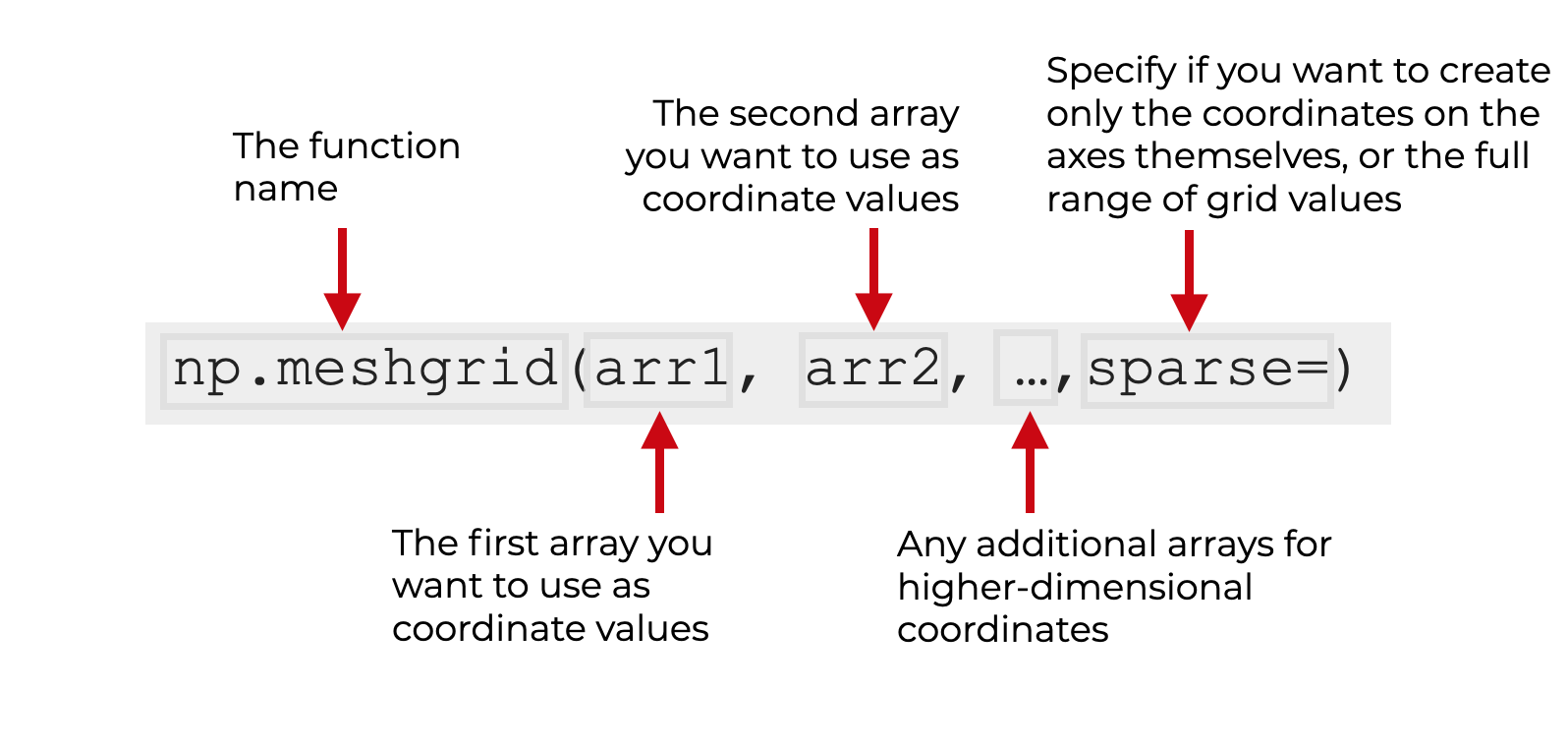
还有一些可选的参数,比如我们稍后要讨论的稀疏参数。
np.Meshgrid的参数和设置
让我们来看看np.meshgrid的输入和可选参数。
x1, x2, ... xnsparseindexing
x1, x2, ... xn (必填)
这些是函数的输入数组。
这些应该是带有数值的一维Numpy数组,尽管它们也可以是类似数组的对象,例如Python的列表。
最常见的是,我们使用两个输入数组。 这将导致Numpy meshgrid创建一个二维网格空间。
然而,技术上也可以只有一个输入数组,形成一个一维 "网格"。
也可以提供三个或更多的输入数组,这将创建一个更高维的网格空间的值。
sparse
sparse 参数使你能够指定你是否希望该函数严格地创建轴的值(如轴的刻度值),或者你希望它创建坐标值的完整网格。
如果你设置sparse = True ,它将只为新空间的轴创建值。
如果你设置sparse = False ,它将为创建的网格空间中的每个新点创建坐标。设置sparse = False 是默认的。
感到困惑吗?
你应该看一下例子1,看看当我们设置sparse = True ,会发生什么。 我想这个例子会阐明它的作用。
indexing
indexing 参数控制输出的索引方式。
indexing = 'xy'用笛卡尔索引创建输出indexing = 'ij'以矩阵索引方式创建输出
'xy' 是默认的。
如何使用Numpy Meshgrid的例子
现在我们看完了语法,让我们看看Numpy meshgrid的一些例子。
例子
- [Numpy meshgrid与
sparse = True] - [有两个输入和两个二维输出数组的Numpy meshgrid]
- [一个 "真实世界 "的机器学习例子,展示了我们如何使用Numpy meshgrid]
先运行这段代码
在我们运行这些例子之前有一个简单的说明。
所有这些例子都假定你已经导入了Numpy。
通常的惯例是用别名 "np"导入Numpy。
你可以像这样做。
import numpy as np
一旦你运行了这段代码,你就可以运行这些例子了。
例子1:Numpy meshgrid with "sparse = True"
在这里,我们不是从最简单的删除任何可选参数的例子开始,而是从一个实际使用了其中一个可选参数的例子开始。
具体来说,我们将使用sparse 参数,并设置sparse = True 。
让我们运行它,看看输出结果,然后我将解释为什么这很有用。
np.meshgrid([1,2,3], [5,6,7], sparse = True)
输出
[array([[1, 2, 3]]),
array([[5],
[6],
[7]])]
解释
看一下输入,再看一下输出。
输入是两个一维的 Python 列表:[1,2,3] 和[5,6,7] 。在这里,我使用了列表而不是 Numpy 数组,以使代码更容易阅读,但是我们也可以使用一维的 Numpy 数组,一样的。
所以输入是一维 Python 列表。
但是输出是二维Numpy数组。
最重要的是看它们是如何结构的。
第一个数组,[[1, 2, 3]] ,一直保持水平状态。
但是第二个数组的结构是垂直的。
[[5], [6], [7]]
为什么?
你需要把这些输出看作是X轴的值和Y轴的值。
Numpy meshgrid正在创建我们可以用于欧几里得、x/y网格的输出。
所以我们提供了输入值,而它产生的输出可以像x轴和y轴的值一样。

重要的是,当我们设置sparse = True ,np.meshgrid只产生像坐标系的轴值一样的输出。
正如你在接下来的例子中所看到的,如果设置sparse = False ,那么np.meshgrid将产生新网格坐标系中所有点的值。
(注意,我上面说的一切都适用于二维的情况,对于n维的输入会更加复杂。)
实例2:Numpy meshgrid有两个输入和两个二维输出数组
接下来,我们来看看一个非常简单的例子,没有任何额外的参数。
所以在这里,我们将使用Numpy meshgrid和两个Python列表作为输入。
并且我们将删除我们在例子1中看到的sparse 参数。
让我们看一下。
np.meshgrid([1,2,3], [5,6,7])
下面是输出结果。
[array([[1, 2, 3],
[1, 2, 3],
[1, 2, 3]]),
array([[5, 5, 5],
[6, 6, 6],
[7, 7, 7]])]
解释
你会注意到,代码相当简单,但输出比我们在例子1中看到的输出要复杂一些。
在例子1中,我们设置了sparse = True ,但在这里我们删除了sparse 参数,所以它被设置为默认的sparse = False 。

在这里,我对输出进行了颜色编码,只是为了帮助你看到它们是如何结构的。
注意输入和输出之间的关系。
在这个例子中,有两个二维的输出数组。
第一个输出数组包含第一个输入的值。1,2,3.但是这些值已经向下重复了。
第二个输出数组包含来自第二个输入的值。5,6,7. 但是这些值已经被重复了。
Meshgrid正在为一个网格的数值创建坐标
你可能会问,这两个输出数组到底是干什么的?
Numpy meshgrid为我们提供了坐标。
正如我之前所建议的,Meshgrid所创建的坐标可以让我们创建一个欧几里得的x和y空间。(至少,在这个例子中是这样的。 它给我们的是一个二维空间的坐标。 如果我们使用更高维的输入,它可能会给我们一个更高维的空间的坐标。 但那要复杂得多,所以现在别想了)。
这看起来像什么呢?
想想看,在一个类似网格的欧几里得空间中的一组坐标,由输入数组中的值定义。
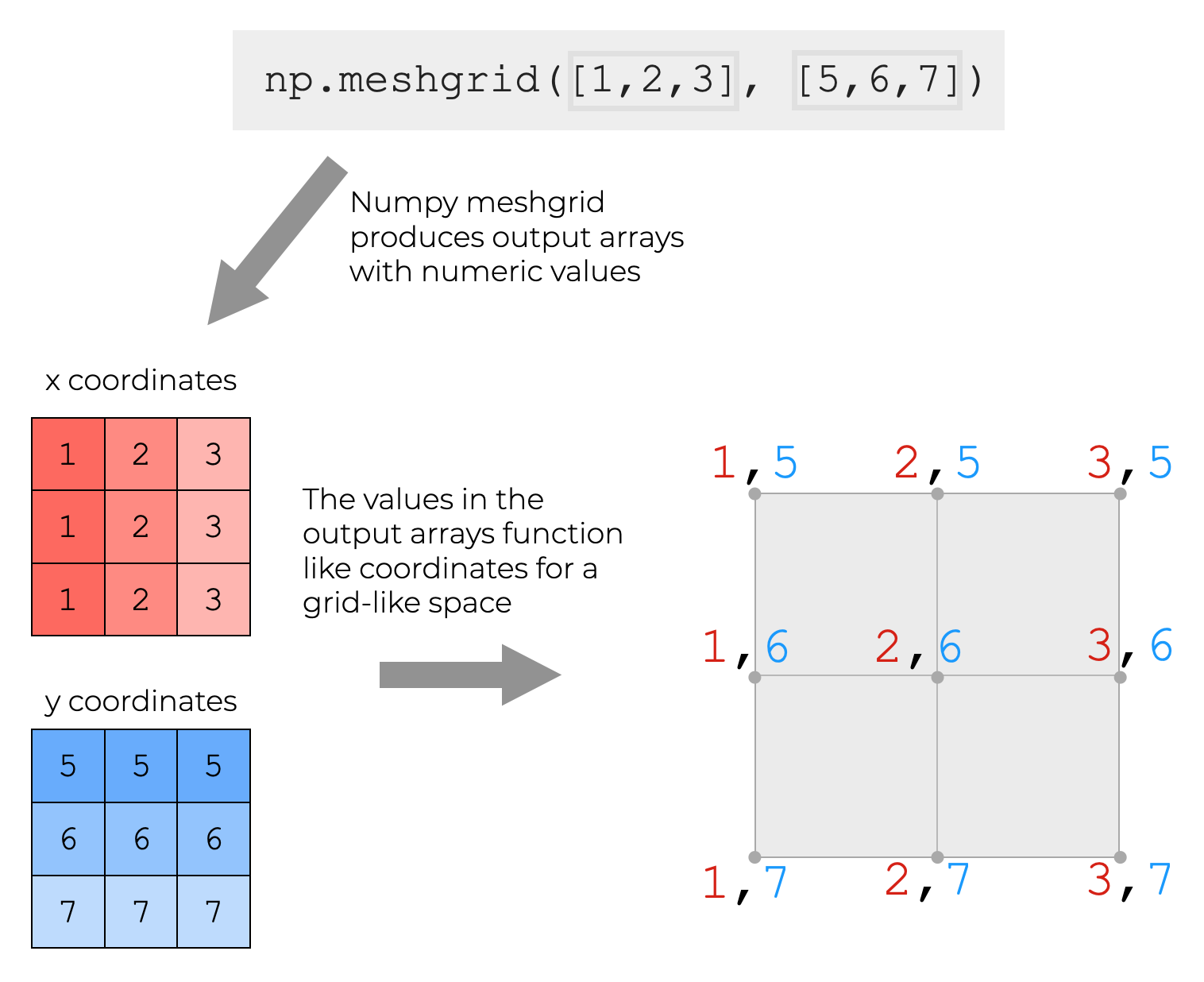
就这样吧,伙计们。
这就是Meshgrid的作用。
这是一种复杂的、倒退的、难以理解的为网格系统创建坐标的方法。
例子3:一个 "真实世界 "的机器学习例子,展示了我们如何使用Numpy meshgrid。
好的。
让我们最后做一个 "真实世界 "的例子,在这个例子中我们实际使用Numpy meshgrid做一些有用的事情。
在这里,我们将使用Numpy meshgrid来可视化一个机器学习模型的决策边界。
我承认:这是一个复杂的例子,这里有很多事情要做。 如果你对此感到困惑,你应该考虑报名参加我们的Numpy课程或Python机器学习课程。
代码
好的,我们首先要导入我们的包。
# IMPORT PACKAGES
import numpy as np
import plotly.graph_objects as go
import seaborn as sns
from sklearn.datasets import make_moons
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
接下来,我们需要创建一个数据集并将其分割。
在这里,我们将使用scikit learn make_moons来创建月形数据。
# LOAD DATA
X, y = make_moons(n_samples = 200
,noise = .1
,random_state = 3
)
X.shape
y.shape
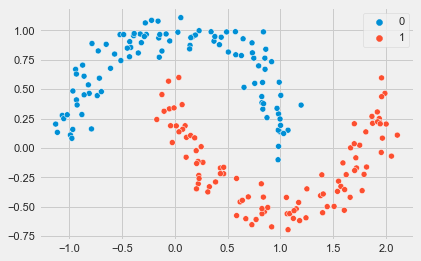
在这里,我们将[用Seaborn散点图函数将其可视化]
# PLOT DATA
plt.style.use('fivethirtyeight')
sns.scatterplot(x = X[:,0], y = X[:,1], hue = y)
输出
现在我们将用Sklearn train_test_split函数来分割数据。
#-------------------------
# CREATE TRAIN & TEST DATA
#-------------------------
(X_train, X_test, y_train, y_test) = train_test_split(X
,y
,test_size = .2
)
好的,这里是我们使用Meshgrid的部分。
我们将用Numpy meshgrid创建一个X/Y坐标的网格。
为此,你会注意到我设置了一个grid_unit_size ,这是网格中的步长。
我还用x_min 、y_min ,等等来设置网格空间的边界。
还注意到我使用了[Numpy的range函数]来创建数据的x范围和y范围。 这些都是Meshgrid的输入。
# CREATE MESHGRID ON WHICH WE WILL RUN OUR MODEL
grid_unit_size = .02
margin = 0.25
x_min = X[:, 0].min() - margin
x_max = X[:, 0].max() + margin
y_min = X[:, 1].min() - margin
y_max = X[:, 1].max() + margin
x_range = np.arange(start = x_min, stop = x_max, step = grid_unit_size )
y_range = np.arange(start = y_min, stop = y_max, step = grid_unit_size )
x_gridvalues, y_gridvalues = np.meshgrid(x_range, y_range)
接下来,我们将创建一个KNN分类器模型。
# INITIALIZE CLASSIFIER AND FIT MODEL
knn_classifier = KNeighborsClassifier(15, weights='uniform')
knn_classifier.fit(X, y)
现在我们有了我们的模型,我们将用它来计算我们网格上的值。
注意,要做到这一点,我们需要用[Numpy vstack]和[Numpy flatten]做大量的数据处理工作。
# COMPUTE PROBABILITIES ON GRID
gridvalues_combined_tidy = np.vstack([x_gridvalues.flatten(), y_gridvalues.flatten()]).T
knn_class_probabilities = knn_classifier.predict_proba(gridvalues_combined_tidy)
probability_postive_class = knn_class_probabilities[:,1]
这样做之后,我们就有了正类的概率。
最后,我们可以用Plotly绘制它们。
# PLOT THE PROBABILITIES ON THE MESHGRID
fig = go.Figure(data=[
go.Contour(
x = x_range
,y = y_range
,z = probability_postive_class.reshape(x_gridvalues.shape)
,colorscale = 'RdBu'
#,alpha = .3
)
])
fig.show()
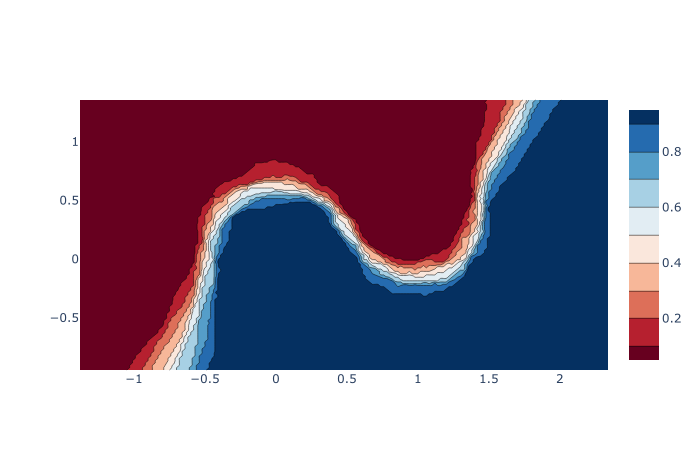
我承认:这里有很多事情要做。 我相信,如果你是一个初学者,这有点难以理解。
但实际上,你只需要知道我们用来做这一切的小函数和工具。
Numpy meshgrid是其中之一,但要真正理解这一点,你需要对Numpy、scikit learn和Python中的数据可视化(Seaborn和/或Plotly)有相当程度的了解。
